前言:因为容器使用namespace以及cgroup来资源隔离和限制,这里也先简单来了解和整理下
简介:
Namespace是将内核的全局资源做封装,使得每个Namespace都有一份独立的资源,因此不同的进程在各自的Namespace内对同一种资源的使用不会互相干扰。
Cgroup(control group)是内核提供的一种资源隔离的机制,可以实现对进程所使用的cpu、内存物理资源、及网络带宽等进行限制。还可以通过分配的CPU时间片数量及磁盘IO宽带大小控制任务运行的优先级。
一、Namespace解析
目前Linux内核总共支持以下6种Namespace:
- IPC:隔离System V IPC和POSIX消息队列。
- Network:隔离网络资源。
- Mount:隔离文件系统挂载点。
- PID:隔离进程ID。
- UTS:隔离主机名和域名。
- User:隔离用户ID和组ID。
Linux对Namespace的操作,主要是通过 clone、setns 和 unshare 这3个系统调用来完成的,clone创建新进程时,接收一个叫flags的参数,这些flag包括 CLONE_NEWNS、CLONE_NEWIPC、CLONE_NEWUTS、CLONE_NEWNET(Mount namespace)、CLONE_NEWPID和CLONE_NEWUSER ,用于创建新的namespace,这样clone创建出来新进程之后就属于新的namespace了,后续新进程创建的进程默认属于同一namespace。
如果想要给已存在进程设置新的namespace,可通过unshare函数(long unshare(unsigned long flags))完成设置,其入参flags表示新的namespace。当想要给已存在进程设置已存在的namespace,可通过setns函数(int setns(int fd, int nstype))来完成设置,每个进程在procfs目录下存储其相关的namespace信息,可找到已存在的namesapce,然后通过setns设置即可:
[root@k8s-node1 kubernetes]# ll /proc/23/ns
total 0
lrwxrwxrwx. 1 root root 0 Nov 23 08:53 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 Nov 23 08:53 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 Nov 23 08:53 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 Nov 23 08:53 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 Nov 23 08:53 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Nov 23 08:53 uts -> uts:[4026531838]
上述每个虚拟文件对应该进程所处的namespace,如果其他进程想进入该namespace,open该虚拟文件获取到fd,然后传给setns函数的fd入参即可,注意虚拟文件type和nstype要对应上。
六种namespace的简单介绍:
1、IPC
IPC也就是进程间通信,Linux下有多种进程间通信,比如socket、共享内存、Posix消息队列和SystemV IPC等,这里的IPC namespace针对的是SystemV IPC和Posix消息队列,其会用标识符表示不同的消息队列,进程间通过找到标识符对应的消息队列来完成通信,IPC namespace做的事情就是相同的标识符在不同namespace上对应不同的消息队列,这样不同namespace的进程无法完成进程间通信。
2、Network
Network Namespace隔离网络资源,每个Network Namespace都有自己的网络设备、IP地址、路由表、/proc/net目录、端口号等。每个Network Namespace会有一个loopback设备(除此之外不会有任何其他网络设备)。因此用户需要在这里面做自己的网络配置。IP工具已经支持Network Namespace,可以通过它来为新的Network Namespace配置网络功能。
3、Mount
Mount namesapce用户隔离文件系统挂载点,每个进程能看到的文件系统都记录在/proc/$$/mounts里。在创建了一个新的Mount Namespace后,进程系统对文件系统挂载/卸载的动作就不会影响到其他Namespace。
4、PID
PID Namespace用于隔离进程PID号,这样一来,不同的Namespace里的进程PID号就可以是一样的了。当创建一个PID Namespace时,第一个进程的PID号是1,也就是init进程。init进程有一些特殊之处,例如init进程需要负责回收所有孤儿进程的资源。另外,发送给init进程的任何信号都会被屏蔽,即使发送的是SIGKILL信号,也就是说,在容器内无法“杀死”init进程。
5、UTS
UTS Namespace用于对主机名和域名进行隔离,也就是uname系统调用使用的结构体structutsname里的nodename和domainname这两个字段,UTS这个名字也是由此而来的。为什么需要uts namespace呢,因为为主机名可以用来代替IP地址,比如局域网通过主机名访问机器。

6、User
