目录
前言:
今天我们就开始学习排序算法,排序算法也是数据结构与算法在重要组成部分之一,排序算法是最经典的算法知识。因为其实现代码短,应该广,在面试中经常会问到排序算法及其相关的问题。一般在面试中最常考的是快速排序和归并排序等基本的排序算法,并且经常要求现场手写基本的排序算法。如果这些问题回答不好,估计面试就凉凉了。所以熟练掌握排序算法思想及其特点并能够熟练地手写代码至关重要。好了,下面就开始我们今天的学习吧!
冒泡排序
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
原理图
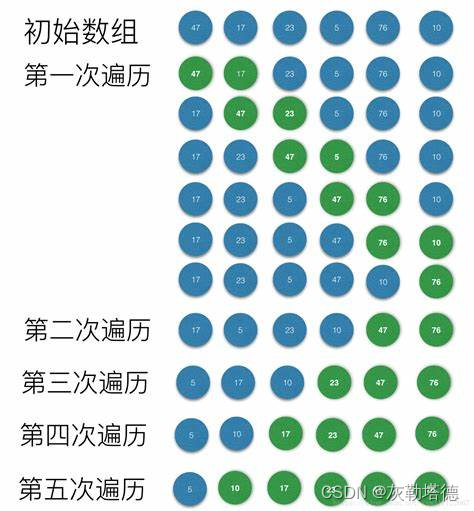
代码实现
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<time.h>
//冒泡排序
void bubble_sort(int* n,int length) {
for (int i = 0; i < length-1; i++)
{
for (int j = 0; j<length - i-1; j++)
{
if (n[j] > n[j + 1]) {
int temp = n[j];
n[j] = n[j + 1];
n[j + 1] = temp;
}
}
}
}
int main() {
int array[10];
srand((unsigned)time(0));//设置随机数种子
for (int i = 0; i < 10; i++) {
array[i] = rand() % 20; //产生10个0~20的随机数
}
for (int i = 0; i < sizeof(array) / sizeof(int); i++) {
printf("%d ", array[i]);
}
printf("\n排序后:");
bubble_sort(array, sizeof(array) / sizeof(int));
for (int i = 0; i < sizeof(array) / sizeof(int); i++) {
printf("%d ", array[i]);
}
}
//输出结果
//5 4 11 8 2 16 16 9 2 15
//排序后:2 2 4 5 8 9 11 15 16 16分析总结
冒泡排序是一种稳定的排序算法(当出现相同的数字的时候相对位置不进行交换),在有序的情况下冒泡排序的时间复杂度是O(n),当然,如果在完全逆序的时候,其复杂度是O(n^2),如果要排序的数字非常多的话,那么这个时间复杂度就会相当吓人,整体来说,冒泡排序的时间复杂度是O(n^2)。冒泡排序作为最简单的排序算法之一,冒泡排序给我的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来说并没有什么太大作用。
选择排序
