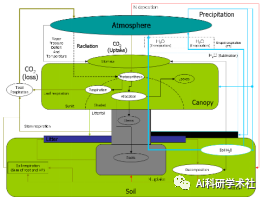
Biome-BGC是利用站点描述数据、气象数据和植被生理生态参数,模拟日尺度碳、水和氮通量的有效模型,其研究的空间尺度可以从点尺度扩展到陆地生态系统。
在Biome-BGC模型中,对于碳的生物量积累,采用光合酶促反应机理模型计算出每天的初级生产力(GPP),将生长呼吸和维持呼吸减去后的产物分配给叶、枝条、干和根。生物体的碳每天都按一定比例以凋落方式进入凋落物碳库;对于水份输运过程,该模型模拟的水循环过程包括降雨、降雪、冠层截留、穿透降水、树干径流、 冠层蒸发、融雪、雪升华、冠层蒸腾、土壤蒸发、蒸散、地表径流和土壤水分变化以及植物对水分的利用;对于土壤过程,模型考虑了凋落物分解进入土壤有机碳库过程、土壤有机物矿化过程和基于木桶模型的水在土层间的输送关系;对于能量平衡,该模型还考虑了净辐射、感热通量和潜热通量等过程。
本次,将讲授利用中国区域地面气象要素驱动数据集(CMFD)和CN05.1气候数据格点化气象数据驱动Biome-BGC在区域上进行模拟。在模拟过程中,需要综合的使用Linux、Python等一些小工具,完成模式的前处理和后处理的工作。
| 安排 |
内容 |
| 第一部分 模式讲解 |
Biome-BGC介绍
|
| 第二部分 课程基础 |
Linux应用 l 实现批量创建文件、删除文件及文件夹 l 并行化执行程序 CDO工具应用 l 使用cdo工具对netCDF文件进行合并 l 筛选时间和变量,裁剪为小区域 Python应用 l Python的循环语句,逻辑语句, l 创建Numpy数组,并统计计算; l 使用Matplotlib制作散点图、等值线图; l 利用零散数据Pandas创建数,制作时间 l 利用Xarray读取netCDF文件,写入netCDF文件;实现插值工作 |
| 第三部分 数据处理 |
在linux 上综合使用cdo和xarray数据制备所需数据。 1静态数据制备: l 地形数据:GTOPO30S 1km l 土地利用数据:GLCC 1km l 土壤数据:FAO l GPP数据:MODIS数据
2驱动数据制备: l CN05.1数据处理 l CMFD数据处理 3生态数据 MODIS GPP |
| 第四部分 单点的模拟 |
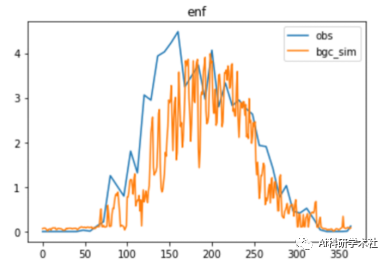
1前处理 l 从空间格点数据(netCDF格式)插值到站点 l 配置Biome-BGC运行文件 l 制备用于驱动Biome-BGC的气象数据 2运行BGC模型 3调参 以MODIS的GPP产品为观测值,使用Python库并行化调整Biome-BGC模型的参数 l 调整生长季开始和结束
4后处理 l 读取Biome-BGC的ascii文件和二进制文件 l 结果统计计算 结果可视化 |
| 第五部分 区域模拟-1 |
区域模拟是将区域上每个格点分别进行计算进行的。在本节案例中,将以一个较小的省份进行高分辨率模拟和在中国进行粗分辨率模拟。模拟过程中涉及以下步骤: l 静态地理数据准备 l 气象驱动数据制备 l 分配数据 l 并行运行 合并单点结果为空间数据 |
| 第六部分 长时间序列模拟案例 |
使用ERA5作为观测数据的降尺度后的CMIP6未来气候变化降尺度数据。 l 对气象数据降尺度,获得气温、湿度、降水和向下短波辐射。 l 土壤数据、植被数据库查询 l 准备气象数据和静态数据 l 后处理模拟结果数据
|
| 第七部分 分析 |
在单点和空间模拟数据的基础上,进行以下分析: l 敏感性分析: 使用敏感性分析方法(SALib库),分析主要模拟参数对GPP的影响 l 归因分析: 使用通径分析方法(semopy库),结合气象要素,分析对GPP和ET的影响过程 |
| 需要硬件基础要求 |
CPU:8核心16线程及以上(空间模拟需要计算资源) 内存:16G及以上 硬盘:计算机本地硬盘100GB及以上(虚拟机+数据的存储) 在课程前,将协助部署配置VirtualBox虚拟机(Python的运行环境) |