关于二叉树的五道面试题的总结
- 求二叉树的最远两个结点的距离;
- 由前序遍历和中序遍历重建二叉树;
- 判断一棵树是否是完全二叉树;
- 求二叉树两个节点的最近公共祖先;
- 将二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
请仔细阅读代码和注释!!!
<一> 求二叉树的最远两个结点的距离
本题在上一篇博客中已经进行了详细的实现,下面给出本题的连接:
<二>由前序遍历和中序遍历重建二叉树
分析:这是一道考察基础的题目,即对二叉树的遍历方式是否有深刻的了解,同时也考察对二叉树的构建的了解,通常给定一个序列构建二叉树的方式是利用前序遍历并且结合非法值的方式进行构建,这个在第一题的实现中已经有了体现;
目前我们所了解的二叉树的遍历方式有四种:前,中,后,层序遍历;
其中前序遍历是深度优先遍历,层序遍历是广度优先遍历(这个会在第三题中用到);当然,这个属于只是扩展;
本题所考察的前序和中序遍历构建二叉树,我们以下面这俩个序列为例,分析:
(前序序列:1 2 3 4 5 6 - 中序序列:3 2 4 1 6 5)
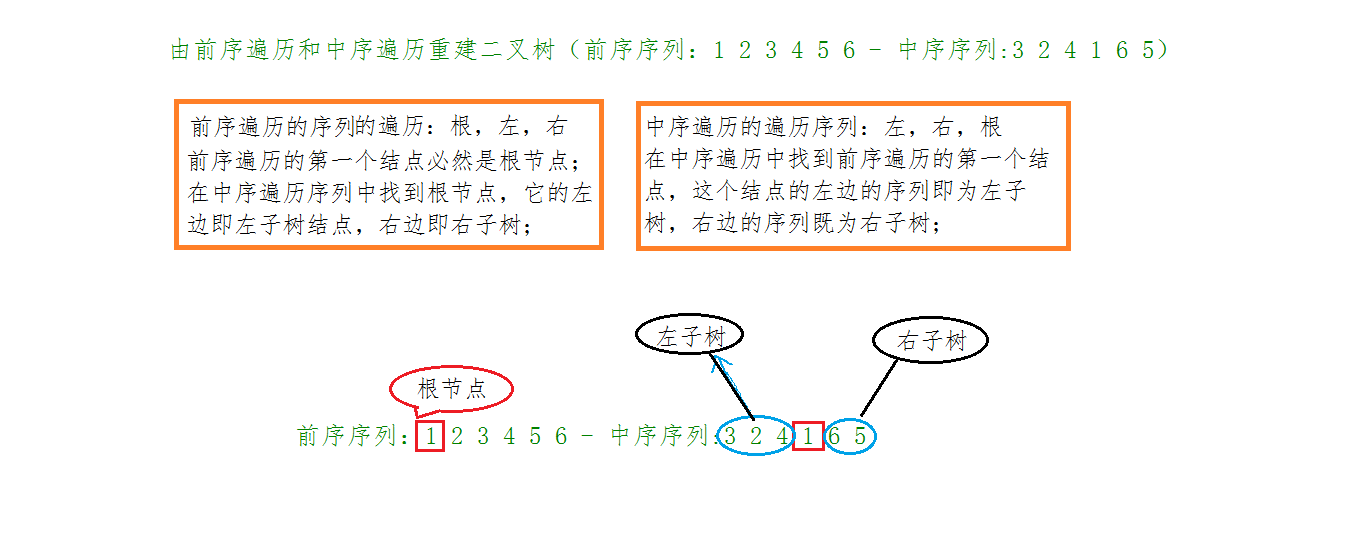
:我们根据前序和中序的特性,划分出了根节点的左子树和右子树,那么此时,我们至少知道了这棵树的根节点,也就是拥有了根节点,还知道了左右子树的节点个数,接下来,就该去创建它的左子树和右子树,而左右子树又可以单独的看作是一棵树,我们可以知道左右子树的根节点,怎么知道的?
