本文翻译自:Life of a Packet in Kubernetes — Part 3 [1], 作者:Dinesh Kumar Ramasamy,本文在原文的基础上做了适当的修改,如有疑问请查阅原文。
本文是 Kubernetes 中数据包的生命周期系列文章的第 3 部分。我们将讨论 Kubernetes 的 kube-proxy 组件如何使用 iptables 来控制流量。 了解 kube-proxy 在 Kubernetes 环境中的作用以及它如何使用 iptables 来控制流量非常重要。
本文包含以下章节:
- 1.Pod-to-Pod
- 2.Pod-to-External
- 3.Pod-to-Service
- 4.NodePort(External-to-Pod)
- 5.External Traffic Policy
- 6.Kube-Proxy
- 7.iptables 规则处理流程
- 8.Headless Service
- 9.Network Policy
1 Pod-to-Pod
kube-proxy 不会参与 Pod 之间的通信,因为 CNI 会为 Node 和 Pod 配置所需的路由。所有容器都可以在没有 NAT 的情况下与其他容器进行通信。所有节点都可以在没有 NAT 的情况下与容器通信(反之亦然)。
注意:Pod 的 IP 地址不是静态的(静态 IP 有多种配置方式,但默认配置不保证静态 IP 地址)。当 Pod 重启时,CNI 会为 Pod 分配一个新的 IP 地址,因为 CNI 不会维护 Pod 和 IP 地址之间的映射关系。另外,通过 Deployment 方式部署的 Pod 的名字也不是静态的。
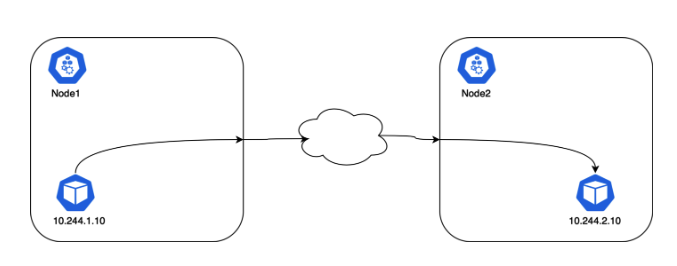
实际上,通过 Deployment 部署的 Pod 应该使用负载均衡类型的实体来发布服务,因为应用程序是无状态的,并且通常会有多个 Pod 托管应用程序。负载均衡器类型的实体在 Kubernetes中称为 Service。
2 Pod-to-external
对于从 Pod 到外部地址的流量,Kubernetes 使用 SNAT(源地址转换)。它所做的是将 Pod IP:Port 替换为主机 IP:Port。当返回的数据包到主机时,主机会修改数据包中的目标 IP 和端口为 Pod IP:Port,并将数据包发回原始的 Pod。整个过程对原始 Pod 是透明的,Pod 并不知道发生了地址转换。
3 Pod-to-Service
Kubernetes 中有一个叫做 Service 的概念,它是 Pod 前面的 L4 负载均衡器。在 Kubernetes 中有几种不同类型的 Service,最基本的类型称为 ClusterIP。这种类型的 Service 有一个唯一的 VIP 地址,只能在集群内部路由。
仅仅通过 Pod IP 将流量发送到特定的应用程序并不容易。Kubernetes 集群的动态特性意味着 Pod 可以被移动,重启,升级或者扩缩容。此外,一些服务会有很多副本,因此我们需要一些方法来平衡它们之间的负载。
Kubernetes 通过 Service 解决了这个问题。Service 是一个 API 对象,它将单个虚拟 IP(VIP)映射到一组 Pod IP。此外,Kubernetes 还为每个 Service 的 VIP 提供了 DNS 的解析条目,以便可以轻松通过域名来访问 Service。
集群内 VIP 到 Pod IP 的映射由每个节点上的 kube-proxy 进程协调。kube-proxy 通过设置 iptables 或者 IPVS 规则将目的地址是 Service VIP 的请求转换为 Pod IP。请求建立的连接会被追踪,因此数据包从 Pod 返回时可以正确地转换为 Service 的 VIP 再响应客户端。IPVS 和 iptables 可以将单个 Service 的 VIP 负载均衡到多个 Pod IP,IPVS 和 iptables 相比有着更好的性能和更灵活的负载均衡算法。
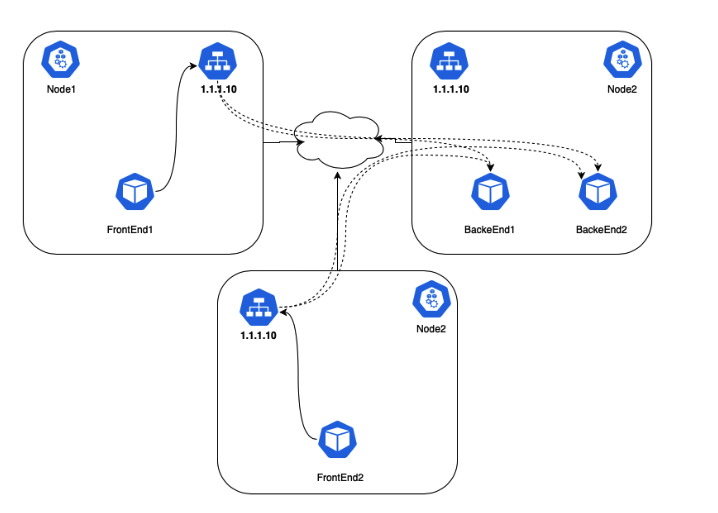 接下来创建 FrontEnd 和 Backend 两个 Deployment,并通过 ClusterIP 类型的 Service 作为负载均衡。
接下来创建 FrontEnd 和 Backend 两个 Deployment,并通过 ClusterIP 类型的 Service 作为负载均衡。
FrontEnd Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
labels:
app: webapp
spec:
replicas: 2
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
Backend Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: auth
labels:
app: auth
spec:
replicas: 2
selector:
matchLabels:
app: auth
template:
metadata:
labels:
app: auth
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
Service:
---
apiVersion: v1
kind: Service
metadata:
name: frontend
labels:
app: frontend
spec:
ports:
- port: 80
protocol: TCP
type: ClusterIP
selector:
app: webapp
---
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
app: backend
spec:
ports:
- port: 80
protocol: TCP
type: ClusterIP
selector:
app: auth
现在 FrontEnd Pod 可以通过 ClusterIP 或者 Kubernetes 添加的 DNS 条目访问 Backend。一个集群感知的 DNS 服务器,例如 CoreDNS,监视 Kubernetes API 获取新创建的服务,并为每个服务创建一组 DNS 记录。
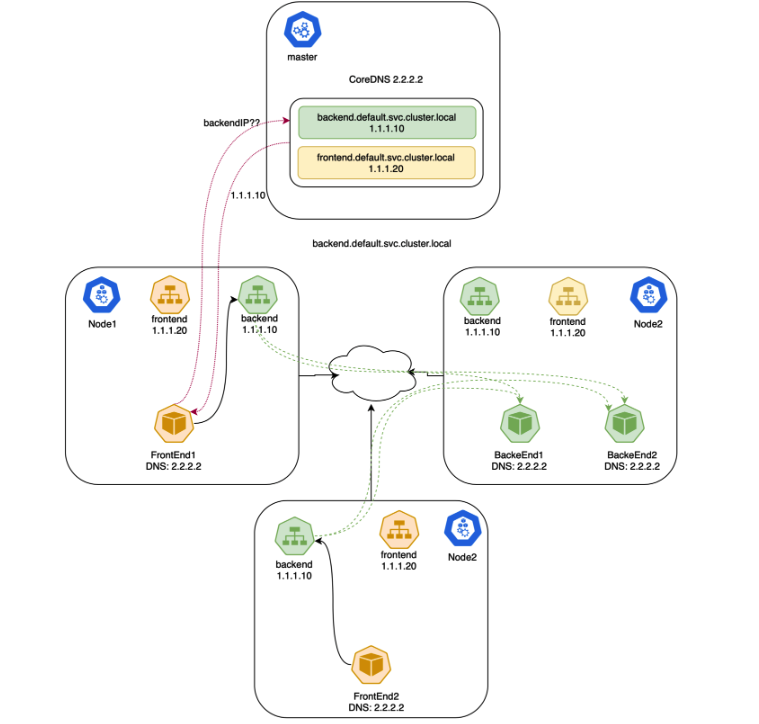
“普通“服务(除了无头服务)会以
your-svc.your-namespace.svc.cluster.local这种名字的形式分配一个 DNS 记录。 该名称会解析成对应 Service 的 ClusterIP。
4 NodePort(External-to-Pod)
现在我们可以在集群内部通过 VIP 或者域名访问 Service。然而,由于 VIP 是虚拟和私有的,此时外部请求还无法到达集群内的 Service。
让我们创建一个 NodePort 类型的服务将 FrontEnd 服务暴露到集群外部。如果将 Service 的 type 字段设置为 NodePort 时,Kubernetes 会为该服务分配一个随机端口。端口的默认范围是 30000-32767,可以通过 API Server 的 --service-node-port-range 参数进行设置。每个节点会将访问 nodePort 端口(每个端口号相同)的请求代理到你的 Service。
---
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort # 将 Service 设置为 NodePort 类型
selector:
app: webapp
ports:
