ps:自己第一次正式参加的竞赛,第一题做的很快,之后第二题用了一点时间,第三题做出来,但是超时,最后完成了两题。
大家的实力太恐怖了,第一名八分钟做完全部,而我八分钟还在第一题。一个半小时也没做完,究其原因,还是对算法掌握不熟练。还是要继续努力锤炼自己!
6124. 第一个出现两次的字母


还是先看约束,发现范围是100以内,就不用担心和超时的问题了
接下来看题目要求,找出第一个出现两次的字母。我第一时间想到的是用一个列表记录出现的元素,如果某元素出现两次,返回这个元素。时间复杂度O(n) ,空间复杂度O(n)
class Solution:
def repeatedCharacter(self, s: str) -> str:
dic=dict()
for i in s:
if i in dic:
return i
else:
dic[i]=0
return -1
虽然很快的完成了题目,但觉得肯定不是最优解。查找重复的元素,最好的办法应该是异或
6125. 相等行列对
6125. 相等行列对

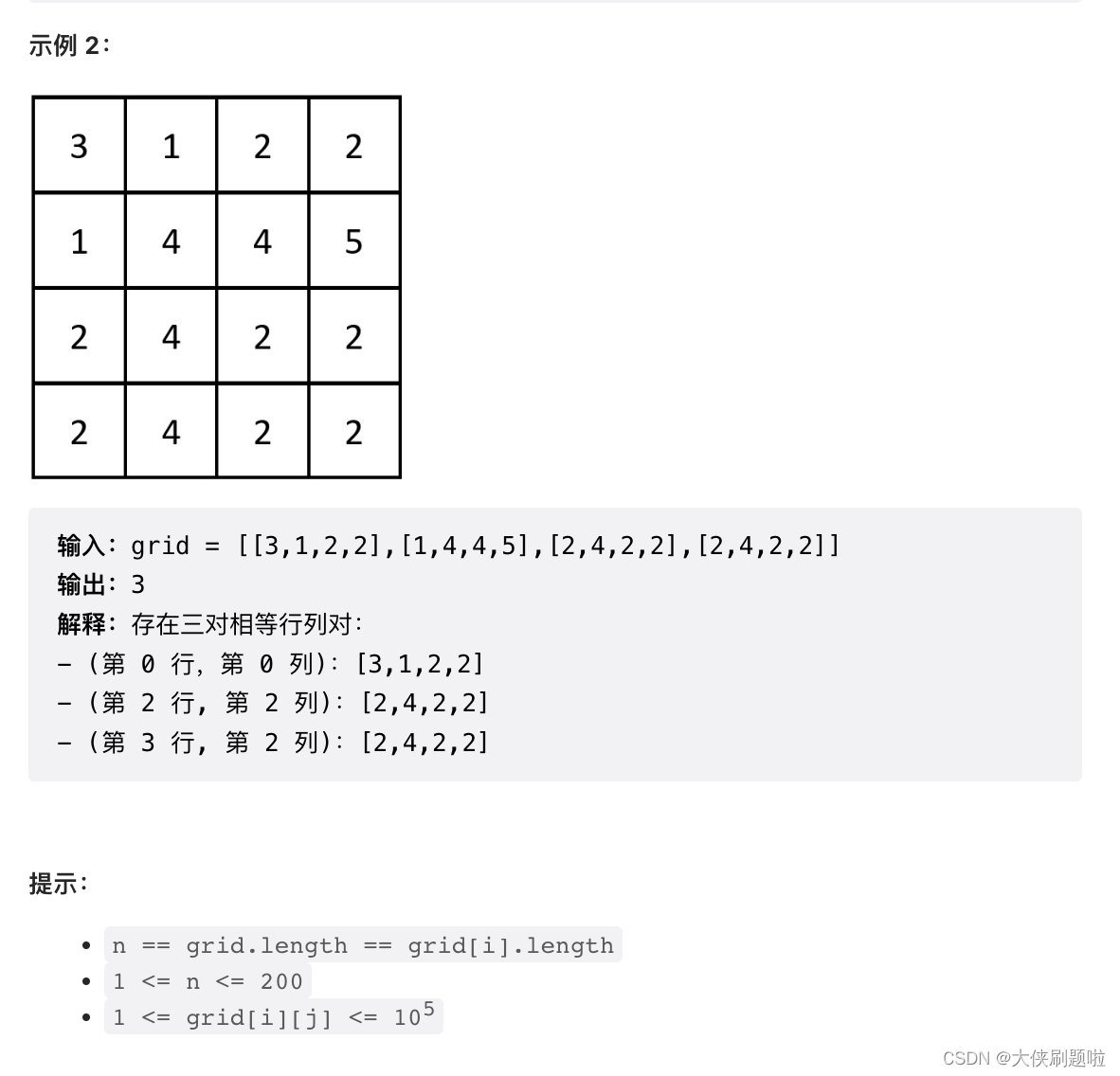
首先看约束条件n在200以内,所以就算是暴力求解也不会运算很长时间。
在看题目,寻找相同的行列,我第一时间想的就是暴力求解,将每行每列都变成字符串,然后比较,如果某行的元素字符串在列中出现,那么记为出现一对。但是这样有个问题,如果列中有两个相同的列,应该记为两次。最终我的方法是统计列中字符串出现的次数。(我发现我就是统计狂魔),于是有了下面的代码
class Solution:
def equalPairs(self, grid: List[List[int]]) -> int:
le = len(grid[0])
hang_str = []
lie_str = []
count=0
dic={
}
for i in range(le):
hang_str.append(",".join([str(i ) for i in grid[i]]))
lie_str.append(",".join([ str(k[i]) for k in grid ]))
for k in lie_str:
if not k in dic:
dic[k]=1
else:
dic[k]+=1
# print(hang_str,lie_str)
for i in hang_str:
count+=dic.get(i,0)
return count
但是暴力的算法,可以有,但是没必要。于是我又去leetcode看了其他人的题解,新思路没学到,以下这个方法和我的思路一致,但是简洁,学到了几个python的内置函数。
class Solution:
def equalPairs(self, grid: List[List[int]]) -> int:
cnt = Counter(tuple(row) for row in grid)
return sum(cnt[col] for col in zip(*grid)) #统计列在行中出现的次数
作者:endlesscheng
链接:https://leetcode.cn/problems/equal-row-and-column-pairs/solution/ha-xi-biao-python-liang-xing-by-endlessc-ljae
cnt是count的缩写,学习了
*grid 是解包,有关✳️的用法上一篇复盘提到了leetcode第302场周赛复盘
然后接下来就是一个zip函数,如果是zip两个列表的话,就是按照列打包成元组。这样正好达到统计列的目的。
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象。
a = [1,2,3]
b = [4,5,6]
c = [4,5,6,7,8]
zipped = zip(a,b) # 返回一个对象
zipped <zip object at 0x103abc288>
list(zipped) # list() 转换为列表
[(1, 4), (2, 5), (3, 6)]
list(zip(a,c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
6126. 设计食物评分系统
6126. 设计食物评分系统



首先看约束条件,n的范围是 1 0 4 10^4 104 ,调用次数也是 1 0 4 10^4 104,因此要考虑是否会超时。
下面分析题目:主要实现两个功能:
- 修改食物的评分
- 找到一种烹调方式下,评分最高的食物(同分数情况下,取字典序小的那个)
先看功能一,修改食物的评分,foods中所有的字符互不相同,可以使用foods作为键,构建一个字典food_info,用于快速找到food对应的评分“rating” 实现线性的修改。
food_info={
'food':
{
'rating':xx,
'suisines':'xxx'
}
}
suisines_info={
'suisines':
[(rating1,food1),(rating2,food2)]
}
在看功能二:需要找到一种烹调方式下,评分最高的食物。可以使用suisines建立一个字典suisines_info,值为有序列表,元素为(rating,food)的元组。这样需要找最高评分的食物,只要取字典中对应烹调方式下的列表的第一个元素。在功能一修改评分时,同样会引起排名的变化,修改后重新排序会消耗时间,导致超时。由于修改评分时的列表是有序列表,因此可以先删除再插入的方式,这样就不要用在此进行排序了。(整个有序列表的构建都是通过,插入有序列表的方式完成)
PS:有的读者可能认为food_info字典没什么用,实则并非如此。在suisines_info字典,删除对应(food,rating)元组时,首先不知道food对应的是哪一种烹调方式suisines,即不知道字典的键是多少,此外找到键之后还需要找到对应的食物名food。也就是说每一次修改都需要遍历整个suisines_info字典,但是使用food_info字典后,只需要O(1)的时间就可以找到,该食物food在suisines_info字典中为位置,以空间换时间。
此外,对于相同值按字典许排列,存在一个小问题:假设列表为
[(16,‘a’),(14,‘c’),(16,‘b’) ]
如果按照分数降序排列的话,那么字母也是降序排列的,得到排序结果如下
[(16,‘b’),(16,‘a’),(14,‘c’) ]
这样的话无法按照题意取到分数最大,字典序号最小的食物名。
这里有个小技巧可以将分数取负值【想法来源:力扣用户 tsreaper】
[(-16,‘a’),(-14,‘b’),(-16,‘c’) ]
然后在升序排列就可以得到
[(-16,‘a’),(-16,‘b’),(-14,‘c’) ]
下面代码
class FoodRatings:
def __init__(self, foods: List[str], cuisines: List[str], ratings: List[int]):
self.info_list = dict()
c=set(cuisines)
self.cuisines_list=dict(zip(c,[ [] for _ in range(len(c))]))
for index, ele in enumerate(foods):
bisect.insort_right(self.cuisines_list[cuisines[index]], (-ratings[index],ele))
self.info_list[ele] = {
'cuisines': cuisines[index], 'ratings': -ratings[index]}
def changeRating(self, food: str, newRating: int) -> None:
ratings=self.info_list[food]['ratings']
cuisine=self.info_list[food]['cuisines']
self.info_list[food]['ratings'] = -newRating
self.cuisines_list[cuisine].remove((ratings, food))
bisect.insort_right(self.cuisines_list[cuisine], (-newRating,food))
def highestRated(self, cuisine: str) -> str:
now,food=self.cuisines_list[cuisine][0]
return food
# Your FoodRatings object will be instantiated and called as such:
# obj = FoodRatings(foods, cuisines, ratings)
# obj.changeRating(food,newRating)
# param_2 = obj.highestRated(cuisine)
这个题目真的是血泪史,只要n大一点,我必超时;但一点一点的调整,终于在超时的边缘提交成功了

