近日,实验室三篇论文被语音研究顶级期刊IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)录用,一篇论文被重要期刊IEEE Signal Processing Letters (IEEE SPL)录用,论文方向涉及说话人识别中的对抗攻击、基于扩散模型的跨语种情感迁移语音合成、语音转换中基于多层级韵律建模的风格迁移、基于语言模型的语音转换。现对四篇论文工作进行简要介绍。
-1-
-
论文题目:Timbre-reserved Adversarial Attack in Speaker Identification
-
作者列表:王晴,姚继珣,张丽,郭鹏程,谢磊
-
发表期刊:IEEE/ACM Transactions on Audio, Speech and Language Processing
-
论文网址:https://arxiv.org/abs/2309.00929
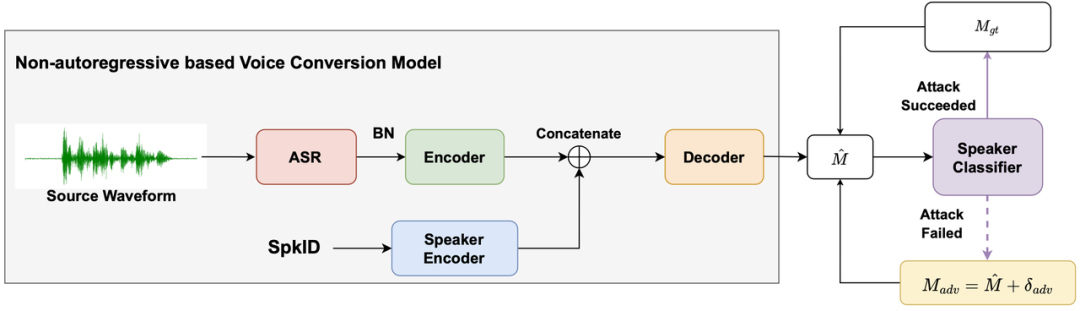
内容简介:作为一种生物特征识别技术,说话人识别(Speaker Identification, SID)系统面临各种攻击。欺骗攻击(Spoofing Attack)通常模仿目标说话人的音色,而对抗攻击(Adversarial Attack)则通过向任意语音添加经过精心设计的对抗扰动来混淆SID系统。尽管欺骗攻击复制了与目标说话人相似的音色,但没有把SID这个下游任务考虑进去,并未利用SID模型的弱点,不能完全使SID系统产生攻击者所期望的决策。至于对抗攻击,尽管SID系统可以被引导到特定的决策上,但它不能满足特定攻击场景中特定的的文本或说话人音色要求。在本文中,为了对说话人识别模型中的攻击不仅利用SID模型的弱点,还可以保留目标说话人的音色,我们提出了一种保留音色的对抗攻击方法。我们通过在语音转换(Voice Conversion, VC)模型的不同训练阶段添加对抗约束来生成保留音色的对抗伪造音频。具体来说,对抗约束是使用目标说话人标签来优化添加到VC模型表示中的对抗扰动,并通过加入VC模型训练的说话人分类器来实现。对抗约束可以帮助控制VC模型生成特定说话人的音频。最终,VC模型的推理结果是理想的保留音色的对抗伪造音频,可以欺骗SID系统。