前序遍历就在那放着,根结点1 的右边第一个不就是左子树的根节点,而根据中序遍历我们又知道左子树的节点个数,1 往右 3 个结点之后不就是5;那么 5 就是 1 的右子树的根节点,以此类推,这棵树都所有结点我们都拥有了,树不就建出来了,下面给出一个图示:
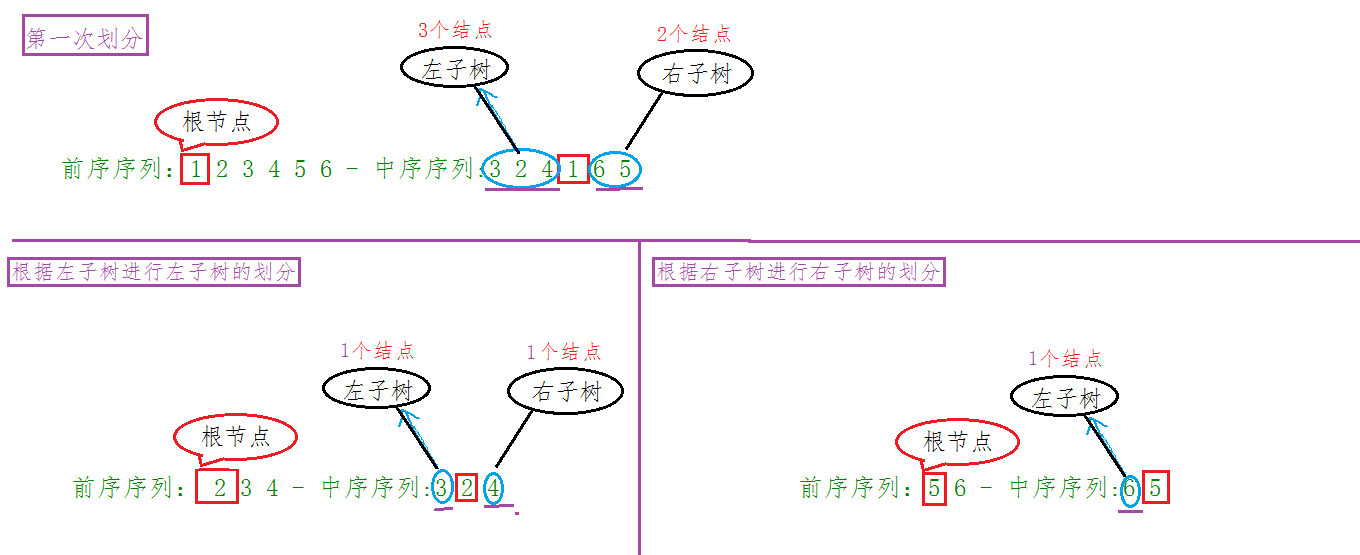
:思路都理得差不多了,但是实现代码又和思路有些差异,因为代码的实现需要考虑很多因素,所以,请仔细看代码的实现;
代码:
//前序序列:1 2 3 4 5 6 - 中序序列:3 2 4 1 6 5
//在没有重复节点的前提下
Node* _GreatTree(int* prestart, int* preend,int* inarrstart,int* inarrend)
{
Node* root = new Node(*prestart);
//如果只有当前一个节点,则将创建好的这个节点返回;
if(prestart == preend && inarrstart == inarrend)
return root;
//找到中序遍历中的根节点
int* rootInorder = inarrstart;
while(rootInorder <= inarrend && *prestart != *rootInorder)
++rootInorder;
//创建左子树
int lenth = rootInorder - inarrstart; //左子树的节点数量
int* leftpreend = prestart+lenth; // 左子树前序遍历节尾
//如果在当前根节点有左子树,进行创建左子树
if(lenth > 0)
root->_left = _GreatTree(prestart+1,leftpreend,inarrstart,rootInorder);
//创建右子树
int* rightprestart = leftpreend+1; //右子树前序遍历的开始
//如果当前根节点有右子树,则创建右子树;
if(lenth < preend - prestart)
root->_right = _GreatTree(rightprestart,preend,rootInorder+1,inarrend);
return root;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
<三>判断一棵树是否是完全二叉树
分析:这道题可以这么说,如果你想到了方法,就很简单不过了,没有思路的话当然就不简单了,当你不会的时候看了一下别人的解决方法,又会痛心疾首的痛恨自己怎么这么简单的题都想不出来!
