本文作者小宝,85 后程序员,现在蚂蚁金服从事后端架构,爱读书、爱编码。
过去半年,随着 ChatGPT 的大火,大模型已经成为一种新的社交货币,现在见面都不是问,天气怎么样,而是你用 ChatGPT 了么?
国内各大巨头也纷纷下场,制作自己的大模型,从过去的百团大战,到今天的百模大战。
大佬们也纷纷表示,大模型带来的是新的一次工业革命,产生的影响会比移动互联网还大!
面对这么一个全新的技术,全新的物种,肯定有很多的人希望能够一探这个新技术背后的究竟,但是这后面涉及到大量的数学、计算机知识,都会让人望而生畏。
我有个做算法的朋友推荐给我一本讲 ChatGPT 的书,对于入门的人会比较友好,我赶紧京东买来准备学习一下。
这本书叫《这就是 ChatGPT 》。作者用非常通俗易懂的语言,讲了一下大模型最基本的原理。对于没有技术背景的人,很容易被各种行业黑话搞懵。
这本书将人工智能最为关键的几个概念,概率、模型、神经网络、再到神经网络深度运用的 ChatGPT 、其背后的架构原理都讲了一下,是一本非常优秀的 ChatGPT 的图书。

作者
本书作者斯蒂芬·沃尔弗拉姆是一位非常低调的科学家。他被称为在世界最聪明的人,谷歌创始人曾经到他公司实习,搜狗创始人王小川是他的铁杆粉丝。
他 13 岁开始写物理书,15 岁开始发高能物理论文。20 岁在美国加州理工学院博士毕业,导师是大名鼎鼎的费曼。
这本书中,他用非常深入浅出的语言,讲述了 ChatGPT 的原理,从基本的人工智能,到神经网络,再到实现 ChatGPT 的大模型的训练和实现方式。

概率和人工智能
按照目前的科学技术,我们其实对于脑科学的了解一直是非常皮毛的内容。所以想通过计算机科学技术实现对于人脑和人脑认知能力的模拟本身就是非常困难的事情。
所以,目前所谓的人工智能技术的本质,其实是基于数学统计的方式,猜测出在多个选择中,哪个选项最像真正的答案。实际上还是基于概率在做选择。
想想一些日常的例子,所谓的大数据营销就是给你推荐最可能让你下单的优惠券,大数据推荐,就是给你推荐你最喜欢、最需要的商品。大数据风控,其实就是判断你比较大概率是一个好人,没有违约风险。
现在红遍半边天的大模型以及他的应用场景 ChatGPT 也没有跳出这个概率框架,实际上就是基于大模型,在当前的上下文下,找到概率最大的下一个单词。
模型
模型,用更加简单的表示就是一个公式,比如 f=ax+b,就是一个最简单的线性公式。所谓的参数,就是里面每个具体的值。
模型的训练,通过辛苦训练,去尝试各种参数的组合,可以得到和预期最一致的结果,我们就认为找到一个好的模型。
通过这个模型,比较大的概率,就算不是训练集合里面的数字,也可以通过这个模型得到一个比较近似的结果。
而大模型,是说他的参数非常多,甚至达到了 1750 亿的参数,所以要把这个模型参数训练出来,需要大量的计算,这些计算适合使用 GPU 来实现。因为训练量大,需要大量的算力和时间。
这也是现在英伟达的股票涨得那么快的原因。因为供不应求。要训练出来大模型,必须 GPU ,暂时没有其他更好的解法。
神经网络
神经网络,顾名思义,就是通过让计算机模拟大脑神经元的结构,来模拟大脑的认知能力。神经网络是对人脑的简单理想化的实现。
正如书中所说,当我们看到一个图像,会产生一个电信号,通过一层层的神经元,最终识别出图像的意义,这是大脑的识别过程。
神经网络的结构也是通过一层层的神经元,每个神经元之间有不同的权重,通过这个复杂的结构,来模拟人的行为。比如判断这是不是一个苹果。
所谓的模型训练,实际上就是训练网络中的参数,最终的结果可以将整个网络理解成一个函数或者一个方法,这个方法的认知结果和人的认知结果基本是类似的。
比如给一张猫的图片,人可以识别出这个图片里面的猫,神经网络通过训练之后的模型,也可以识别出这是一只猫。
这里面的差别是人有意识,知道什么是猫,具体指代什么。但是对于神经网络,他其实不知道什么是猫或者狗,他只是计算出来了猫这个结果概率最大,然后就输出了。
模型或者说神经网络训练的过程,和人学习的过程基本是类的。
人学习的过程,是总结规律,并将规律进行记忆并应用的过程。
神经网络的训练,特别是有监督学习的训练,就是给一堆输入期望模型给出明确的输出。这个过程,跟我们学生时代,先做试卷,然后对答案的过程是一样的。
通过这个训练的过程,神经网络得到的模型,就是对应问题的特征,对于类似的问题,都可以找到类似的答案。训练了猫和狗之后,对于企鹅和恐龙也是可以分辨出来。
简单的描述这个过程,训练,找规律,应用,一直重复这个过程,不知疲倦,也不会疲倦,就是费电。学霸就是这样练成。
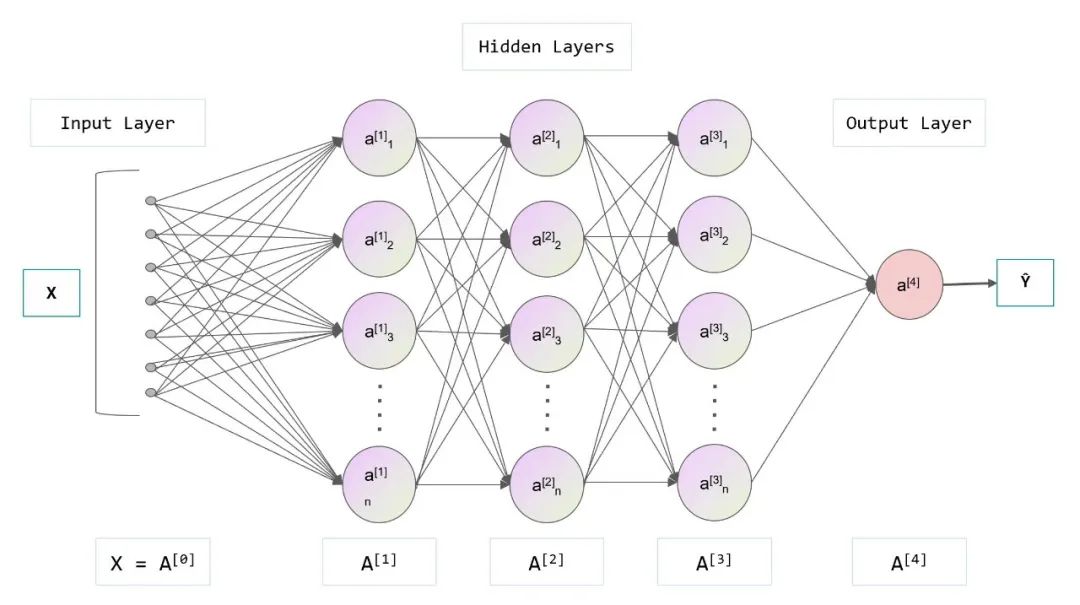
ChatGPT 的架构和原理
ChatGPT能够成功,书中总结了这么几个关键点。
无监督的训练
神经网络的训练,过去一般模式是依赖于有监督的训练。
用更加好理解的话是,给考试出题,需要先出好答案。这样学生训练完成之后,才能看看考试的结果。
以过去最经常见到的神经网络应用于图像识别的例子,给一张猫的图片,需要跟神经网络说这是猫,这样神经网络才能训练。同时训练需要非常大量的数据,所以过去标注,需要耗费大量的人力物力。
而 ChatGPT 的一个创新点是使用了无监督的训练。原因是他的目标是猜测出下个单词应该是什么。给一个完整的文章和书籍,将后面的字盖住,就可以达到训练的目的。这意味着给 ChatGPT 几乎无限的训练资源,这为他的通用模型能力建设打下非常重要的基础。
这个思路跟之前的人工智能有不小的差别,一个是从有监督到无监督,一个是从只能运用无专门领悟到变成一个业务无关的通用能力,甚至具有多模态,感觉是打通了任督二脉!
transfer的架构
我认为这个全新的架构,是 ChatGPT 能够成功的非常关键的因素,它包括以下几个关键点。
第一,他使用了自注意力机制。过去的机器学习,比如识别一张图,是不需要管上下文,对于一个聊天对话文本生成的机器人,这个上下文理解能力是非常重要,会严重影响聊天的结果
一个像鱼一样只有 7 秒钟记忆的人是无法好好聊天的。ChatGPT 通过使用自注意力机制,让神经网络根据不同上下文,会得到不同的结果。
第二,就是使用了上面提到的无监督的训练方式,对于模型进行了预训练。
第三,这个架构是一个生成式的模型。这个跟过去只是输出一个结果,也有很大的差别。
超大规模的神经网络实现通用智能
GPT-3 是一个非常大的模型。它包含 1750 亿个模型参数。GPT4 更是非常恐怖的达到 100 万亿的模型参数。
这种规模也带来了挑战,包括大量的计算资源需求,模型的存储和部署问题,以及由于模型复杂性引发的可解释性问题。
总结
这是最好的时代,也是最坏的时代。
今天,大模型已经在智能营销、数字人、智能客服等多个领域被证明是可以落地并提高效能的。
作为这个时代的弄潮儿,当然必须了解这些新技术背后的原理。
《这就是ChatGPT》就是这样一本很好的科普书。对于那些非业内的人士,把这个复杂原理用简单的语言讲清楚,让人轻松易懂。专业人士也可以用这本书快速人门,大概了解这个全新的技术,帮助构建 ChatGPT 的底层逻辑。
推荐阅读

《这就是ChatGPT》
[美] 斯蒂芬·沃尔弗拉姆|著
WOLFRAM传媒汉化小组|译
国内首部由世界顶级 AI 学者、科学和技术领域重要的革新者、“第一个真正实用的人工智能”搜索引擎 WolframAlpha 发明人斯蒂芬·沃尔弗拉姆对 ChatGPT 最本质的原理的解释的权威之作!
OpenAI CEO,ChatGPT 之父山姆·阿尔特曼、世界顶级的 AI 学者,机器人界的巨擘,MIT 教授,多家知名机器人公司创始人,美国工程院院士罗德尼·布鲁克斯、量子位联合创始人,总编辑李根、科学作家,“得到”APP《精英日课》专栏作者万维钢联袂推荐。