# By default and for convenience, the `targetPort` is set to the same value as the `port` field.
- port: 80
targetPort: 80
# Optional field
# By default and for convenience, the Kubernetes control plane will allocate a port from a range (default: 30000-32767)
nodePort: 31380 # 指定端口
...
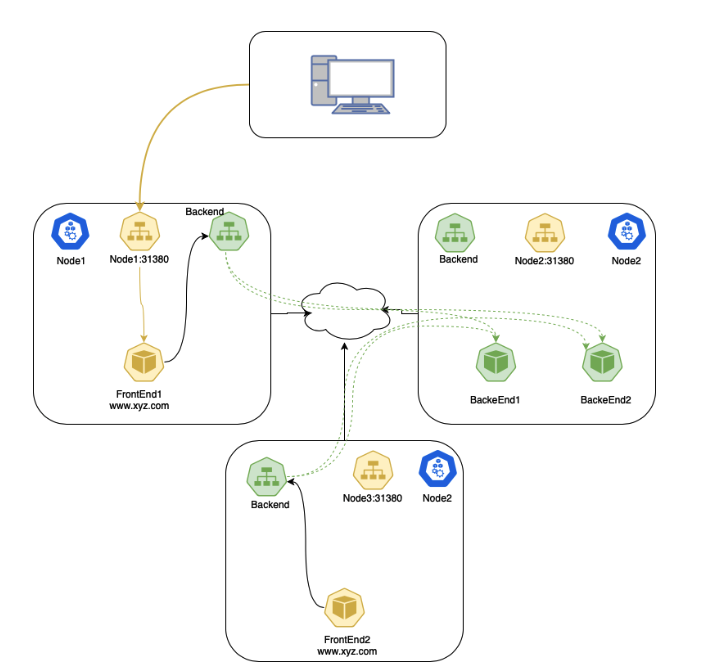
现在我们可以在集群外部通过 <任何一个节点 IP>:<nodePort 端口> 访问 FrontEnd Service 了。如果你需要指定特定的端口号,那么可以在 nodePort 字段中进行设置。这意味着你需要自己处理可能的端口冲突,同时你还必须使用一个有效的端口号,当设置的 nodePort 冲突或超过范围时,API Server 会返回错误信息。
5 External Traffic Policy
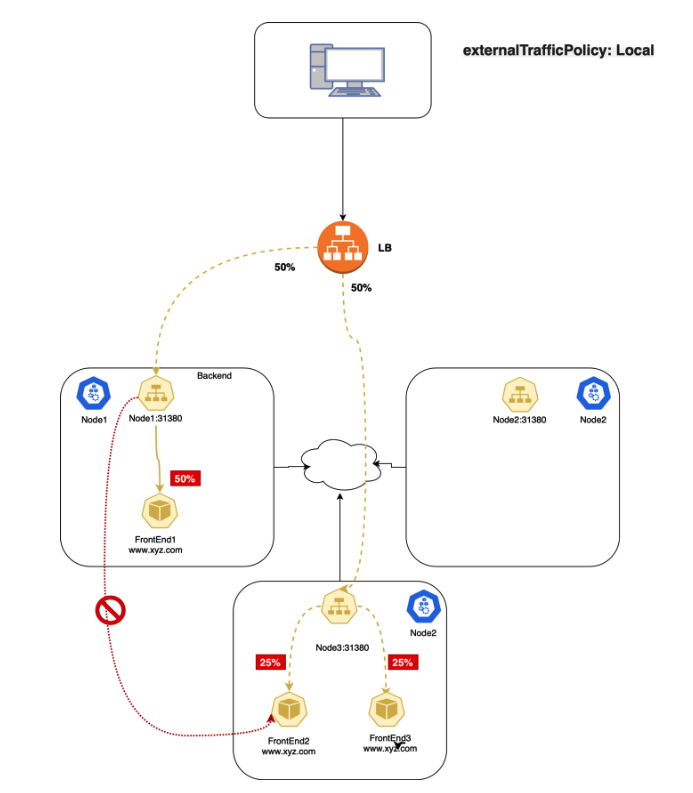
ExternalTrafficPolicy 表示该 Service 是否希望将外部流量路由到节点本地或集群范围的端点。Local 表示保留客户端的源 IP,并且 NodePort 或者 LoadBalancer 类型的 Service 将不会把流量分发到其他节点上的 Pod,这样可以避免产生额外的网络跳数,与此同时可能会存在流量传播不平衡的风险。Cluster 隐藏了客户端的源 IP,并且可能会将流量分发到其他节点上的 Pod, 此时会产生额外的网络跳数,但这样会具有良好的整体负载均衡。
5.1 Cluster Traffic Policy
Cluster Traffic Policy 是 Kubernetes Service 默认的 ExternalTrafficPolicy 策略。这里假设的是,你总是希望将流量平衡地路由到 Service 下的所有 Pod。
使用此策略的一个注意事项是,当外部流量访问 NodePort Service 时,你可能会在节点之间看到不必要的网络跃点。例如,当通过 NodePort 接收外部流量,NodePort Service 可能会(随机)将流量路由到另一台主机上的 Pod,而它本来可以将流量路由到同一主机上的 Pod,从而避免额外的网络跳数。
Cluster Traffic Policy 中数据包的流量如下:
- 客户端发送数据包到
Node2:3138。 Node2将数据包的目标 IP 通过 DNAT(目标地址)转换为 Pod IP。Node2将数据包的源 IP 通过 SNAT(源地址转换)转换为Node2自身的 IP。- 数据包路由到 Node1 或者 Node3,然后交给节点上的 Pod。
- Pod 的响应回到
Node2,源 IP 是 Pod IP,目标 IP 是Node2的 IP。 Node2将 Pod 返回数据包的源 IP 修改为Node2的 IP,目标 IP 修改为客户端的 IP,然后响应客户端。

5.2 Local Traffic Policy
当使用 Local Traffic Policy 策略时,kube-proxy 将仅为同一节点(本地)上的 Pod 添加代理规则,而不是为 Service 的每个 Pod 添加代理规则。此时 kube-proxy 只会将请求代理到本地端点,而不会将流量转发到其他节点。这样可以保留原始的源 IP 地址。 如果没有本地端点,则丢弃发送到节点的数据包。
如果你尝试在 Serivce 上设置 externalTrafficPolicy: Local,Kubernetes API 将要求你使用 LoadBalancer 或 NodePort 类型的 Service。这是因为 Local 模式的 ExternalTrafficPolicy 策略仅与外部流量相关,因此只适用于这两种类型的 Service。
---
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort
externalTrafficPolicy: Local # 仅转发到本地 Pod,保留客户端源 IP
selector:
app: webapp
ports:
# By default and for convenience, the `targetPort` is set to the same value as the `port` field.
- port: 80
targetPort: 80
# Optional field
# By default and for convenience, the Kubernetes control plane will allocate a port from a range (default: 30000-32767)
nodePort: 31380
...
