原文:Attribute-aware Face Aging with Wavelet-based Generative Adversarial Networks
文章目录
基于小波的生成式对抗网络的属性感知的脸部老化
摘要
由于很难收集同一被试者在很长的年龄范围内的脸部图像,大多数现有的脸部老化方法都采用非配对数据集来学习年龄映射。然而,未配对的训练数据所固有的年轻和老年面部图像之间的匹配模糊性可能会导致面部属性在老化过程中的不自然变化,这不能像大多数现有的研究那样通过强制身份一致性来解决。在本文中,我们提出了一个基于小波的生成对抗网络(GANs)的属性感知的面部老化模型来解决上述问题。具体来说,我们将面部属性向量嵌入模型的生成器和判别器中,以鼓励每个合成的老年面部图像忠实于其相应的输入属性。此外,我们还加入了小波包变换(WPT)模块,通过在频率空间的多个尺度上捕捉与年龄相关的纹理细节来提高生成图像的视觉保真度。定性结果证明了我们的模型在合成视觉上可信的人脸图像方面的能力,而广泛的定量评估结果表明,所提出的方法在现有的数据集上达到了最先进的性能。
1. 绪论
脸部老化,也被称为年龄递增[16],目的是在给定的脸部图像上呈现出老化效果,同时仍然保留个性化的特征。脸部老化技术的应用范围从社会安全到数字娱乐,如预测失踪儿童的当代外观和跨年龄的身份验证。由于人脸老化的实用价值,在过去的二十年里,人们提出了许多方法来解决这个问题[8, 20, 19, 21, 7]。随着深度学习的快速发展,深度生成模型被广泛采用来合成老化的人脸图像[23, 3, 4]。然而,这些方法最关键的问题是在训练阶段需要同一人在不同年龄段的多张人脸图像,这在实践中的收集成本极高,因此其应用在很大程度上受到限制。
为了处理这个问题,许多最近的研究诉诸于未配对的面部老化数据来训练模型[23, 28, 25, 9]。然而,这些方法主要关注人脸老化本身,而忽略了输入的其他关键条件信息(如面部属性),因此不能规范训练过程。因此,训练属性不匹配的人脸图像对会误导模型学习衰老以外的翻译,造成严重的重影伪影,甚至在生成结果中出现错误的面部属性。图1显示了一些属性不匹配的人脸老化结果。在 "性别 "下最右边的脸部老化结果中,胡须被错误地附加到输入的女性脸部图像上。这是因为模型学会了长胡子是衰老的典型标志,但没有办法知道这种情况不会发生在女性身上,因为如果不考虑条件信息,年轻女性和老年男性的脸部图像对可以被视为积极的训练样本。

图1. 由没有面部属性嵌入的面部老化模型产生的面部属性不匹配的面部老化实例。我们考虑了四个属性(种族、性别、眼镜和秃头),并为每个属性提供了三个样本结果。种族 "和 "性别 "的标签都是通过Face++[13]的高级公开API获得的,并放在每张图片下面。