User Namespace用来隔离用户资源,比如一个进程在Namespace里的用户和组ID与它在host里的ID可以不一样,这样可以做到,一个host的普通用户可以在该容器(user namespace)下拥有root权限,但是它的特权被限定在容器内。(容器内的这类root用户,实际上还是有很多特权操作不能执行,基本上如果这个特权操作会影响到其他容器或者host,就不会被允许)
二、Cgroup解析
相关名称的概念:
- 任务(task): 在cgroup中,任务相当于是一个进程,可以属于不同的cgroup组,但是所属的cgroup不能同属一层级
- 任务/控制组: 资源控制是以控制组的方式实现的,进程可以加入到指定的控制组中,类似于Linux中user和group的关系。控制组为树状结构的上下父子关系,子节点控制组会继承父节点控制组的属性,如资源配额等
- 层级(hierarchy): 一个大的控制组群树,归属于一个层级中,不同的控制组以层级区分开
- 子系统(subsystem): 一个的资源控制器,比如cpu子系统可以控制进程的cpu使用率,子系统需要附加(attach)到某个层级,然后该层级的所有控制组,均受到该子系统的控制
层级结构关系
- 1.在创建新层级时,系统中所有任务都是那个层级的默认顶级cgroup,我们称之为 root cgroup ,后面该层级中创建的子cgroup都是隶属于此父cgroup。
- 2.一个子系统最多只能附加到一个层级。
- 3.一个层级可以附加多个子系统
- 4.一个任务可以是多个cgroup的成员,但是这些cgroup必须在不同的层级。
- 5.系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的cgroup。
为了便于理解,个人理解以图来辅助说明
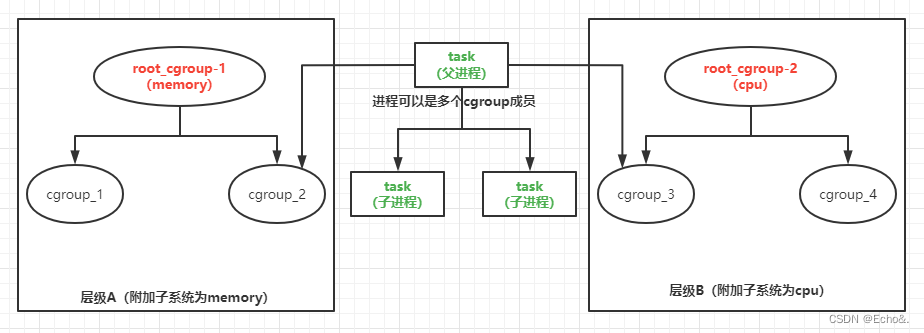
简单介绍上图:
1、分为两个层级A和B,分别附加子系统为Memory和CPU
2、cgroup_1和cgroup_2隶属于root_cgroup_1中,又都归属于层级A,为子系统memory来管理此层级内所属进程的配额
3、cgroup_3和cgroup_4隶属于root_cgroup_2中,又都归属于层级B,为子系统cpu来管理此层级内所属进程的配额
4、task任务进程可以属于多个cgroup组,上图所属组为cgroup_2和cgroup_3
常见的子系统如下:
- cpu 子系统: 主要限制进程的 cpu 使用率。
- cpuacct 子系统: 可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统: 为cgroups中的进程分配单独的cpu节点或者内存节点。
- memory 子系统: 可以限制进程的 memory 使用量。
- blkio 子系统: 可以限制进程的块设备 io。
- devices 子系统: 可以控制进程能够访问某些设备。
- net_cls 子系统: 可以标记cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统: 可以挂起或者恢复 cgroups 中的进程。
- ns 子系统: 可以使不同 cgroups 下面的进程使用不同的 namespace。
测试使用
在/sys/fs/cgroup/cpu目录下创建一个container目录,这个目录就称为一个“控制组”,系统会自动生成该子系统对应的资源限制文件
[root@k8s-node2 cpu]# pwd
/sys/fs/cgroup/cpu
[root@k8s-node2 cpu]# mkdir container
[root@k8s-node2 cpu]# ls container
cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
创建一个占用100%CPU的进程
[root@k8s-node2 cpu]# while : ; do : ; done & #死循环
[1] 23066
可用top查看到此进程的CPU占用率逐渐增加到100%
查看 container 目录下的文件
container 控制组里的 CPU quo ta还没有任何限制(即:-1)CPU period 则是默认的 100ms(100000 us)
[root@k8s-node2 container]# cat cpu.cfs_quota_us
-1
[root@k8s-node2 container]# cat cpu.cfs_period_us
100000
修改cpu.cfs_quota_us值,来限制cpu资源
向 container 组里的 cfs_quota 文件写入 20 ms(20000 us)
echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
这个操作的含义:它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
然后把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
[root@k8s-node2 container]# echo 23066> tasks
可以使用top查看对应进程的资源占用,就可以查看到进程所占用的cpu资源很快降到了20%
小结
一般namespace都是和cgroup结合来使用的,但是直接操作Namespace和Cgroup并不是很容易,因此docker的出现就显得有必要了,Docker通过Libcontainer来处理这些底层的事情。这样一来,Docker只需要简单地调用Libcontainer的API,就能将完整的容器搭建起来。而作为Docker的用户,就更不用操心这些事情了,只需要通过一两条简单的Docker命令启动容器即可。
End……