Local Traffic Policy 中数据包的流量如下:
- 客户端发送数据包到
Node1:31380,该节点上有 FrontEnd 的 Pod。 - Node1 将数据包路由到本地的 Pod,保留正确的源 IP。
- 由于设置了 Local 的转发策略,因此 Node1 不会将数据包路由到 Node3。
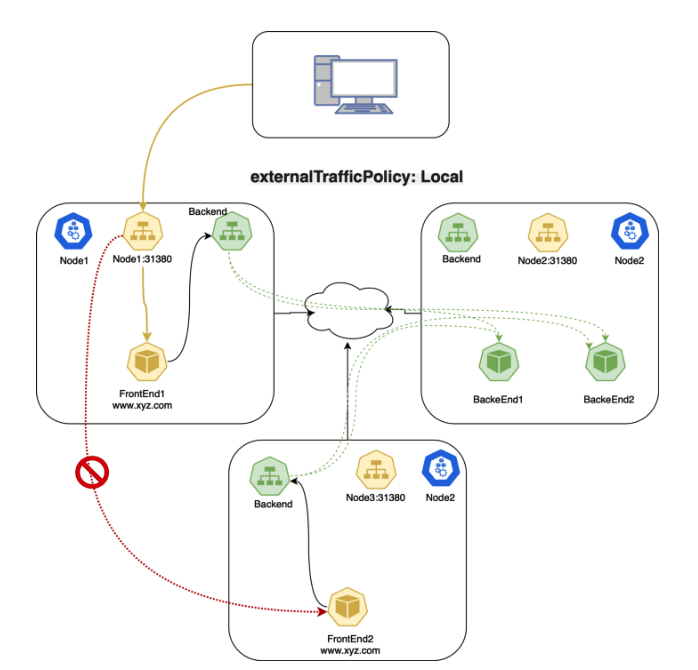
- 客户端发送数据包到
Node2:31380,该节点上没有 FrontEnd 的 Pod。 - 数据包将会被 Node2 丢弃。
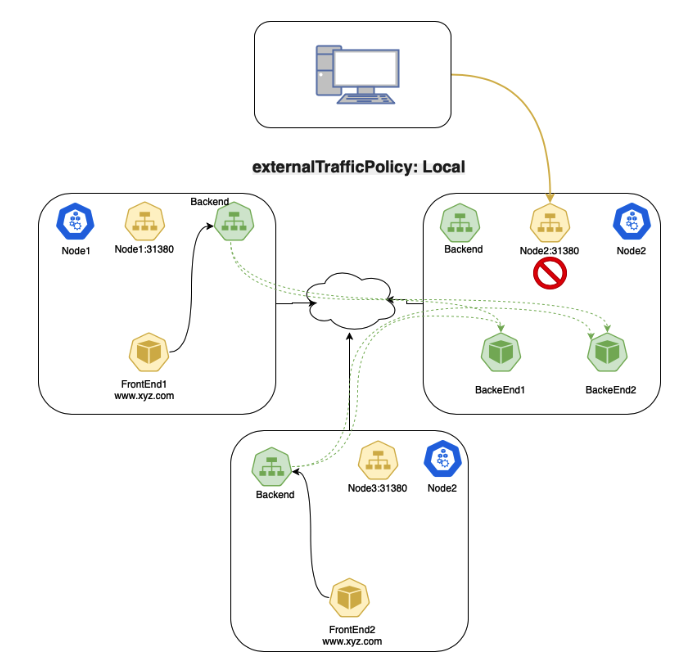
5.3 Local traffic policy in LoadBalancer Service type
当你将公有云的 Kubernetes 服务(例如 Google Kubernetes Engine,GCE)中的 Service 设置为 externalTrafficPolicy: Local 时,如果节点中没有 Service 对应的 Pod,将不会通过负载均衡器(LB)的健康检查而被移出转发列表,在这种情况下不会发生数据包的丢弃。这种模式非常适合有大量的入访流量,同时希望避免网络上不必要的跃点以减少延迟的应用程序。同时我们还可以保留真正的客户端 IP,因为我们不再需要来自代理节点的 SNAT 流量!然而,正如 Kubernetes 文档中提到的,使用 Local traffic policy 策略的最大缺点是应用程序的流量可能不平衡。
6 Kube-Proxy (iptable mode)
Kubernetes 中实现 Service 的组件称为 kube-proxy。它位于每个节点上,编写复杂的 iptables 规则以在 Pod 和 Service 之间进行各种过滤和 NAT。如果你到 Kubernetes 节点上执行 iptables-save 命令,你将能够看到 Kubernetes 或者其他程序插入的 iptables 规则。其中最重要的链是 KUBE-SERVICES, KUBE-SVC-* 和 KUBE-SEP-*。
KUBE-SERVICES链是访问 Service 的入口,它的作用是匹配目标 IP:Port 并将数据包分发到相应的KUBE-SVC-*链。KUBE-SVC-*链充当负载均衡器(Service),将数据包平均分配到KUBE-SEP-*链。每个KUBE-SVC-*链中含有与其后面端点数量相同的KUBE-SEP-*链。KUBE-SEP-*链代表一个服务端点(Pod),它只做 DNAT,将 Service 的 IP:Port 替换为 Pod 的 IP:Port。