为了抑制衰老过程中语义信息的这种不想要的变化,许多最近的脸部衰老研究试图通过强制身份一致性来监督输出[28, 1, 25, 9]。然而,如图1所示,在所有的样本结果中,个性化的特征在输出中得到了很好的保留,尽管如此,仍然观察到明显的面部属性的非自然变化。换句话说,在用未配对的数据进行训练时,保持良好的身份相关特征并不意味着合理的老化结果。因此,仅仅执行身份一致性不足以消除非配对训练数据中的匹配模糊性,因此无法实现令人满意的面部老化性能。
为了解决上述问题,在本文中,我们提出了一个基于生成对抗网络(GANs)的框架。与现有文献中的方法不同,我们通过在生成器和判别器中嵌入面部属性向量来涉及输入的语义条件信息,从而引导模型输出具有忠实于每个相应输入属性的老年面部图像。此外,为了增强衰老的细节,基于衰老的迹象主要由皱纹、笑纹和眼袋所代表,这些都可以被视为局部纹理,我们采用小波包变换来有效地提取频率空间中多个尺度的特征。
总结起来,主要贡献如下:
- 面部属性作为条件信息被纳入到面部老化的生成器和判别器中,因为身份保留不足以产生合理的结果。
- 采用小波包变换来提取频域中多个尺度的纹理细节特征,以生成细粒度的老化效果细节。
- 我们进行了大量的实验,以证明所提出的方法在呈现准确的老化效果和保留身份和面部属性信息方面的能力。定量结果表明,我们的方法达到了最先进的性能。
2. 相关工作
在过去的几十年里,人脸老化一直是一个非常受欢迎的研究课题,并提出了大量的算法来解决这个问题。一般来说,这些方法可以分为三类:基于物理模型的方法,基于原型的方法,以及基于深度学习的方法。
基于物理模型的方法通过对人脸的解剖结构进行建模,机械地模拟面部外观随时间的变化。Todd等人[22]通过修改心形应变变换对面部外观的转换进行建模。随后的工作从包括肌肉和整体面部结构在内的各种生物方面研究了这个问题[8, 20]。然而,基于物理模型的算法计算成本很高,而且需要大量的同一主体的图像序列来模拟老化效应。
数据驱动的原型方法[19, 21, 7]进入人们的视线,将人脸分为不同的年龄组,每个组由一个从训练数据中计算出来的平均脸(原型)来代表。之后,原型之间的转换模式被认为是老化的影响。原型方法的主要问题是,在计算平均脸时,个性化的特征被消除了,因此身份信息没有得到很好的保留。
近年来,具有时间架构的深度生成模型被采用来合成老年人脸部的图像[23, 3, 4]。然而,在大多数这些工作中,每个受试者都需要一个很长的年龄跨度的面部图像序列,因此它们在实际使用中的潜力是有限的。随着GANs[5]在生成视觉上吸引人的图像方面的成功,许多人已经努力使用基于GAN的框架来解决人脸老化的问题[28, 25, 9, 17, 24, 10]。Zhang等人[28]提出了一个条件对抗自动编码器(CAAE),通过在低维流形中遍历来实现年龄的递增和回归。与我们最相似的工作是[25],其中提出了一个基于GAN的金字塔结构的模型,并采用身份损失来实现永久性。除了保留身份信息外,我们着重于减轻未配对训练样本的匹配模糊性的影响,并通过在模型中嵌入面部属性向量来确保属性一致性。
