python篇—提取VOC格式的坐标,并按照cameraID进行排序
from datetime import datetime
import xml.etree.ElementTree as ET
import os
sets = [("images")]
# fixme: 所对应的标签
classes = ["2"]
IMAGE_PATH = "./saves/{}.txt"
DATA_TXT = "./saves/"
IMAGE_WRITE_PATH = "images/{}.jpg"
OPEN_XML_PATH = "labels/{}.xml"
def convert_annotation(image_id, list_file):
in_file = open(OPEN_XML_PATH.format(image_id))
tree = ET.parse(in_file)
root = tree.getroot()
# list_file.write('"'+image_id.split("-")[0]+'"')
#########################################################################
list_file.write('{"name":"' + image_id.split("-")[0] + '",' + '"box":')
# list_file.write(IMAGE_WRITE_PATH.format(image_id))
#########################################################################
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
# list_file.write(":" + '"(' + (",".join([str(a) for a in b])) + ')"' + ",")
#########################################################################
list_file.write('[('+(",".join([str(a) for a in b])) + ")]},")
#########################################################################
# list_file.write("}")
list_file.write('\n')
for image_set in sets:
image_ids = open(IMAGE_PATH.format(image_set)).read().strip().split()
str_date_li = []
for img_id in image_ids:
str_date = img_id.split(".")[0].split("-")[0]
str_date_li.append(str_date)
li_ti1 = sorted(str_date_li)
save_data_path = '/'.join(DATA_TXT.split('/')[:-1])
if not os.path.exists(save_data_path):
os.makedirs(save_data_path)
list_file = open(os.path.join(DATA_TXT, "images_final1.txt"), 'w')
for cameraID in li_ti1:
for image_id in image_ids:
if image_id.startswith(cameraID):
print(image_id)
convert_annotation(image_id, list_file)
list_file.close()
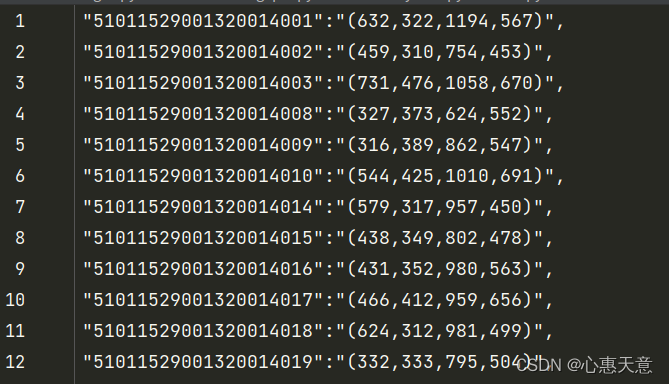
结果如下:
from datetime import datetime
import xml.etree.ElementTree as ET
import os
sets = [("images")]
# fixme: 所对应的标签
classes = ["1"]
IMAGE_PATH = "./saves/{}.txt"
DATA_TXT = "./saves/"
IMAGE_WRITE_PATH = "images/{}.jpg"
OPEN_XML_PATH = "labels/{}.xml"
def convert_annotation(image_id, list_file):
in_file = open(OPEN_XML_PATH.format(image_id))
tree = ET.parse(in_file)
root = tree.getroot()
list_file.write('"'+image_id.split("-")[0]+'"')
#########################################################################
# list_file.write('{"name":"' + image_id.split("-")[0] + '",' + '"box":')
# list_file.write(IMAGE_WRITE_PATH.format(image_id))
#########################################################################
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(":" + '"(' + (",".join([str(a) for a in b])) + ')"' + ",")
#########################################################################
# list_file.write('[('+(",".join([str(a) for a in b])) + ")]},")
#########################################################################
# list_file.write("}")
list_file.write('\n')
for image_set in sets:
image_ids = open(IMAGE_PATH.format(image_set)).read().strip().split()
str_date_li = []
for img_id in image_ids:
str_date = img_id.split(".")[0].split("-")[0]
str_date_li.append(str_date)
li_ti1 = sorted(str_date_li)
save_data_path = '/'.join(DATA_TXT.split('/')[:-1])
if not os.path.exists(save_data_path):
os.makedirs(save_data_path)
list_file = open(os.path.join(DATA_TXT, "images_final.txt"), 'w')
for cameraID in li_ti1:
for image_id in image_ids:
if image_id.startswith(cameraID):
print(image_id)
convert_annotation(image_id, list_file)
list_file.close()
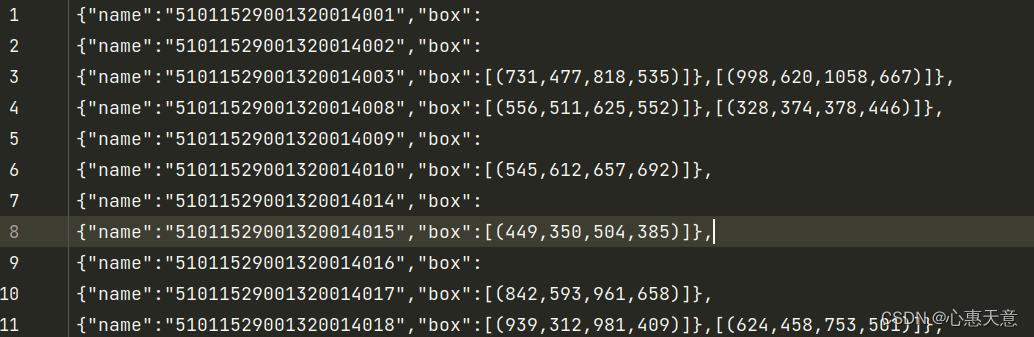
结果如下: