微服务·组件架构之服务注册与发现之Nacos
Nacos服务注册与发现流程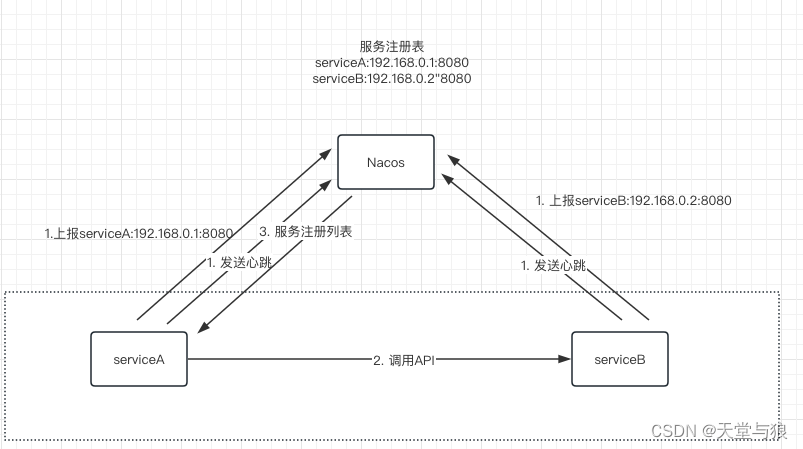
- 服务注册:Nacos 客户端会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。 Nacos Server接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
- 服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认 5s发送一次心跳。
- 服务同步:如果是集群部署,Nacos 服务端集群之间会互相同步服务实例,用来保证服务信息的一致性。
- 服务发现:Nacos 客户端在调用服务提供者的服务时,会发送一个REST请求给Nacos 服务端,获取上面注册的服务清单,并且缓存在Nacos 客户端本地,同时会在Nacos客户端本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存。
- 服务健康检查:Nacos 服务端会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它的 healthy属性置为false,如果某个实例超过30秒没有收到心跳,直接剔除该实例
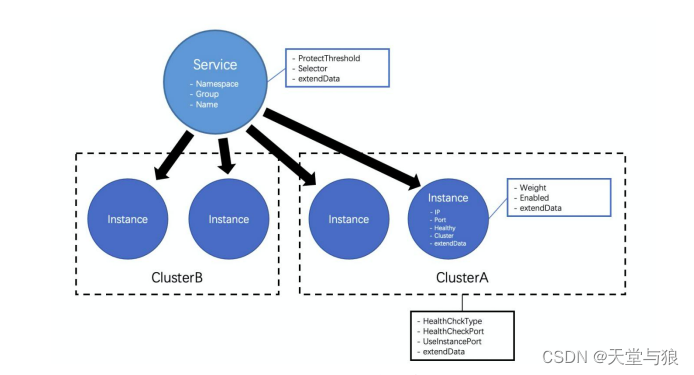
Nacos服务注册中心数据模型
定义服务
在Nacos中,服务的定义包括以下几个内容:
- 命名空间(Namespace):Nacos数据模型中最顶层、也是包含范围最广的概念,用于在类似环境或租户等需要强制隔离的场景中定义。
- 分组(Group):Nacos数据模型中次于命名空间的一种隔离概念,区别于命名空间的强制隔离属性,分组属于一个弱隔离概念,主要用于逻辑区分一些服务使用场景或不同应用的同名服务,最常用的情况主要是同一个服务的测试分组和生产分组、或者将应用名作为分组以防不同应用提供的服务重名。
- 服务名(name):该服务的实际名称,一般用于描述该服务提供了某种功能或能力。
通常推荐使用运行环境作命名空间、应用名作为分组和服务功能作为服务名的组合来确保该服务的天然唯一性。
服务元数据
- 健康保护阈值(ProtectThreshold):未来防止因过多实例故障,导致所有流量流入剩余实例,继而造成流量压力将剩余实例被压垮形成的雪崩效应,应将保护阈值定义为一个0到1之间的浮点数。当域名健康实例数占总服务实例数的比值小于该值时,无论实例是否健康,都会将这个实例返回给客户端。这样做虽然损失了一部分流量,但是保证了集群中剩余健康实例能正常工作。
- 实例选择器(Selector):用于在获取服务下的实例列表时,过滤和筛选实例。该选择器也被称为理由器,目前Nacos支持通过将实例的部分信息存储在外部元数据管理CMDB中,并在发现服务时使用CMDB中存储的元数据标签进行筛选的能力。
- 拓展数据(extendData):用于用户在注册实例时自定义扩展的元数据内容,形式为k-v。
服务端数据结构
/**
* Map(namespace, Map(group::serviceName, Service)).