当然,以上纯属废话;
判断一颗树是否是完全二叉树,首先需要知道什么是完全二叉树,我相信有很多人对这个概念并不是很清晰;
完全二叉树(Complete Binary Tree)
若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
一棵二叉树至多只有最下面的一层上的结点的度数可以小于2,并且最下层上的结点都集中在该层最左边的若干位置上,则此二叉树成为完全二叉树。
例如下面这棵树:
那么,了解了完全二叉树的基本概念之后,这道题似乎就变得简单了很多,既然前k-1层是满二叉树,而最后一层又是从左到右没有间隔的,了解层序遍历的同学相信很容易就想到了用层序遍历来解这道题,至于什么是层序遍历,就不在这里赘述了;
下面我给出这道题基于层序遍历的两种解法:
1)设置标志法
从根节点开始,入队列,如果队列不为空,循环。
遇到第一个没有左儿子或者右儿子的节点,设置标志位,如果之后再遇到有左/右儿子的节点,那么这不是一颗完全二叉树。
图示:
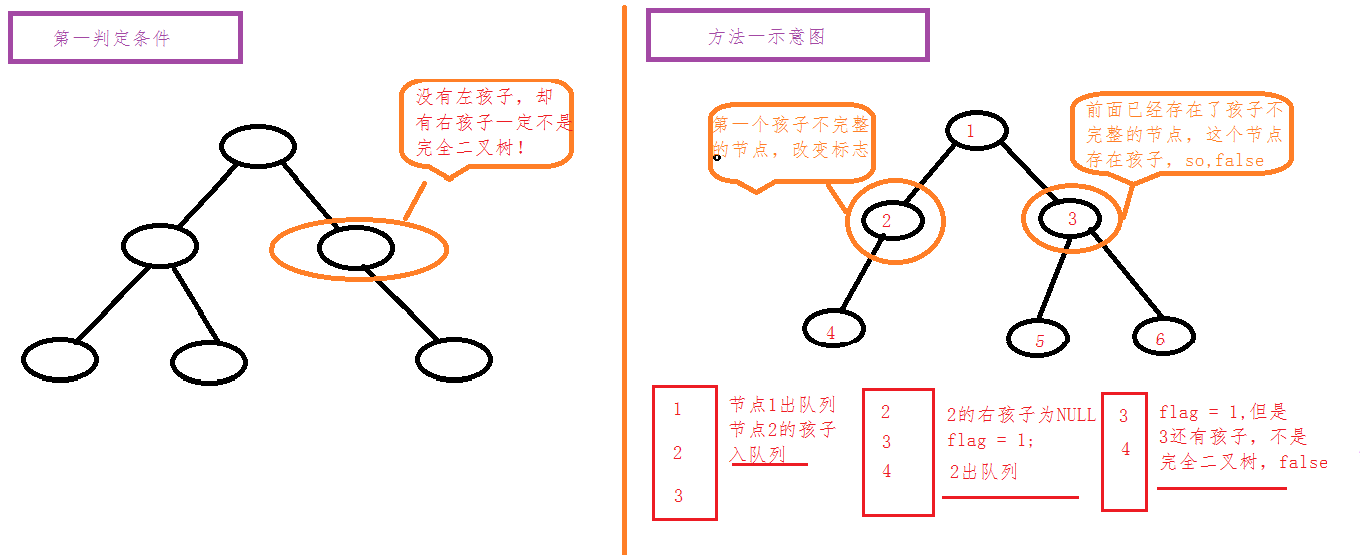
核心算法代码实现:
bool IsCompleteTreeTwo(Node* root)
{
queue<Node*> q;
q.push(root);
Node* cur = q.front();
int flag = 0; //标志
while(cur)
{
没有左孩子却有右孩子,一定不是完全二叉树
if(cur->_left == NULL && cur->_right != NULL)
return false;
//如果flaga==1,并且当前节点右孩子,则false
if(flag == 1 && (cur->_left != NULL || cur->_right != NULL))
return false;
//当前节点没有右孩子或者左孩子
if(cur->_left == NULL || cur->_right == NULL)
flag = 1;
if(cur->_left != NULL)
q.push(cur->_left);
if(cur->_right != NULL)