6127. 优质数对的数目
6127. 优质数对的数目


首先看约束条件 数字的个数 1 0 5 10^5 105 ,单个数字的大小 1 0 9 10^9 109超级大,因此要考虑怎么优化时间复杂度。此外k的取值范围是[1,60] ,而数字的取值是大于1的,因此当k等于1时,数组中所有的数对都满足条件,当然不包含重复的元素。
下面开始看题目,查找数字数组中的优质数对,优质数对有两个条件
-
这两个数字必须都在数组中出现,可以是同一个数字用两次,重复的数字只算一个;
-
这两个数字的二进制“或”与二进制的“与”中,包含“1”的个数总数应该大于等于k
以3和5为例,3=0b11,5=0b101 3&5=0b1 ,包含1个“1”; 3|5=0b111,包含3个“1”,共计4个
此处有个细节:
当两个数的二进制进行“或” 操作时,结果只会保留两个数字二进制中所有的“1” 但是重叠的为只算一个,所以有:
“或”操作后二进制数中“ 1 ”的个数 = 两个二进制数中“ 1 ”的个数 − 重叠的个数 “或” 操作后二进制数中“1”的个数=两个二进制数中“1”的个数-重叠的个数 “或”操作后二进制数中“1”的个数=两个二进制数中“1”的个数−重叠的个数
当两个数的二进制进行“与” 操作时,结果只会保留两个数字二进制中重叠的“1”
“与”操作后二进制数中“ 1 ”的个数 = 重叠的个数 “与” 操作后二进制数中“1”的个数=重叠的个数 “与”操作后二进制数中“1”的个数=重叠的个数
最终的得出结论
这两个数字的二进制“或”与二进制的“与”中,包含“1”的个数总数=两个数字二进制数中“1”的个数
因此只要求出数组中每一个数字的二进制数中包含“1”的个数,然后求两数之和大于K就可以了。因此将原有数组先去重复,然后将数组中每个数字转化为其二进制中包含1的个数。
如将原数组[1,3,2,1] -去重复->[1,3,2]-转化为“1”的个数->[1,2,1]。
此时这个问题就变成了,在数组中选择两个数使其和大于等于K,有多少种选法
暴力求解的话就是两层for循环,但是这样肯定会超时。
因此首先进行排序,然后从后向前遍历数组,
- 如果当前数组的值的2倍大于等于k,那么次数加一
- 求当前数值nums[i]和目标数值k的差值,在有序数组中寻找差值的位置d,那么d到i中所有的数字都是满足条件的,又由于(1,2)和(2,1)算两个,因此次数应该加2*(i-d)次
分析到问题就解决的差不多了,下面是代码:
class Solution:
def countExcellentPairs(self, nums: List[int], k: int) -> int:
cnt = 0
nums = sorted([bin(i).count("1") for i in set(nums)])
length = len(nums)
if k == 1:
return length * length
for i in range(length-1,-1,-1):
if nums[i] * 2 >= k:
cnt += 1
index = bisect_left(nums, k - nums[i])
if index>i:#如果index的位置大于i 不合法,因为已经遍历过了
break
cnt += 2 * ( i-index)
return cnt
不保证以上思路没有问题,欢迎一起交流