接着上一篇我们继续来研究char类型和浮点类型的数据的储存
1.char类型的数据储存方式
直接用代码来给大家演示
#include<stdio.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}阅读这段代码我们可以发现i的值都要付给a[i],a[i]的值随着循环会是-1,-2,-3,....,-999,-1000,但是真的会打印出-1000吗?
肯定不会
问题就出现在char类型不能存放这么小的数字,所以接下来我们来深入研究char类型的数据;
我们都知道int类型的数据占4个字节,而char类型的数据只占一个字节,所以按照比特位来看int类型占32个比特位,而char类型只占8个比特位
而一个bit的大小可以放一个二进制
所以他们的最大值可能就是(此处看成无符号的):
int 1111 1111 1111 1111 1111 1111 1111 1111(4,294,967,168)
char 同理 1111 1111 (255)
但是我们还是要考虑第一个bit是符号位,0表示正数,1表示负数,
所以char类型中最大的数用二进制表示为0111 1111,也就是十进制中的127;
而char类型中最小的数用二进制表示为 1000 0000 (-128)此处是一个固定的值,当char中出现该数就会直接看成-128,
并且char的二进制的值在运算时会在-128和127之间循环,也就是当127的二进制+1会变成-128,同理从-1开始-1,一直减到-128,再减一就会变成127,直到减到零又会循环
所以当然不够存下-1000这样的数字,
再来看strlen函数,我们都知道strlen是测字符串长度,遇到\0才会结束,
所以最后输出的值就是127+128
我们让代码跑起来
诶!走!
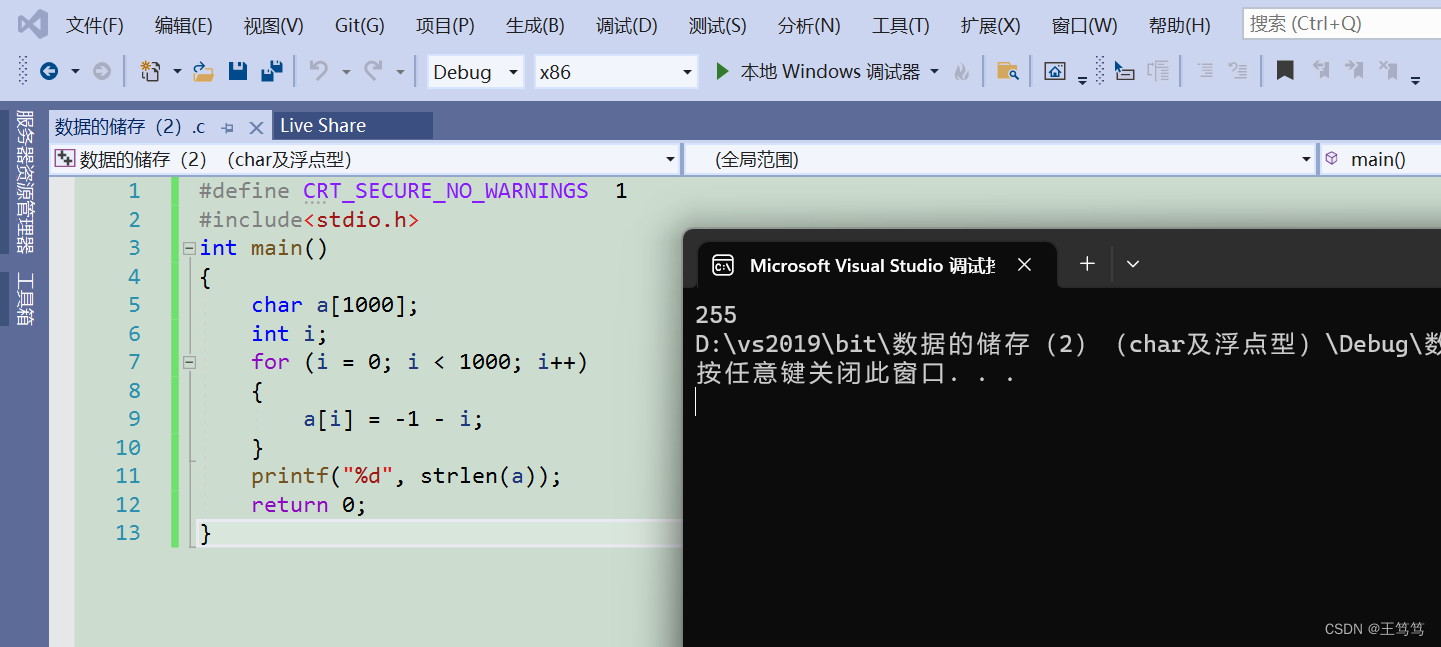
我们也可以将这个循环化成一个圆

这样就非常好理解了
2.了解浮点数是如何储存并处理的
我们先看看常见的浮点数;
3.1415926(就是一个有小数点的)
1E10(科学计数法的表示,表示1.0×10^10)
浮点数的类型包括:float、double、long double类型
继续来观察下面这组关于浮点数的代码
#include<stdio.h>
int main()
{
int n = 9;
float* pfloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pfloat*的值为:%f\n", *pfloat);
*pfloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pfloat的值为:%f\n", *pfloat);
return 0;
}下面是输出的结果,是否和你想的一样呢?

我们可以先看上面两个打印出来的数据;

n是值是9,是整形类型的数据,我们再以整形类型的数据输出,也就是%d输出,我们发现输出是9;
但是当我们定义一个float类型的指针,这个指针指向的是n的地址,最后将这个指针解应用并输出发现是0.000000和整形输出不是一个值
也就是说我们将整形的数据9存进去,再用整形拿出来他还是不变的,
但当我们依旧将整形的数据存入,但是用浮点型数据拿出时,就变得不一样了
所以我们以此来证明整形的存储规则和浮点型的存储规则是不一样的;
同样的下面个输出的数据相反;

用浮点型数据存入,用整形拿出时会输出这么一串东西;
但是用浮点型数据存入,用浮点型拿出时就可以正常使用,又又说明了整形的存储规则和浮点型的存储规则是不一样的;
那到底有什么样的区别呢
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。
M表示有效数字,大于等于1,小于2。(换算成二进制的数字只有0/1所以1≤M<2)
2^E表示指数位。
意思就是说
V是一个二进制浮点数,V=(-1)^S * M * 2^E,如果在(-1)^S中,S=0,那么(-1)^S=1,那么这个V就表示一个正数;如果S=1的时候,那么(-1)^S=-1,这时候V就表示一个负数;
我们来举一个例子
5.5
个位数子5转换成二进制表示为101;
小数点后面的数值的权重就变成了负数,
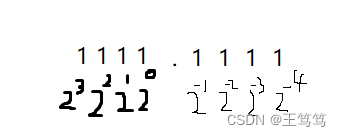
如图理解权重会比较好理解,
那么5.5用二进制表达就是101.1 ,移动小数点变成科学计数法成为1.011,再根据上述所说的V的表达形式,就可以写为5.5=(-1)^0* 1.011 *2^2,其中(-1)^0表示这是一个正数,2^2表示将小数点向后移动两位,因为V=(-1)^S * M * 2^E,所以S=0,M=1.011,E=2,所以计算机在存储数据的时候只要将S、M、E存入计算机中即可达到储存浮点数的效果;
我们还需要知道的是
float类型是32位的浮点型

double类型是64位的浮点型

前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分,当我们再拿出来用的时候,计算机给小数点前面加上1.就可以还原其值,这么做的原因就是可以省出比特位使小数的精度更高一些。因为double比float储存的小数点后位数多,所以精度更高,所以也叫double为双精度浮点型,float为单精度浮点型(不是double比float的精度多一倍,只是能存储更多比特位)
但是真的什么浮点类型的数据都可以被精确的保存吗?
①M的储存
比如我们给出一个数字5.3

就这样以此类推,我们会发现无论我们后面要补多少位M,永远都不能精确的表达出小数点后3的真实的值
经过我们的编译器中的监视功能发现
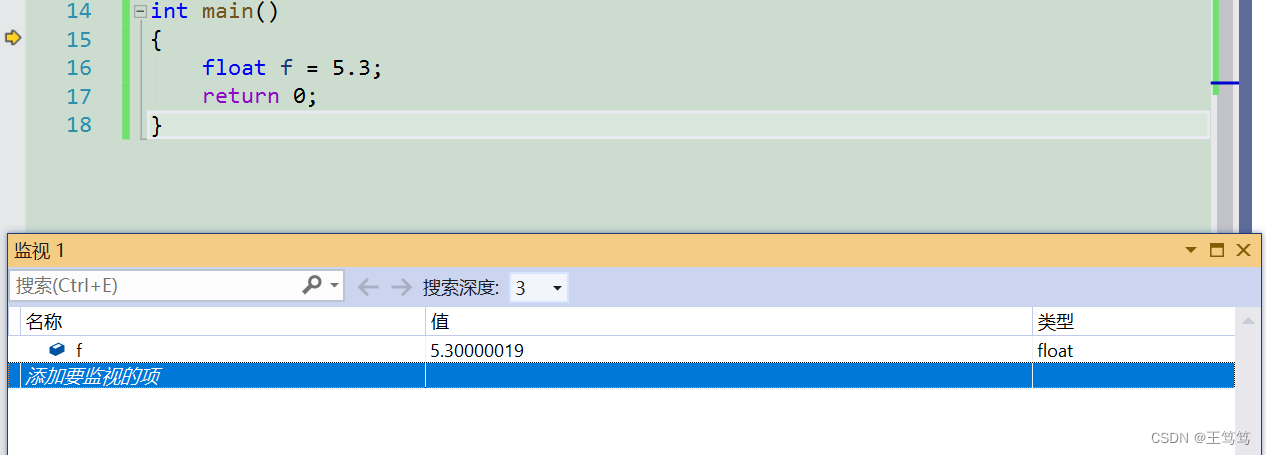
我们的 f 确实比3要差了那么一点点点点
所以有的浮点数是不能非常非常精确的保存在计算机中的,还是有一点点的误差的
②E的储存
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出
现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
我们接着用代码演示
int main()
{
float f = 5.5;
//101.1
//科学计数法:(-1)^0 * 1.011 * 2^2
//二进制存储:0 10000001 011 00000000000000000000
//十六进制表示:40b00000
return 0;
}用二进制看的话第一个 0 表示这个数是正数,
因为2^2,E是2,上面说过储存E时要加上一个中间值,float是八位数的E,所以加上127再转换为二进制,那么2+127在转换为二进制就是10000001,最后是M,前面说过舍去小数点和小数点前面的数字,只保留小数点后面的数字,所以在M中存011,后面的位数补0;
以上就是数据的储存,希望对你有所帮助