框架介绍
X-AnyLabeling 是一款全新的交互式自动标注工具,其基于 Labelme 和 Anylabeling 等诸多优秀的标注工具框架进行构建,在此基础上扩展并支持了许多丰富的模型和功能,并借助Segment Anything和 YOLO 系列等目前主流和经典的深度学习模型提供强大的 AI 能力支持。无须任何复杂配置,下载即用,大大降低用户使用成本,同时支持自定义模型和快捷键设置等,极大提升用户标注效率和使用体验!
项目链接:https://github.com/CVHub520/X-AnyLabeling/tree/main
帮助文档:https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/Q%26A.md

X-AnyLabeling 具备以下优势:
- 支持中英文一键切换,随心所欲;
- 支持必要的快捷键操作,可自定义设置;
- 支持
CPU和GPU一键推理,可按需选取; - 提供详细的操作手册及交流社区,帮助用户快速解决问题;
- 支持
Windows、Linux和MacOS等多个主流的操作系统,同时支持用户自编译; - 提供多种标注样式,包括多边形、矩形、线段、点、圆形、文本等,以满足用户的多元化的需求。
- 支持多种导出格式,包括
YOLO-txt、COCO-json、VOC-xml以及图片掩码等,只需一键运行,即可满足日常训练所需标签样式。 - 提供多种模型架构,包括但不仅限于
YOLO系列、DETR系列和SAM系列等,可无缝衔接OpenMMLab、PaddlePaddle、timm等多个主流的深度学习框架,同时支持自定义模型导入。 - 支持多种任务模式,包括目标检测、语义分割、姿态估计、人脸关键点回归、文本检测、识别和KIE(关键信息提取)标注等。
功能支持
