发生数据倾斜时的常见的现象:
绝大多数task执行得都非常快,但个别task执行极慢。大部分task都执行完了,但是最后几个task始终在运行。
发生数据倾斜的原因:
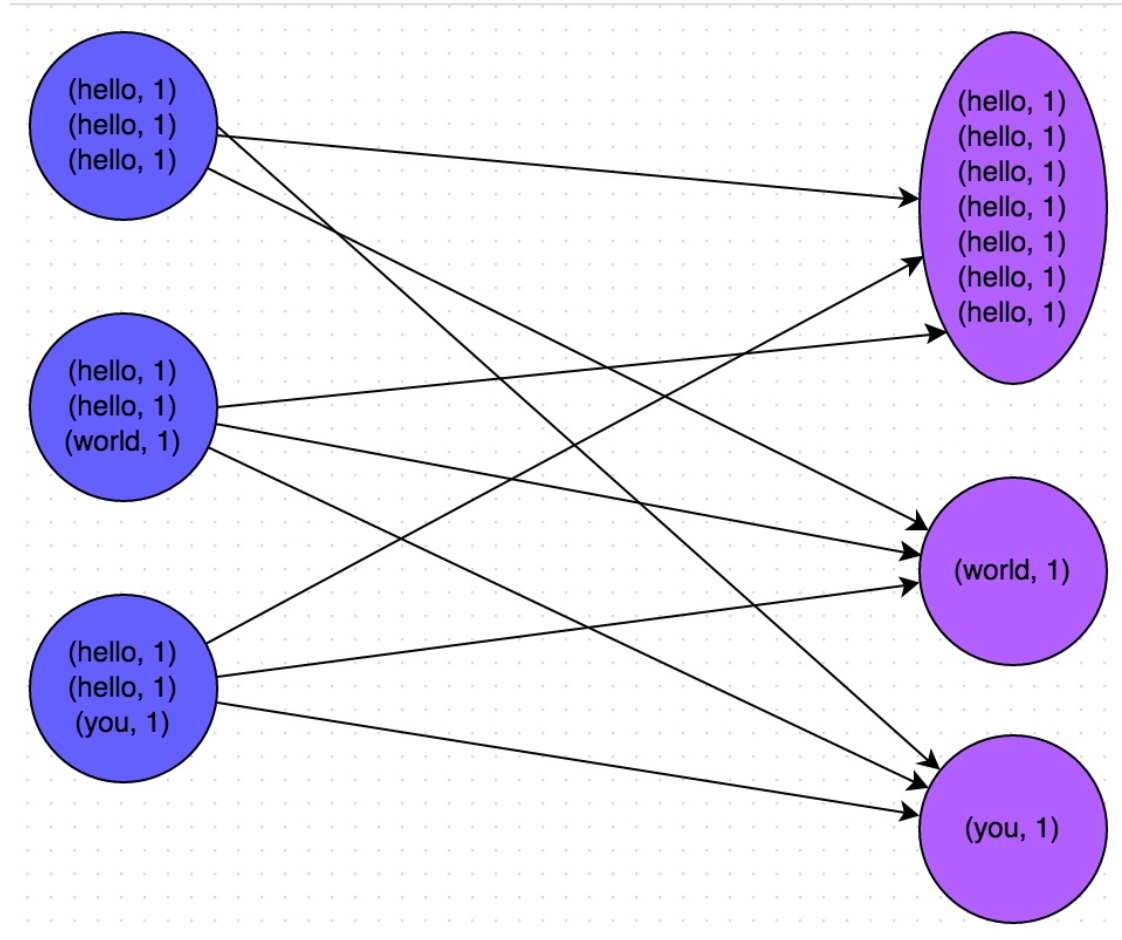
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了100万数据,要运行一两个小时。因此,整个Spark作业的运行进度是由运行时间最长的那个task决定的。如下图:key为hello的就会有数据倾斜
解决方法:
1. 尽量少使用distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup等一些容易触发shuffle的算子。
2. 使用Hive ETL预处理数据(将中间shuffle结果存成hive表)
3.直接过滤掉一些导致倾斜的key
4. 增大spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很多场景来说都有点过小。但是如果是某个key特别特别大(比如几百万其他key只有几百),该方法无效,该方法只能将不同key分到不同机子上,无法将同一个key分到多台机子。
5. 对于聚合操作导致的数据倾斜,可以给key添加一个随机数,如hello -> (hello,1) (hello,2)...将其作为新的key再聚合
6.对于大表join小表(表在1~2G以内)导致的倾斜问题,不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
7. 适当加大repartition