
一、说明
在本系列关于训练 GAN 实用指南的第 1 部分中,我们讨论了 a) 鉴别器 (D) 和生成器 (G) 训练之间的不平衡如何导致模式崩溃和由于梯度消失而导致静音学习,以及 b) GAN 对超参数的敏感性。
在本文中,我们将为每种不稳定性提供多种解决方案。这些解决方案在我们的实验中经验上运作良好,在广泛尝试了书中的每一个技巧来稳定GAN训练之后。我们按照其易于实施和各自影响的顺序编制列表,以就GAN培训的迭代增强功能提出建议。 另外,请注意,此处讨论的所有解决方案都是任何形式的GAN培训的通用解决方案,并且也与时空用例直接相关。JUST时空GAN特有的问题和解决方案将在本系列的最后一部分进一步详细讨论。
二、驯服 GAN 的不稳定性
2.1. 生成器和鉴别器之间的不平衡
如上一篇文章所述,训练 G 和 D 之间的不平衡(即,G 或 D 中的任何一个被不成比例地训练为优于另一个)会导致梯度消失,以及当 G 没有动力产生不同的样本来欺骗其竞争对手时模式崩溃。 为了解决这个问题,通常的解决方案围绕着:
·更改成本函数以获得更好的优化目标。
·在成本函数中添加额外的惩罚以强制执行约束(例如多样性)。
· 避免过度自信和过度拟合。
梯度消失和模式崩溃的解决方案将在以下小节中详细讨论。在每个部分中,我们首先列出所有(排名)建议的解决方案以及每个解决方案背后的直觉。随后,我们最后总结了每个部分的要点。
2.2 消失梯度:
为了减轻梯度消失,通常部署的策略是使D的任务更难,并给G一个追赶的机会。这是出于这样的信念:“判断一幅画是否是梵高很容易,但实际制作一幅画却非常困难。因此,基本假设是G的任务比D的任务困难得多。
1. 单侧标签平滑:如果 D 对其预测过于自信,则会导致梯度消失,G 无法从此类观测中学习——将实际样本预测为 ~1(例如,0.999),将生成的样本预测为 ~0(例如,0.0001)给出 ~0 的损失。解决此问题的一种简单但高效的技术是将真实数据的所有“1”基本真实标签转换为 [0.7 到 1.2] 的范围,将生成数据的所有“0”基本真实标签从“0”转换为 [0.0 到 3.<>]。 当 D 对其预测过于自信时,这会惩罚它,并确保即使在正确的预测场景下也能保持梯度流动,使 G 能够从这些实例中学习。请注意,这仅在更新 D 的权重时完成,而不是在 G 更新期间完成(因此称为“单侧”)。
2.单面翻转标签:如果你注意到损失仍然很快下降到0,你可以进一步削弱表现优异的D.从业者通常会翻转真实数据和生成数据的标签(真实数据标签从1随机翻转到0;生成的数据从0到1)。这增加了 D 训练的噪音,并防止它在训练的任何阶段变得太强大。同样,这仅适用于 D 更新。
3. 由于 G 的任务比较困难,G 通常会在再次训练 D 之前训练 x 步(~2-5)(同时保持 D 不变)。这允许生成器在训练早期弥合 p 和 q 分布之间的差距,并从 D 获得有意义的反馈以改进生成。我们建议在尝试列表中的其他建议之前不要在此步骤上花费太多时间,因为 GAN 训练的不同阶段无法通过这种固定相对更新的启发式来控制。相对更新将根据G和D之间不断发展的学习动态而动态变化,并且这些更新不能以启发式方式预定义。但是,G:D 的系数为 2:1理想情况下可以遵循培训步骤。
4. 在 D 中使用批量归一化 (BN) 与下面的提示 #5 共轭。批量归一化是一种监督学习方法,用于归一化神经网络的层间输出。它有助于稳定训练过程(通过减少协变量偏移)并通过防止过度拟合来改善泛化。