AI 开放能力
X-AnyLabeling 目前提供以下 AI 开放能力:
- 目标检测 & 语义分割
注:每个检测模型均提供多个型号,如 YOLOv5(n/s/m/l/x),可根据需要自行选取合适的版本。
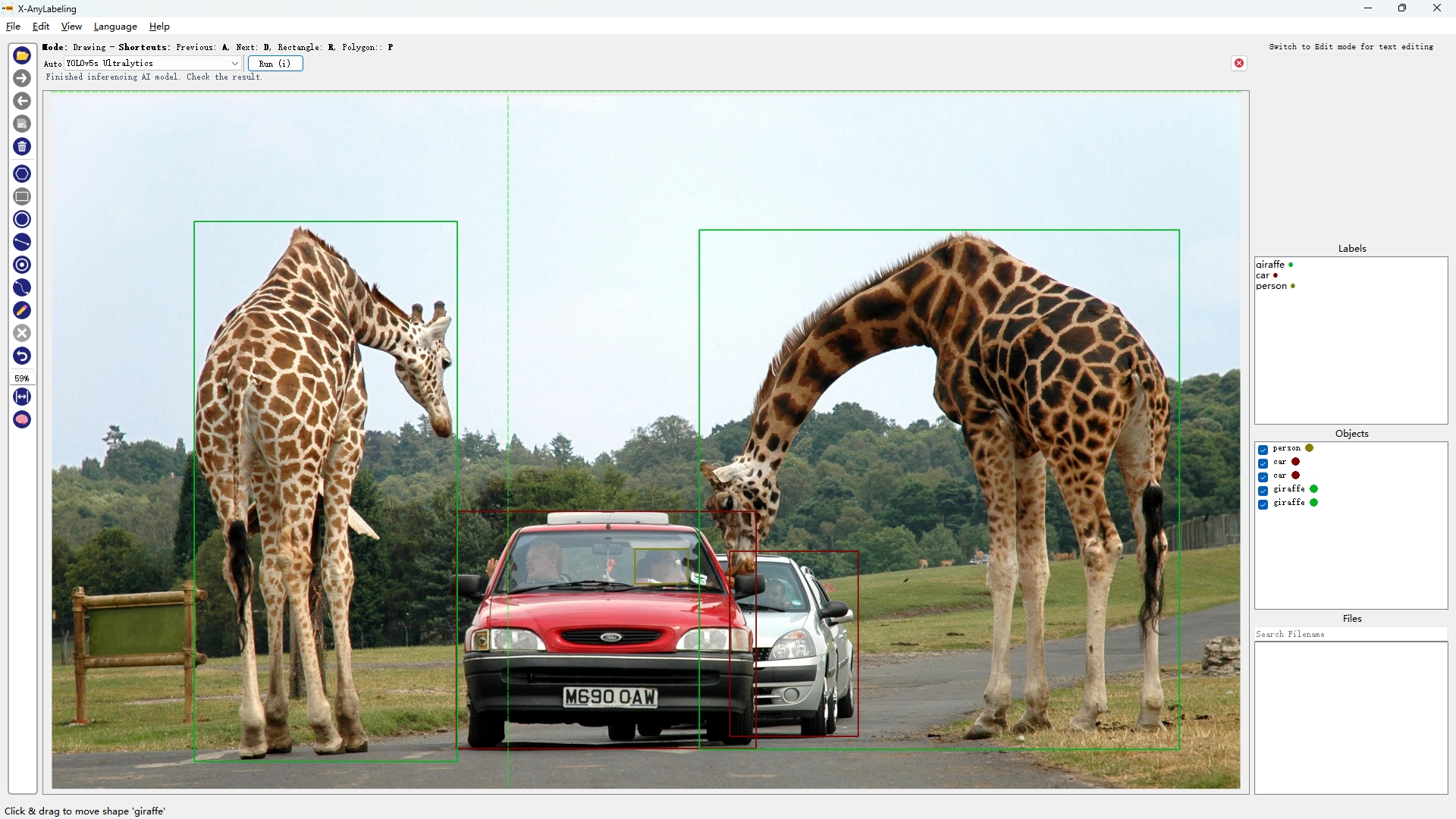 |
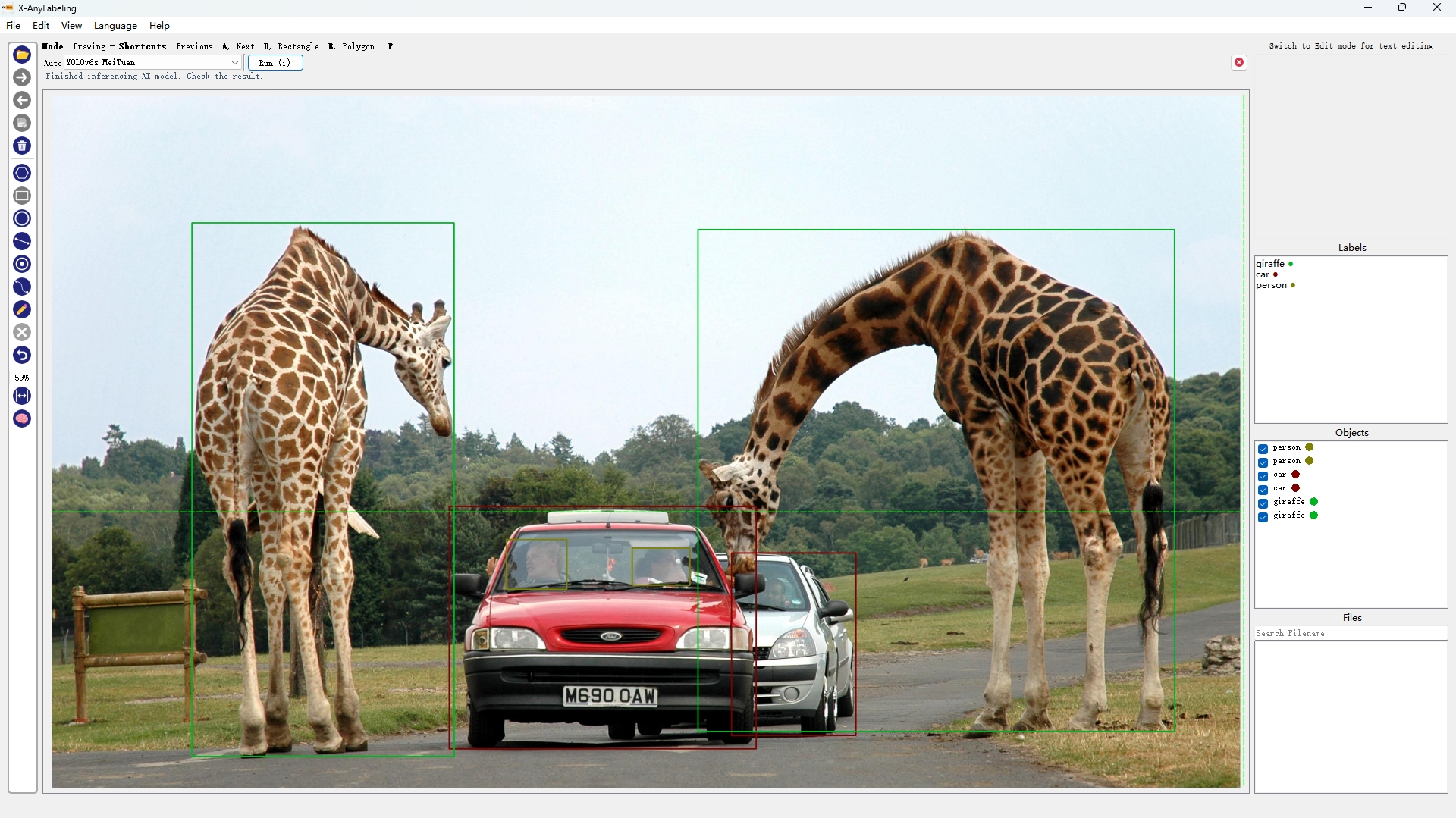 |
 |
 |
|---|---|---|---|
| YOLOv5s | YOLOv6s | YOLOv7 | YOLOv8s |
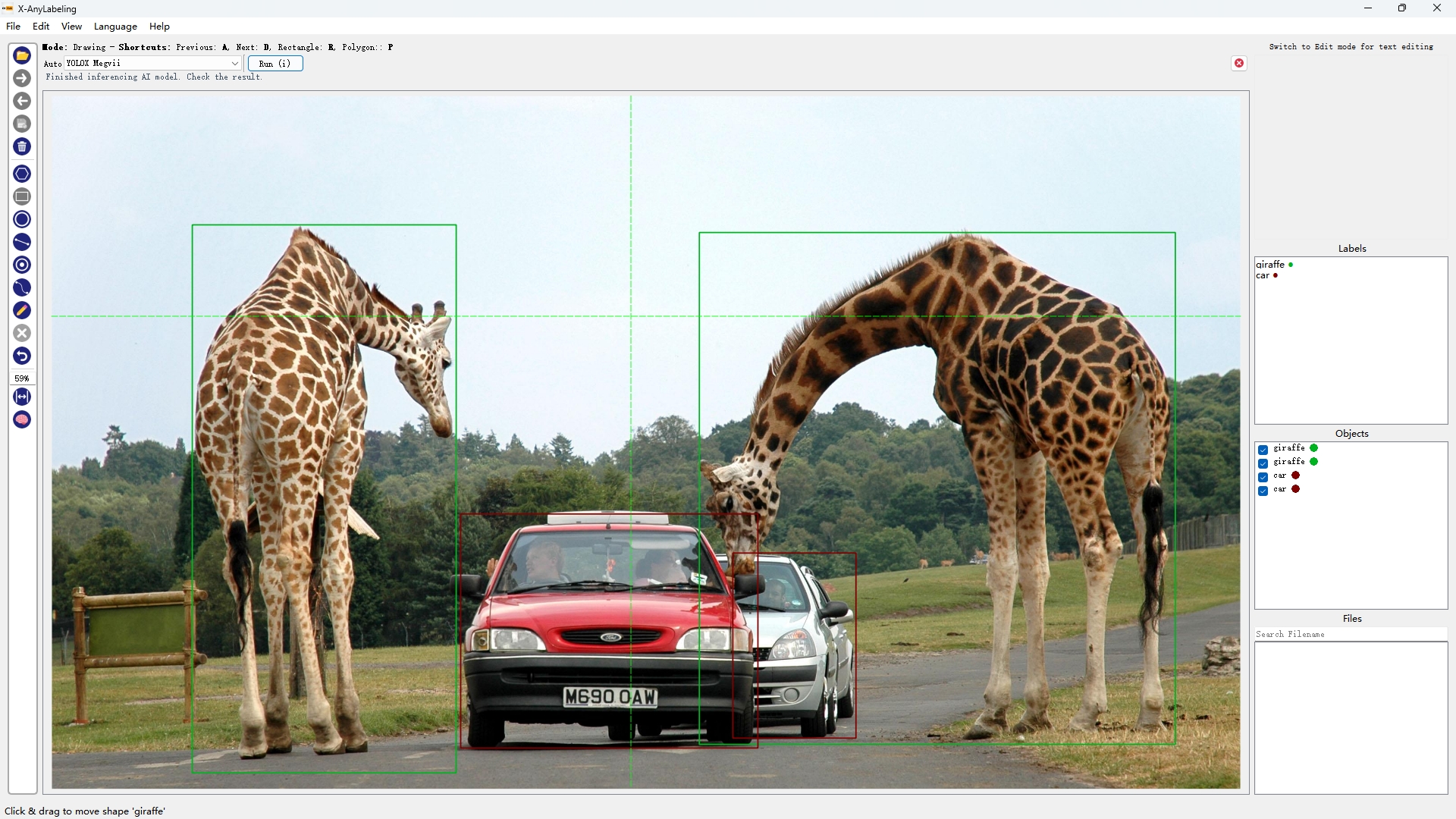 |
|
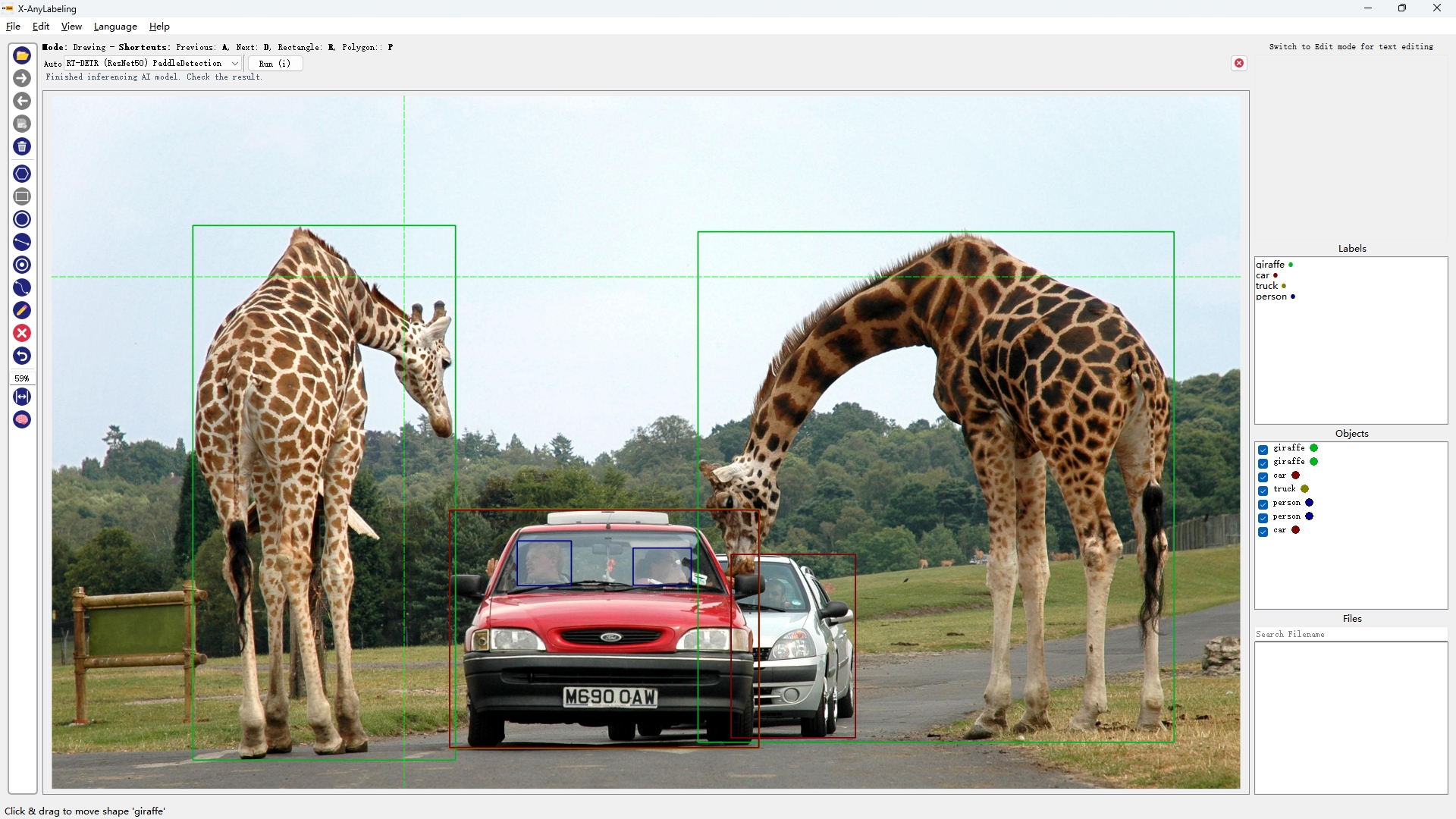 |
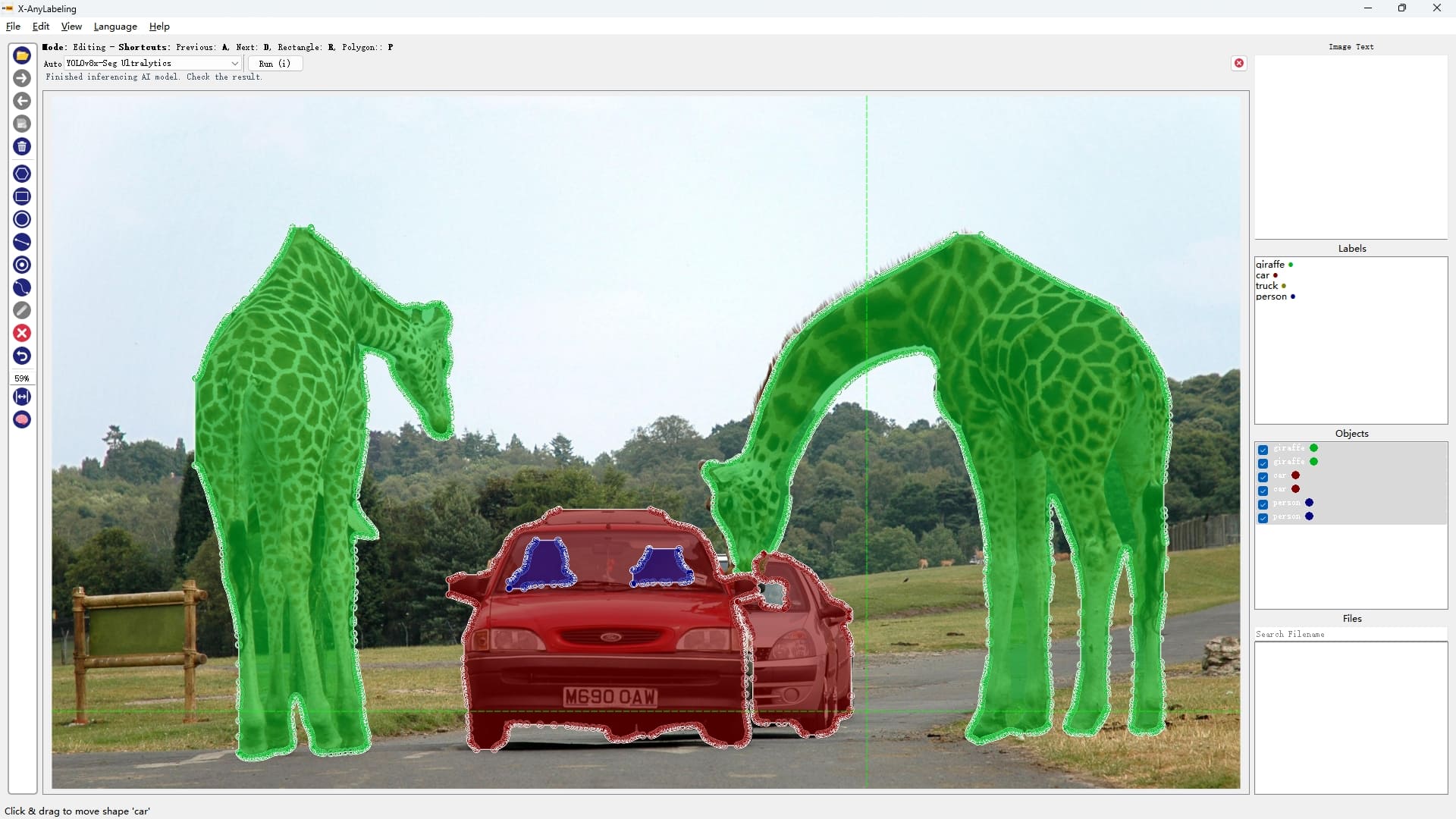 |
|---|---|---|---|
| YOLOX | YOLO-NAS-S | RT-DETR-ResNet50 | YOLOv8-seg |
从上述结果可以看出【可点开图片放大查看】,精度"高"的模型不一定在所有图片上均表现优异,例如:
- YOLOv5s/YOLOv8s/YOLOX/YOLO-NAS-S 出现漏检无法有效检测出车里的人(小目标检测);
- RT-DETR-ResNet50则检出率很高但也容易出现误检,如将汽车识别成火车;
- YOLOv6s/YOLOv7 则能够完美检测出来,且YOLOv7的回归框精度更高;
因此关键还是要针对不同的场景选取合适的模型。
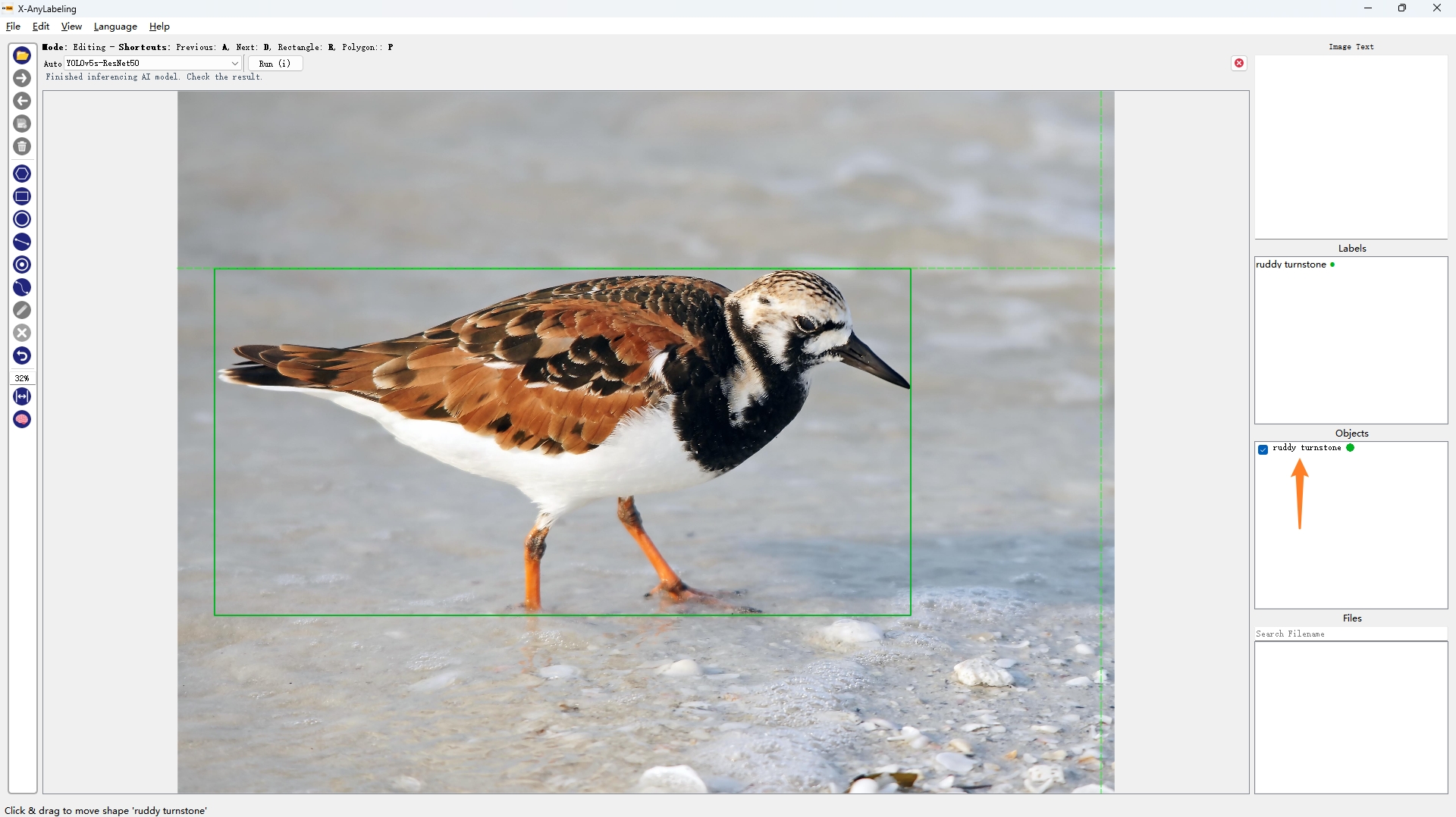
- 细粒度检测分类
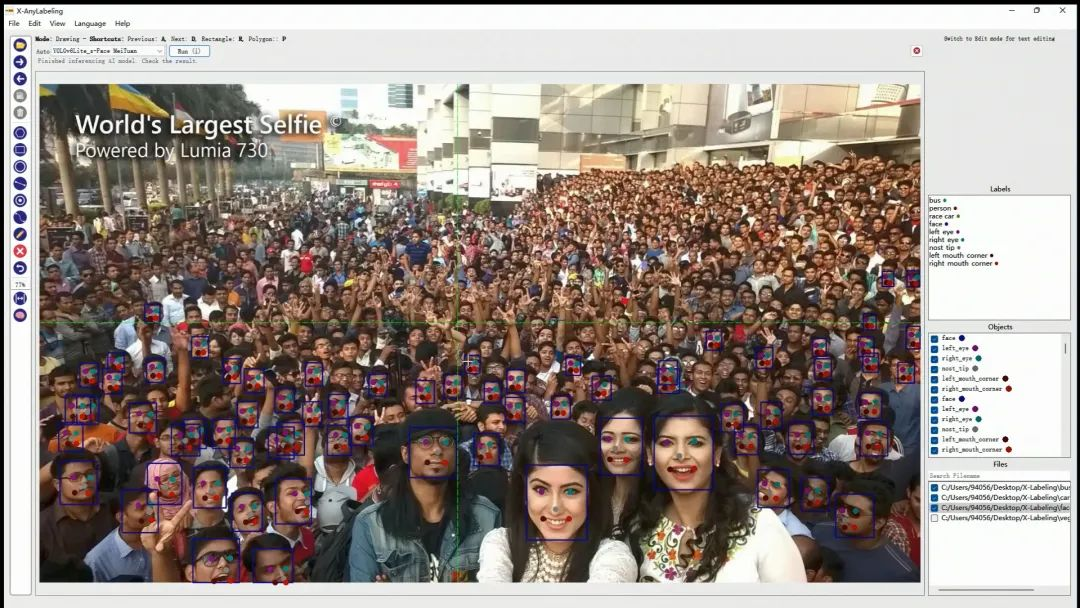
- 人脸检测+关键点回归