对于 DNAT,conntrack 会跟踪连接状态,因为它需要记住修改的目标地址,以便数据包返回时将其更改回来。iptables 还可以依靠 conntrack 状态 (ctstate) 来决定数据包的命运。这 4 个 conntrack 状态尤其重要:
- NEW:一个连接的初始状态(例如:TCP 连接中,一个 SYN 包的到来)。
- ESTABLISHED:连接已经建立完成。
- RELATED:这是一个关联连接,是一个主链接的子连接,例如 FTP 的数据通道的连接。
- INVALID:这是一个特殊的状态,用于记录那些没有按照预期行为进行的连接。
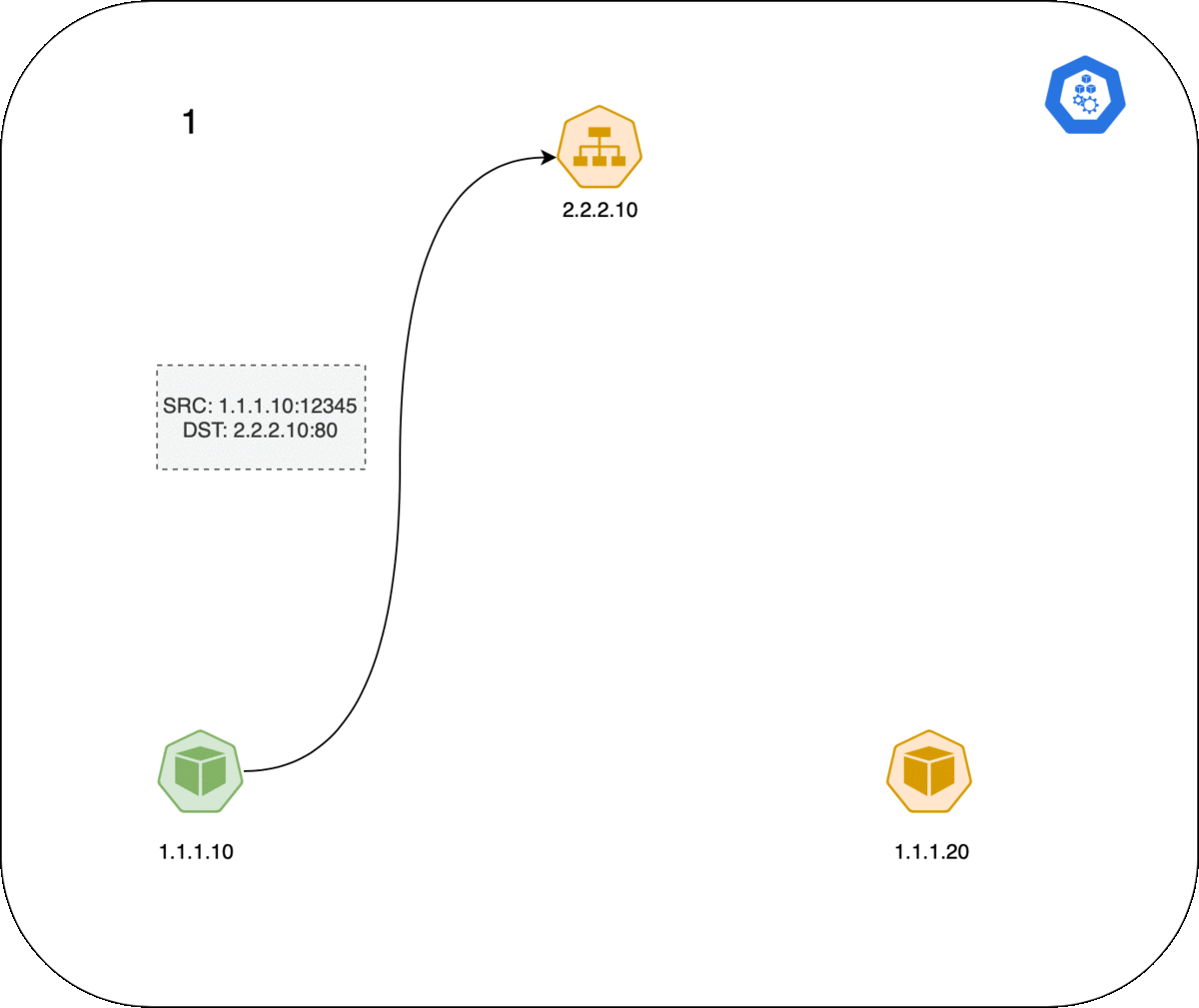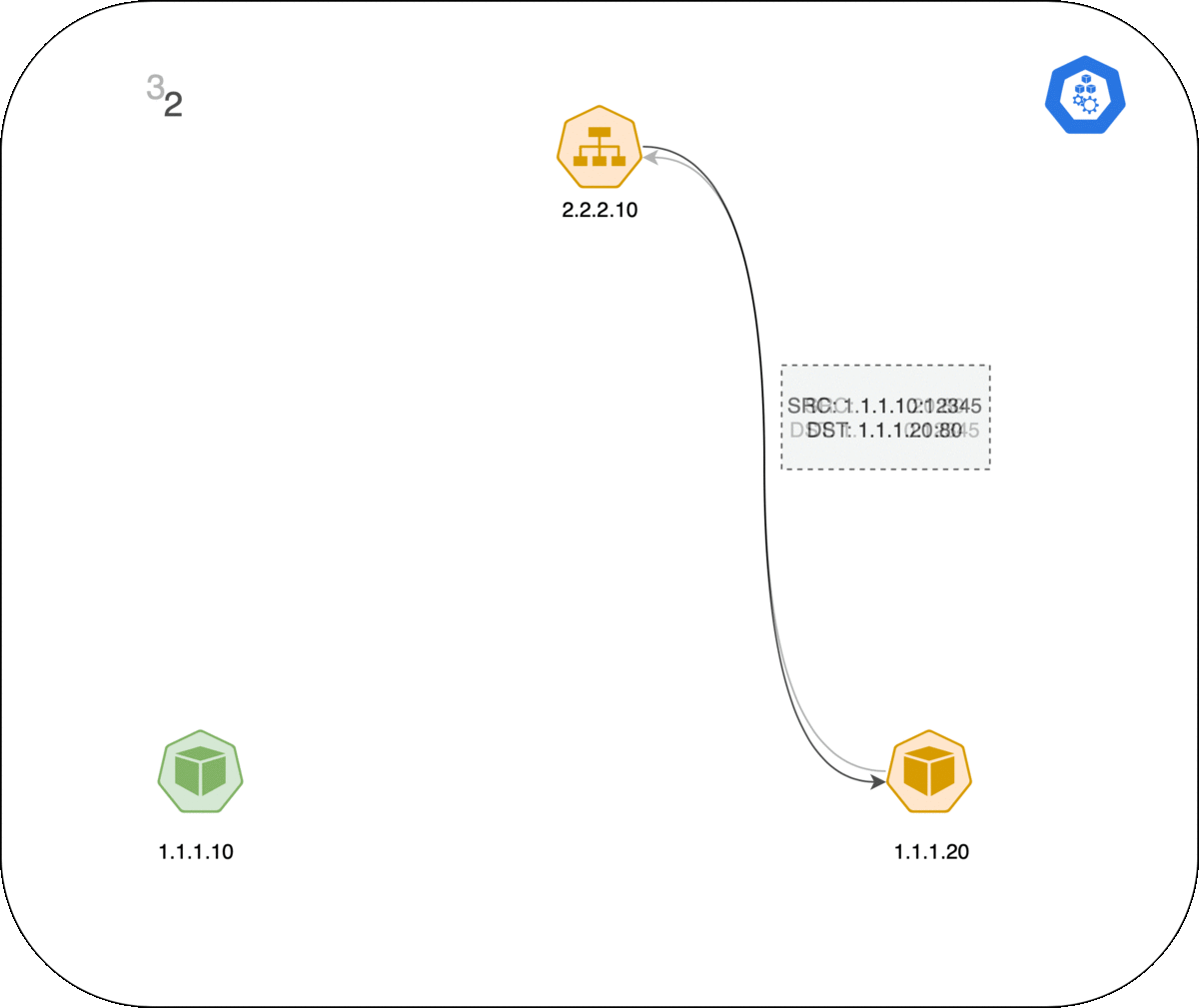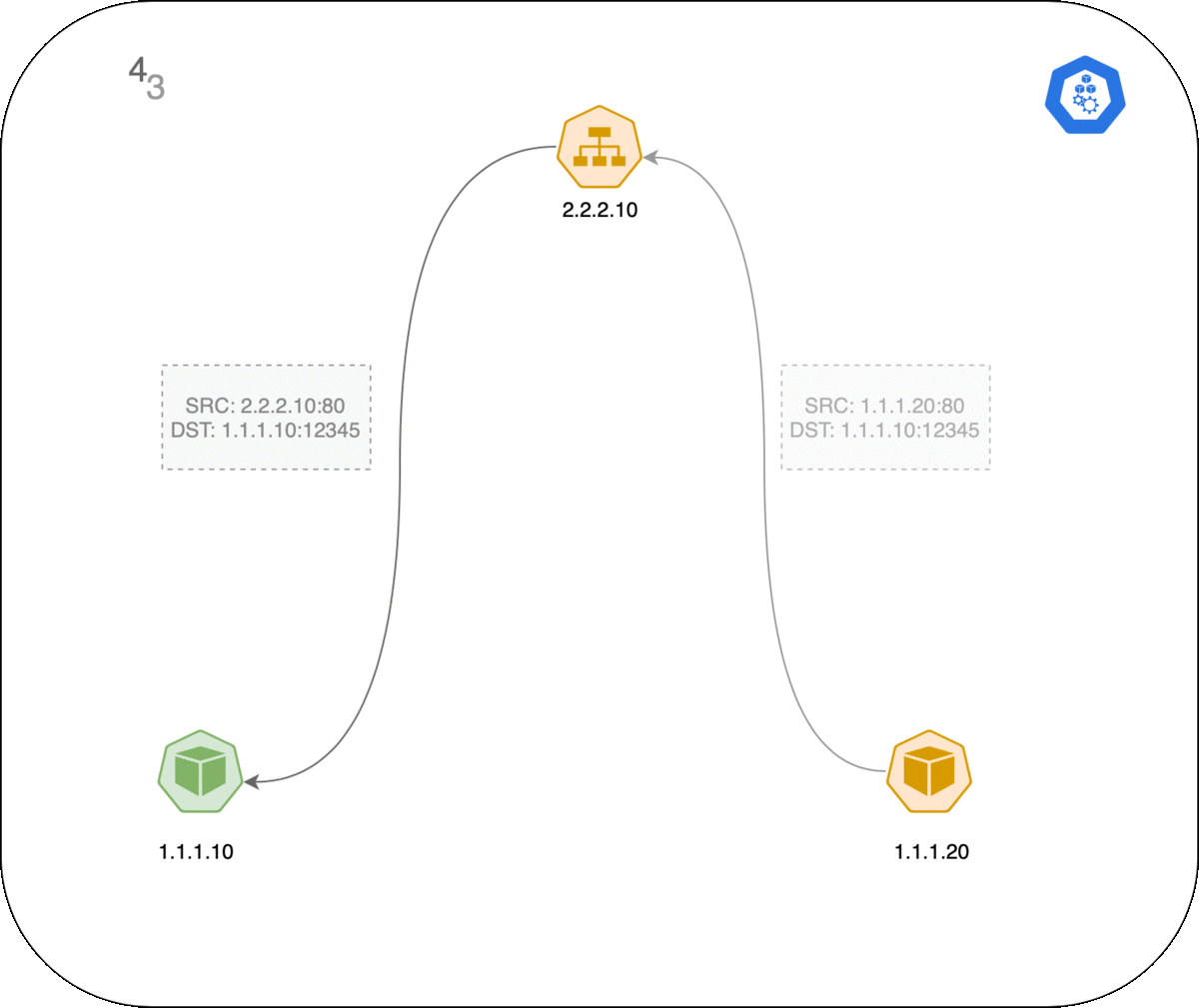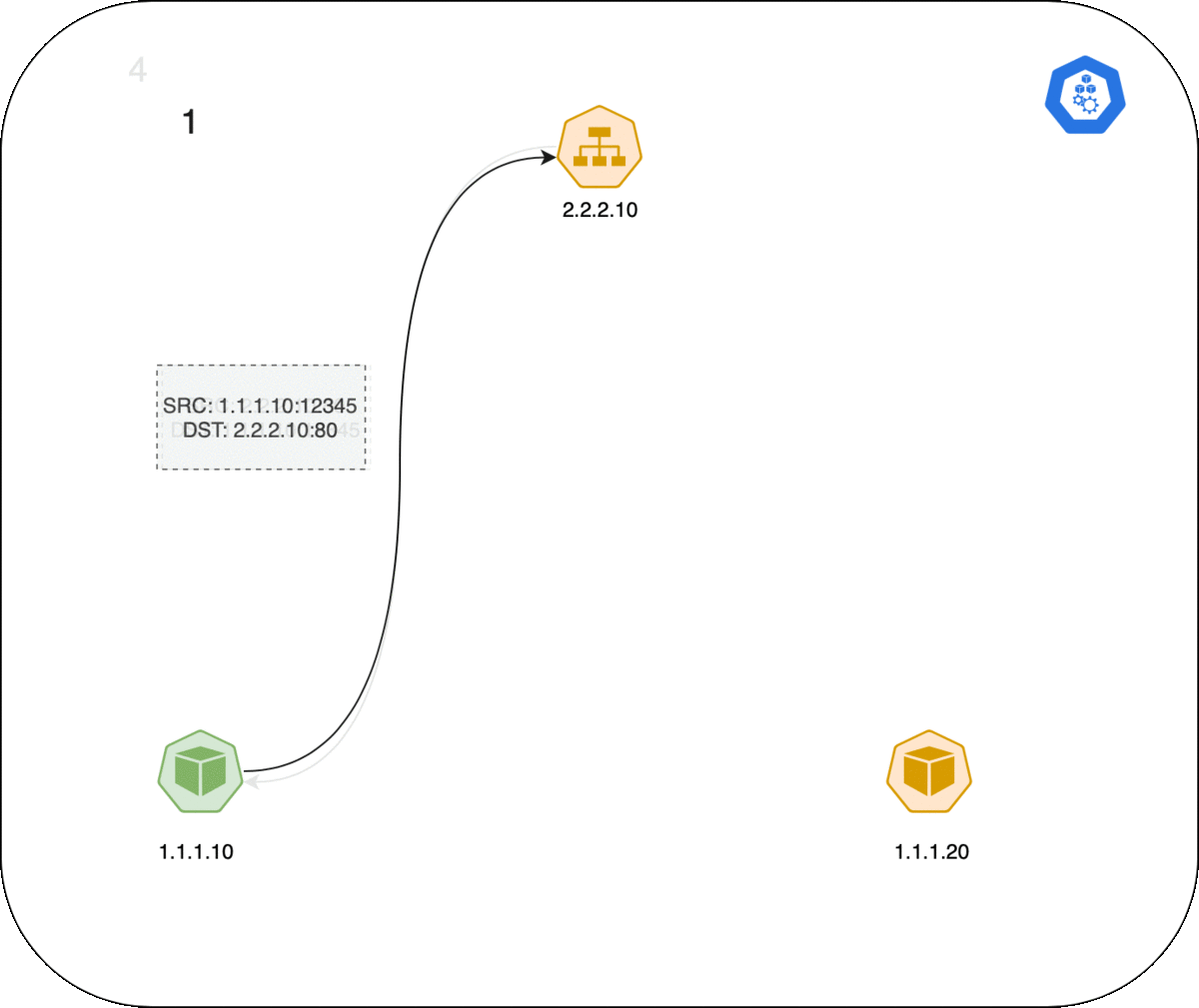
以下是 Pod 和 Service 之间连接的工作方式,事件的顺序如下:
- 左侧的客户端 Pod 向 Service 2.2.2.10:80 发送数据包。
- 数据包在客户端节点经过 iptables 规则,目的 IP 被更改为服务端 Pod IP(1.1.1.20:80)。
- 数据包返回客户端节点,conntrack 识别到数据包并将源地址重写回 2.2.2.2:80。
- 客户端 Pod 收到响应数据包。
GIF 动图演示:
7 Iptables 规则处理流程
netfilter 是 Linux 内核中一个对数据包进行控制、修改和过滤的框架。iptables 是配置 netfilter 过滤功能的用户空间工具。
7.1 Chains 链
iptables 中有 5 条链,每条链负责一个特定的任务:
- PREROUTING:在数据包做路由选择前应用此链路中的规则,所有的数据包进来时都先由这条链处理。
- INPUT:经过路由表判断后,目的为本机的数据包应用这条链上的策略。
- FORWARD:经过路由表判断后,目标地址不为本机,转发数据包时应用这条链上的策略。
- OUTPUT:由本机产生的往外发送的数据包应用这条链中的策略。
- POSTROUTING:数据包发送到网卡之前应用这条链中的策略,所有的数据包出来的时候都由这条链处理。

- 进入的数据包目的是本机:
PREROUTING -> INPUT。 - 进入的数据包目的是其他主机:
PREROUTING -> FORWARD -> POSTROUTING。 - 本机产生的数据包:
OUTPUT -> POSTROUTING。
