导入表(Import Table)是Windows可执行文件中的一部分,它记录了程序所需调用的外部函数(或API)的名称,以及这些函数在哪些动态链接库(DLL)中可以找到。在Win32编程中我们会经常用到导入函数,导入函数就是程序调用其执行代码又不在程序中的函数,这些函数通常是系统提供给我们的API,在调用者程序中只保留一些函数信息,包括函数名机器所在DLL路径。
当程序需要调用某个函数时,它必须知道该函数的名称和所在的DLL文件名,并将DLL文件加载到进程的内存中。导入表就是告诉程序这些信息的重要数据结构。一般来说导入表的数据结构如下:
- Import Lookup Table:通常被称为ILT,记录了程序需要调用的外部函数的名称,每个名称以0结尾。如果使用了API重命名技术,这里的名称就是修改过的名称。
- Import Address Table:通常被称为IAT,记录了如何定位到程序需要调用的外部函数,即每个函数在DLL文件中的虚拟地址。在程序加载DLL文件时,IAT中的每一个条目都会被填充为实际函数在DLL中的地址。如果DLL中的函数地址发生变化,程序会重新填充IAT中的条目。
- Import Directory Table:通常被称为IDT,记录了DLL文件的名称、ILT和IAT在可执行文件中的位置等信息。
导入表是Windows可执行文件中的重要组成部分,它直接决定了程序是否能够正确调用外部函数和执行需要依赖外部DLL文件的功能。在分析恶意软件或者逆向工程中,导入表也是非常重要的分析对象,常常可以通过检查IAT中的条目或IDT中的DLL名称,来发现程序中是否存在恶意行为或隐藏的功能。
2.5.1 导入表原理分析
对于磁盘上的PE文件来说,它无法得知这些导入函数会被放置在那个空间中,只有当PE文件被装入内存时,Windows装载器才会将导入表中声明的动态链接库与函数一并加载到进程的地址空间,并修正指令代码中调用函数地址,最后让系统API函数与用户程序结合起来.
为了验证导入函数的导入规律,这里我们使用汇编语言调用一个简单地弹窗,这里并没有使用C语言是因为C中封装了太多无用代码,这回阻碍我们学习导入表结构,这里我所使用的汇编环境是RadASM,编译器是VC++10.
.386p
.model flat,stdcall
option casemap:none
include windows.inc
include user32.inc
includelib user32.lib
include kernel32.inc
includelib kernel32.lib
.data
szTitle byte 'MsgBox',0h
szMsg byte 'hello lyshark',0h
.code
main PROC
invoke MessageBox,NULL,offset szMsg,offset szTitle,MB_OK
invoke ExitProcess,0
main ENDP
END main
在汇编中程序一旦被编译,编译器会对invoke指令进行分解,分解后的指令中将包含指向导入函数的地址的操作数,当PE加载后,该操作数就会被操作系统导入替换为函数的VA地址,如下我们使用调试器附加,观察这段弹窗代码,有没有发现特殊的地方?
00D21000 | 6A 00 | push 0x0 |
00D21002 | 68 0030D200 | push main.D23000 |
00D21007 | 68 0730D200 | push main.D23007 |
00D2100C | 6A 00 | push 0x0 |
00D2100E | E8 07000000 | call <JMP.0x00D2101A> | call MessageBox
00D21013 | 6A 00 | push 0x0 |
00D21015 | E8 06000000 | call <JMP.0x00D21020> | call ExitProcess
00801017 | CC | int3 |
00D2101A | FF25 0820D200 | jmp dword ptr ds:[<&0x00D22008>] | 导入函数地址
00D21020 | FF25 0020D200 | jmp dword ptr ds:[<&0x00D22000>] | 导入函数地址
反汇编后,可看到对MessageBox和ExitProcess函数的调用,变成了对<JMP.0x00D2101A>和<JMP.0x00D21020>地址的调用,但是这两个地址显然是位于程序自身模块,而不是系统模块中,实际上这是由于编译器在编译时,自动在程序代码的后面添加了jmp dword ptr ds:[<&0xxxxxx>]类型的跳转指令,其中的[xxxxx]地址中才是真正存放导入函数地址的地址.
PE文件在被装入内存后JMP跳转后面的地址才会被操作系统确定并填充到指定的位置上,那么在程序没有被PE装载器加载之前0x00D22000地址处的内容是什么呢,我们使用上面的PE解析器对节表进行解析观察.
----------------------------------------------------------------------------------------------------
编号 节区名称 虚拟偏移 虚拟大小 实际偏移 实际大小 节区属性
----------------------------------------------------------------------------------------------------
1 .text 0x00001000 0x00000026 0x00000400 0x00000200 0x60000020
2 .rdata 0x00002000 0x00000092 0x00000600 0x00000200 0x40000040
3 .data 0x00003000 0x00000015 0x00000800 0x00000200 0xC0000040
4 .rsrc 0x00004000 0x00000010 0x00000A00 0x00000200 0x40000040
5 .reloc 0x00005000 0x00000030 0x00000C00 0x00000200 0x42000040
----------------------------------------------------------------------------------------------------
由于该程序的OEP建议装入地址是0x0d20000所以0x0d22000地址实际上是处于RVA偏移为2000h的地方,我们再观察各个节的相对偏移,可发现2000h开始的地方位于.rdata节内,而这个节的实际偏移项为600h,也就是说0x0d22000地址的内容实际上对应到了PE文件中偏移600h处的数据.
你可以打开WinHEX十六进制查看器,或自己实现一个简单的十六文本进制转换器,对可执行文件进行十六进制转换与输出,使用Python实现代码如下.
import os,sys
import argparse
def BinaryToHex(FileName,Seek,Range):
count = 0
offset = 0
with open(FileName,"rb") as fp:
file_size = os.path.getsize(FileName)
fp.seek(int(Seek))
offset = int(Seek)
if int(Seek)+int(Range) < file_size:
print("-" * 60)
print("0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | offset")
print("-" * 60)
for item in range(int(Range)):
char = fp.read(1)
count = count + 1
if count % 16 == 0:
if ord(char) < 16:
print("0" + hex(ord(char))[2:] + " | ",end="")
else:
print(hex(ord(char))[2:] + " | ",end="")
print("0x%07d"%offset)
offset = offset + 16
else:
if ord(char) < 16:
print("0" + hex(ord(char))[2:] + " ",end="")
else:
print(hex(ord(char))[2:] + " ",end="")
else:
print("[-] 输入参数超出文件最大字节数.")
if __name__ == "__main__":
# 使用方式: main.py -e qq.exe -s 0 -c 100
parser = argparse.ArgumentParser()
parser.add_argument("-e","--exe",dest="exe",help="指定要打开的二进制文件")
parser.add_argument("-s","--seek",dest="seek",help="指定文件偏移位置")
parser.add_argument("-c","--count",dest="count",help="指定要读取的字节数")
args = parser.parse_args()
if args.exe and args.seek and args.count:
BinaryToHex(args.exe,args.seek,args.count)
else:
parser.print_help()
将光标拖到600h处,会发现其对应的地址是00002076h,这个地址显然也不会是ExitProcess函数的调用地址,此时我们将它作为RVA相对偏移来看呢?
C:\Users> python main.py -e c://pe/x86.exe -s 1536 -c 100
------------------------------------------------------------
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | offset
------------------------------------------------------------
76 20 00 00 00 00 00 00 5c 20 00 00 00 00 00 00 | 0x0001536
54 20 00 00 00 00 00 00 00 00 00 00 6a 20 00 00 | 0x0001552
08 20 00 00 4c 20 00 00 00 00 00 00 00 00 00 00 | 0x0001568
84 20 00 00 00 20 00 00 00 00 00 00 00 00 00 00 | 0x0001584
00 00 00 00 00 00 00 00 00 00 00 00 76 20 00 00 | 0x0001600
00 00 00 00 5c 20 00 00 00 00 00 00 b1 01 4d 65 | 0x0001616
查看节表可以发现RVA地址00002076h也处于.rdata节内(虚拟偏移+虚拟大小 > 2076h),我们拿00002076h减去节的起始地址0x2000h得到这个RVA相对于节首的偏移是76h,也就是说它对应文件为0x600+76 = 676h开始的地方,接下来观察可发现,这个位置的字符串正好就是ExitProcess对应的文件偏移中的位置.
C:\Users> python main.py -e c://pe/x86.exe -s 1648 -c 100
------------------------------------------------------------
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | offset
------------------------------------------------------------
2e 64 6c 6c 00 00 9b 00 45 78 69 74 50 72 6f 63 | 0x0001648
65 73 73 00 6b 65 72 6e 65 6c 33 32 2e 64 6c 6c | 0x0001664
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | 0x0001680
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | 0x0001696
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | 0x0001712
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | 0x0001728
最后的总结,当PE文件被装载到内存之前,Windows装载器会根据jmp dword ptr ds:[<xxxxxx>]里面的相对偏移RVA来得到函数名,再根据函数名在内存中找到函数地址,并且用函数的实际地址将[xxxxx]处的内容替换成真正的函数地址,从而完成对函数的调用解析.
2.5.2 IMAGE_IMPORT_DESCRIPTOR
导入表位置和大小可以从PE文件头中IMAGE_OPTIONAL_HEADER32结构的IMAGE_DATA_DIRECTORY数据目录字段中获取,从IMAGE_DATA_DIRECTORY字段得到的是导入表的RVA值,如果在内存中查找导入表,那么将RVA值加上PE文件装入的基址就是实际的地址.
首先我们需要找到数据目录表,找到了数据目录结构,就能找到导入表,导入表由一系列的IMAGE_IMPORT_DESCRIPTOR结构组成,结构的数量取决于程序需要使用的DLL文件数量,每个结构对应一个DLL文件,在所有结构的最后,由一个内容全为0的IMAGE_IMPORT_DESCRIPTOR结构作为结束标志,表结构定义如下:
typedef struct _IMAGE_IMPORT_DESCRIPTOR
{
union {
DWORD Characteristics;
DWORD OriginalFirstThunk; // 包含指向IMAGE_THUNK_DATA(输入名称表)结构的数组
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 当可执行文件不与被输入的DLL进行绑定时,此字段为0
DWORD ForwarderChain; // 第一个被转向的API的索引
DWORD Name; // 指向被输入的DLL的ASCII字符串的RVA
DWORD FirstThunk; // 指向输入地址表(IAT)的RVA
} IMAGE_IMPORT_DESCRIPTOR;
如上表结构定义中的OriginalFirstThunk和FirstThunk字段含义是相同的,他们都指向一个包含IMAGE_THUNK_DATA结构的数组,数组中每个IMAGE_THUNK_DATA结构定义了一个导入函数的具体信息,数组的最后以一个内容全为0的IMAGE_THUNK_DATA结构作为结束,该结构的定义如下:
typedef struct _IMAGE_THUNK_DATA32
{
union {
DWORD ForwarderString; // 转发字符串的RAV
DWORD Function; // 被导入函数的地址
DWORD Ordinal; // 被导入函数的序号
DWORD AddressOfData; // 指向输入名称表 PIMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA32;
从上方的结构定义不难看出,是一个双字共用体结构,当结构的最高位为1时,表示函数是以序号的方式导入的,这时双字的低位就是函数的序号,当双字最高位为0时,表示函数以函数名方式导入,这时双字的值是一个RVA,指向一个用来定义导入函数名称的IMAGE_IMPORT_BY_NAME结构,此结构定义如下:
typedef struct _IMAGE_IMPORT_BY_NAME
{
WORD Hint; // 函数序号
CHAR Name[1]; // 导入函数的名称
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
上面的所有结构就是导入表的全部了,如果但看这些东西,懵逼那是很正常的,其实总结起来就是下图这张表.
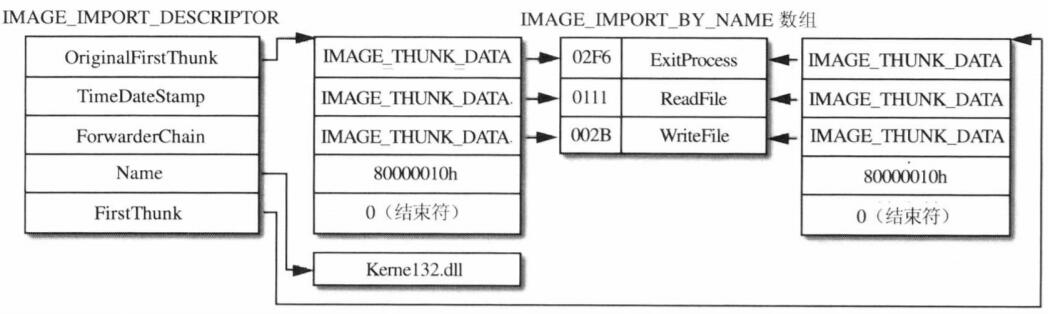
现在我们来分析下上图,导入表中IMAGE_IMPORT_DESCRIPTOR结构的NAME字段指向字符串Kernel32.dll表明当前程序要从Kernel32.dll文件中导入函数,OriginalFirstThunk和FirstThunk字段指向两个同样的IMAGE_THUNK_DATA数组,由于要导入4个函数,所有数组中包含4个有效项目并以最后一个内容为0的项目作为结束。
第4个函数是以序号导入的,与其对应的IMAGE_THUNK_DATA结构最高位等于1,和函数的序号0010h组合起来的数值就是80000010h,其余的3个函数采用的是以函数名方式导入,所以IMAGE_THUNK_DATA结构的数值是一个RVA,分别指向3个IMAGE_IMPORT_BY_NAME结构,每个结构的第一个字段是函数的序号,后面就是函数的字符串名称了,一切就这么简单!
上图为什么会出现两个一模一样的IMAGE_THUNK_DATA数组结构呢? 这是因为PE装载器会将其中一个结构修改为函数的地址jmp dword ptr[xxxx]其中的xxxx就是由FirstThunk字段指向的那个数组中的一员。
实际上当PE文件被装载入内存后,内存中的映像会被Windows修正为如下图所示的样子:
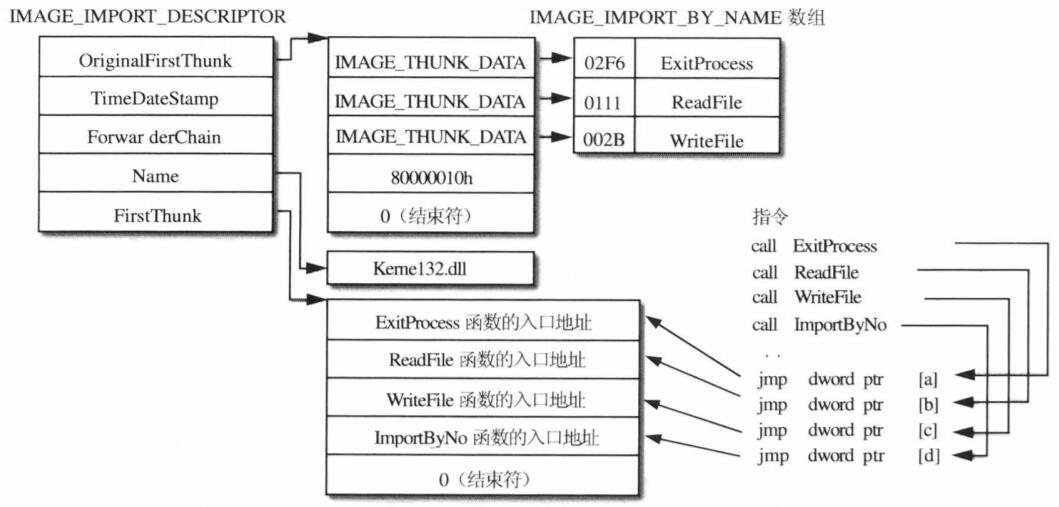
其中由FristThunk字段指向的那个数组中的每个双字都被替换成了真正的函数入口地址,之所以在PE文件中使用两份IMAGE_THUNK_DATA数组的拷贝并修改其中的一份,是为了最后还可以留下一份备份数据用来反过来查询地址所对应的导入函数名。
2.5.3 枚举导入表流程
通过编程实现读取导入表数据,首先通过(PIMAGE_IMPORT_DESCRIPTOR)(RVAtoFOA(rav) + GlobalFileBase)找到导入表结构体,并以此通过循环的方式输出每一个导入表中导入函数即可,这段代码实现如下所示;
int main(int argc, char * argv[])
{
BOOL PE = IsPeFile(OpenPeFile("c://pe/x86.exe"), 0);
if (PE == TRUE)
{
// 1. 从数据目录表的下标为1的项找到 rva
DWORD rav = NtHeader->OptionalHeader.DataDirectory[1].VirtualAddress;
// 2. 找到导入表结构体
auto ImportTable = (PIMAGE_IMPORT_DESCRIPTOR)(RVAtoFOA(rav) + GlobalFileBase);
// 3. 遍历导入表数组,数组以全0结尾
while (ImportTable->Name)
{
// 4. 输出对应DLL的名字
CHAR* DllName = (CHAR*)(RVAtoFOA(ImportTable->Name) + GlobalFileBase);
// printf("----> [遍历模块: %s] \n", DllName);
printf("Hint值 \t\t API序号 \t 文件RVA \t VA地址 \t 函数名称 \t 模块: [ %s ] \n", DllName);
// 5. 找到 IAT 表(文件中的导入表)
auto Iat = (PIMAGE_THUNK_DATA)(RVAtoFOA(ImportTable->FirstThunk) + GlobalFileBase);
// 这个是INT内存中的导入表
auto Int = (PIMAGE_THUNK_DATA)(RVAtoFOA(ImportTable->OriginalFirstThunk) + GlobalFileBase);
// 6. 遍历 IAT表 ,直到遇到 全 0 结束遍历
while (Iat->u1.Ordinal != 0)
{
// 7. 判断是否有名字
if (Iat->u1.AddressOfData & 0x80000000)
{
// 序号导入,直接输出
printf("[%5d] \t [None] \n", LOWORD(Iat->u1.AddressOfData));
}
else
{
// 找到名字结构体
auto Name = (PIMAGE_IMPORT_BY_NAME)(RVAtoFOA(Iat->u1.AddressOfData) + GlobalFileBase);
// 通过ImageBase与AddressOfData 相加得到VA
DWORD ImageBase = NtHeader->OptionalHeader.ImageBase;
DWORD VA = Iat->u1.AddressOfData + ImageBase;
printf("[%5d] \t %09d \t %08X \t %08X \t %s \n",
Name->Hint, Iat->u1.Ordinal, RVAtoFOA(Iat->u1.AddressOfData), VA, Name->Name);
}
++Iat;
}
// 指向下一个结构
ImportTable++;
}
}
else
{
printf("非标准程序 \n");
}
system("pause");
return 0;
}
编译并运行上述代码,则可输出当前程序中的所有导入函数信息,输出效果如下图所示;

本文作者: 王瑞
本文链接: https://www.lyshark.com/post/9108413f.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!