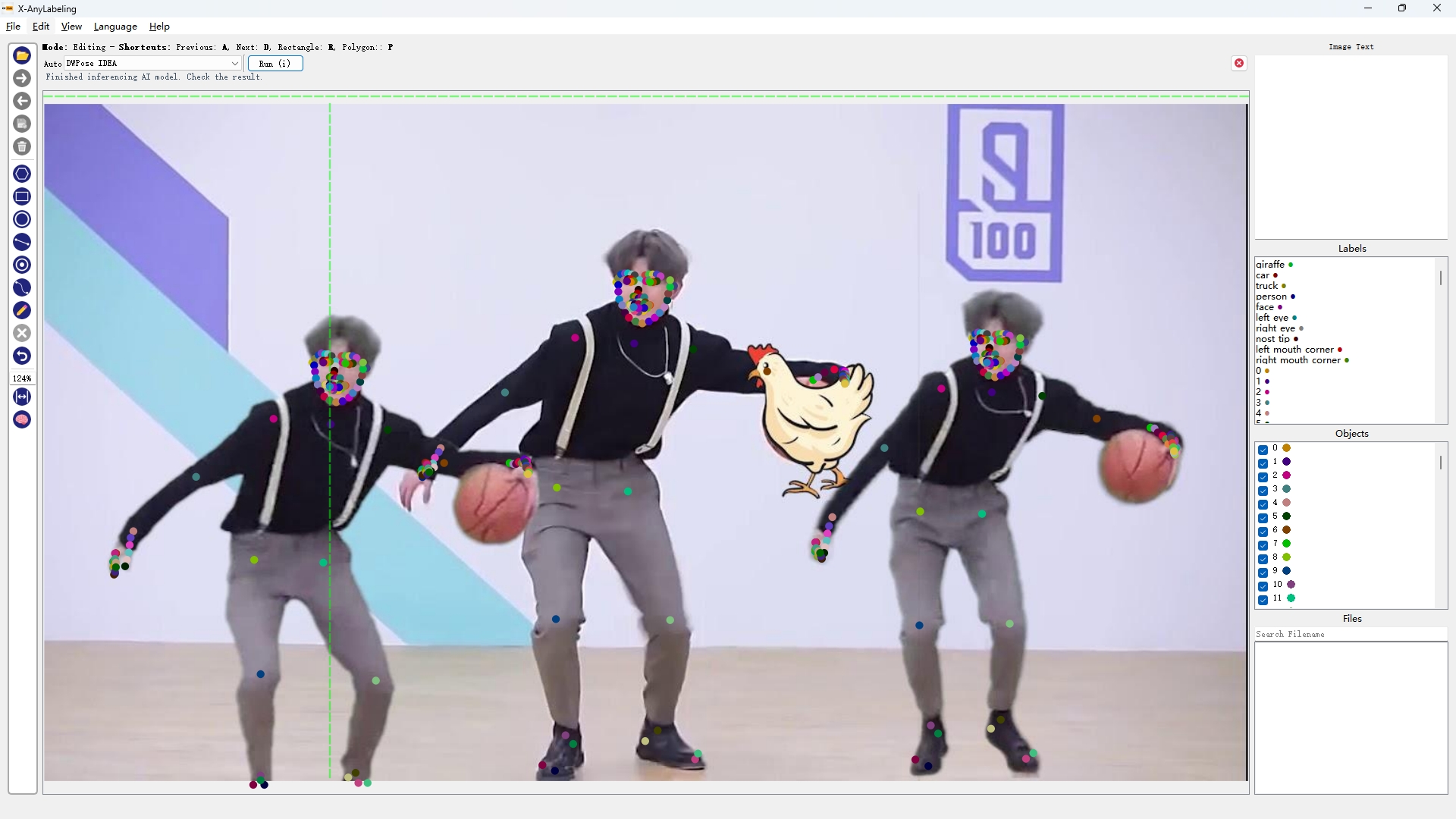
- 全身人体姿态估计
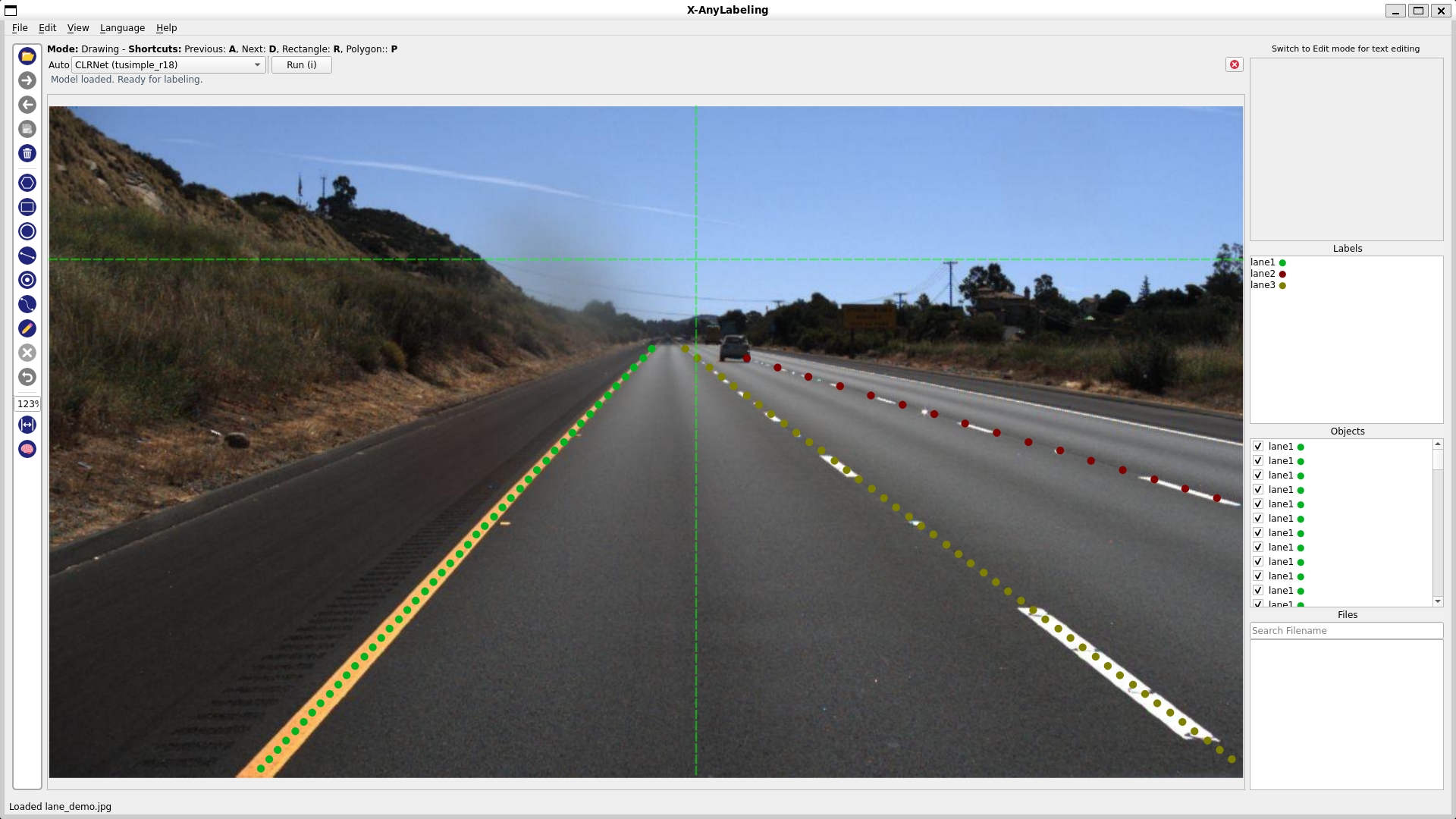
- 车道线检测
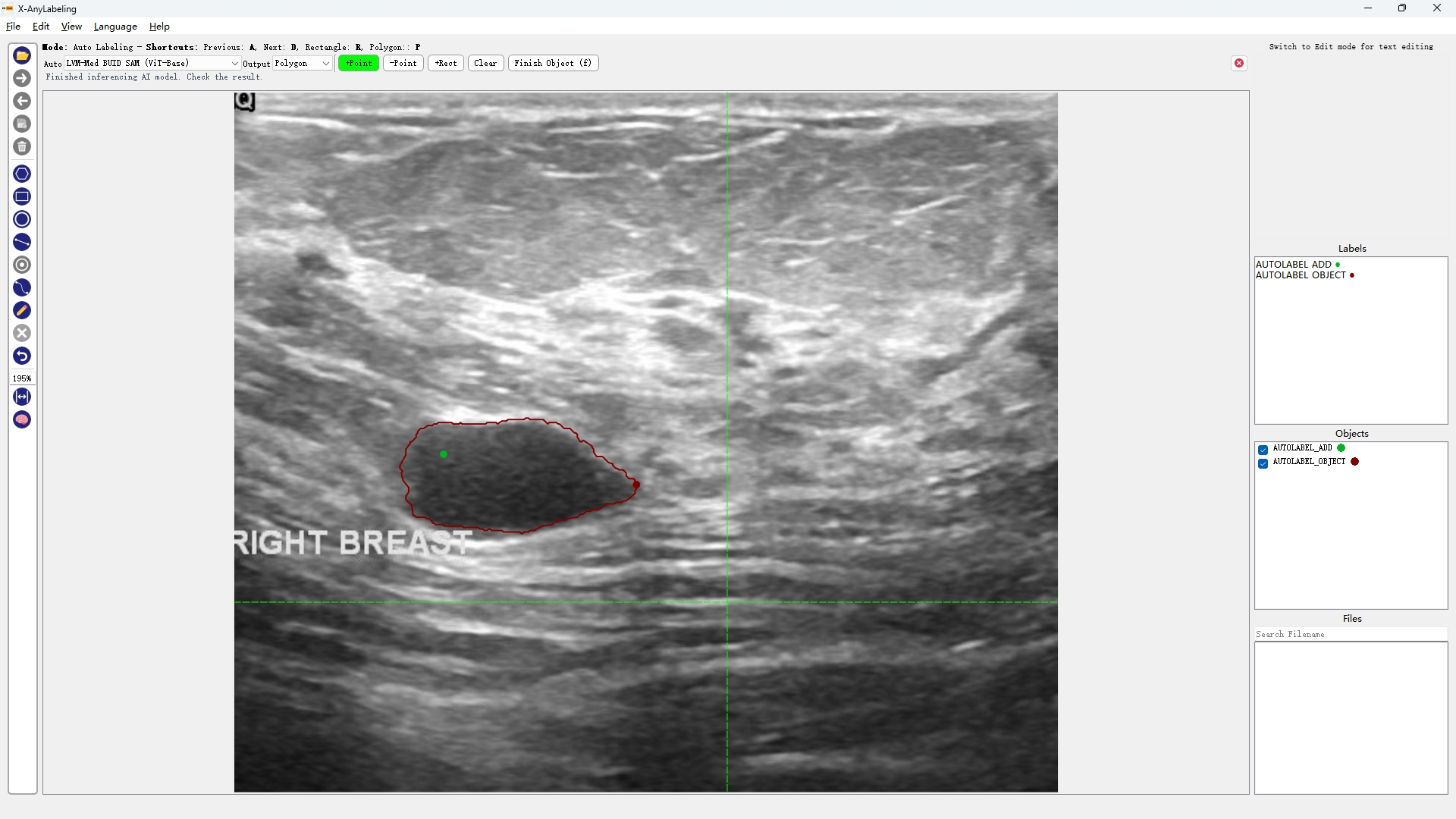
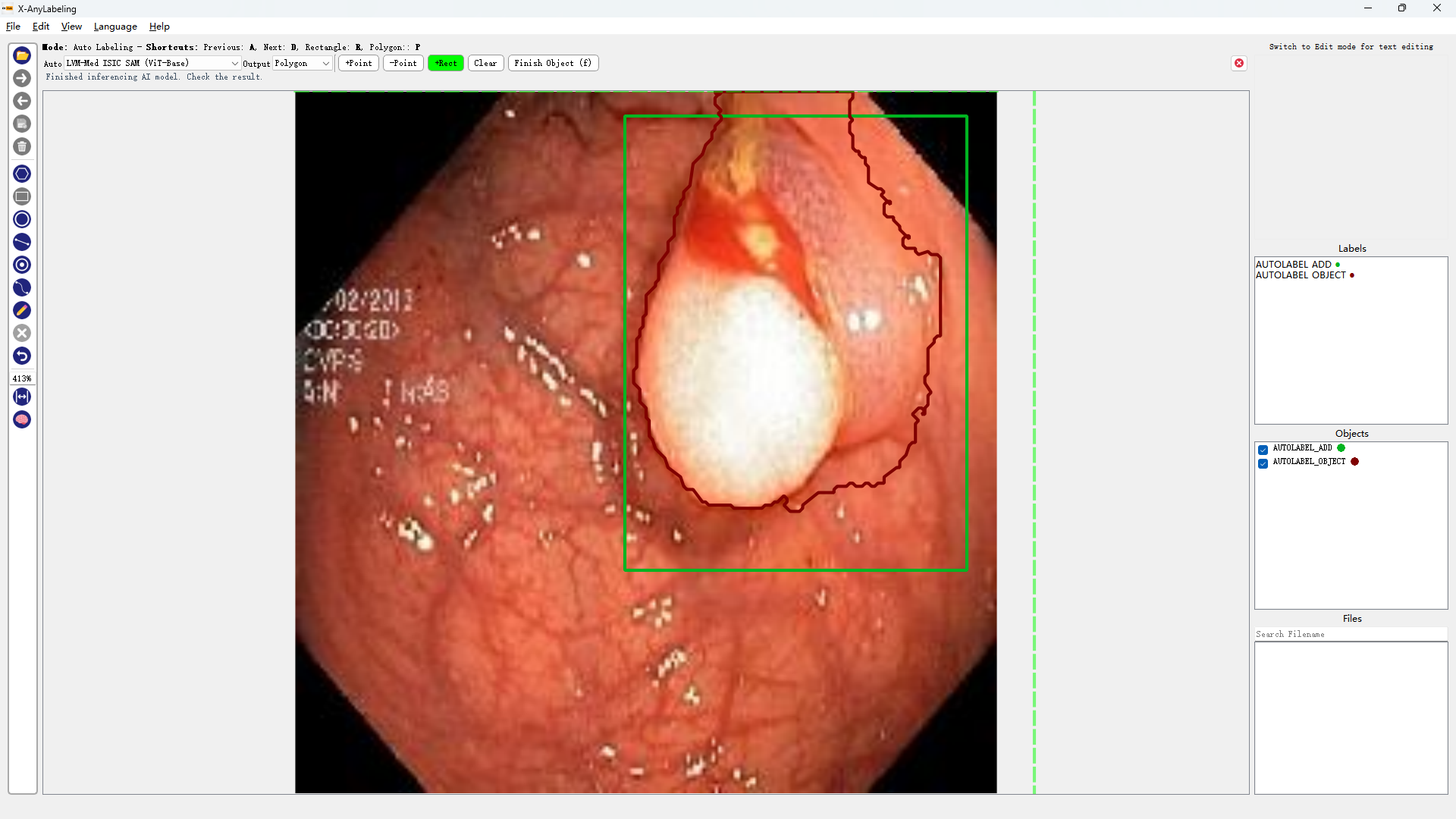
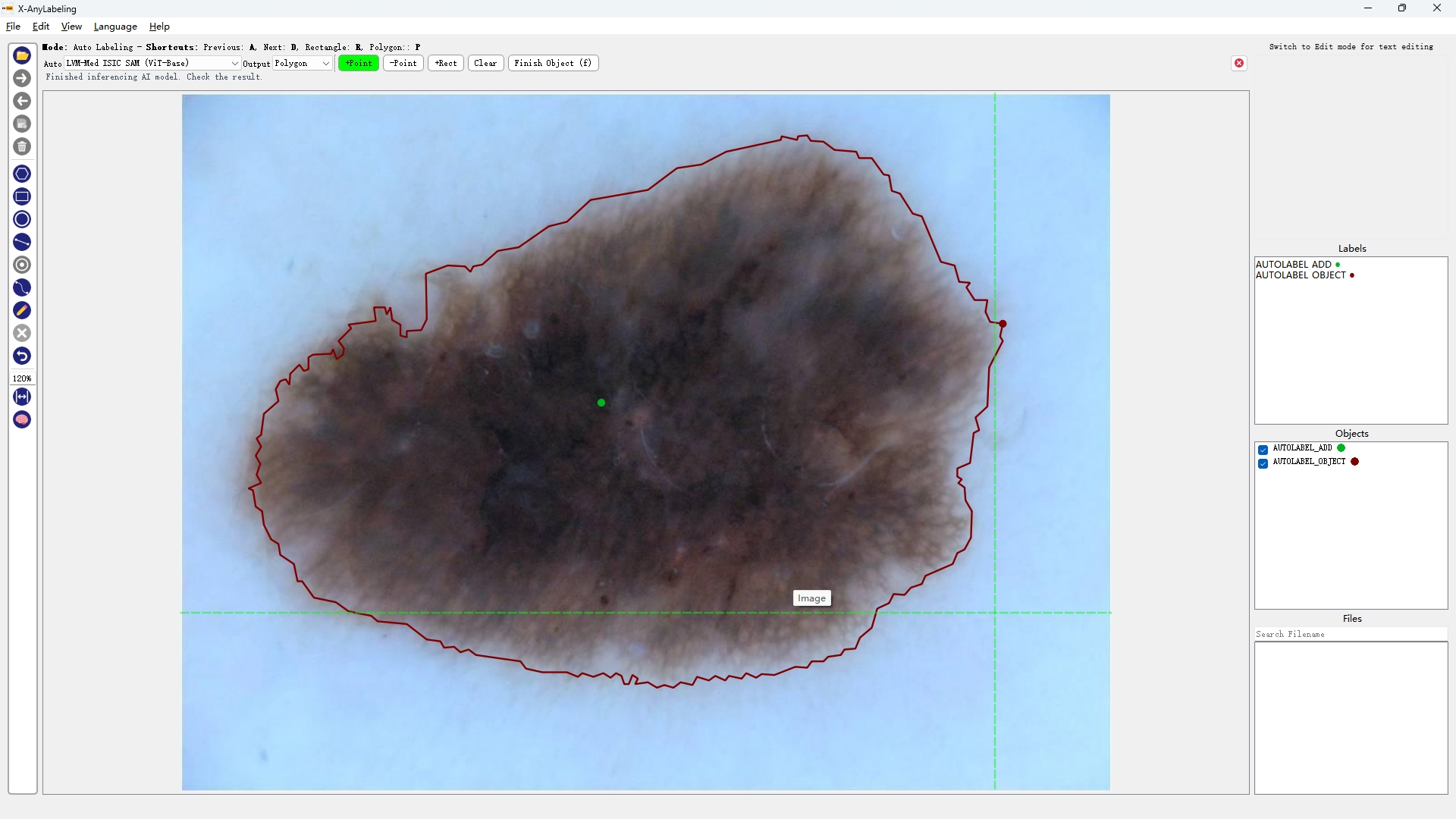
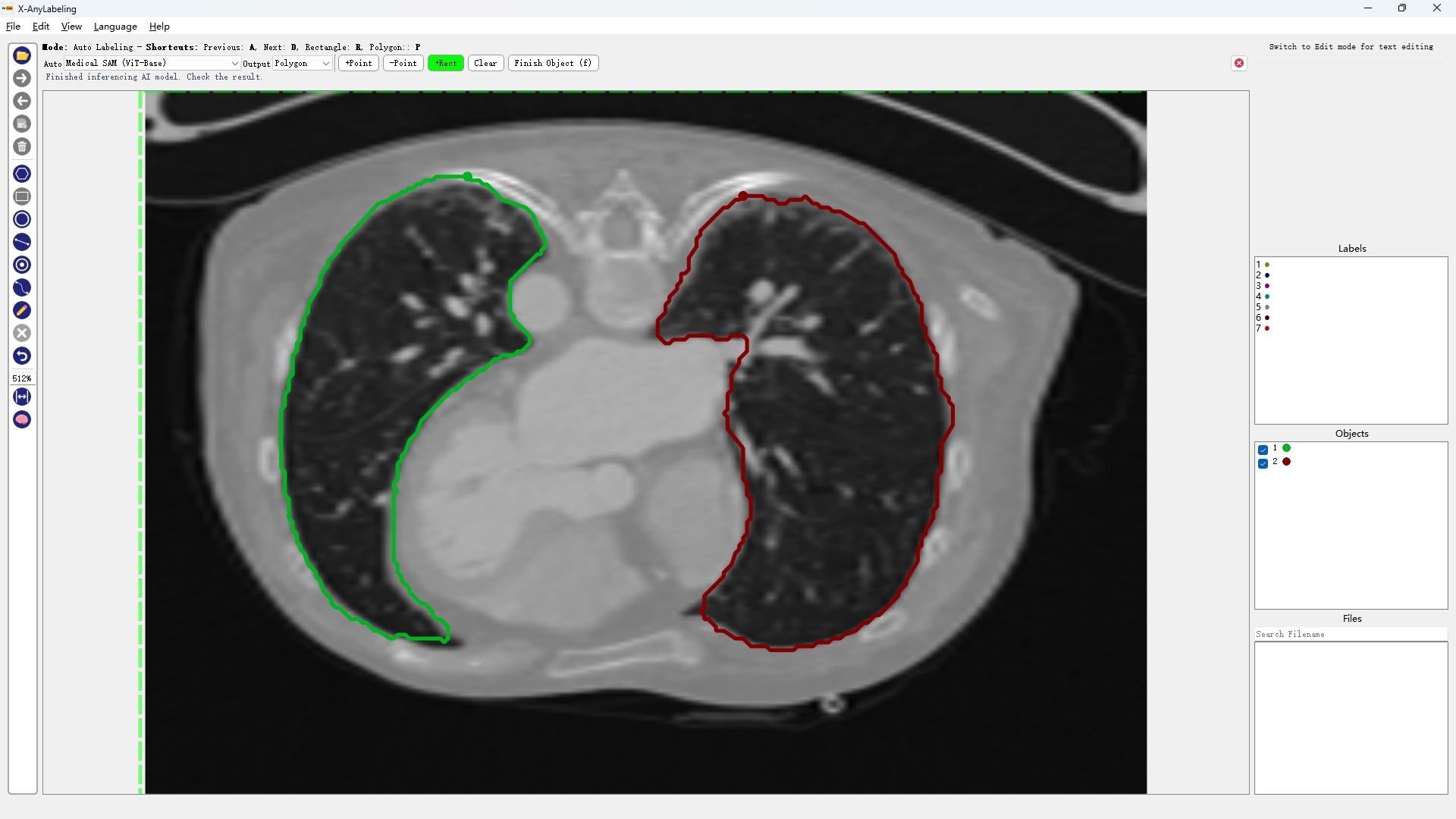
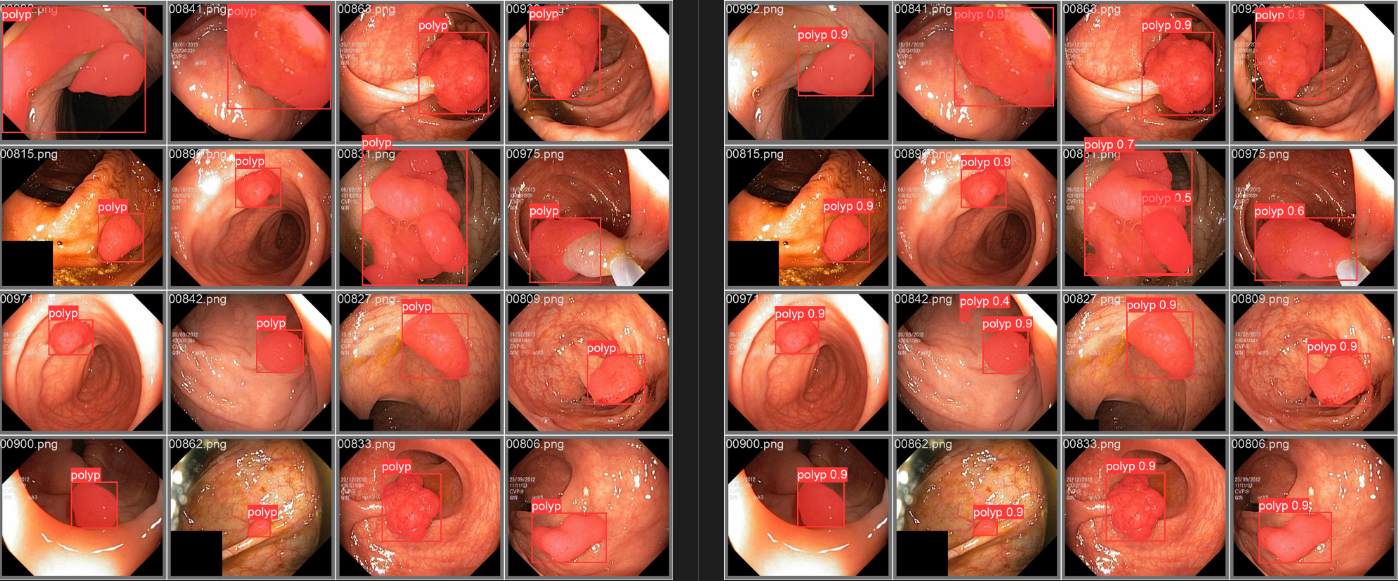
- 医学图像分割
超声波乳腺癌分割 | 结直肠息肉分割 | 皮肤镜病变分割
 |
 |
 |
|---|---|---|
| BUID-SAM | Kvasir-SAM | ISIC-SAM |
通用医学图像分割一切
 |
 |
|---|---|
| SAM-Med2D | Med-SAM |
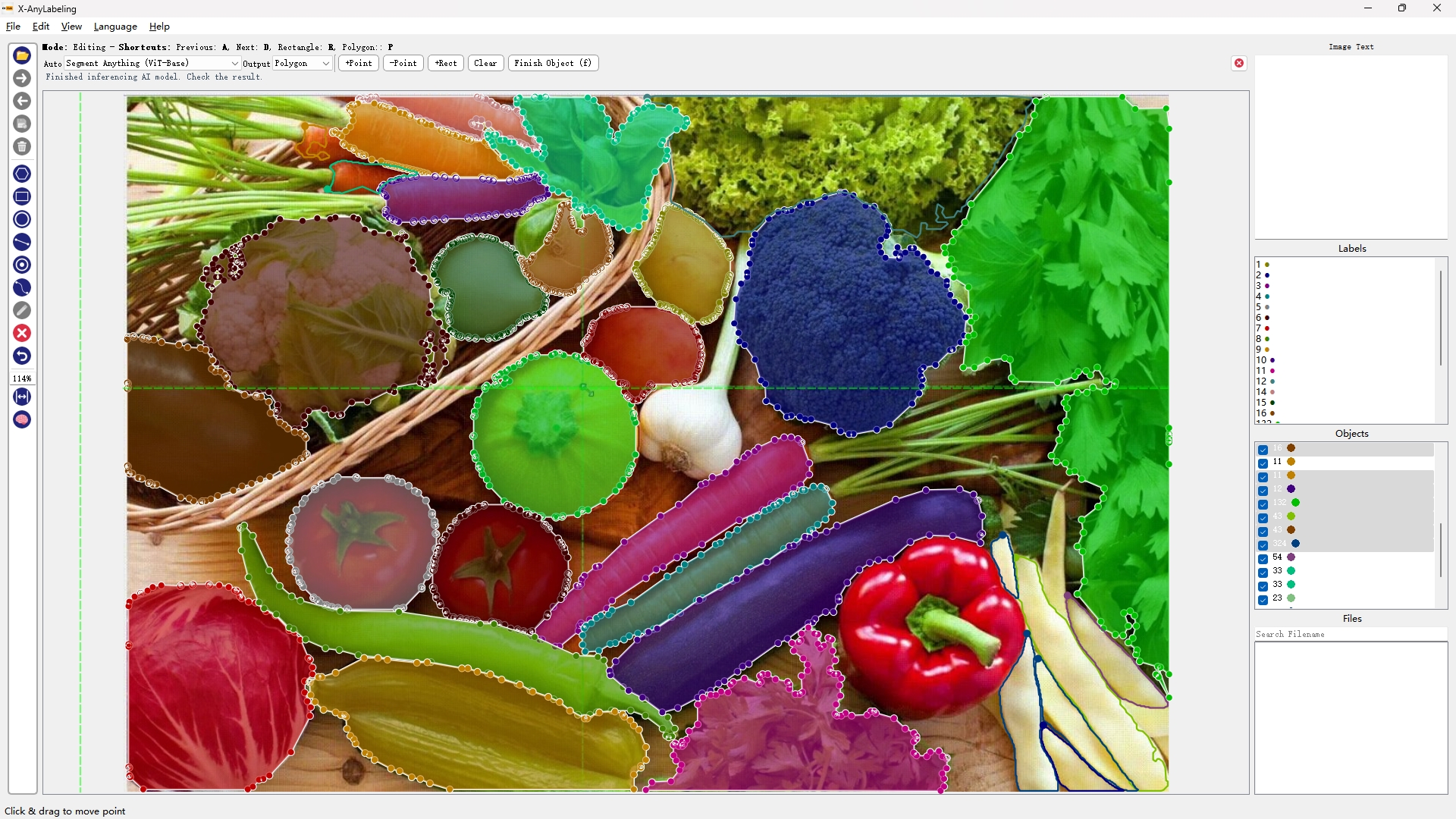
- 自然图像分割
 |
|
|
|
|---|---|---|---|
| SAM-ViT-B | SAM-ViT-L | SAM-ViT-H | Mobile-SAM |
此外,为了加速模型推理速度,提供了多个量化版本及LRU缓冲机制,极大提升用户体验。
- OCR
文本标签是许多标注项目中的一项常见任务,但遗憾的是在 Labelme 和 LabelImg 中仍然没有得到很好的支持。X-AnyLabeling 中完美支持了这一项新功能。
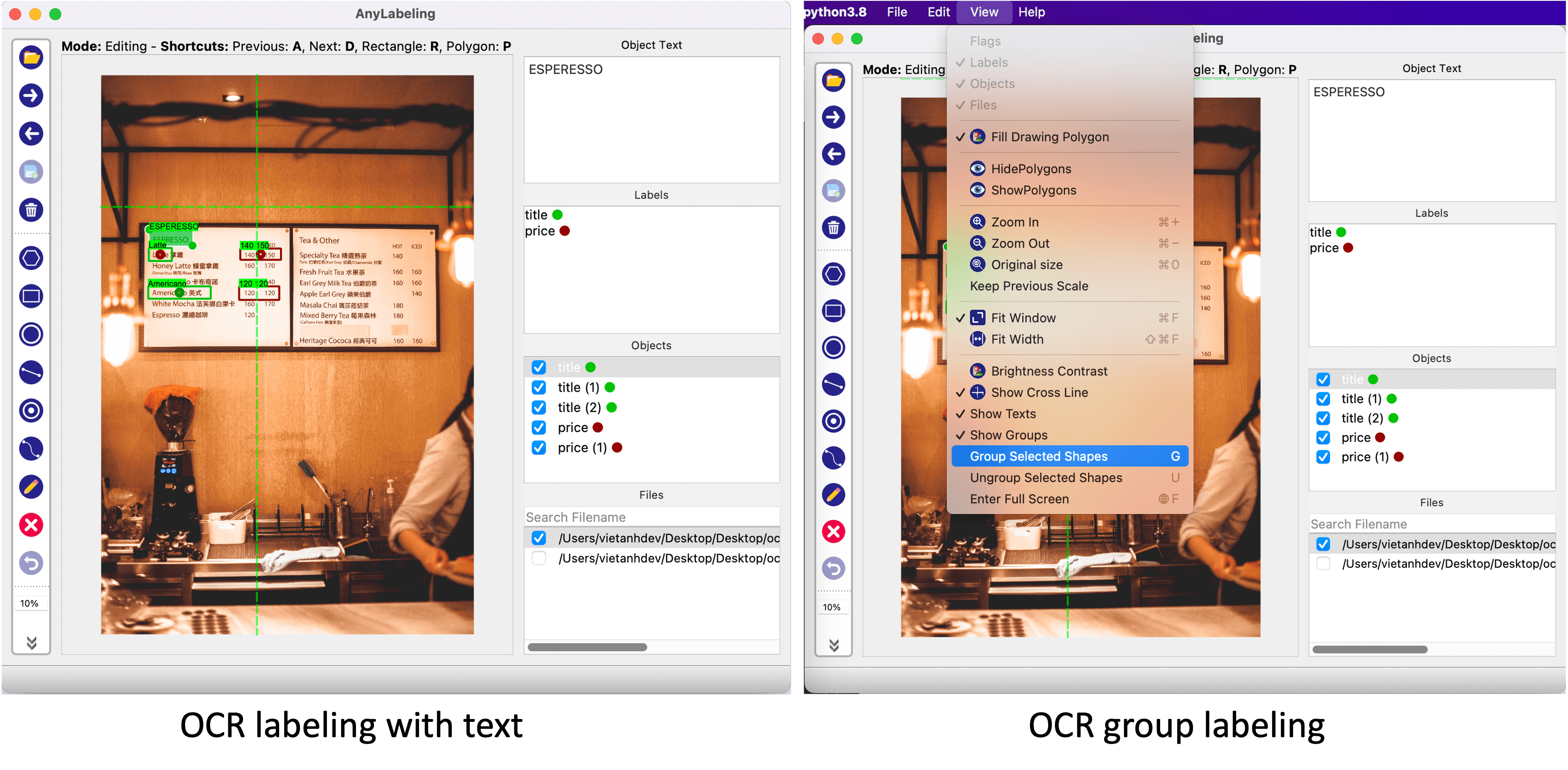
- 图像文本标签:用户可以切换到编辑模式并更新图像的文本——可以是图像名称或图像描述。
