之前学习了docker的一些原理和文件系统,对于其核心技术namespace和cgroup没有一个很好的认识,下面将记录其知识点
Namespace
概念
namespce资源隔离,又称为命名空间,它主要做访问隔离。其原理是针对一类资源进行抽象,并将其封装在一起提供给一个容器使用,对于这类资源,因为每个容器都有自己的抽象,而他们彼此之间是不可见的,所以就可以做到访问隔离。
docker就是通过这样一种技术,使自己内部进程在不同于外部namespce下进行,以达到独立的隔离的目的
容器6六项隔离
想要实现一个资源隔离的容器,也许第一反应就是chroot命令,隔离文件系统。接着为了在分布式的环境下进行通信和定位,容器必然有独立的IP,端口,路由等,进行网络隔离。同时,容器还需要一个独立的主机名以便在网络中标识自己。有了网络,自然离不开通信,进程间也要隔离。对用户和用户组的隔离实现了用户权限隔离,最后,容器中所运行应用的进程号自然也与宿主机中的PID进行隔离,这样就形成了容器的六项隔离

用图来表述整个隔离过程
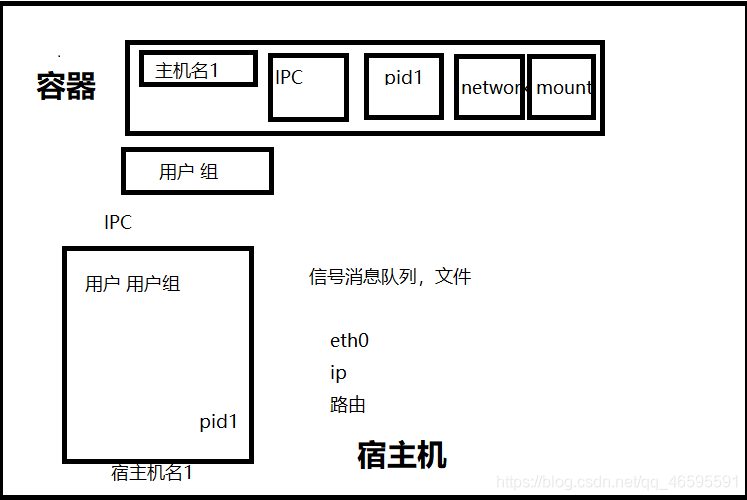
图中可以看到宿主机和容器之间有相同的UTS,IPC,PID,Network,Mount,User,
通过隔离使其在不同的命名空间下,这就形成相互不干扰
Namespace API实际操作
namespace的API包括clone()、setns()以及unshare(),还有/proc下的部分文件。为了确定隔离的到底是哪种namespace,在使用这些API时,通常需要指定以下六个常数的一个或多个,通过|(位或)操作来实现。你可能已经在上面的表格中注意到,这六个参数分别是CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER和CLONE_NEWUTS
1.通过clone()创建新进程的同时创建namespace
使用clone()来创建一个独立namespace的进程是最常见做法,它的调用方式如下
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
2.查看/proc/pid/ns文件
3.通过setns()加入一个已经存在的namespace
在进程都结束的情况下,也可以通过挂载的形式把namespace保留下来,保留namespace的目的自然是为以后有进程加入做准备。通过setns()系统调用,你的进程从原先的namespace加入我们准备好的新namespace,使用方法如下
int setns(int fd, int nstype);
4.通过unshare()在原先进程上进行namespace隔离
它跟clone()很像,不同的是,unshare()运行在原先的进程上,不需要启动一个新进程,使用方法如下
int unshare(int flags);
这里使用的是第二种
1.echo $$ // 查看当前宿主机进程号
2. ls -l /proc/进程号/ns //查看宿主机namespace
3. docker ps //查看某个容器的ID
4. docker inspect --format='{{. State.Pid}} ' 容器ID //查看某个容器的进程号
5. ls -l /proc/容器进程号/ns //查看容器namespace
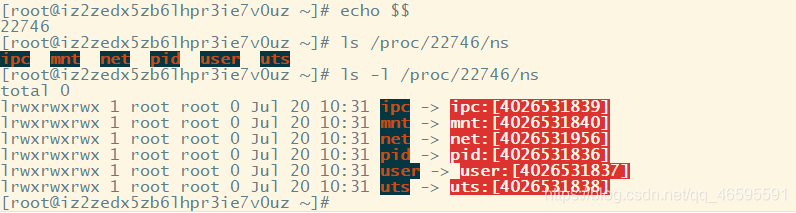