3. 方法
在一个没有配对的人脸老化数据集中,每个年轻的人脸图像在训练过程中可能会映射到许多老年的人脸候选人,而语义信息不匹配的图像对可能会误导模型学习老化以外的翻译。为了解决这个问题,我们提出了一个基于GAN的人脸老化模型,它将年轻的人脸图像及其语义信息(即面部属性)作为输入,并相应地输出视觉上可信的老年脸。该网络由两部分组成:面部属性嵌入生成器G和基于小波的判别器D。生成器网络将面部属性嵌入到年轻的面部图像中,并合成老化的脸。鉴别器网络用于鼓励生成的结果与一般的结果无法区分,并拥有与相应输入相同的属性。图2展示了拟议框架的概况。
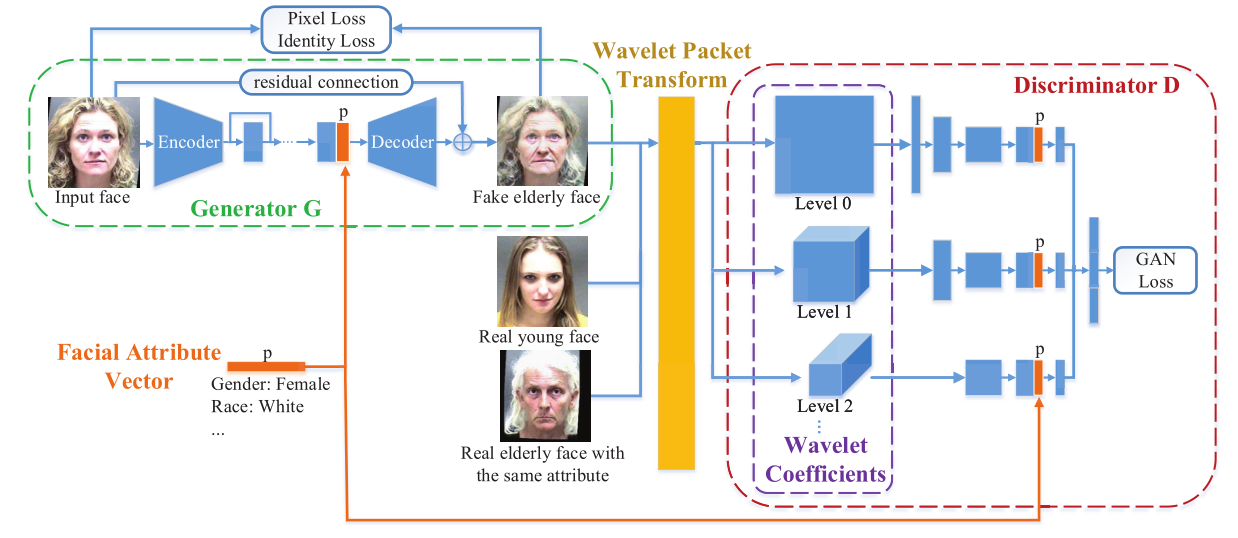
图2. 拟议的脸部老化框架的概述。一个沙漏状的生成器G学习年龄映射并输出栩栩如生的老人脸部图像。鉴别器D被用来区分合成的人脸图像和普通的人脸图像,基于小波包变换模块计算的多尺度小波系数。描述输入人脸图像的p维属性向量被嵌入到发生器和鉴别器中,以减少未配对训练数据所固有的匹配模糊性。
3.1. 脸部属性嵌入生成器
现有的脸部老化研究[9, 25, 28]只将年轻的脸部图像作为输入,然后使用基于GAN的网络直接学习年龄映射。虽然通常对身份信息和像素值的约束是为了限制对输入图像的修改,但面部属性仍可能发生不自然的转换(如图1所示)。与以往的工作不同,我们建议将低层次的图像信息(像素值)和高层次的语义信息(面部属性)纳入面部老化模型,以规范图像的翻译模式,并减少未配对的年轻和年老面孔之间映射的模糊性。具体来说,该模型将年轻的人脸图像及其相应的属性向量作为输入,并生成与输入属性一致的老年人脸图像。
我们不是通过简单地采用一个额外的损失项来监督生成结果的属性,而是将属性向量嵌入生成器中,以便在生成过程中充分考虑面部语义信息,鼓励模型更有效地生成具有一致属性的面部图像。具体来说,我们采用一个沙漏状的全卷积网络作为生成器,它在以前的图像翻译研究中取得了成功[6, 29]。它由一个编码器网络、一个解码器网络和作为瓶颈的中间的四个剩余块组成。输入的面部属性向量被复制并串联到最后一个残余块的输出blob上,因为它们都包含高级语义特征。组合之后,解码器网络将串联的特征blob转换回图像空间。
由于脸部衰老可以被认为是以输入的年轻脸部图像为条件渲染衰老效果,所以我们将输入图像添加到解码器的输出中,形成一个剩余连接。与合成整个脸部图像相比,这种结构自动使生成器更专注于建模输入和输出脸部图像之间的差异,即有代表性的老化迹象,而不容易被与老化无关的视觉内容,如背景所干扰。最后,通过双曲正切(tanh)映射将结果张量的数字尺度归一化,从而得到生成的老年人脸部图像。
3.2. 基于小波的鉴别器