FORWARD 链仅当 Linux 服务器中启用 ip_forward 时才有效,这就是以下命令在设置和调试 Kubernetes 集群时很重要的原因。
node-1# sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
node-1# cat /proc/sys/net/ipv4/ip_forward
1
上述命令的修改不是永久的,要在 Linux 系统上永久启用 IP 转发,请编辑 /etc/sysctl.conf 并添加以下内容:
net.ipv4.ip_forward = 1
7.2 Tables 表
iptables 中有 5 种表:
- Filter:这是默认的表,用于过滤数据包。
- NAT:网络地址转换(端口映射、地址映射等)。
- Mangle:主要功能是根据规则修改数据包的一些标志位,以便其他规则或程序可以利用这些标志对数据包进行过滤或策略路由。
- Raw:设置 RAW 表时一般是为了不再让 iptables 做数据包的链接跟踪处理,以提高性能。
- Security:用于在数据包上设置内部 SELinux 安全上下文标记。
7.3 Kubernetes 中的 iptables 配置
让我们在 Kubernetes 中部署一个副本数为 2 的 Nginx 应用程序并查看 iptables 规则。Service 类型:NodePort。
master # kubectl get svc webapp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp NodePort 10.103.46.104 <none> 80:31380/TCP 3d13h
master # kubectl get ep webapp
NAME ENDPOINTS AGE
webapp 10.244.120.102:80,10.244.120.103:80 3d13h
ClusterIP 在主机的接口上并不存在,它的虚拟 IP 存在于 iptables 规则中,在 CoreDNS 中添加了下面这个 DNS 条目。
master # kubectl exec -i -t dnsutils -- nslookup webapp.default
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: webapp.default.svc.cluster.local
Address: 10.103.46.104
Kubernetes 在 iptables 中创建了 KUBE-SERVICES 链以便对数据包进行过滤和 NAT。它将会把所有 PREROUTING 和 OUTPUT 链的流量重定向到 KUBE-SERVICES 链上。
