在介绍大数据关键技术之前,先给出一张Hadoop大数据应用生态中最主要的组件图,该图描述了这些组件的地位,以及它们之间的相互关系。
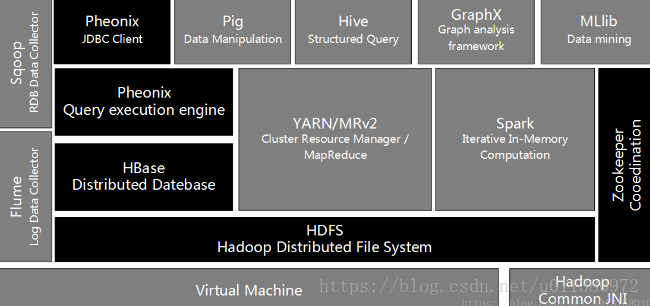
图1.Hadoop大数据应用生态组件及其关系
HDFS(Hadoop分布式文件系统)
HDFS是Hadoop体系中数据存储管理的基础,它是一个高容错的系统。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序访问功能。HDFS中数据以块的形式存储,默认数据块大小为64MB,同时分布存储在集群的不同物理机器上,副本数量默认为3提供一次写入多次读取的机制。
HDFS主要由三个组件构成,分别是NameNode、SecondaryNameNode和DataNode。
① NameNode保存数据的元信息,主要包括:文件名目录名以及它们之间的层级关系;文件目录的所有者及其权限;每个文件块的名及其文件有哪些块组成。
Hadoop只有一个NameNode这也导致了Hadoop集群的单点故障问题,为了解决这个问题,Hadoop提供了两种机制来解决。(1)将Hadoop元数据写入到本地文件系统的同时再实时同步到一个远程挂载的网络文件系统(NFS)。(2)运行一个SecondaryNameNode。
②SecondaryNameNode它的作用是与NameNode进行交互,定期通过编辑日志文件合并命名空间镜像,当NameNode发生故障时,它会通过自己合并的空间镜像的副本来恢复,但SecondaryNameNode并不是NameNode的备份。
③DataNode是HDFS中的Worker节点,它负责存储数据块,也负责为系统客户端提供数据块的读写服务。
MapReduce(分布式计算框架)
MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”进行规约,以得到最终结果。
HBase(分布式列存数据库)
HBase是一个建立在HDFS之上,面向结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。HBase采用了BigTable的数据模型-增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问。
ZooKeeper(分布式协作服务)
ZooKeeper的主要目标是解决分布式环境下的数据管理问题。如统一命名、状态同步、集群管理、配置同步等。Hadoop的许多组件依赖于ZooKeeper,它运行在计算机集群上面,用于管理Hadoop操作。
Hive(数据仓库)
Hive最初用于解决海量结构化的日志数据统计问题。Hive定义了一种类似于SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行,通常用于离线分析。
Pig(ad-hoc脚本)
其设计动机是提供一种基于Mapreduce的ad-hoc(计算在query时发生)数据分析工具。定义了一种数据流语言—Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行。
Sqoop(数据ETL/同步工具)
Sqoop主要用于传统数据库和Hadoop之间传输数据,数据的导入和导出本质上是MapReduce程序,充分利用了MR的并行化和容错性。Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
Flume(日志收集工具)
Mahout(数据挖掘算法库)
mahout只是一个机器学习的算法库,在这个库当中实现了相应的机器学习的算法,如:推荐系统(包括基于用户和基于物品的推荐),聚类和分类算法。并且这些算法有些实现了MapReduce,spark从而可以在hadoop平台上运行,在实际的开发过程中,只需要将相应的jar包即可。mahout的各个组件下面都会生成相应的jar包。
Yarn(分布式资源管理器)
Yarn是第二代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要为了解决原始Hadoop扩展性差,不支持多计算框架而提出的。该框架是hadoop2.x以后对hadoop1.x之前JobTracker和TaskTracker模型的优化,而产生出来的,将JobTracker的资源分配和作业调度及监督分开。该框架主要有ResourceManager,Applicationmatser,nodemanager。其主要工作过程如下:
- ResourceManager主要负责所有的应用程序的资源分配,
- ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个ApplicationMaster。
- Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体。
ResourceManager在接收到client的作业提交请求之后,会分配一个Conbiner,这里需要说明一下的是Resoucemanager分配资源是以Conbiner为单位分配的。第一个被分配的Conbiner会启动Applicationmaster,它主要负责作业的调度。Applicationmanager启动之后则会直接跟NodeManager通信。
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
在Yarn平台上可以运行多个计算框架,如:MR,Tez,Storm,Spark等计算,框架。
Spark(内存DAG计算模型)
Phoenix(HBase的SQL驱动)
Phoenix是HBase的SQL驱动(HBase SQL接口),Phoenix使得HBase支持通过JDBC的方式进行访问,并将你的SQL查询转换成HBase的扫描和相应的动作。
Kafka(消息系统)
Kafka是开源的消息系统,主要用于处理活跃的流式数据。
Ambari(管理工具)
Ambari是安装部署配置管理工具,其作用就是创建、管理、监视Hadoop的集群,是为了让Hadoop以及相关的大数据软件更容易使用的一个Web工具。