*/
private final Map<String, Map<String, Service>> serviceMap = new ConcurrentHashMap<>();
/**
* Service of Nacos server side
*
* <p>We introduce a 'service --> cluster --> instance' model, in which service stores a list of clusters, which
* contain
* a list of instances.
*
* <p>his class inherits from Service in API module and stores some fields that do not have to expose to client.
*
* @author nkorange
*/
//重要!!!Service实体类中包含Cluster对象
private Map<String, Cluster> clusterMap = new HashMap<>();
/**
* Cluster. 集群类
*
*/
//持久实例列表
@JsonIgnore
private Set<Instance> persistentInstances = new HashSet<>();
//临时实例列表
@JsonIgnore
private Set<Instance> ephemeralInstances = new HashSet<>();
//持有service对象
@JsonIgnore
private Service service;
定义实例
由于服务实例是具体提供服务的节点,因此Nacos在设计实例的定义时,主要需要存储实例的一些网络相关的基础信息。
- 网络IP地址:该实例的IP地址,在Nacos2.0版本后支持设置为域名。
- 网络端口:该实例的端口信息。
- 健康状态(Healthy):用于表示该实例是否为健康状态,会在Nacos中通过健康检查手段进行维护。
- 集群(Cluster):用于标示该实例归属于哪个逻辑集群。
- 拓展数据(extendData):用与用户自定义扩展的元数据内容,形式为k-v。
实例元数据
- 权重(Weight):实例级别的配置。权重越大,分配给该实例的流量越大。
- 上线状态(Enable):标记该实例是否接受流量,优先级大于权重和健康状态。
- 拓展数据(extendData):用与用户自定义扩展的元数据内容,形式为k-v。
在Nacos2.0版中,实例数据被拆分为实例定义和实例元数据,只要对应着两种不同场景:开发运行场景以及运维场景。
客户端数据结构
/**
* unique id of this instance.
*/
private String instanceId;
/**
* instance ip
*/
private String ip;
/**
* instance port
*/
private int port;
/**
* instance weight
*/
private double weight = 1.0D;
/**
* instance health status
*/
private boolean healthy = true;
/**
* If instance is enabled to accept request
*/
private boolean enabled = true;
/**
* If instance is ephemeral
*
* @since 1.0.0
*/
private boolean ephemeral = true;
/**
* cluster information of instance
*/
private String clusterName;
/**
* Service information of instance
* 拼接:分组名@@服务名
*/
private String serviceName;
/**
* user extended attributes
*/
private Map<String, String> metadata = new HashMap<String, String>();
集群
定义集群
- 健康检查类型(HealthCheckTye):使用哪种类型的健康检查方式,目前支持的TCP,HTTP,MySQL;设置为NONE可以关闭健康检查。
- 健康检查端口(HealthCheckPort):设置用于健康检查的端口。
- 是否使用实例端口进行健康检查(UseInstancePort):如果使用实例端口进行健康检查,将会使用实例定义中的网络端口进行健康检查,而不再使用上述设置的健康检查端口进行。