$ sudo iptables -t nat -L PREROUTING | column -t
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
cali-PREROUTING all -- anywhere anywhere /* cali:6gwbT8clXdHdC1b1 */
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
在将 KUBE-SERVICES 链用于包过滤和 NAT 后,Kubernetes 可以检查到 Service 的流量并相应地应用 SNAT/DNAT。在 KUBE-SERVICES 链的末端,它将插入另一个自定义链 KUBE-NODEPORTS 来处理 Service 类型是 NodePort 的流量。
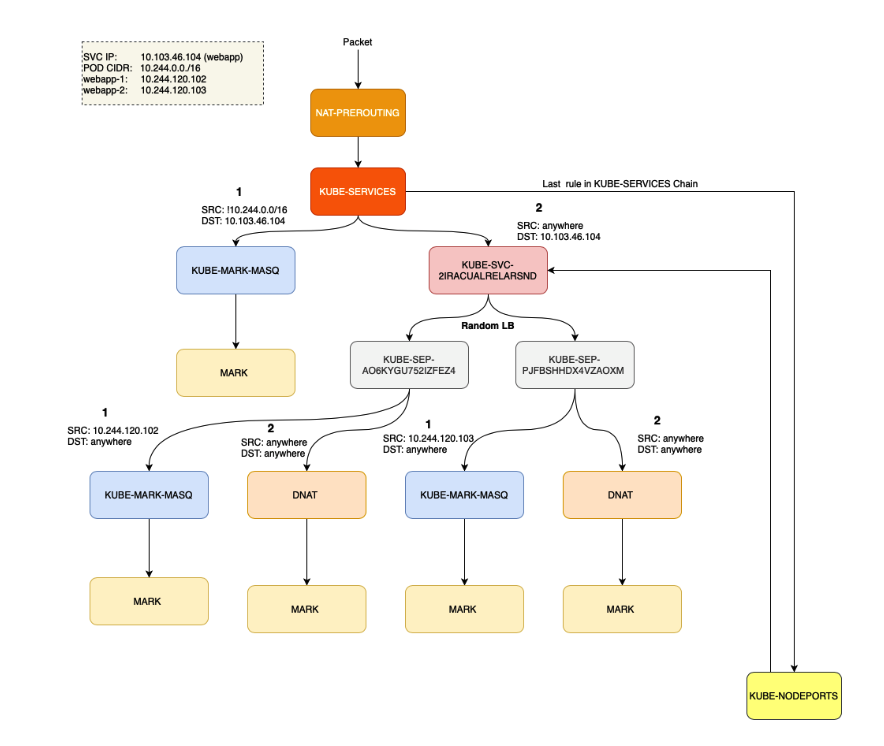
如果流量是针对 ClusterIP 的,KUBE-SVC-2IRACUALRELARSND 链会处理流量;否则,下一条链将处理流量,即 KUBE-NODEPORTS。
$ sudo iptables -t nat -L KUBE-SERVICES | column -t
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.103.46.104 /* default/webapp cluster IP */ tcp dpt:www
KUBE-SVC-2IRACUALRELARSND tcp -- anywhere 10.103.46.104 /* default/webapp cluster IP */ tcp dpt:www
KUBE-NODEPORTS all -- anywhere anywhere /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
让我们查看一下 KUBE-NODEPORTS 链。
$ sudo iptables -t nat -L KUBE-NODEPORTS | column -t
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- anywhere anywhere /* default/webapp */ tcp dpt:31380
KUBE-SVC-2IRACUALRELARSND tcp -- anywhere anywhere /* default/webapp */ tcp dpt:31380
可以看到 KUBE-NODEPORTS 链最终也会将流量送到 KUBE-SVC-2IRACUALRELARSND 链。
# statistic mode random -> Random load-balancing between endpoints.
# Service 的流量随机分发给两个 Pod
$ sudo iptables -t nat -L KUBE-SVC-2IRACUALRELARSND | column -t
Chain KUBE-SVC-2IRACUALRELARSND (2 references)
target prot opt source destination
# Pod1
KUBE-SEP-AO6KYGU752IZFEZ4 all -- anywhere anywhere /* default/webapp */ statistic mode random probability 0.50000000000
# Pod2
KUBE-SEP-PJFBSHHDX4VZAOXM all -- anywhere anywhere /* default/webapp */
# 流量分发到 Pod1
$ sudo iptables -t nat -L KUBE-SEP-AO6KYGU752IZFEZ4 | column -t
Chain KUBE-SEP-AO6KYGU752IZFEZ4 (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- 10.244.120.102 anywhere /* default/webapp */
DNAT tcp -- anywhere anywhere /* default/webapp */ tcp to:10.244.120.102:80
# 流量分发到 Pod2
$ sudo iptables -t nat -L KUBE-SEP-PJFBSHHDX4VZAOXM | column -t
Chain KUBE-SEP-PJFBSHHDX4VZAOXM (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- 10.244.120.103 anywhere /* default/webapp */
DNAT tcp -- anywhere anywhere /* default/webapp */ tcp to:10.244.120.103:80
# 源地址转换
$ sudo iptables -t nat -L KUBE-MARK-MASQ | column -t
Chain KUBE-MARK-MASQ (24 references)
target prot opt source destination
MARK all -- anywhere anywhere MARK or 0x4000
总结一下: ClusterIP: KUBE-SERVICES → KUBE-SVC-XXX → KUBE-SEP-XXX。 NodePort: KUBE-SERVICES → KUBE-NODEPORTS → KUBE-SVC-XXX → KUBE-SEP-XXX。
注意:NodePort 类型的 Service 将分配一个 ClusterIP 来处理内部和外部流量。
上述规则的示意图如下:
 ExtrenalTrafficPolicy: Local 如前所述,使用 externalTrafficPolicy: Local 将保留源 IP 并丢弃没有本地端点的数据包。让我们来看看没有本地端点的节点中的 iptables 规则。
ExtrenalTrafficPolicy: Local 如前所述,使用 externalTrafficPolicy: Local 将保留源 IP 并丢弃没有本地端点的数据包。让我们来看看没有本地端点的节点中的 iptables 规则。
master # kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 6d1h v1.19.2
minikube-m02 Ready <none> 85m v1.19.2
这次只部署 1 个 Nginx Pod,Service 设置为 externalTrafficPolicy: Local。
master # kubectl get pods nginx-deployment-7759cc5c66-p45tz -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-7759cc5c66-p45tz 1/1 Running 0 29m 10.244.120.111 minikube <none> <none>
检查 externalTrafficPolicy。
master # kubectl get svc webapp -o wide -o jsonpath={.spec.externalTrafficPolicy}
Local
获取 Service。
master # kubectl get svc webapp -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
webapp NodePort 10.111.243.62 <none> 80:30080/TCP 29m app=webserver
让我们检查 minikube-m02 节点中的 iptables 规则,应该有一个 DROP 规则来丢弃数据包,因为该节点上没有 Nginx Pod。
$ sudo iptables -t nat -L KUBE-NODEPORTS
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp — 127.0.0.0/8 anywhere /* default/webapp */ tcp dpt:30080
KUBE-XLB-2IRACUALRELARSND tcp — anywhere anywhere /* default/webapp */ tcp dpt:30080
检查 KUBE-XLB-2IRACUALRELARSND 链。
$ sudo iptables -t nat -L KUBE-XLB-2IRACUALRELARSND
Chain KUBE-XLB-2IRACUALRELARSND (1 references)
target prot opt source destination
KUBE-SVC-2IRACUALRELARSND all — 10.244.0.0/16 anywhere /* Redirect pods trying to reach external loadbalancer VIP to clusterIP */
KUBE-MARK-MASQ all — anywhere anywhere /* masquerade LOCAL traffic for default/webapp LB IP */ ADDRTYPE match src-type LOCAL
KUBE-SVC-2IRACUALRELARSND all — anywhere anywhere /* route LOCAL traffic for default/webapp LB IP to service chain */ ADDRTYPE match src-type LOCAL
# 丢弃没有本地端点的数据包
KUBE-MARK-DROP all — anywhere anywhere /* default/webapp has no local endpoints */
查看 minikube 节点的 iptables,该节点上有 Nginx Pod,因此不会丢弃数据包。
# NodePort 规则
$ sudo iptables -t nat -L KUBE-NODEPORTS
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp — 127.0.0.0/8 anywhere /* default/webapp */ tcp dpt:30080
KUBE-XLB-2IRACUALRELARSND tcp — anywhere anywhere /* default/webapp */ tcp dpt:30080
# 不会丢弃数据包,最后没有 DROP 规则
$ sudo iptables -t nat -L KUBE-XLB-2IRACUALRELARSND
Chain KUBE-XLB-2IRACUALRELARSND (1 references)
target prot opt source destination
KUBE-SVC-2IRACUALRELARSND all — 10.244.0.0/16 anywhere /* Redirect pods trying to reach external loadbalancer VIP to clusterIP */
KUBE-MARK-MASQ all — anywhere anywhere /* masquerade LOCAL traffic for default/webapp LB IP */ ADDRTYPE match src-type LOCAL
KUBE-SVC-2IRACUALRELARSND all — anywhere anywhere /* route LOCAL traffic for default/webapp LB IP to service chain */ ADDRTYPE match src-type LOCAL
KUBE-SEP-5T4S2ILYSXWY3R2J all — anywhere anywhere /* Balancing rule 0 for default/webapp */
# Service 规则,将流量分发到 Pod
$ sudo iptables -t nat -L KUBE-SVC-2IRACUALRELARSND
Chain KUBE-SVC-2IRACUALRELARSND (3 references)
target prot opt source destination
KUBE-SEP-5T4S2ILYSXWY3R2J all — anywhere anywhere /* default/webapp */
8 Headless Service
有的应用并不需要负载均衡和服务 IP。在这种情况下就可以使用 Headless Service,只要设置 .spec.clusterIP 为 None 即可。
可以借助这种服务类型和其他服务发现机制协作,无需和 Kubernetes 绑定。Headless Service 并不会分配 Cluster IP,kube-proxy 不会处理它们, 而且平台也不会为它们进行负载均衡和路由。 另外,DNS 的配置要根据 selector 来确定。
带选择器(selector)的服务
定义了 selector 的 Headless Service,Endpoint 控制器会创建 Endpoints 记录, 并修改 DNS 记录,通过域名可以直接访问 Service 的后端 Pod 。
master # kubectl get svc webapp-hs
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp-hs ClusterIP None <none> 80/TCP 24s
master # kubectl get ep webapp-hs
NAME ENDPOINTS AGE
webapp-hs 10.244.120.109:80,10.244.120.110:80 31s
无选择器的服务
没有定义 selector 的 Headless Service,也就没有 Endpoint 记录。然而 DNS 系统会尝试配置:
ExternalName类型的服务,会产生CNAME记录。- 所有其他类型的服务,查找与 Service 名称相同的
Endpoints的记录。
9 Network Policy
到目前为止,你可能已经了解了 Kubernetes 中的网络策略是如何实现的。是的,又是 iptables;CNI 负责实施网络策略,而不是 kube-proxy。
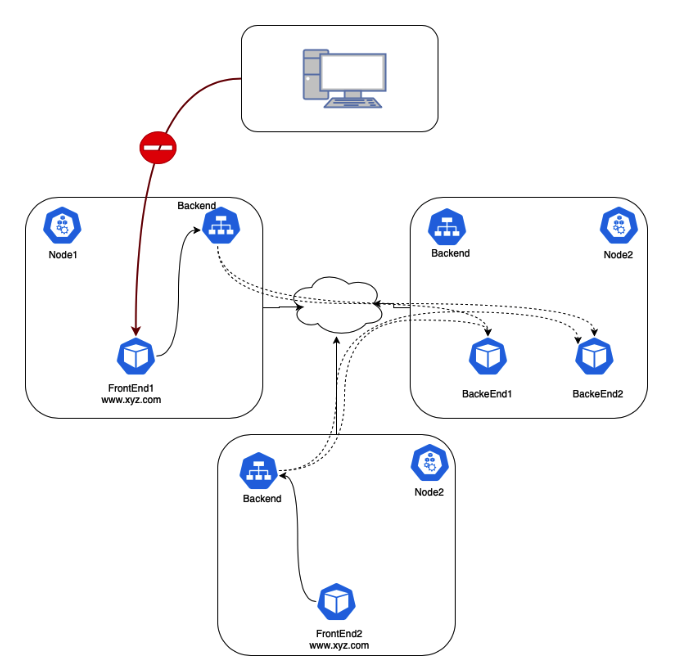
让我们创建 3 个服务:FrontEnd, Backend 和 DB。默认情况下,Pod 是非隔离的;他们接受来自任何来源的流量。
但是,应该有一个网络策略将 DB pod 与 FrontEnd pod 隔离,以避免它们之间的任何流量。

我们可以通过设置 NetworkPolicy 来实现网络策略,如果入访的 Pod 带有 networking/allow-db-access: "true" 标签,则允许访问 DB。
# 网络策略
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-db-access
spec:
podSelector: # 匹配应用策略的 Pod
matchLabels:
app: "db"
policyTypes:
- Ingress
ingress:
- from:
- podSelector: # 匹配入访 Pod
matchLabels:
networking/allow-db-access: "true"
# Backend 服务
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
labels:
app: backend
spec:
replicas: 1
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
networking/allow-db-access: "true" # 网络策略会允许有该标签的 Pod 访问 DB 服务
spec:
volumes:
- name: workdir
emptyDir: {}
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
initContainers:
- name: install
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', "echo $HOSTNAME > /work-dir/index.html"]
volumeMounts:
- name: workdir
mountPath: "/work-dir"
...