为了迫使生成器吸收输入人脸图像的语义信息,采用了一个条件判别器。鉴别器有两个主要功能。1)区分合成的人脸图像和普通的人脸图像;2)检查每个生成结果的属性是否忠实于相应的输入结果。
具体来说,考虑到典型的衰老迹象,如皱纹、笑纹和眼袋,可以被视为局部图像纹理,我们采用小波包变换(WPT,见图3)来捕捉与年龄有关的纹理特征。具体来说,进行多级WPT以对给定图像中的纹理进行更全面的分析,每个分解级别的小波系数被送入判别器的卷积通路。请注意,这与[9]不同,因为在我们的工作中,小波系数只用于判别,不涉及预测或重建。
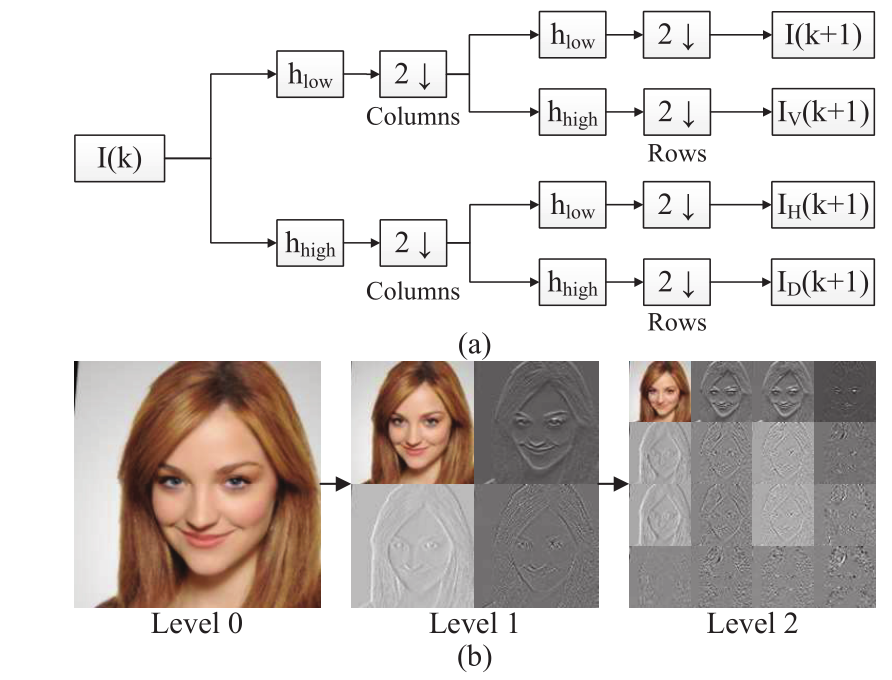
图3. 小波包变换的演示。(a)低通和高通分解滤波器(hlow和hhigh)被迭代应用于第k层的输入,以计算下一层的小波系数;(b)一张脸部图像样本及其在不同分解层的小波系数。
为了使判别器获得判断属性是否在生成的图像中被保留的能力,输入的属性向量也被复制并连接到每个路径的中间卷积块的输出中。在判别器的末端,所有路径的相同大小的输出被融合成一个单一的张量,然后针对标签张量估计对抗性损失。
与[25]中通过卷积层序列提取多尺度特征相比,使用WPT的优势在于计算成本大大降低,因为计算小波系数可以被视为通过单个卷积层的转发。因此,WPT大大减少了每个转发过程中执行的卷积次数。虽然模型的这一部分被简化了,但它仍然利用了多尺度图像纹理分析的优势,这有助于提高生成图像的视觉保真度。
3.3. 总体目标函数
与普通的GANs不同[5],我们采用最小平方损失而不是负对数似然损失,以使生成的样本与特征空间的决策边界之间的边际最小化,从而进一步提高合成图像的质量[12]。实际上,我们把年轻的人脸图像xi和它们相应的属性向量αi配对起来,维数为p,表示为(xi,αi)∼ Pyoung(x,α),并把它们作为模型的输入。只有属性与输入相同的通用老年脸,即(xi, αi) ∼ Pold(x, αi),被视为正样本,而真正的年轻脸,即(xi, αi) ∼ Pyoung(x, α),被视为负样本,以帮助D获得对老化效应的判别能力。
在数学上,G和D的目标函数可以写成如下:
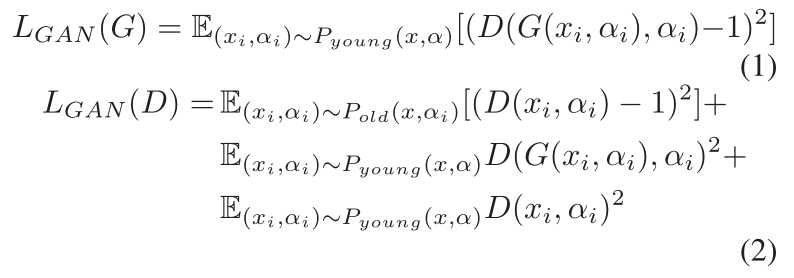
其中,Pyoung和Pold分别表示年轻和年长受试者的通用人脸图像的分布。
此外,我们采用了像素损失和身份损失来保持图像层面和个性化特征层面的一致性。具体来说,我们利用VGG-Face描述器[14],用Φ表示,来提取人脸图像的身份相关语义表示。这两个损失项可以表述为。
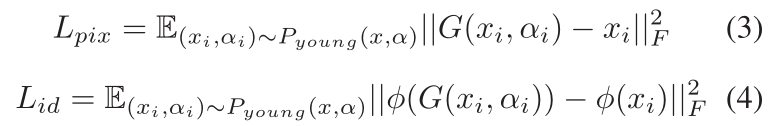
总之,拟议模型的总体目标函数可以写成如下。
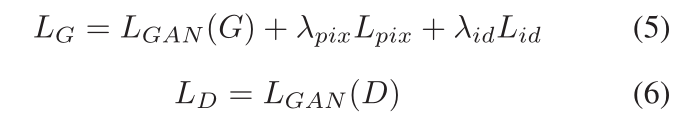
其中λid和λpix分别是平衡批评对身份和像素的重要性的系数。我们通过交替最小化LG和LD来优化模型,直到达到最佳状态。
4. 实验
4.1. 数据集
MORPH[15]是一个大型的老龄化数据集,包含了超过13000名受试者的55000张面部图像。MORPH中的数据样本是在均匀和适度的光照和简单的背景下表现出中性表情的近额面部的彩色图像。CACD[2]包含了163,446张在较少的控制条件下拍摄的2,000名名人的脸部图像。除了姿势、光照和表情的巨大变化(PIE变化),CACD中的图像是通过谷歌图像搜索收集的,由于每张图像中实际呈现的脸和提供的相关标签(姓名和年龄)之间的不匹配,使其成为一个非常具有挑战性的数据集。
至于面部属性,MORPH为研究人员提供了每个图像的标签,包括年龄、性别和种族。我们选择 "性别 "和 "种族 "作为需要保留的属性,因为这两个属性可以保证在自然老化过程中保持不变,而且与流行的面部属性数据集CelebA[11]中使用的 "有吸引力 "或 "胖子 "等属性相比,它们相对客观。对于CACD,由于除 "白人 "以外的其他种族的脸部图像只占整个数据集的一小部分,我们只选择 "性别 "作为要保留的属性。具体来说,我们通过名人的名字列表,对相应的图像进行标注。这就在性别标签中引入了噪音,因为注释的名字和每张图片中呈现的实际面孔不匹配,这进一步增加了我们的方法在这个数据集上取得良好性能的难度。值得注意的是,所提出的模型是高度可扩展的,因为研究人员可以选择任何要保留的属性,只需将它们纳入条件面部属性向量,并相应地安排训练图像对。
4.2. 实施细节
所有的人脸图像都根据MTCNN[27]检测到的五个面部标志进行裁剪和对齐。按照[25, 9]的惯例,我们将人脸图像分为四个年龄组,即30-、31-40、41-50、51+,只考虑从30-到其他三个年龄组的翻译。为了客观地评估所提方法的性能,所有的指标测量都是通过Face++[13]的稳定的公共API进行的。我们的人脸验证实验中采用的阈值(阈值=76。FAR=1e-5)与[25]中使用的相同。因此,我们的实验的定量结果与[25]中报告的结果相当。
我们选择Adam作为G和D的优化器,学习率和批量大小分别设置为1e-4和16。像素级的批判每5次迭代一次,而D在每次迭代时都会更新。至于权衡参数,λpix和λid首先被设定为使Lpix和Lid与LGAN(G)处于同一数量级,然后除以10以强调对抗性损失的重要性。所有实验都是在Nvidia Titan Xp GPU上进行5倍交叉验证。
4.3. 面部老化的定性结果
在Morph和CACD上的样本结果显示在图4。很明显,我们的方法能够模拟不同年龄组之间的翻译,并以高视觉保真度合成老年人的面部图像。此外,我们的方法对种族、性别、表情和遮挡等方面的变化是稳健的。

图4. Morph(第一行)和CACD(第二行)的样本结果。每个结果中的第一张图像是输入的测试脸部图像,随后的3张图像分别是同一受试者在31-40岁、41-50岁和51岁以上年龄组的合成老年脸部图像。