- 文本检测标签:当用户创建新对象并切换到编辑模式时,可以更新对象的文本。
- 文本分组:想象一下,当使用 KIE(键信息提取)时,需要将文本分组到不同的字段中,包含标题和值。在这种情况下,你可以使用文本分组功能。当创建一个新对象时,我们同样可以通过选择它们并按
G将其与其他对象组合在一起。分组的对象将用相同的颜色标记。当然,也可以按快捷键U取消组合。
注:标注的文本和分组信息将与其他标注保存在同一个
JSON文件中。文本将保存在text对象的字段中,组信息将保存在字段中group_id。
- 其它
OCR识别
多模态技术
更多能力陆续接入中,敬请期待…
标签格式
X-AnyLabeling 目前输出的标注文件格式遵循 Labelme 框架(此处定义为custom样式),为了帮助用户真正落实到应用上,提供了一系列常用的转换工作,包括但不仅限于以下功能,打通整个闭环:
- Box-level
- custom ↔ VOC
- custom ↔ COCO
- custom ↔ YOLO
- Polygon-level
- custom ↔ VOC
- custom ↔ COCO
- custom ↔ YOLO
- Mask-level
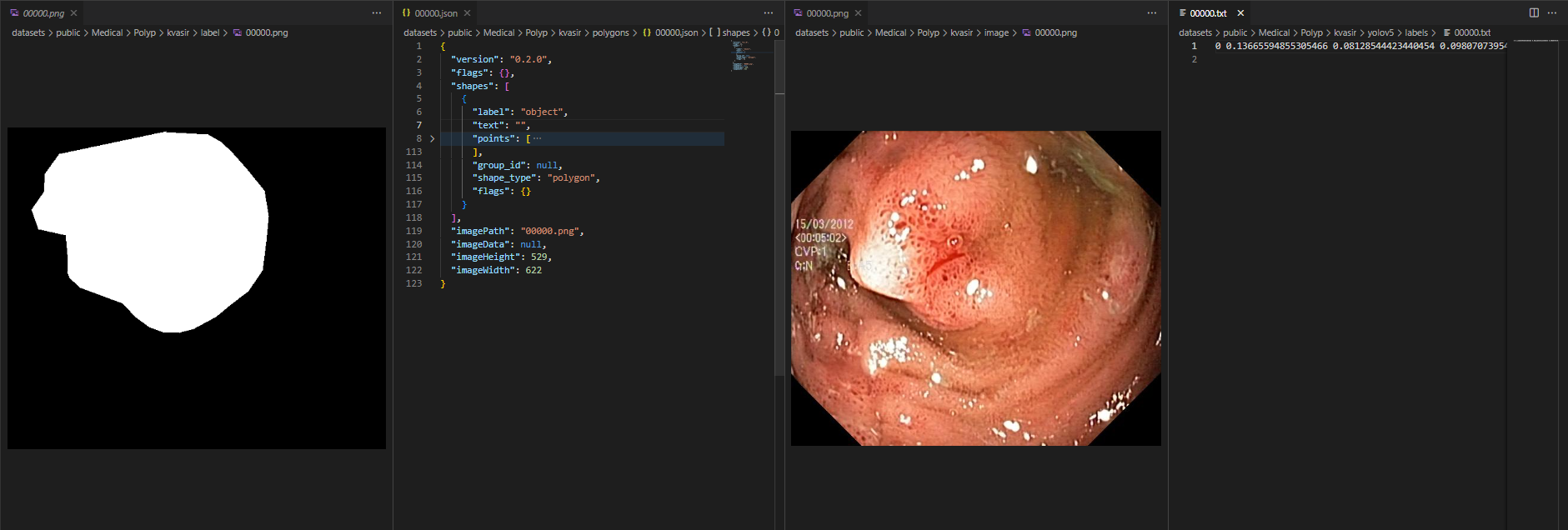
通过上述转换,我们可以很轻松地将图片格式的掩码转换成 custom 格式导入到标注工具进行修正后再直接导出 YOLO 系列或其它框架所需的多边形标签格式进行快速训练,如下图展示了基于 YOLOv5 训练的效果图。更多详情请参考“帮助文档”。
推理架构
模型推理架构如下图所示:

LabelingWidget是 SAM 模型推理功能所需的主要小部件。绘图区域由Canvas类处理。AutoLabelingWidget则作为自动标记功能和ModelManager的主要部件用于管理和运行 AI 模型。
SAM 是 Meta 的新细分模型。使用 11M 图像和 1B 分割掩码进行训练,它可以在不针对特定对象进行训练的情况下分割图像中的对象。出于这个原因,Segment Anything 是自动标记的一个很好的候选框,即使是从未见过的新对象。
优化点:
-
因为
Encoder的计算是需要时间的,所以我们可以把结果缓存起来,也可以对Encoder在以后的图片上做预计算。这将减少用户等待编码器运行的时间。 -
对于缓存,添加了一个
LRU缓存来保存编码器的结果。图像保存在缓存中,键是标签路径。当缓存中存在图像嵌入时,不会再次运行编码器,这样可以节省很多时间。缓存大小默认为 10 张图像。 -
对于预计算,创建一个线程来为下一个图像运行编码器。当加载新图像时,它将和下一张图像一起发送到工作线程进行编码器计算。之后,
image embedding会缓存到上面的LRU缓存中。如果图像已经在缓存中,工作线程将跳过它。
SAM 模型使用步骤
- 选择左侧的
Brain按钮以激活自动标记。 - 从下拉菜单
Model中选择Segment Anything Models类型的模型。模型精度和速度因模型而异。其中,Segment Anything Model (ViT-B)是最快的但精度不高。Segment Anything Model (ViT-H)是最慢和最准确的。Quant表示量化过的模型。 - 使用自动分割标记工具标记对象。
- +Point:添加一个属于对象的点。
- -Point:移除一个你想从对象中排除的点。
- +Rect:绘制一个包含对象的矩形。Segment Anything 将自动分割对象。
- 清除:清除所有自动分段标记。