在音频深度伪造检测挑战赛(Audio Deepfake Detection Challenge, ADD)数据集上的实验结果表明,我们提出的方法显著提高了攻击成功率,与仅在攻击语音中直接添加对抗扰动的普通VC模型的结果是可比的。客观和主观评估表明,本文方法生成的伪造音频的质量优于直接向VC生成的音频添加对抗扰动。此外分析显示,生成的对抗伪造音频也符合攻击者指定的文本和目标说话人音色保留要求。
-2-
-
论文题目:DiCLET-TTS: Diffusion Model based Cross-lingual Emotion Transfer for Text-to-Speech -- A Study between English and Mandarin
-
作者列表:李涛, 胡晨旭, 从坚, 朱新发, 李静北, 田乔,王玉平, 谢磊
-
发表期刊:IEEE/ACM Transactions on Audio, Speech and Language Processing
-
合作单位:字节跳动
-
论文网址:http://arxiv.org/abs/2309.00883
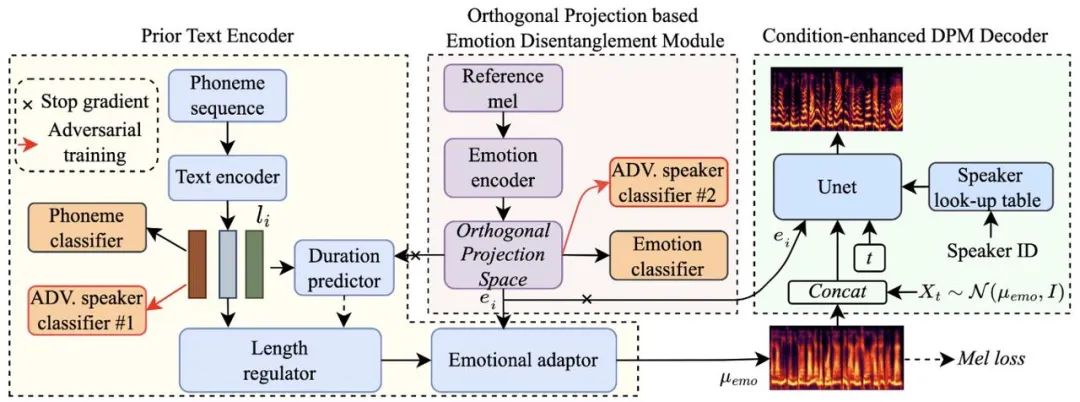
内容简介:跨语种语音合成旨在赋予目标发音人说外语的能力。虽然基于单语语料库的跨语种语音合成的性能得到了显著改善,但合成的跨语种语音仍然受到外国口音问题的影响,导致合成语音的自然度有限。此外,当前的跨语种语音合成方法大多忽略了情感建模,而情感是人类语音中不可或缺的副语言信息。针对上述问题,本文提出了DiCLET-TTS,一种基于扩散模型的跨语种情感迁移方法,可以将情感从源说话人迁移至语种内的和跨语种的目标说话人。具体来说,为了缓解外国口音问题,同时提升情感表现力,前向扩散过程的终端分布被先验文本编码器以情感嵌入为条件,参数化为与说话人无关但与情感相关的语义先验。为了解决从情感嵌入中去除说话人信息而导致迁移的情感表现力较弱的问题,提出了一种新颖的基于正交投影的情感解耦模块(OP-EDM)以学习与说话人无关但具有情感判别性的嵌入。此外,引入条件增强的扩散解码器来增强反向扩散过程中说话人和情感的建模能力,进一步提高语音传递中的情感表现力。实验表明,尽管语种内情感迁移的性能优于更具挑战性的跨语种迁移,但与三种基线方法相比,DiCLET-TTS 在语内和跨语种迁移方面都可以有效提升合成语音的自然度、情感相似度和说话人相似度。同时,嵌入可视化和偏好测试证明了 OP-EDM 在学习与说话人无关但具有情感判别性的情感嵌入方面的优势。
-3-
-
论文题目:MSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
-
作者列表:王智超,王新升,谢启聪,李涛,谢磊,田乔,王玉平
-
发表期刊:IEEE/ACM Transactions on Audio, Speech and Language Processing
-
合作单位:字节跳动
-
论文网址:https://arxiv.org/abs/2309.01142
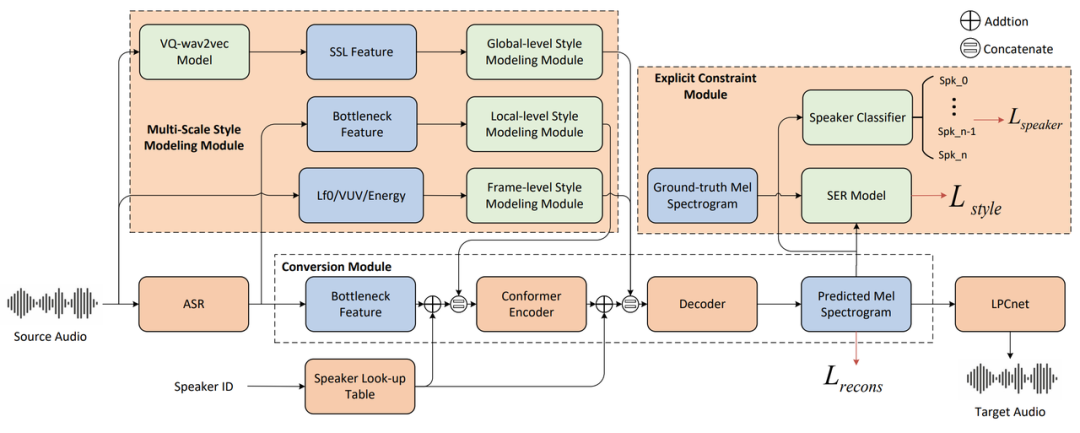
内容简介:在语音转换(Voice Conversion, VC)任务中,除了需要将源语音的语义内容传递给转换后的语音,保持源语音中的讲话风格同样十分的重要,它对于许多需要高表现语音的场景十分关键,比如电影电视配音、数据增广等。过去的方法通常使用基于信号提取的韵律特征或者网络学习的定长风格表征来表示源语音的讲话风格,但是这种方式下对于实现全面的风格建模和目标说话人音色保留是不充足的。受语音风格多尺度性质的启发,本文提出了一种用于 VC 任务的多尺度风格建模方法,简称 MSM-VC。MSM-VC 从不同级别(全局、局部和帧级)对源语音的说话风格进行建模。为了有效地建模说话风格,同时防止源语音中音色信息泄露到转换后的语音,每个级别的风格都通过特定的特征来建模。具体来说, 韵律特征、预训练的 ASR 模型的瓶颈特征以及自监督模型提取的特征分别对帧级、局部和全局的风格进行建模。同时,为了平衡源语音风格建模和目标说话人音色保留的能力,我们引入了由预训练的语音情感识别模型和说话人分类器组成的显式约束模块。这种显式约束模块还可以在训练过程中模拟风格迁移的推理过程,能够提高模型解耦能力并减轻训练与推理之间的不匹配。在高表现力语音测试集上进行的实验表明,MSM-VC 优于过去的 VC 方法。提出的方法可以实现对源语音风格进行建模,同时保持良好的语音质量和说话人相似性。此外,消融分析证明了每个风格级别建模的必要性以及每个模块的有效性。
-4-
-
论文题目:LM-VC: Zero-shot Voice Conversion via Speech Generation based on Language Models
-
作者列表:王智超,陈远哲,谢磊,田乔,王玉平