- 拓展数据(extendData):用与用户自定义扩展的元数据内容,形式为k-v。
生命周期
在注册中心中,实例数据都和服务实例的状态绑定,因此服务实例的状态直接决定了注册中心中实例数据的生命周期。
服务的生命周期
- 开始:用户向注册中心发起服务注册请求
- 结束:用户主动发起删除服务的请求或一定时间内服务没有实例。
实例的生命周期
持久化实例
持久化的实例会通过健康检查的状态维护健康状态,但是不会自动终止该实例的生命周期。唯一终止持久化实例生命周期的方法就是注销实例的请求。
非持久化实例
Nacos1.0版本通过心跳请求进行续约,当超过一定时间内没有心跳进行续约时,该非持久化实例则终止生命周期。
Nacos2.0版本通过gRPC的长连接来维持状态,当连接发生中断时,该非久化实例则终止生命周期。
集群的生命周期
- 开始:与集群中第一个实例的生命周期同时开始。
- 结束:与集群中最后一个服务的生命周期同时结束。
元数据的生命周期
元数据通常为运维人员的主从操作的数据,会被Nacos进行一段时间的记忆。因此元数据的生命周期的终止相比对应的数据要滞后,如果在滞后期间,对应的数据又重新开始生命周期,则元数据的生命周期将被立即重制。
Nacos注册中心健康检查机制
临时实例健康检查机制
Nacos提供给了两种方式进行临时实例的注册,即通过Nacos的OpenAPI进行服务注册或通过Nacos提供的SDK进行服务注册。
OpenAPI的注册方式是用户根据自身需求调用Http接口对服务进行注册,然后通过Http接口发送心跳到注册中心。在注册服务的同时会注册一个全局的客户端心跳检测任务。在服务端一段时间没有收到来自客户端的心跳后,该任务会将其标记为不健康,如果在间隔的时间内还未收到心跳,那么该任务会将其剔除。
SDK的注册方式实际是通过RPC与注册中心保持连接,客户端会定时的通过RPC连接向Nacos注册中心发送心跳,保持连接的存活。如果连接中断,注册中心会剔除该client所注册的服务来达到下线的效果。
永久实例健康检查机制
Nacos采用的是注册中心探测机制,注册中心会在永久服务初始化时根据客户端选择的协议类型注册探活的定时任务。Nacos内置提供了三种探测的协议:Http、TCP、MySQL。
集群模式下的健康检查机制
对于集群下的服务,Nacos一个服务只会被Nacos集群中的一个注册中心所负责,其余节点的服务信息只是集群副本,用于订阅者在查询服务列表时,始终可以获得全部的服务列表。临时节点只会对其被负责的注册中心节点发送心跳信息,注册中心服务节点会对其负责的永久实例进行健康探测,在获取到健康状态后由当前节点将健康信息同步到集群中的其他注册中心。
Nacos为什么需要一致性协议
Nacos是一个简单存储数据的组件,因此为了实现这个目标,就需要在Nacos内部实现数据存储。单机下问题不大,简单的内嵌关系型数据库即可;但是在集群模式下,就要考虑如何保障各个节点之间的数据一致性以及数据同步,而要解决这个问题,就不得不引入共识算法来保障各个节点之间的数据一致性。
Nacos为什么选择Raft以及Distro
Nacos在单个集群中同时运行了CP协议和AP协议,这个要从Nacos的应用场景出发:Nacos是一个集服务注册发现以及配置管理于一体的组件,因此对于集群中各个节点之间的数据一致性保障问题要从两方面考虑。
从服务注册发现来看
服务注册发现中心在当前微服务体系下,是十分重要的组件,服务之间感知对方服务当前可正常提供服务的实例信息,必须从服务注册中心中获取,因此对于服务注册中心组件的可用性,提出了很高的要求。需要在任何场景下尽最大可能保证服务注册发现能力可以对外提供服务。同时Nacos的服务注册发现设计,采用了心跳可自动完成服务数据的补偿机制。如果数据丢失的话,可以通过该机制快速弥补数据丢失。
针对非持久化服务(即需要客户端上报心跳机制进行服务实例续约)强一致性的共识算法不太合适,因为强一致共识算法必须保证集群中可用节点超过半数。而最终一致算法更多的是保证可用性,并且能够在一定时间内各个节点之间的数据达成一致。
针对持久化服务,数据是直接使用Nacos服务端的,因此需要由Nacos保障数据节点之间的强一致性。
从配置管理来看
配置数据,是直接在Nacos服务端进行创建并管理的,必须保证大部分节点都保存了此配置数据才能任务配置被成功保存了。因此需要使用强一致性共识算法。
为什么是Raft和Distro
对于强一致性算法,当前工业生产中,使用最多的就是Raft协议,Raft协议更容易让人理解,并且有很多成熟的工业算法实现,比如蚂蚁金服的JRaft、Zookeeper的ZAB、Consul的Raft、百度的braft以及Apache的Ratis;JRaft支持多RaftGroup,为Nacos的多数据分片带来了可能。
