系列文章目录
一、kafka基本原理
二、使用java简单操作kafka
三、简单了解kafka设计原理
一、Kafka核心总控制器Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
- 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
- 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
- 当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到。
关于总控制器是怎么选出来的呢?
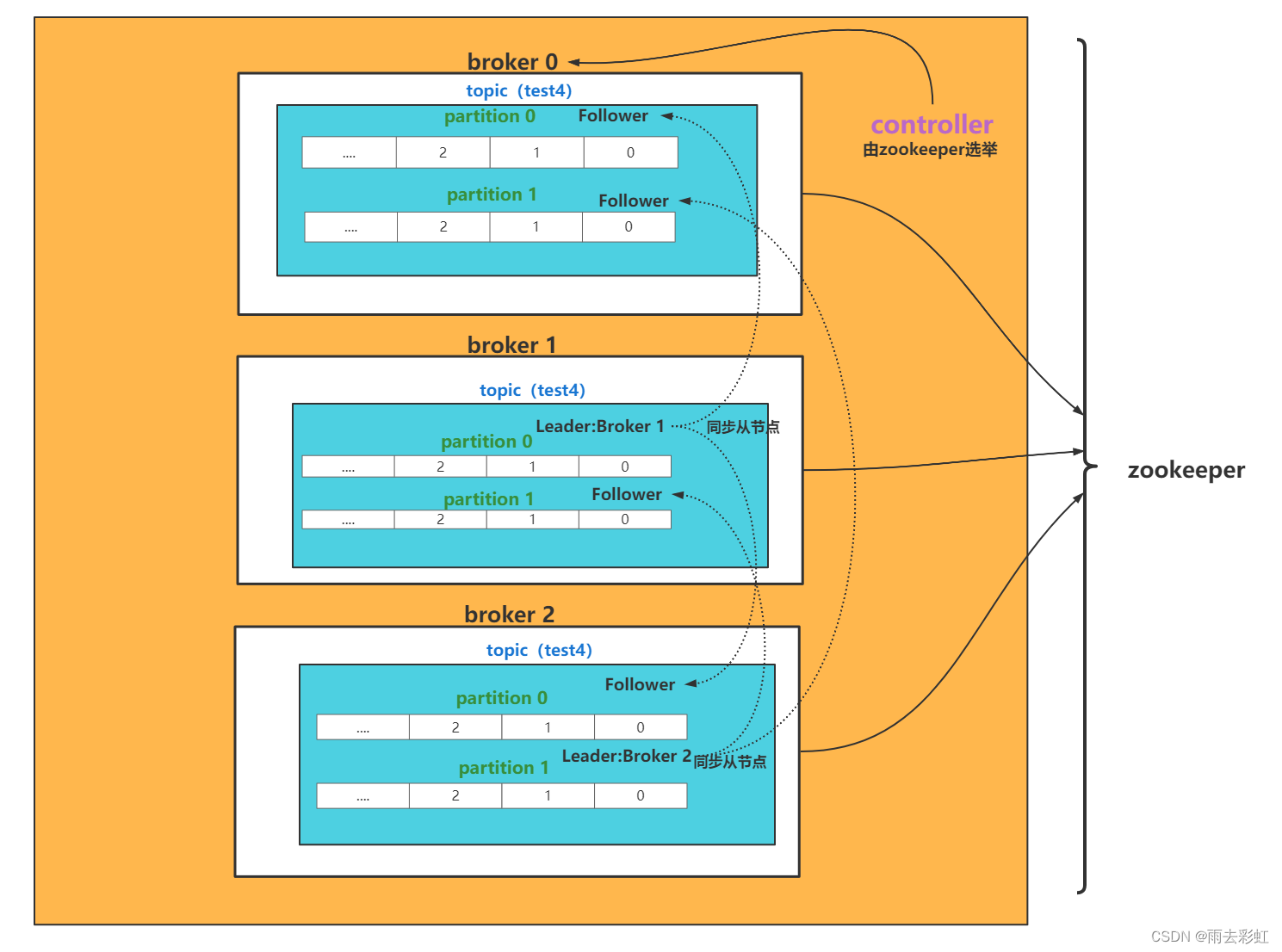
情况一:
如果kafka集群是一台一台启动的,那么最先启动的就是controller。
情况二;
同时启动,所有的kafka节点都会向zookeeper发送create命令,谁先创建成功,谁就是controller,如果controller挂了,还是会按照这样重新选举。
controller具体细节:
1.监听broker相关的变化。为zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增加减少变化(kafka集群增加减少节点)
2.监听topic相关变化。为zookeeper中的/brokers/topics/节点添加TopicChangeListener,用来处理topic的增加减少变化。为zookeeper中的/admin/delete_topics/[topic]/节点添加TopicDeletionListener,用来处理删除topic的动作。
3.从zookeeper中获取当前所有的与topic、partition和broker有关的信息进行相应的管理。对于所有topic所对应的zookeeper中的/brokers/topics/[topic]/中添加PartitionModificationsListener,用来监听topic中的分区分配变化。
4.更新集群的元数据信息,同步到其他普通的broker节点中。
Partition副本选举Leader机制
controller感知到分区leader所在的broker挂了(controller监听了很多zookeeper节点可以感知到broker存活),controller会从ISR列表(配置为unclean.leader.election.enable=false的前提下)里挑一个broker为leader,如果isr列表里边都挂了,那么会一直卡在这块,影响消息的写入。(在Isr前面的broker,也就是最先放假isr列表的broker,可能是同步数据最多的副本),如果配置为unclean.leader.election.enable=true,这种情况下,只有在isr列表的broker都挂了之后,回去取isr列表之外的存活的broker,这种设置可以提高可用性,但是新的leader可能有部分数据没有同步,数据会少很多。
消费者消费消息的offset记录机制