-
发表期刊:IEEE Signal Processing Letters
-
合作单位:字节跳动
-
论文网址:https://arxiv.org/abs/2306.10521
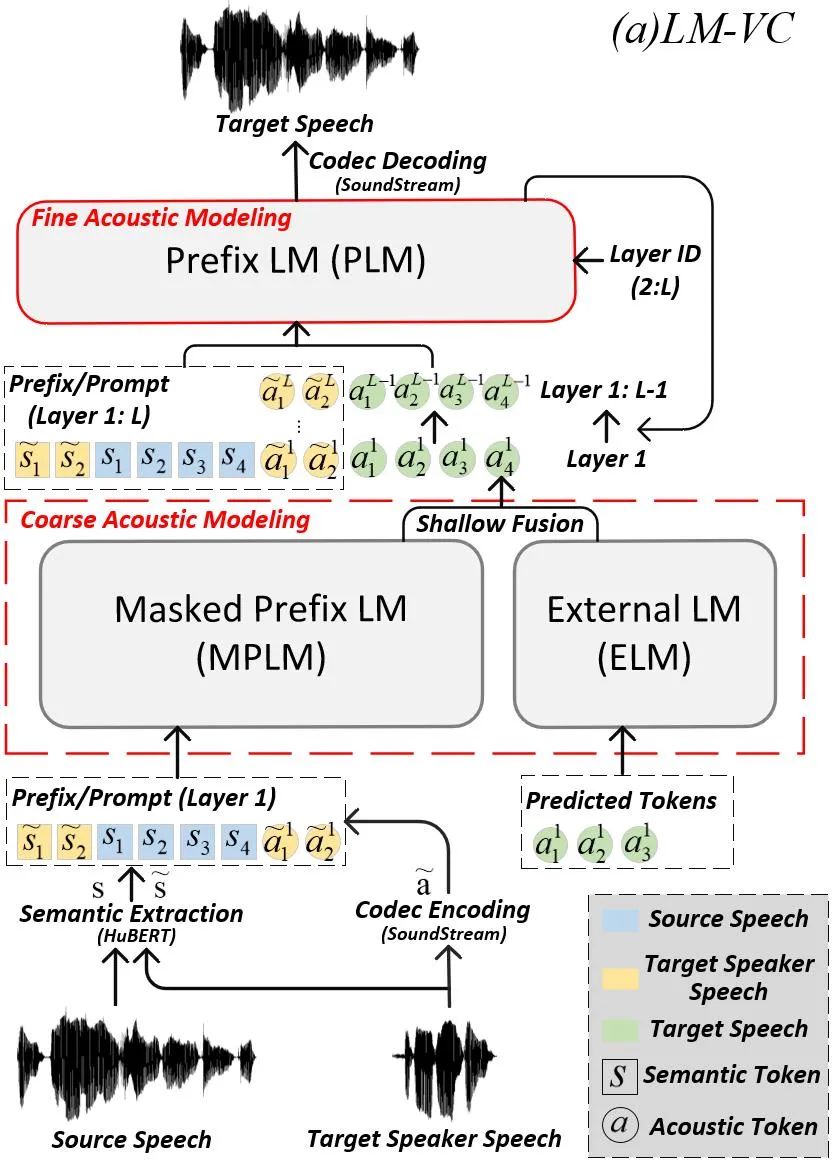
内容简介:基于语言模型 (Lauguage Model, LM) 的音频生成框架(例如 AudioLM)最近在零样本音频生成方面实现了非常优越的性能。本文探索了LM用于零样本语音转换(Zero-shot Voice Conversion)的潜力。最直观的方法是参照AudioLM的框架——通过HuBERT和SoundStream将语音分别表示为语义标记(Semantic Token)和声学标记(Acoustic Token),并根据目标说话人的声学标记将源语音的语义标记转换为目标语音的声学标记。然而,这种方案的问题是:1)语义标记中包含的语言内容可能在多层建模过程中逐渐变弱,而语音转换任务中较长的语音输入使上下文学习变得更加困难;2)语义标记仍然包含少量说话人相关的信息,这些信息可能会泄漏到目标语音中,从而降低目标说话人的相似度;3)LM采样时的多样性可能会导致推理过程中出现错误的结果,从而导致发音不自然和语音质量下降。为了缓解这些问题,我们提出了 LM-VC,这同样是一种两阶段的语言建模方法,它生成粗略的声学标记来恢复源语音的语言内容和目标说话人的音色,然后重建包含声学细节的精细声学标记最终得到转换后的语音。具体来说,为了增强语言内容的传递并促进更好的解耦,我们使用带有掩模预测策略的掩模前缀语言模型(Masked Prefix Language Model, MPLM)进行粗略声学建模。该模型被要求从周围上下文中恢复屏蔽的内容,并根据目标说话人的语音和损坏的语义标记来生成目标语音。此外,为了进一步减轻生成过程中的采样误差,我们引入了一个外部语言模型(External Language Model, ELM),它利用窗口注意力机制(Window Attention)来捕获局部的声学关系,通过浅层融合(Shallow Fusion)参与粗略的声学建模过程。最后,前缀语言模型(Prefix Language Model, PLM)以非自回归的方式从粗略的声学标记中重建精细的声学标记,并产生转换后的语音。实验表明,LM-VC 在语音自然度和说话人相似度方面优于对比系统。