与先前的Morph工作的性能比较见图5。传统的脸部老化方法,CONGRE[18]和HFA[26],只在狭小的面部区域内呈现细微的老化效果,这不能准确地模拟老化过程。相比之下,基于GAN的方法,GLCA-GAN[9]和[25]中提出的具有金字塔结构的GAN,简称PAG-GAN,在生成结果的质量上取得了明显的改善。然而,与GLCA-GAN相比,我们的方法进一步生成了更高分辨率(2倍)的人脸图像,并增强了细节,与PAG-GAN相比,减少了结果中的重影假象(如头发和胡须的细节更精细)。
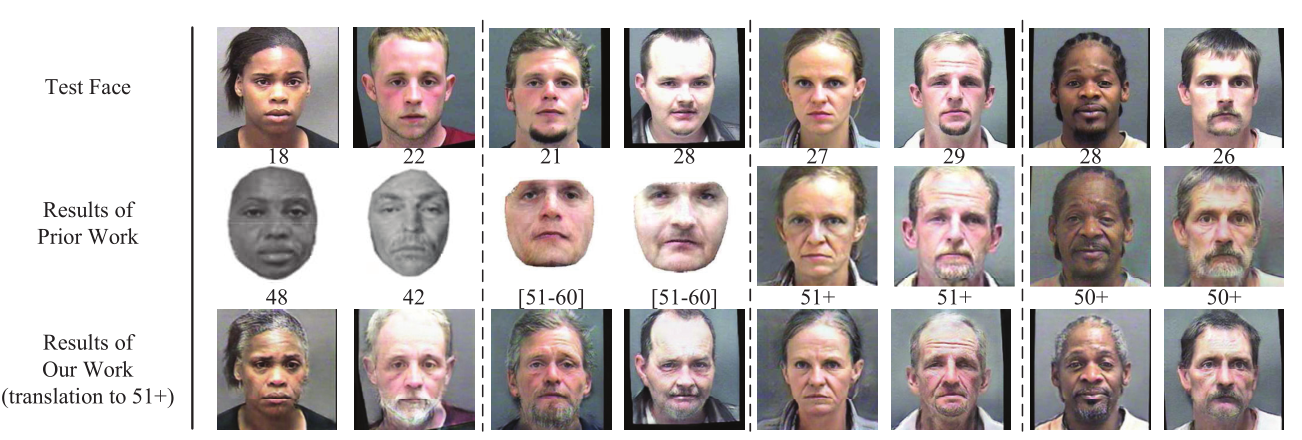
图5. 与先前的Morph工作的性能比较(放大后可以更好地看到老化的细节)。第二行显示了先前工作的结果,其中考虑了四种方法,并为每种方法提供了两个样本结果。这四种方法是(从左到右)。CONGRE [18], HFA [26], GLCA-GAN [9], 和PAG-GAN [25]。最后一行显示的是我们的方法的结果。
4.4. 老化的准确性和身份的保存
在本小节中,我们报告了关于时效准确性和身份保持的评估结果。所提出的模型的性能与以前的先进方法CAAE[28]、GLCA-GAN[9]和PAGGAN[25]进行比较,以证明其有效性。
衰老的准确性。每个年龄段的普通人脸和合成人脸的年龄分布都被估算出来,真实图像和虚假图像之间的差异越小,说明对老化效果的模拟越准确。在Morph和CACD上,年龄小于或等于30岁的人脸图像被认为是测试样本,而其他三个年龄组中相应的老化脸被合成。我们使用Face ++ APIs估计了生成结果和数据集中的自然人脸图像的表观年龄,以进行公平的比较。
对Morph和CACD的年龄估计结果显示在表1和图6。我们将我们的方法与以前的工作在平均年龄的差异方面进行比较。在Morph上,可以看到合成的老年人脸部图像的估计年龄分布与所有年龄组的自然图像的年龄分布非常吻合。我们的方法在所有三个老化过程中一直优于其他方法,证明了我们方法的有效性。CAAE结果中的老化迹象不够明显,导致了较大的年龄估计误差。在CACD中,由于人脸图像和相关标签之间存在不匹配,可以观察到轻微的性能下降。尽管如此,所提出的方法仍然取得了与以前的技术水平相当的结果。这表明我们的方法对属性标签中的噪声是相对稳健的,从而降低了对先前属性检测过程的准确性的要求。
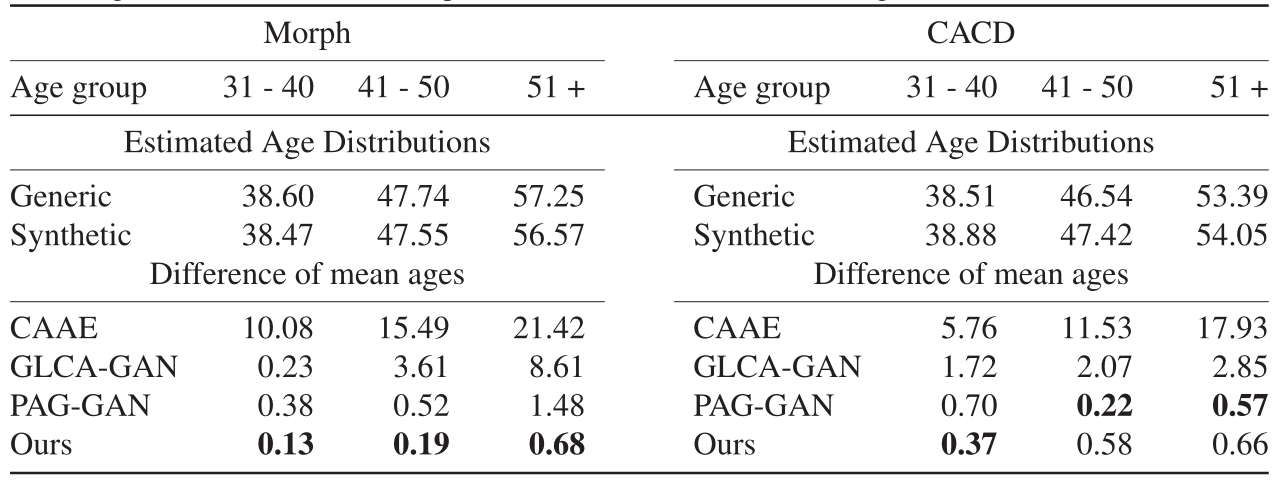
表1. Morph和CACD的年龄估计结果(平均年龄的差异以绝对值计算)。
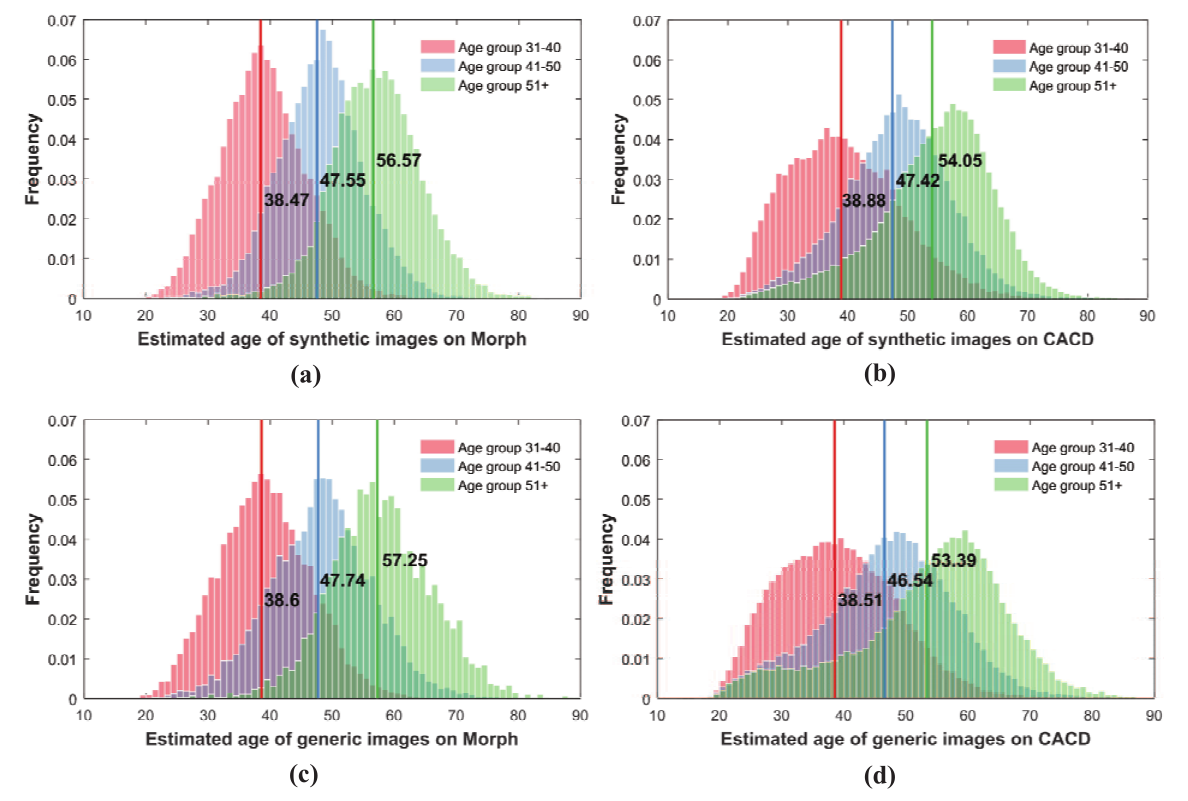
图6. 估计年龄的分布。(a) Morph上的合成面孔;(b) CACD上的合成面孔;© Morph上的普通面孔;(d) CACD上的普通面孔。