q.push(cur->_right);
q.pop();
if(!q.empty())
cur = q.front();
else
cur = NULL;
}
return true;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
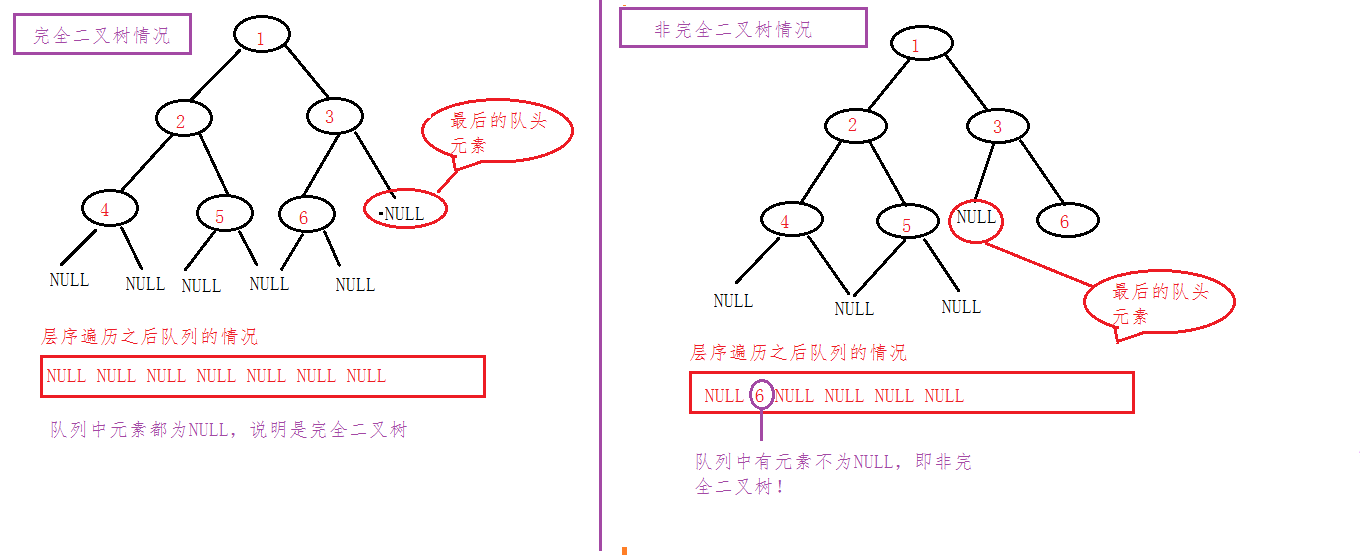
2)剩余队列判空法
这个方法同样需要入队列,不同的在于判断的方式,试想一颗完全二叉树,我们把它的所有节点,包括叶子节点的左右空孩子都入队列,通过层序遍历,不断的入队列和出队列的方式,如果遇到第一个队头元素为空,那么如果是完全二叉树的 话,此时一定遍历完了所有节点,队列中剩余的元素肯定全是NULL的节点,也就是叶子节点的空孩子,如若不是如此,那么,抱歉了,这就不是一颗完全二叉树!
图示:
图中省略入队出队过程;
核心代码实现:
bool IsCompleteTree(Node* root)
{
if(root == NULL)
return false;
//用到辅助内存队列
queue<Node*> q;
q.push(root);
//先将所有的节点以及它们的左右节点入队列
Node* cur = q.front();
while(cur) //如果遇到第一个空节点停止
{
q.push(cur->_left);
q.push(cur->_right);
q.pop();
cur = q.front();
}
//此时应该是完全二叉树的结尾;
//此时正确的情况应该是队列中的所有元素都是NULL,否则不是完全二叉树
while(!q.empty())
{
if(q.front() != NULL)
return false;
q.pop();
}
return true;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
本题完整代码实现链接:
<四>求二叉树两个节点的最近公共祖先
分析: 这道题是剑指offer上的一道题,难点在于全面的考虑各种情况,利用合适的方法解决各种情况;
什么是最近公共祖先?