5.将生成的样本和实际样本分别馈送到D。这个小技巧可以防止 D 使用快捷方式进行分类,这些分类不会给 G 任何反馈来改进其生成。BN 的目的是通过使所有激活均匀分布(均值为零且 std 等于 1)来减少激活映射中的内部协方差偏移。在这种情况下,NN 没有必要适应由于训练过程中权重变化而发生的激活分布的变化。因此,这种规范化大大简化了学习。在GAN训练的一开始,小批量中的真实和假样本具有非常非常不同的分布,因此如果我们尝试对其进行规范化,我们最终不会得到居中良好的数据。此外,在训练过程中,这种归一化数据的分布将发生显著变化(因为 G 会逐渐提供越来越好的结果),鉴别器将不得不适应这些变化。
6. 使用其他提供更稳定梯度分布的损失函数,如 WGAN、RSGAN 等。然而,Google Brain 的论文实证表明,没有损失函数是明显的赢家(Mario Lucic,2018),GAN损失函数的选择仍然是一个尚未被征服的模糊领域。
7. 在监督任务上对生成器进行某种形式的预训练,使其与潜在空间广泛对齐,并学习捕获任务的一些基本特征(例如图像生成时的边缘和轮廓)。这有助于在对抗训练开始时弥合 p 和 q 之间的差距,从而防止由于 G 输出与真实世界数据之间的巨大脱节而导致 JSD 梯度消失。
2.3 模式折叠:
为了缓解这种情况,部署的常用策略是:
1. 使用标签:尽可能使用带有辅助分类器 GAN 设置的标签(Augustus Odena,2016)。这鼓励G在潜在空间的不同区域与用作条件输入的不同标签之间建立连接。这可以防止G产生相同的输出,而不管其输入如何,从而防止模式崩溃。

2. 特征匹配:通过将 G 的目标从不惜一切代价成功愚弄 D 修改为匹配真实数据的潜在特征,从而促进生成的多样性。这涉及在批处理级别上获取各个特征向量均值之间的 L-2 距离。此小批量设置引入了随机性,这使得在单个模式下更难过度拟合。
![]()
3. 小批量判别:为了解决模式崩溃问题,将真实数据和生成的数据分别分批馈送到D,并计算数据点x与同批次数据点的相似性。然后将 中的相似性 o(x) 与鉴别器的倒数最后一层的特征连接起来,以对该数据 x 是真实的还是生成的进行分类。在模式崩溃的情况下,生成的数据的相似性开始增加,D可以使用此信息再次开始对生成的图像进行正确分类,并惩罚G缺乏多样性。计算这一点的确切机制比特征匹配稍微复杂一些,但声称在实践中效果更好(Tim Salimans,2016),总结如下。

在这里,xi是输入图像,xj是同一批次中的其余图像。这些操作如下图所示:
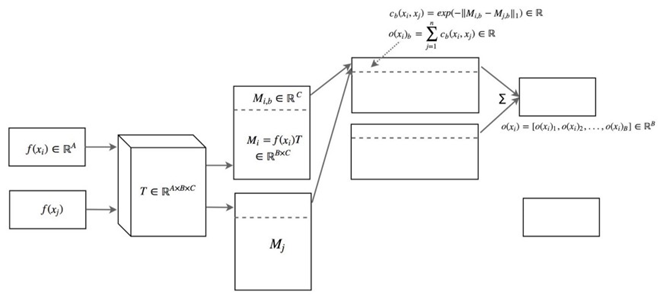
要点:
1. 尝试使用 G 和 D 的“容量”很可能不会产生太大区别(即它们的相对参数大小)。与 G 和 D 的相对模型大小相比,训练动态受正在优化的损失函数和确切的实验设置的影响更大。
2. 尝试针对 G:D 进行优化训练步长比是徒劳的练习。虽然一种直觉敦促你更多地训练G,但另一种直觉表明这可能是有害的。当GAN训练过程高度动态和敏感时,很难设计这种静态启发式方法。许多人尝试过这个,但失败了。
3.尝试单面标签平滑和标签翻转作为第一步。集成非常简单,但非常有效。通过使用这两个简单的技巧,我们看到了巨大的学习收益。
4. 使用批量归一化,并将生成的样本和实际样本分别馈送到 D。