- 完成对象(f):当完成当前标记后,我们可以及时按下快捷键f,输入标签名称并保存对象。
注意事项:
- 由于 SAM 部署时采用了编解码分离的范式并应用了 LRU 机制,因此第一次进行推理时后天会缓存多张(可自行设置)图片的
image_embedding,具体见下述"集成方式"章节。 X-AnyLabeling在第一次运行任何模型时,需要从远程服务器下载模型,可能需要一段时间,这具体取决于本地的网络速度和服务运营商。此外,由于当前模型存放在 github 托管,因此如果没有开启科学上网的化,大概率会由于下载失败而中断,可以参考后续实操步骤解决。
集成方式
Segment Anything Model 分为两部分:一个很heavy的编码器和一个lightweight解码器。编码器从输入图像中提取图像嵌入。基于嵌入和输入提示(点、框、掩码),解码器生成输出掩码。解码器可以在单掩码或多掩码模式下运行。

在演示中,Meta 在服务器中运行编码器,而解码器可以在用户的浏览器中实时运行,如此一来用户便可以在其中输入点和框并立即接收输出。在本项目中,我们还为每个图像只运行一次编码器。之后,根据用户提示的变化(点、框),运行解码器以生成输出掩码。项目添加了后处理步骤来查找轮廓并生成用于标记的形状(多边形、矩形等)。
使用手册
如何修改自定义快捷键?
可通过修改当前设备的用户根目录下的 .anylabelingrc 文件,如:
#Linux
cd ~/.anylabelingrc
#Windows
cd C:\\Users\\xxx\\.anylabelingrc
如何支持自定义模型?
已适配模型
- 对于
X-AnyLalabeling中已提供的基础模型,可参考以下操作:
- 创建配置文件
进入 X-AnyLabeling 项目工程,查看所需的配置文件

- 查看配置文件