每个consumer会定期将自己消费分区的offset提交给kafka内部topic:_consumer_offsets,提交过去的时候,key是consumerGroupId+topic+分区号,value就是当前的offset值,kafka会定期清理topic里的消息,最后就保留最新的那条数据,因为_consumer_offsets可能会接受高并发的请求,kafka默认给其分配50个分区(通过offsets.topic.num.partitions设置),这样做的好处是可以更好的抗并发。
如果没有指定提交的分区,会有一个公式来计算提交的那个分区上。
公式:hash(consumerGroupId) % __consumer_offsets主题的分区数
消费者Rebalance机制
rebalance就是消费组里的消费者数量变化,或者消费的分区数有变化,kafka会重新分配消费组消费分区的关系。例如消费组中某个消费者挂了,此时会自动把分配给他的分区交给其他消费者,如果他又重新启动,那么又会把一些分区重新分给他。
Rebalance只针对subscribe这种不指定分区消费的情况,如果通过assign指定分区消费,则kafka不会进行rebanlance。
可能触发kafka的Rebalance的情况:
1.消费组里的consumer增加或减少了。
2.动态给topic增加了分区
3.消费组订阅了更多的topic
Rebalance过程中,消费者无法从kafka消费消息,这对kafka的tps会有影响,如果kafka集群内节点较多,那么重平衡会耗时非常多,尽量避免业务高峰时间发生。
消费者Rebalance分区分配策略:
主要有三种策略:range、round-robin、sticky。
1.range:按照分区序号排序。假设 n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。比如分区0-3给一个consumer,分区4-6给一个consumer,分区7-9给一个onsumer。
2.round-robin:轮询分配。比如分区0、3、6、9给一个consumer,分区1、4、7给一个consumer,分区2、5、8给一个consumer
3.sticky:初始时分配策略与round-robin类似,但是在rebalance的时候,需要保证如下两个原则。
①分区的分配要尽可能均匀 。
②分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。
比如对于第一种range情况的分配,如果第三个consumer挂了,那么重新用sticky策略分配的结果如下:
consumer1除了原有的0-3,会再分配一个7
consumer2除了原有的4-6,会再分配8和9
二、kafka高性能简单理解
1.磁盘顺序读写:kafka不能修改以及不会从文件中间删除保证了磁盘顺序读(保证数据连续),kafka的消息写入文件都是追加在文件末尾,不会写入文件中的某个位置保证了磁盘顺序写。
2.数据传输零拷贝
3.读写数据的批量处理,以及压缩传输