转自:http://blog.csdn.net/noaboutfengyue/article/details/45192897
自己用JAVA做的CSDN博文下载器,提供jar包和源码。
源码也公开吧,反正jar反编译也能得到源码,新手不会jar加密。
下载:http://download.csdn.net/detail/owuguanfengyue123/8619649
资源csdn在审核吧…好慢
考虑到上课的时候看博客不方便,想把好的博客全部下载下来,在手机上看。
各种百度,找到了几个工具。
1.http://blog.csdn.net/gzshun/article/details/7555525
大神写了思路和教程,用他的工具发现的问题:
(1)下载不完全,测试只能下载第一页的21篇文章左右。
(2)生成的pdf看着还行,代码部分有的超出pdf页面范围,导致看不到,不方便
2.http://www.cr173.com/soft/48129.html
这个大神写的通用博客导出工具,好像接口有变化,失效了,导出不了。
我就在琢磨自己写个程序出来。
好了,有了http://blog.csdn.net/gzshun/article/category/932960 前辈的思路。
扩展了一下,自己的思路:
(1)电脑版改为手机版
个人感觉手机版csdn更精简,处理起来肯定方便,链接是http://m.blog.csdn.net/blog,后面加用户名就是该用户的博客了,这里要区别用户名和自定义域名,电脑版的博客链接一般是自定义域名,例如:我的电脑版csdn博客自定义域名是:noaboutfengyue,我的用户名是:oWuGuanFengYue123,电脑版中http://blog.csdn.net/加这两个都可以跳转到博客,但是在手机版中只能访问 http://m.blog.csdn.net/blog/oWuGuanFengYue123打开博客。
为了使用方便,程序只需读入自定义域名就能下载,所以,增加个方法,功能是通过域名获得用户名,实现很简单,打开http://blog.csdn.net/noaboutfengyue,源码中就有oWuGuanFengYue123用户名,通过正则表达式解析就Ok。
(2)采用ITEXT从html生产pdf
在http://blog.csdn.net/noaboutfengyue/article/details/45174787中已经说明
(3)获取所有文章列表
经测试发现http://m.blog.csdn.net/blog/oWuGuanFengYue123?page= 这个page是文章页数,当这个数字很大时,大过文章页数,取个极限,99999,http://m.blog.csdn.net/blog/oWuGuanFengYue123?page=999999,显示的就是所有文章
(4)文章列表的获取和文章内容的解析
在(3)中获取的页面,通过正则表达式,解析出所有文章标题和url,然后通过这个url得到html源码,由于使用IText,对html源码的格式要求很严,所以这里要进行预处理(这里做的有点不完善),比如<br>报错,必须改成<br/>,还有一些,然后直接转换成pdf输出。
(5)增加序号
为了使生成出来的pdf有序,按照作者第一篇博文开始编号。生成出来的文件名是 1.标题.pdf
思路大概就这些,细节方面有些要处理。
使用说明:
下载目录在当前程序目录/csdn/用户名
演示一下吧。
用http://m.blog.csdn.net/blog/lmj623565791 这个老师的来演示,博客写得很好。

处理过程显示:
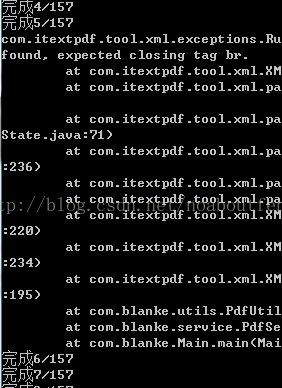
还是有些地方处理的不完善,大致上处理还不错,能生成大部分pdf。
结果:
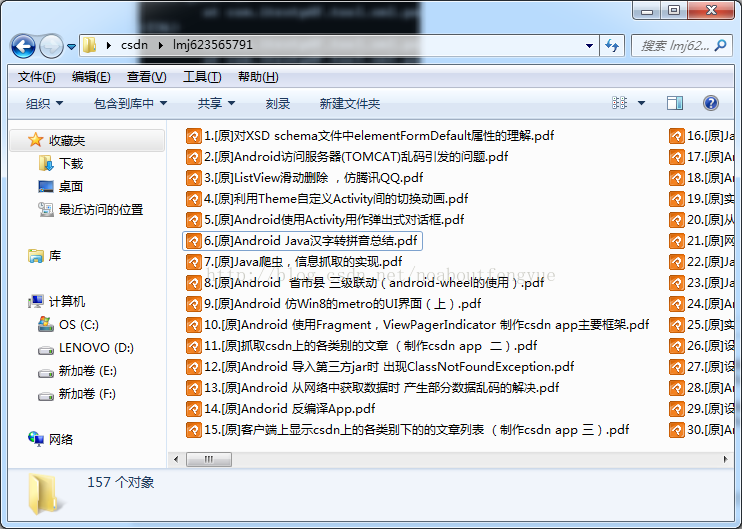