即从根节点分别到两个节点的路经中最后一个公共节点,即最近公共祖先;
如下图所示: 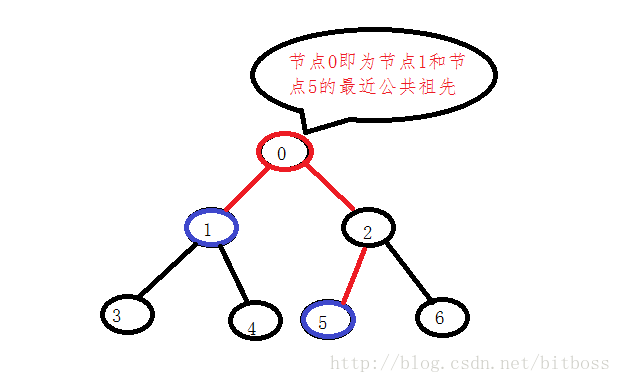
再然后,我们需要分析出都有哪些情况?
1)二叉搜索树
2)带有父指针的二叉树(就是三叉链)
3)一颗普通的树
情况1:
最简单的情景,即本身就是一颗二叉搜索树,即是有关联的,那么我们只要找到一个比其中一个节点大或者等于,并且比另一个节点小或者等于的节点就可以了,这个节点就是最低公共祖先,这个很好理解,就不多做赘述,直接上代码了;
//查找最小公共祖先
int MinCommonAncestor(int x,int y)
{
Node* cur = _root;
Node* tmp = NULL;
while(cur)
{
//比两个目标节点的值都大,继续往左子树找;
if(cur->_data > x && cur->_data > y)
{
tmp = cur;
cur = cur->_left;
}
//比两个目标节点的值都小,继续往右子树找;
else if(cur->_data < x && cur->_data < y)
{
tmp = cur;
cur = cur->_right;
}
//符合条件找到目标节点
else if(cur->_data >= x && cur->_data <= y || cur->_data <= x && cur->_data >= y)
{
return cur->_data;
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
情景2:
不是二叉搜索树,但是有父指针的二叉树;
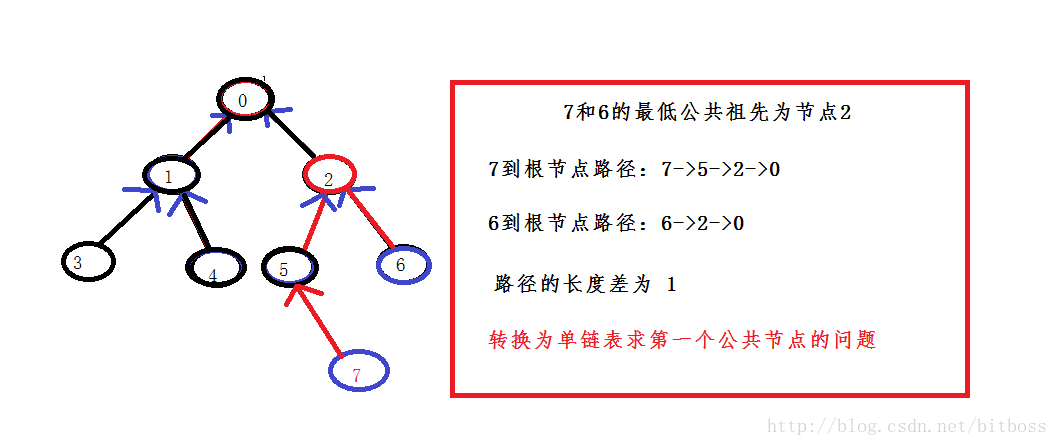
既然有父指针,即是三叉连,那么问题就又变的简单了,熟悉的同学应该很快就发现,这样的话就把问题转化为求两条相交链表的第一个公共节点的问题了,当然,为什么是第一个公共节点?前面说最低公共祖先的概念的时候不是说是从根节点分别到两个节点的最后一个公共节点吗?
不要急,你想想,现在我们有了父节点的话,完全可以从两个目标节点往上遍历,这不就是反着的了,求两个相交节点的 第一个公共节点,出发点不一样;
而从两个目标节点向上遍历的时候又有好几种办法,比如说利用栈,利用长度差的方法,栈的方法我们先不用,留到下一种情景用,这里我们用的 是长度差的方法,何为长度差的方法?
长度差:即我们寻找两个目标节点的时候,顺便把从根节点到他们所经过的路径长度保存起来,分别是count1和count2; 然后求得他们的差值,即长的那条路径比短的那条路径多的节点数,为什么要这样呢?