应用上面的 NetworkPolicy,可以看到 FrontEnd 可以正常访问 Backend,但是已经无法访问 DB 了。
master # kubectl exec -it frontend-8b474f47-zdqdv -- /bin/sh
# curl backend
backend-867fd6dff-mjf92
# curl db
curl: (7) Failed to connect to db port 80: Connection timed out
但是 Backend 依然可以访问 DB。
master # kubectl exec -it backend-867fd6dff-mjf92 -- /bin/sh
# curl db
db-8d66ff5f7-bp6kf
如果使用的 CNI 是 Calico,Calico 会将 Kubernetes 的网络策略转换为 Calico 的格式。
master # calicoctl get networkPolicy --output yaml
apiVersion: projectcalico.org/v3
items:
- apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
creationTimestamp: "2020-11-05T05:26:27Z"
name: knp.default.allow-db-access
namespace: default
resourceVersion: /53872
uid: 1b3eb093-b1a8-4429-a77d-a9a054a6ae90
spec:
ingress:
- action: Allow
destination: {}
source:
selector: projectcalico.org/orchestrator == 'k8s' && networking/allow-db-access
== 'true'
order: 1000
selector: projectcalico.org/orchestrator == 'k8s' && app == 'db'
types:
- Ingress
kind: NetworkPolicyList
metadata:
resourceVersion: 56821/56821
使用 calicoctl 获取工作负载端点的详细信息。
master # calicoctl get workloadEndpoint
WORKLOAD NODE NETWORKS INTERFACE
backend-867fd6dff-mjf92 minikube 10.88.0.27/32 cali2b1490aa46a
db-8d66ff5f7-bp6kf minikube 10.88.0.26/32 cali95aa86cbb2a
frontend-8b474f47-zdqdv minikube 10.88.0.24/32 cali505cfbeac50
cali95aa86cbb2a 是 DB pod 正在使用的 veth 对的主机端。我们来获取这个接口相关的 iptables 规则。从 iptables 规则中,可以看到只有数据包来着 Backend Pod 时才允许进入 DB Pod。
# Calico iptables 规则链命名
# cali-: 前缀,calico 的规则链
# tw: 简写,to wordkoad endpoint
# wl: 简写,workload endpoint
# fw: 简写,from workload endpoint
# from-XXX: XXX发出的报文
# to-XXX: 发送到XXX的报文
# pi: 简写,policy inbound
# po: 简写,policy outbound
# pri: 简写,profile inbound
# pro: 简写,profile outbound
$ sudo iptables-save | grep cali95aa86cbb2a
...
# 先检查 fw: from workload 的规则,再检查 tw: to workload 的规则,下面以 tw 的规则进行说明
# 第一步:如果 conntrack 表中能够检索到该连接的状态,可以直接根据状态放行或者丢弃
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:eCrqwxNk3cKw9Eq6" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:_krp5nzavhAu5avJ" -m conntrack --ctstate INVALID -j DROP
# 第二步:先对数据包进行标记,--set-xmark value[/mask],value 表示要匹配的 mark 的值,mask 代表掩码,如果要完全匹配可以省略掉掩码
# 如果经过 Network Policy 后 mark 值没有修改,第七步会丢弃该数据包
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:leBL64hpAXM9y4nk" -m comment --comment "Start of policies" -j MARK --set-xmark 0x0/0x20000
# 第三步(重点):进入 cali-pi-_tTE-E7yY40ogArNVgKt 链进行 Network Policy 判断
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:pm-LK-c1ra31tRwz" -m mark --mark 0x0/0x20000 -j cali-pi-_tTE-E7yY40ogArNVgKt
# 第六步:如果 Network Policy 检查通过(检查是否匹配 mark 0x10000/0x10000), 匹配说明通过,直接 RETURN,不再检查其他的规则
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:q_zG8dAujKUIBe0Q" -m comment --comment "Return if policy accepted" -m mark --mark 0x10000/0x10000 -j RETURN
# 第七步:如果 mark 没有修改,与原先一致,视为没有任何一个 Network Policy允许该包通过,丢弃数据包
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:FUDVBYh1Yr6tVRgq" -m comment --comment "Drop if no policies passed packet" -m mark --mark 0x0/0x20000 -j DROP
...
# Network Policy 规则判断
$ sudo iptables-save -t filter | grep cali-pi-_tTE-E7yY40ogArNVgKt
...
# 第四步(重点):如果源 IP 匹配 ipsetali40s:LrVD8vMIGQDyv8Y7sPFB1Ge,将数据包添加 mark 0x10000
-A cali-pi-_tTE-E7yY40ogArNVgKt -m comment --comment "cali:M4Und37HGrw6jUk8" -m set --match-set cali40s:LrVD8vMIGQDyv8Y7sPFB1Ge src -j MARK --set-xmark 0x10000/0x10000
# 第五步:检查是否匹配 mark,如果匹配就 RETURN 放行
-A cali-pi-_tTE-E7yY40ogArNVgKt -m comment --comment "cali:sEnlfZagUFRSPRoe" -m mark --mark 0x10000/0x10000 -j RETURN
...
Calico 使用 ipset 进行流量管理,ipset 是 iptables 的扩展,有以下几个优点:
- 允许在一条规则中根据多个 IP 地址和端口号进行匹配。
- 允许针对 IP 地址或者端口号动态更新 iptables 规则。
- ipset 使用 set 集合作为存储结构,set 在查询时十分高效。
通过检查 ipset,很明显看到只允许从 Backend Pod 的 IP 10.88.0.27 访问 DB Pod。
[root@minikube /]# ipset list
Name: cali40s:LrVD8vMIGQDyv8Y7sPFB1Ge
Type: hash:net
Revision: 6
Header: family inet hashsize 1024 maxelem 1048576
Size in memory: 408
References: 3
Number of entries: 1
Members:
10.88.0.27
参考资料
- [1] 原文: https://dramasamy.medium.com/life-of-a-packet-in-kubernetes-part-3-dd881476da0f
- [2] iptables四表五链及规则组成: https://blog.csdn.net/wfs1994/article/details/89047230)
- [3] 使用 iptables、ipset 的全局智能代理: https://blog.chih.me/global-proxy-within-ipset-and-iptables.html
- [4] networkpolicy的实践--felix: https://segmentfault.com/a/1190000039030174
- [5] calico iptables详解: https://blog.csdn.net/ptmozhu/article/details/73301971
- [6] iptables mark: https://www.kancloud.cn/pshizhsysu/linux/2084993
欢迎关注