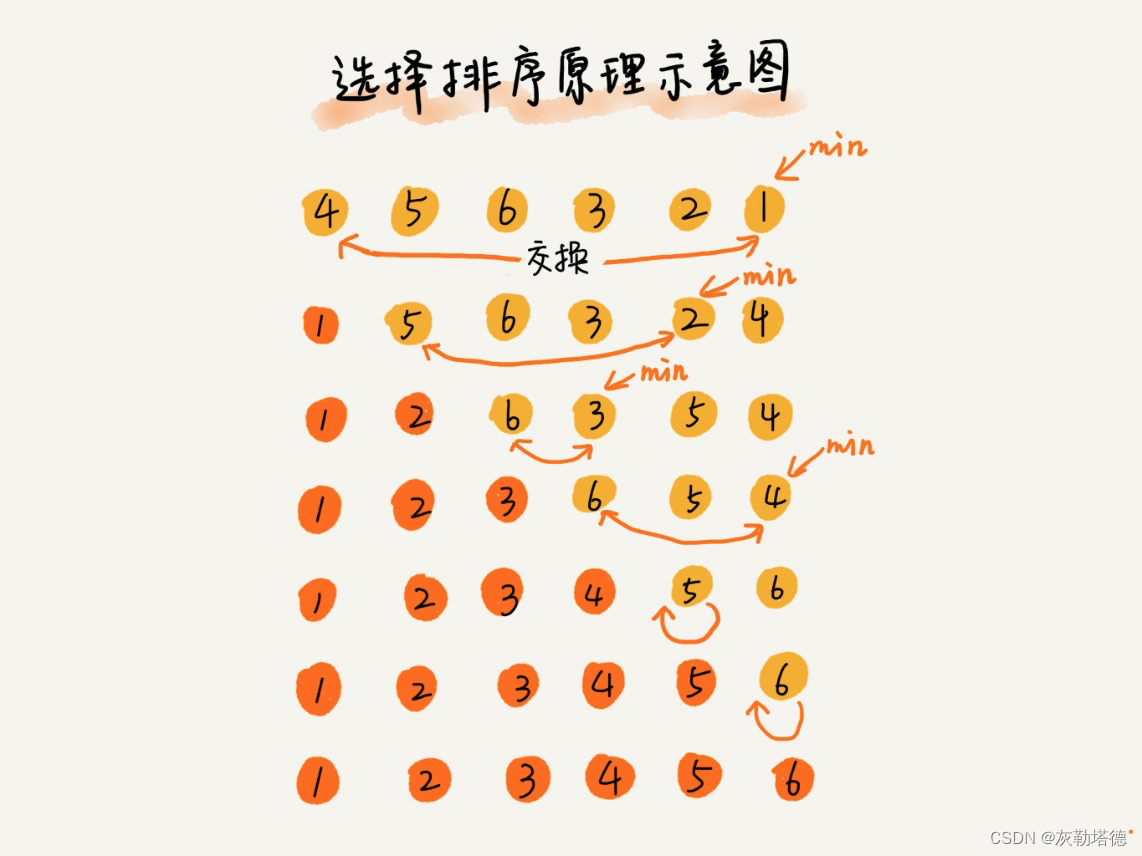
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是:第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零
原理图
代码实现
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<time.h>
//选择排序
void select_sort(int* n, int length) {
for (int i = 0; i < length-1; i++) {
for (int j = i + 1; j < length; j++) {
if (n[i] > n[j])
{
int temp = n[i];
n[i] = n[j];
n[j] = temp;
}
}
}
}
int main() {
int array[10];
srand((unsigned)time(0));
for (int i = 0; i < 10; i++) {
array[i] = rand() % 20;
}
for (int i = 0; i < sizeof(array) / sizeof(int); i++) {
printf("%d ", array[i]);
}
printf("\n排序后:");
select_sort(array, sizeof(array) / sizeof(int));
for (int i = 0; i < sizeof(array) / sizeof(int); i++) {
printf("%d ", array[i]);
}
}
//输出结果:
//2 12 8 3 13 17 18 12 4 14
//排序后:2 3 4 8 12 12 13 14 17 18分析总结
时间复杂度分享
选择排序的最大特点是减少了数字交换的时间,对交换次数而言,当最好的时候,交换0次,最差时,交换n-1次,交换次数比冒泡排序少多了,由于交换所需CPU时间比比较所需的CPU时间多,n值较小时,选择排序比冒泡排序快。但是基于整体的排序时间(包括比较此时和交换次数),其时间复杂度是O(n^2)。
稳定性分析
选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n-1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。那么,在一趟选择,如果一个元素比当前元素小,而该小的元素又出现在一个和当前元素相等的元素后面,那么交换后稳定性就被破坏了。举个例子,序列5 8 5 2 9,我们知道第一遍选择第1个元素5会和2交换,那么原序列中两个5的相对前后顺序就被破坏了,所以选择排序是一个不稳定的排序算法。
好了,以上就是今天的全部内容了,我们下一期继续学习更高级的排序算法,下次见!
分享一张壁纸: