Redis是一个key-value的数据库,key一般是String类型,不过value的类型是多样的:
- String:hello word
- Hash:{name:"Jack",age:21}
- List:[A -> B -> C -> D]
- Set:{A,B,C}
- SortedSet:{A:1,B:2,C:3}
- GEO:{A:(120.3,30.5)}(地理坐标)
- BitMap:01101101010111010000100
- HyperLog:01101101010111010000100
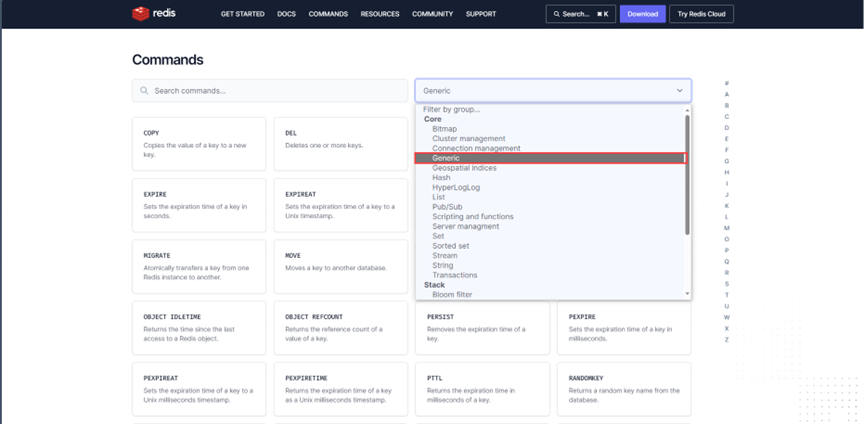
对于数据结构的操作是使用命令的方式去操作数据,Redis的命令操作分为通用操作和不同的数据类型对应的特有操作,这些命令在官网中都可以查到:

这里的分组就是根据不同的数据对应不同数据的特有操作去查询对应的操作。
通用命令
通用命令是不分数据类型的,都可以使用的指令,在官网中对应的分组是Generic
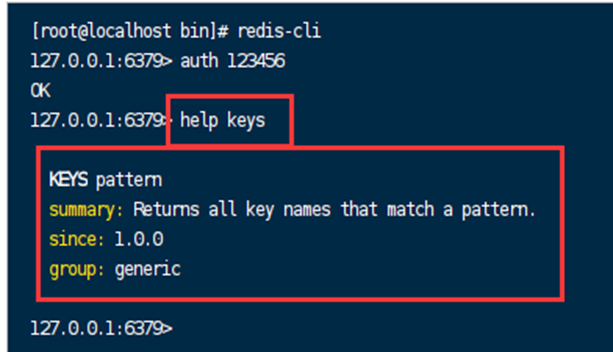
除了在官网上可以看到对应的命令的描述之外,还可以在命令行中使用help的方式去查看命令的使用方法:
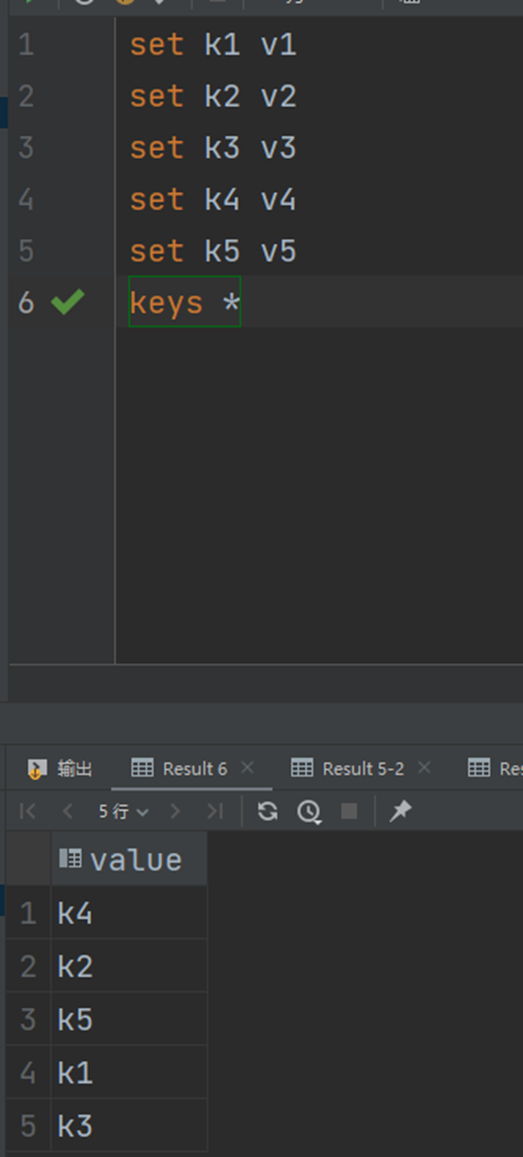
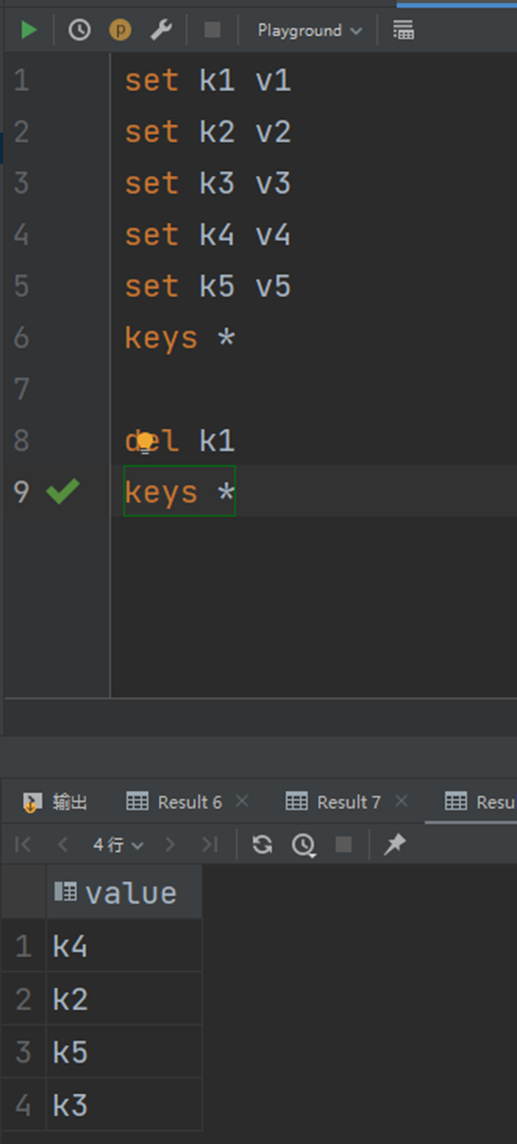

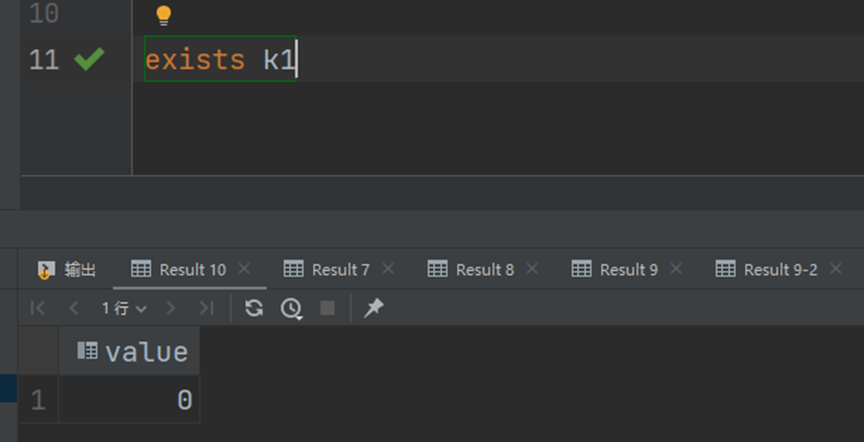
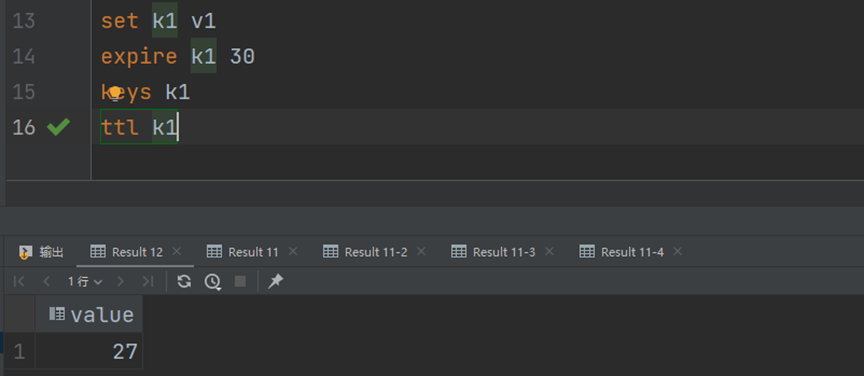

最终到时间,一般消失的时候有效期会显示为-2,这时候就会消失:
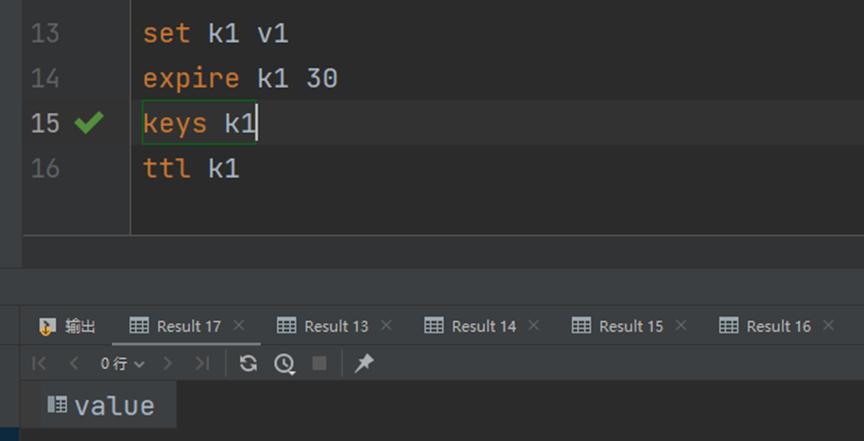
在不使用expire设置有效期的时候,数据的有效期为-1,表示永久有效。
String类型
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
不管是那种形式,底层都是字节数组形式存储,只不过是编码方式不同。字符类型的最大空间不能超过512m
String类型的常见命令
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整形的key自增1
- INCRBY:让一个整形的key自增并指定步长,例如:incrby num 2让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
Redis中key的结构
Redis的key允许有多个单词形成层级结构,多个单词之间用【:】隔开,格式如下:
这个格式并不是强制的,而是一种约定,可以按照自己的情况去修改这个约定。
例如,当我们有两个ID都为1的数据,比如用户的ID为1,而我的商品的ID也是1,那么就可以使用层级的方式区分这两个ID,例如:
user相关的ID:project:user:1
如果value是一个对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
product:user:1 = {"id":1,"name":"Jack","age":21}
product:product:1 = {"id":1,"name":"小米11","price":4999}

HASH类型
HASH类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

HASH结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:

HASH类型的常见命令:
HSET key field value:添加或者修改hash类型key的field的值
HGET key field:获取一个hash类型key的field的值
HGETALL:获取一个hash类型的key中的所有的field和value
HKEYS:获取一个hash类型的key中的所有的field
HVALS:获取一个hash类型的key中的所有的value
HINCRBY:让一个hash类型key的字段值自增并指定步长
HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
LIST类型
Redis中的List类型与]ava中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
常用来存储一个有序数据,例如: 朋友圈点赞列表,评论列表等。
LIST类型的常见命令
LPUSH key element...:向列表左侧插入一个或多个元素
LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
RPUSH key element...:向列表右侧插入一个或多个元素
LRANGE key star end:返回一段角标范围内的所有元素
BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
L表示左侧,也就是队首的位置,R表示右侧,也就是队尾的位置。B表示阻塞,即如果没有取到值,则会等待一段时间之后才会结束。
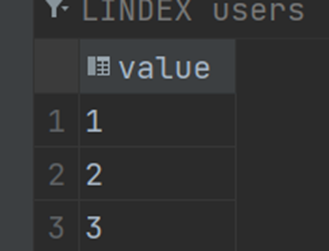
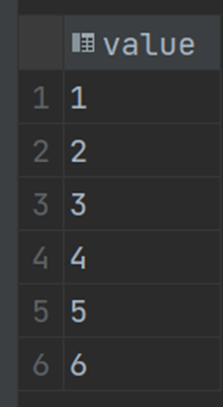
当使用LPUSH的时候,实际存储的元素和你输入的元素位置是相反的:

比如,当我们使用LPUSH将数据输出进入,但是实际的存储顺序与输入的顺序相反:

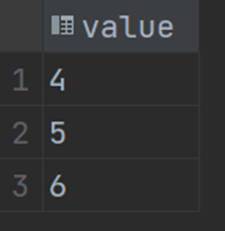
并且,需要注意的是,当你执行POP操作之后,数组里面的内容会消失:

阻塞指的是当我们获取某一个key对应的值的时候,这个值可能当时没有,但是经过一段时间的延迟之后才会被传入进去,这时候我们等待一段时间才能判断确实获取失败:
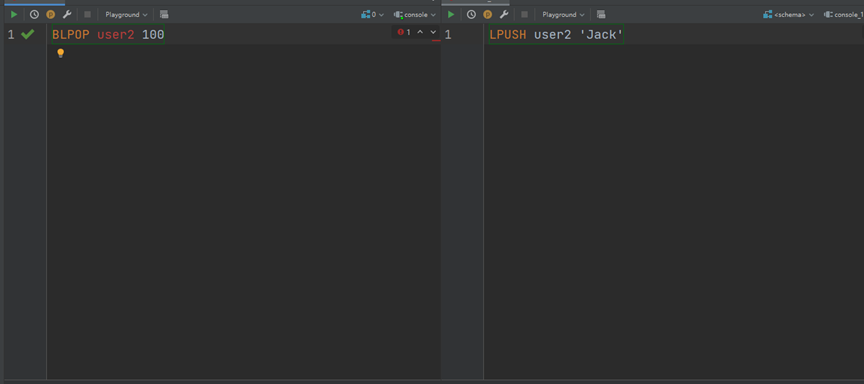
我们开启两个会话窗口,其中一个使用阻塞方法获取元素,另一个正常填充元素,但是我们现在首先启动阻塞方法去获取元素:

此时没有数据,他并不会马上就报错,而是等待一段时间,这个时间就是后面的参数,以秒为单位,比如上面我设置的是100秒,当100秒之后还没有数据,才会报错,现在我们执行另一个窗口中的传入元素的命令:
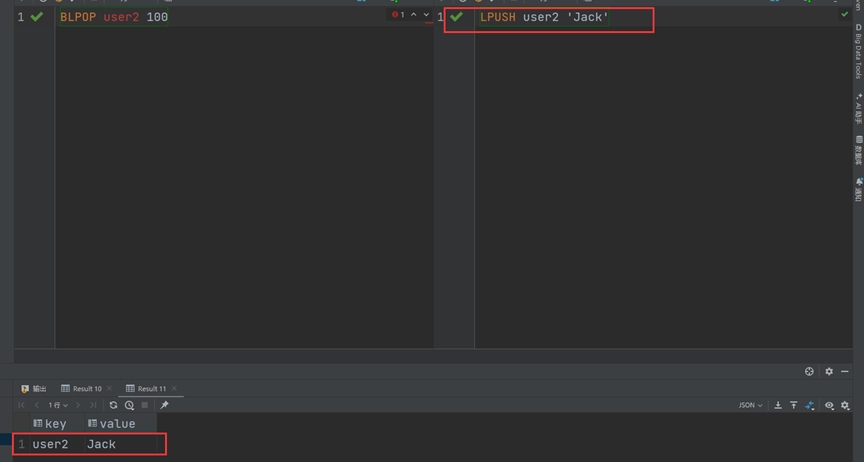
在另一个会话传入数据的一瞬间,另一边的阻塞获取数据的方法也会结束并获取到我们在另一个会话窗口中传入的数据。
如何利用LIST模拟一个栈
如何使用LIST模拟一个队列
如何使用LIST模拟一个阻塞队列
SET类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
SET的常用命令
在Redis中SET除了支持对单个SET的操作,还支持对多个SET之间的操作,就是求交集,并集,差集等操作,首先看对单个SET的操作指令:
SADD key member...:向set中添加一个或多个元素
SREM key member ...:移除set中的指定元素
SISMEMBER key member:判断一个元素是否存在于set中
SINTER key1 key2…:求key1与key2的交集
SDIFF key1 key2…:求key1与key2的差集
SUNION key1 key2 …:求key1和key2的并集
SET的练习
--Set命令练习
-- 将下列数据用Redis的Set集合来存储
-- 张三的好友有:李四、王五、赵六
-- 李四的好友有:王五、麻子、二狗
SADD zhangsan lis wangwu zhaoliu
SADD lisi wangwu mazi ergou
-- 利用Set的命令实现下列功能:
-- 计算张三的好友有几人
SCARD zhangsan
-- 计算张三和李四有哪些共同好友
SINTER zhangsan lisi
-- 查询哪些人是张三的好友却不是李四的好友
SDIFF zhangsan lisi
-- 查询张三和李四的好友总共有哪些人
SUNION zhangsan lisi
-- 判断李四是否是张三的好友
SISMEMBER zhangsan lisi
-- 判断张三是否是李四的好友
SISMEMBER lisi zhangsan
-- 将李四从张三的好友列表中移除
SORTEDSET类型
Redis的SortedSet是一个可排序的set集合,与]ava中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
Redis并不是基于元素本身进行排序,而是基于元素自带的score属性进行排序。
SORTEDSET类型的常用命令:
ZADD key score member:添加一个或多个元素到sorted set,如果已经存在则更新其score值
ZREM key member:删除sorted set中的一个指定元素
ZSCORE key member:获取sorted set中的指定元素的score值
ZRANK key member:获取sorted set 中的指定元素的排名
ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可
SortedSet命令练习
-- SortedSet命令练习
-- 将班级的下列学生得分存入Redis的SortedSet中
-- Jack 85, Lucy 89, Rose 82, Tom 95, Jerry 78, Amy 92, Miles 76
ZADD student 85 Jack 89 Locy 82 Rose 95 Tom 78 Jerry 92 Amy 76 Miles
-- 并实现下列功能:
-- 删除Tom同学
ZREM student Tom
-- 获取Amy同学的分数
ZSCORE student Amy
-- 获取Rose同学的排名
ZREVRANK student Rose
-- 查询80分以下有几个学生
ZCOUNT student 0 80
-- 给Amy同学加2分
ZINCRBY student 2 Amy
-- 查出成绩前3名的同学
ZREVRANGE student 0 2
-- 查出成绩80分以下的所有同学