配置文件需要遵循以下格式,以 rtdetr_r50.yaml 为例:
type: rtdetr
name: rtdetr_r50-r20230520
display_name: RT-DETR (ResNet50) PaddleDetection
model_path: https://github.com/CVHub520/X-AnyLabeling/releases/download/v0.1.0/rtdetr_r50vd_6x_coco.onnx
input_width: 640
input_height: 640
score_threshold: 0.45
classes:
- person
- bicycle
- car
...
我们可以根据 model_path 字段下载所需的模型权重,同时也可根据需要设置相应的超参数。
- 配置模型文件
将下载好的 *.onnx 文件放置到当前系统用户目录下的 anylabeling_data/models/xxx 下。这里 xxx 为对应的模型的名称,具体地可参考 X-anylabeling/anylabeling/configs/auto_labeling/models.yaml 文件中的对应 model_name 字段,示例如下:
(x-anylabeling) cvhub@CVHub:~/anylabeling_data$ tree
.
└── models
├── mobile_sam_vit_h-r20230810
│ ├── mobile_sam.encoder.onnx
│ └── sam_vit_h_4b8939.decoder.onnx
├── yolov5s-r20230520
│ └── yolov5s.onnx
├── yolov6lite_s_face-r20230520
└── yolox_l_dwpose_ucoco-r20230820
├── dw-ll_ucoco_384.onnx
└── yolox_l.onnx
只需将下载好的模型权重放置上述对应位置,重新打开标注工具载入,点击“运行”或按下快捷键i实现一键标注功能。
未适配模型
- 对于未适配模型,可以参考以下四个步骤自行适配:
如何编译打包成可执行文件?
可参考以下打包指令:
#Windows-CPU
bash scripts/build_executable.sh win-cpu
#Windows-GPU
bash scripts/build_executable.sh win-gpu
#Linux-CPU
bash scripts/build_executable.sh linux-cpu
#Linux-GPU
bash scripts/build_executable.sh linux-gpu
注意事项:
- 编译前请针对相应的 GPU/CPU 版本修改
anylabeling/app_info.py文件中的__preferred_device__参数,同时根据对应参数激活对应的 GPU/CPU 虚拟环境;- 如果需要编译
GPU版本,请通过pip install -r requirements-gpu-dev.txt安装对应的环境;特别的,对于Windows-GPU版本的编译,请自行修改anylabeling-win-gpu.spec的datas列表参数,将您本地的onnxruntime-gpu的相关动态库*.dll添加进列表中;此外,下载onnxruntime-gpu包是需要根据CUDA版本进行适配,具体匹配表可参考官方文档说明。- 对于
macos版本可自行参考anylabeling-win-*.spec脚本进行修改。
更多详情,敬请登陆github,欢迎Star。