身份保留。进行人脸验证实验,以检查身份信息在人脸老化过程中是否被保留下来。与以前的文献类似,还对同一受试者不同年龄组的合成老人脸部图像进行了比较,以检查身份信息在三个单独训练的年龄映射中是否一致。
人脸验证实验的结果见表2。在Morph上,我们的方法在所有三种翻译上都取得了最高的验证率,并以明显的优势胜过其他方法,尤其是在最难的情况下(从30岁到51岁以上)。这表明,所提出的方法在人脸老化过程中成功地实现了身份的永久性。在含有不匹配标签的更具挑战性的数据集CACD上,我们的方法的性能与PAG-GAN相当,但有微小的差别。值得注意的是,随着单个主体的两张人脸图像之间的时间间隔增加,验证的置信度和准确度都会下降,这是合理的,因为随着时间的推移,面部外观可能发生更大的变化。
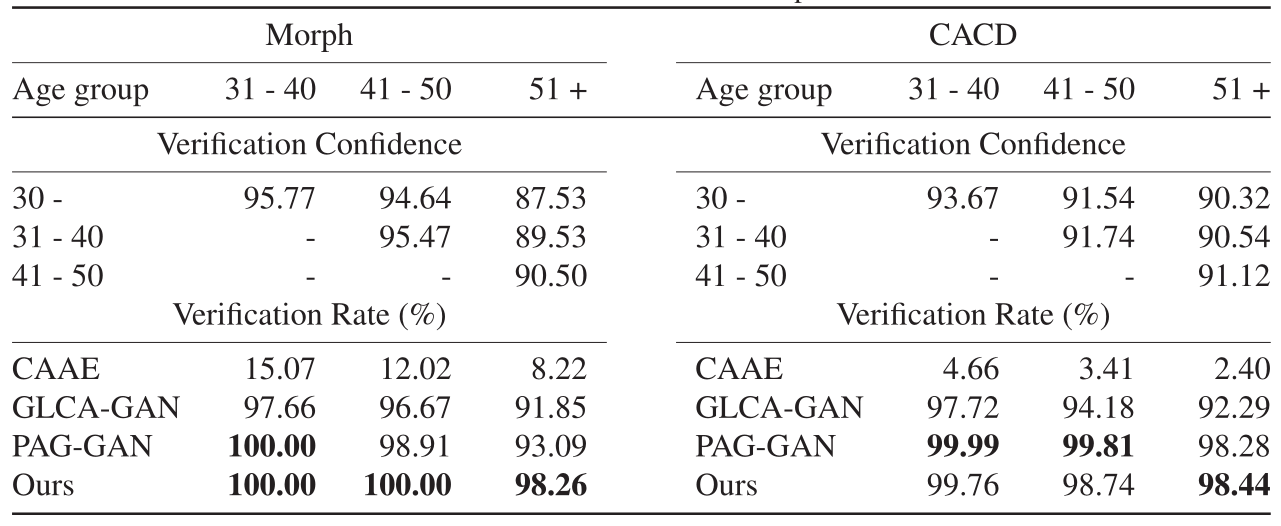
表2. Morph和CACD的人脸验证结果。
4.5. 面部属性的一致性
我们通过比较年龄增长前后估计的面部属性来评估面部属性的保存性能,结果列于表3。在Morph上,大多数测试样本的面部属性("性别 "高达97.37%,"种族 "为95.86%)在老化过程中得到了很好的保留。此外,我们的方法在对所有年龄组的翻译上以明显的优势胜过GLCA-GAN和PAG-GAN。在CACD上,由于被错误标记的数据样本的影响,与Morph上的结果相比,可以看到明显的性能下降。然而,我们的方法在保存面部属性方面仍然比其他方法有更好的表现。我们的方法在保留 "性别 "属性方面的优势随着年龄差距的增加而变得更大,最终在翻译到最年长的51岁以上年龄组时达到17.14%(87.19%比70.05%)。从表3中,我们可以得出结论,随着年龄差距的增加,面部属性的不希望发生的变化更容易发生,而纳入条件信息有利于在衰老过程中保持目标面部属性的一致性。

表3. Morph和CACD上 "性别 "和 "种族 "的面部属性保存率。
4.6. 消融研究
在这一部分,我们进行了实验,以充分探索面部属性嵌入(FAE)和小波包变换(WPT)在模拟准确的年龄翻译中的贡献。我们研究了包括/不包括属性嵌入(w/wo FAE)和小波包变换(w/wo WPT)对年龄分布、面部验证率和属性保存率的影响。本小节的所有实验都只在Morph上进行,因为CACD数据集上的标签是有噪声的。
图7显示了由所提模型的变体生成的人脸图像的视觉图示。很明显,当FAE和WPT都不参与时(woFAE woWPT),生成的结果会出现严重的重影假象。由于未配对训练数据的内在匹配模糊性,没有FAE的模型会错误地将小胡子附在输入的女性面部图像上,以显示老化效果。值得注意的是,留胡子并没有降低人脸验证的可信度,因为生成的人脸图像仍然与输入的身份相关特征相似。这再次证实了我们的观察,即强制执行身份一致性并不足以获得令人满意的人脸老化效果。