5. 使用替代损失函数,如 WGAN、RSGAN 等,通过更好的梯度来稳定训练(但要有一点盐;这里没有明显的赢家)。
6. 使用辅助分类器GAN框架(当标签可用时),特征匹配和小批量判别来促进多样性并解决模式崩溃问题。
三. 对超参数的敏感性
GAN对超参数非常敏感,周期。尽管优化超参数需要大量的耐心和时间,但事实证明,此练习对于成就或破坏架构性能具有决定性意义。为了帮助完成此过程,一般提示是:
1. 学习率 (LR):学习率是最重要的超参数之一,可以成就或破坏您的训练,在选择一个时需要记住多种启发式方法:
a)两个时间尺度更新规则(TTUR):这本质上意味着对G和D使用不同的学习率,G的LR低于D。这可确保 G 采取小步骤来欺骗 D,这有助于防止模式崩溃。如果 G 在训练期间过早地采取太快和太精确的步骤,那么它更有可能选择一种欺骗 D 的单一模式来赢得对抗游戏。
b) LR 应取决于批量大小:对于较大的批量大小,较高的 LR 是可以的,因为它们在批次之间提供的噪音更新较少,这可能会导致 GAN 训练的巨动。但建议与 LR 总体上保持保守。
2.批量大小:较大的批量大小是首选,因为批次中覆盖了更多模式,这可以防止G从批次中的任何单个主导模式中大量学习并成为模式崩溃的牺牲品。
3.提前停止:GAN训练总是会波动的,一个常见的错误是在G损失开始发散时(特别是在训练初期)过早停止训练。不要使用基于启发式的提前停止,而是跟踪评估指标以查找模式崩溃或消失梯度,并根据观察到的行为重新开始训练。
要点:
- 学习率:用不同的LR训练G和D,G的LR最好低于D。
- 批量大小:首选较大的批量大小,以涵盖小批量中的更多模式。
- 提前停止:不要使用基于启发式的提前停止,而是跟踪评估指标以查找模式崩溃或消失梯度,并根据观察到的行为重新开始训练
这将我们带到该系列的第二个博客的结尾。在这一部分中,我们深入探讨了第 1 部分中讨论的 GAN 不稳定性的潜在解决方案。请注意,建议的解决方案排名列表基于我们的经验和实验,但可能会因您的特定用例而异。
在本系列的下一部分也是最后一部分中,我们将探讨时空数据的特殊情况。我们将首先讨论在训练期间要跟踪的客观评估指标,以检测一些讨论的陷阱。最后,我们将阐明一些在时空数据训练中特别出现的不稳定性以及它们的潜在解决方案。
四、引用
奥古斯都·奥德纳 克里斯托弗·奥拉,乔纳森·施伦斯使用辅助分类器 GAN 的条件图像合成 [期刊].— 2016.
伊恩·古德费罗 让·普盖特-阿巴迪、迈赫迪·米尔扎、徐冰、大卫·沃德-法利、谢吉尔·奥扎尔、亚伦·库尔维尔、约书亚·本吉奥生成对抗网络[期刊].— [s.l.] : 神经信息处理系统进展, 2014.
马里奥·卢西奇·卡罗尔·库拉赫、马尔钦·米哈尔斯基、西尔万·盖利、奥利维尔·布斯凯GAN 生而平等吗?一项大规模的研究[期刊]。— [s.l.] : 神经信息处理系统国际会议, 2018.
蒂姆·萨利曼斯 伊恩·古德费罗, 沃伊切赫·扎伦巴, 张薇琪, 亚历克·拉德福德, 陈曦, 陈曦改进的 GAN 训练技术 [期刊]。— [s.l.] : 神经信息处理系统进展, 2016.
关于作者:Shantanu是ZS卓越中心实验室的AI研究科学家。他在阿姆斯特丹大学获得了计算机科学工程学士学位和人工智能硕士学位(优等生),他的论文是几何深度学习和NLP的交叉点,与伦敦的Facebook AI和伦敦国王学院合作。他的研究领域包括图神经网络(GNN),NLP,多模态AI,深度生成模型和元学习。尚塔努·钱德拉