因为我们需要逆向找路径上的第一个公共节点,而如果从两个目标节点同时出发的话,肯定就不是我么想要的结果了,看着上面那个图所举得例子,如果7和6同时开始遍历,那就有问题了,而如果我们让路径长的那个节点先走上他们的长度差的节点后,两个节点再同时向上遍历,第一个相同的节点不就是第一个公共节点了(当然,我们排除出现相同节点的可能性);
代码:
//查找最小公共祖先
int MinCommonAncestor(int x,int y)
{
//根据已知节点向上查找到根节点,求两个链表的第一个交点
//前提都是建立在没有重复元素的二叉树中
if(x == y)
return x;
//不考虑返回空的情况,即暂时不考虑非法输入
//采用找两个链表第一个公共节点的方法求解,三种方法,穷举,辅助栈,和求长度差;
//利用第三种方法,求长度差
int count1 = 1;
int count2 = 1;
Node* nodeone = NULL;
Node* nodetwo = NULL;
Node* cur = _root;
while(cur)
{
if(cur->_data == x)
{
nodeone = cur;
break;
}
++count1;
}
cur = _root;
while(cur)
{
if(cur->_data == y)
{
nodetwo = cur;
break;
}
++count2;
}
//求出长度差
int len = abs(count1 - count2);
if(count1 >= count2)
return _FindFirstNode(nodeone,nodetwo,len);
else
return _FindFirstNode(nodeone,nodetwo,len);
}
int _FindFirstNode(Node* one,Node* two, int len)
{
while(len--)
one = one->_parent;
while(one != two)
{
one = one->_parent;
two = two->_parent;
}
return one->_data;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
情景3:
普通的二叉树,那就别无他法了,只能利用最原始的概念,从根节点开始分别到两个目标节点的路径的最后一个公共节点;
这样的就没有什么技巧可言了,我们为了方便起见还是以二叉树为例(当然,三叉,四岔的就麻烦点了);
可以利用两种方法来实现:即递归和利用栈;
递归的思想有些类似于第一题的思想:利用递归带返回值的方法进行判断;
不停的向下递归,如果找到俩个目标节点的其中一个节点,就把当前这个节点返回,如果递归到叶子节点还没有找到一个目标节点就返回NULL;
接收左右子树的反馈结果,如果left和right都不为NULL,那么很好,说明两个目标节点分别在我的左右子树上,返回当前节点,当前节点就是最低公共祖先;如果只有一颗子树返回的非空值,那么就说明两个目标节点都在我的那个返回非空节点的子树上,而返回值就是最低公共祖先,这里是最难懂的地方,为什么非空的返回值就是最低公共祖先?
联系这张图看看:
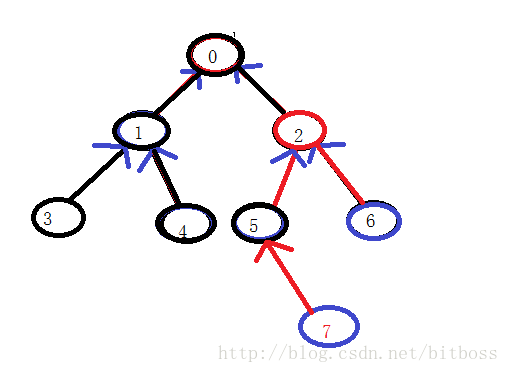
假如我们要求得2和5的最低公共祖先,那么我们从根节点递归的往下遍历,左子树肯定是返回NULL了,而右子树递归到2的时候就返回了,既然我已经找到了一个目标节点,那我就不继续递归了,要不然另一个目标节点在另一个子树上,不管我2的事,要不然5就在我2的子树上,那就更简单了,2就是最低公共祖先了,所以也就不存在很多同学担心两个目标节点在一条线上的情况会出现误判的情况了;
讲完这段感觉我都变2了;
int MinCommonAncestor(int x,int y)
{
Node* left = NULL;
Node* right = NULL;
Node* cur = _MinCommonAncestor(_root,x,y);
return cur->_data;
}
Node* _MinCommonAncestor(Node* root,const int x, const int y)
{
Node* left = NULL;
Node* right = NULL;
if(root == NULL)
return NULL;
if(root->_data == x || root->_data == y)
return root;
left = _MinCommonAncestor(root->_left,x,y);
right = _MinCommonAncestor(root->_right,x,y);