Distro是阿里自研的一个最终一致性协议。最终一致性协议有很多,例如Gossip、Eureka内的数据同步算法。而Distro是集合以上两种算法的优点并加以优化而来的。对于原生Gossip,由于随机选取发送消息的节点,也就不可弥漫的存在消息重复发送给同一节点的清空,增加了网路的传输压力,也给消息节点带来了额外的处理负担,而Distro引入权威Server的概念,每个节点负责一部分数据以及自己的数据同步给其他节点,有效的降低消息冗余问题。
Distro协议
Distro协议是Nacos社区自研的一种AP分布式协议,是面向临时实例设计的一种分步式协议,其保证了某些Nacos节点宕机后,整个临时实例处理系统依旧可以正常工作。作为一种有状态的中间件应用的内嵌协议,Distro保证了各个Nacos节点对于海量注册请求统一协调和存储。
设计思想
- Nacos每个节点是平等的都可以处理写请求,同时把新数据同步到其他节点。
- 每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据一致性。
- 每个节点独立处理读请求,及时从本机发出的响应。
工作原理
数据初始化
新加入的Distro节点会进行全量数据拉取,具体操作是轮询所有的Distro节点,通过向其他的机器发送请求拉取全量数据。
在全量拉取操作完成后,Nacos的每台机器上都维护了当前的所有注册上来的非持久化实例数据。
数据校验
在Distro集群启动之后,各台机器之间会定期的发送心跳。心跳信息主要为各个机器上的所有数据的元信息(之所以是元信息,是因为需要保证网络中数据传输的量级维持在一个较低的水平)。这种数据校验会以心跳的形式进行,即每台机器在固定的时间间隔向其他机器发起一次数据校验的请求。
一旦在数据校验过程中,某台机器发现其他机器上的数据与本地数据不一致,则会发起一次全量拉取请求,将数据补齐。
写操作
对于一个已经启动完成的Distro集群,在一次客户端发起写操作的流程中,当注册非持久化的实例的写请求打到某台Nacos服务器时,Distro集群的处流程:
- 前置的Filter拦截请求,并根据请求中包含的IP和Port信息计算其所属的Distro负责节点,并将该请求转发到所属的Distro节点上。
- Distro节点上的controller将写请求进行解析。
- Distro协议定期执行sync任务,将本机所负责的所有实例信息同步到其他节点上。
读请求
由于每台机器上都存放了全量数据,因此在每次读操作中,Distro机器会直接从本地拉取数据,快速响应。
这种协议保证了Distro协议可以作为一种AP协议,对于读操作都进行了及时的响应。在网络分区的情况下,对于所有的读操作也能够正常返回;当网络恢复时,各个Distro节点会把各个数据分片的数据进行合并恢复。
小结
Distro协议是Nacos对于临时实例数开发的一致性协议,其数据存储在缓存中,并且会在启动是进行全量数据同步,并定期进行数据校验。
Nacos寻址机制
Nacos支持单机部署和集群部署,针对单机部署,Nacos只是自己和自己进行通信;对于集群模式,则集群中的每个Nacos成员都需要相互通信,那么应该怎么管理集群内的Nacos成员节点信息,这就是Nacos内部寻址机制。
设计
无论是单机模式还是集群模式,其根本区别只是Nacos成员节点的个数是单个还是多个,并且能够感知到这些节点的变更情况:节点是增加了还是减少了;当前罪行的成员列表信息是什么;怎么管理成员列表信息;如何快速的支持新的、更优秀的成员列表管理模式等.
内部实现
单机寻址
单机寻址,就是找到自己的IP:Post组合信息,然后格式化一个节点信息,调用afterLookup将信息存储到ServierMemberManager中。
文件寻址
文件寻址是Nacos集群模式下默认的寻址实现。文件寻址就是每个Nacos节点需要维护一个cluster.conf的文件,文件中默认填写每个成员的IP信息即可。
当Nacos节点启动时,会读取该文件的内容,然后将文件内的IP解析为节点列表,调用afterLookup将信息存储到ServierMemberManager中。如果发现集群扩缩容,那么需要修改每个Nacos节点下的cluster.conf文件,然后Nacos内部的文件变动监听中心会自动发现文件修改,重新读取文件内容、加载IP列表信息,更新新增节点。缺点是运维成本太大。
地址服务器寻址
地址服务器寻址模式是Nacos推荐的一种集群成员节点信息管理,该模式利用了简易的web服务器,用于管理cluster.conf文件的内容信息,这样运维只需要管理一份集群节点内容即可。而每个Nacos成员节点只需要向这个web节点定时请求当前最新的集群成员节点列表信息即可。