图7. 消融研究的视觉结果样本。对于每张脸,估计的年龄(第一行)和检测的属性(第二行)都列在下面。最后一行的数值是生成结果和测试脸之间的脸部验证信心。
相反,加入FAE后,通过减少匹配的模糊性,抑制了不希望出现的面部属性漂移。具体来说,在图7中,采用FAE后,生成结果中不再有小胡子,从而实现了面部属性的一致性。不幸的是,去掉小胡子也会抹去与衰老有关的纹理细节(皱纹、笑纹和眼袋),导致相对不准确的衰老结果(比预期的年轻很多)。
为了解决这个问题,并生成视觉上更可信的具有生动老化迹象的人脸图像,WPT被用作判别器的初始层。通过比较 "woFAE / woWPT "和 "woFAE / wWPT "以及 "woFAE / woWPT "和 "Ours "设置下的结果,可以很容易地看到WPT的贡献。尽管在设置 "woFAE / wWPT "下获得的结果仍然存在错误的面部属性,但重影伪影得到了明显的缓解,逼真的老化效果得到了清晰的观察。
消减研究的定量结果显示在表4和5中。根据表4的结果,引入面部属性嵌入(wFAE)增加了所有三种年龄映射下的 "性别 "和 "种族 "的保存率,特别是在翻译到51岁以上的情况下。这证明了属性嵌入的有效性,因为它使未配对的年龄数据在面部属性方面保持一致,从而减少了数据映射中的内在模糊性。

表4. 所提模型各变体之间的面部属性保存和老化准确性的结果比较(平均年龄的差异以绝对值衡量)。
此外,很明显,采用WPT可以在所有情况下减少通用图像和合成图像的年龄分布之间的差异。然而,WPT在保持面部属性的一致性方面提供的帮助很小。这是因为WPT只捕捉了基于低层次视觉数据的特征,而无法弥补语义上的差距,所以该框架仍然受到数据样本不匹配的影响。
结合表4和表5的结果,可以看出,虽然属性保存率仍有改进空间,但验证率即将达到完美。这一观察结果验证了我们的说法,即身份保留并不能保证面部属性在老化过程中保持稳定。因此,除了对身份的约束外,对面部属性的监督也有助于减少未配对数据的内在匹配模糊性,达到满意的面部老化效果。
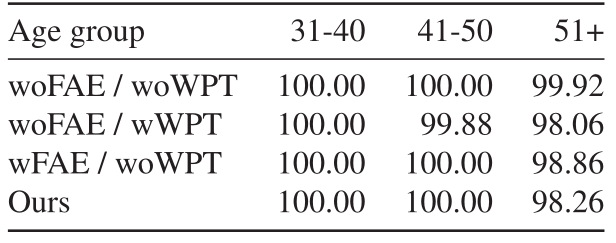
表5. 在Morph上提出的模型的变体的脸部验证率(%)。
5. 总结
在本文中,我们提出了一个基于GAN的框架来合成老化的面部图像。由于身份约束在减少未配对的老化数据的匹配模糊性方面没有效果,我们建议采用面部属性来解决这个问题。具体来说,我们将面部属性向量嵌入到生成器和判别器中,以鼓励生成的图像忠实于相应输入图像的面部属性。为了进一步提高生成的人脸图像的视觉保真度,我们引入了小波包变换来有效地提取多尺度的文本特征。在Morph和CACD上进行了广泛的实验,定性结果表明,我们的方法可以合成栩栩如生的人脸图像,对PIE变化和噪声标签都有很好的适应性。此外,通过公共API获得的定量结果验证了所提出的方法在老化精度以及身份和属性保存方面的有效性。