if(left && right)
return root;
return left ? left : right;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
利用栈的实现原理:无外乎就是保存路径,而栈的后进先出的特性,就又变成了第一个相同节点的问题了;
如图:
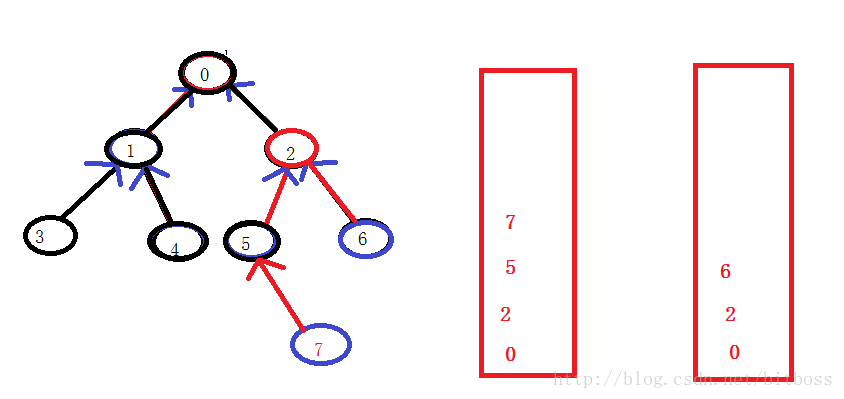
7和6的路径分别入栈,然后还是需要一个路径差,不过这时候的路径差就很简单的可以利用栈的size()求出,同样,size大的栈先pop掉路径差个元素,然后,两个栈同时pop,知道遇到一个相同的元素,这其实已经和情景2一样了;
代码:
//利用递归和栈保存路径,然后消去两条路径的差值,进行同时pop();找到第一对不同;
int MinCommonAncestor(int x,int y)
{
stack<Node*> s1;
_MinCommonAncestor(_root,s1,x);
stack<Node*> s2;
_MinCommonAncestor(_root,s2,y);
if(s1.size() > s2.size())
{
int count = s1.size() - s2.size();
return FindCommonParent(s1,s2,count)->_data;
}
int count = s2.size() - s1.size();
return FindCommonParent(s2,s1,count)->_data;
}
Node* FindCommonParent(stack<Node*> first,stack<Node*> second,int count)
{
while(count--)
first.pop();
Node* cur = NULL;
while(!first.empty() && !second.empty() && first.top() != second.top())
{
first.pop();
second.pop();
}
return first.top();
}
bool _MinCommonAncestor(Node* root,stack<Node*>& s, const int x)
{
if(root == NULL)
return false;
if(root->_data == x)
{
s.push(root);
return true;
}
s.push(root);
bool left = _MinCommonAncestor(root->_left,s,x);
bool right = _MinCommonAncestor(root->_right,s,x);
if(left == false && right == false)
{
s.pop();
return false;
}
return true;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
<五>将二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
分析:怎么说呢,这道题本质也很简单,但是我们一看到限制条件就先慌张了,既然有附加条件肯定不会那么简单,那么,其实想的复杂了,这道题其实就是简单的考察你对二叉搜索树的了解;
二叉搜索树,也是有分别指向左子树和右子树的指针,而且中序遍历有序;
而把二叉搜索树变为有序的双向链表,第一点不免想到的肯定是中序遍历的 方法,然后就是改变指针的指向,因为不允许创建新的节点,而改变指针的指向的话,就简单很多了,只要让left变为指向前一个节点的指针,right变为指向后一个节点的 指针就可以了,当然,代码的实现过程中肯定会有些许的细节差异!
代码:
Node* TurnToList()
{
Node* prev = NULL;
_TurnToList(_root,prev);
//返回双向链表的头结点
Node* cur = _root;
while(cur && cur->_left)
cur = cur->_left;
return cur;
}
void _TurnToList(Node* root, Node*& prev)
{
if(root == NULL)
return;
_TurnToList(root->_left,prev);
if(prev != NULL)
prev->_right = root;
prev = root;
_TurnToList(root->_right,prev);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24