就这样了,哈哈,世界清净了。
不说了,我去下载好的博客去了,上课了去看。
</div>
转自:http://blog.csdn.net/noaboutfengyue/article/details/45192897
自己用JAVA做的CSDN博文下载器,提供jar包和源码。
源码也公开吧,反正jar反编译也能得到源码,新手不会jar加密。
下载:http://download.csdn.net/detail/owuguanfengyue123/8619649
资源csdn在审核吧…好慢
考虑到上课的时候看博客不方便,想把好的博客全部下载下来,在手机上看。
各种百度,找到了几个工具。
1.http://blog.csdn.net/gzshun/article/details/7555525
大神写了思路和教程,用他的工具发现的问题:
(1)下载不完全,测试只能下载第一页的21篇文章左右。
(2)生成的pdf看着还行,代码部分有的超出pdf页面范围,导致看不到,不方便
2.http://www.cr173.com/soft/48129.html
这个大神写的通用博客导出工具,好像接口有变化,失效了,导出不了。
我就在琢磨自己写个程序出来。
好了,有了http://blog.csdn.net/gzshun/article/category/932960 前辈的思路。
扩展了一下,自己的思路:
(1)电脑版改为手机版
个人感觉手机版csdn更精简,处理起来肯定方便,链接是http://m.blog.csdn.net/blog,后面加用户名就是该用户的博客了,这里要区别用户名和自定义域名,电脑版的博客链接一般是自定义域名,例如:我的电脑版csdn博客自定义域名是:noaboutfengyue,我的用户名是:oWuGuanFengYue123,电脑版中http://blog.csdn.net/加这两个都可以跳转到博客,但是在手机版中只能访问 http://m.blog.csdn.net/blog/oWuGuanFengYue123打开博客。
为了使用方便,程序只需读入自定义域名就能下载,所以,增加个方法,功能是通过域名获得用户名,实现很简单,打开http://blog.csdn.net/noaboutfengyue,源码中就有oWuGuanFengYue123用户名,通过正则表达式解析就Ok。
(2)采用ITEXT从html生产pdf
在http://blog.csdn.net/noaboutfengyue/article/details/45174787中已经说明
(3)获取所有文章列表
经测试发现http://m.blog.csdn.net/blog/oWuGuanFengYue123?page= 这个page是文章页数,当这个数字很大时,大过文章页数,取个极限,99999,http://m.blog.csdn.net/blog/oWuGuanFengYue123?page=999999,显示的就是所有文章
(4)文章列表的获取和文章内容的解析
在(3)中获取的页面,通过正则表达式,解析出所有文章标题和url,然后通过这个url得到html源码,由于使用IText,对html源码的格式要求很严,所以这里要进行预处理(这里做的有点不完善),比如<br>报错,必须改成<br/>,还有一些,然后直接转换成pdf输出。
(5)增加序号
为了使生成出来的pdf有序,按照作者第一篇博文开始编号。生成出来的文件名是 1.标题.pdf
思路大概就这些,细节方面有些要处理。
使用说明:
下载目录在当前程序目录/csdn/用户名
演示一下吧。
用http://m.blog.csdn.net/blog/lmj623565791 这个老师的来演示,博客写得很好。
处理过程显示:
还是有些地方处理的不完善,大致上处理还不错,能生成大部分pdf。
结果:
就这样了,哈哈,世界清净了。
不说了,我去下载好的博客去了,上课了去看。
</div>