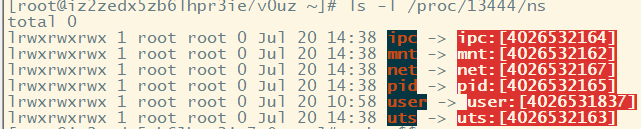
可以明显地看到两者namespace不同
下面用图更好地解释
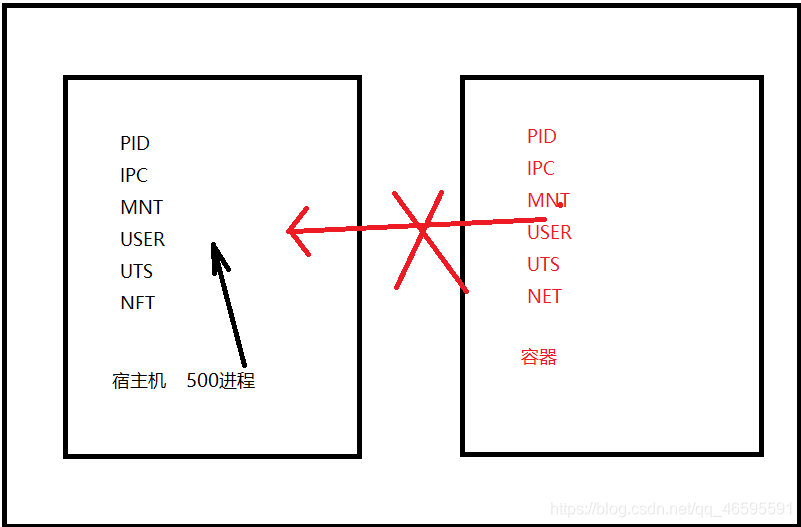
Cgroup
概念
控制群组 control groups :在一个系统中运行的层级制进程组,可对资源进行分配,如CPU时间、系统内存、网络带宽等
主要提供以下功能
限制进程组可以使用的资源(Resource limiting ):比如memory子系统可以为进程组设定一个memory使用上限,进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)
进程组的优先级控制(Prioritization ):比如可以使用cpu子系统为某个进程组分配cpu share
记录进程组使用的资源量(Accounting ):比如使用cpuacct子系统记录某个进程组使用的cpu时间
进程组隔离(Isolation):比如使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间
进程组控制(Control):比如使用freezer子系统可以将进程组挂起和恢复
资源控制器 也称cgroup子系统,代表单一资源
blkio – 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
cpu – 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
cpuacct – 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
cpuset – 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
devices – 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
freezer – 这个子系统挂起或者恢复 cgroup 中的任务。
memory – 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
net_cls – 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包
实际操作
一般来说,docker容器一般用cgroup控制CPU和内存Memory
1.对基于centos镜像运行一个容器,要求CPU使用权重为512的实际操作
1.cat /sys/fs/cgroup/cpu/cpu.shares //查看宿主机CPU的权重
2. docker run -it centos //运行一个容器
3. cat /sys/fs/cgroup/cpu/cpu.shares //查看容器中CPU的权重 发现和宿主机一样
4. exit //退出容器
5. docker run -it --name 容器名 -c 512 centos
6. cat /sys/fs/cgroup/cpu/cpu.shares //查看修改后容器中CPU的权重



2.基于centos镜像运行一个容器,要求内存为200M,内存交换空间为400M
1.cat /sys/fs/cgroup/memory/memory.limit_in_bytes //查看宿主机内存的限制
2.cat /sys/fs/cgroup/memory/memory.memsw.limit_in_bytes //查看宿主机交换空间的限制
3.同样的对一个容器进行查看
4.docker run -it --name 容器名 -m 300M --memory-swap 400M centos //启动一个容器限制内存为300M,交换空间为400M
5.cat /sys/fs/cgroup/memory/memory.limit_in_bytes
cat /sys/fs/cgroup/memory/memory.memsw.limit_in_bytes ////对容器进行查看确认


