什么是Kafka
传统定义:Kafka是一个分布式的基于发布/订阅模式的消息队列,主要用于大数据实时处理领域。
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者指接受自己感兴趣的消息。
戳这里:了解消息队列
现在的定义:Kafka是一个 开源 的 分布式事件流平台(Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。
Kafka诞生背景
kafka 的诞生,是为了解决linkedin的数据管道问题,起初linkedin采用了ActiveMQ来进行数据交换,大约是在2010年前后,那时的ActiveMQ还远远无法满足linkedin对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,linkedin决定研发自己的消息传递系统,当时 linkedin 的首席架构师jay kreps便开始组织团队进行消息传递系统的研发。
Kafka基础结构
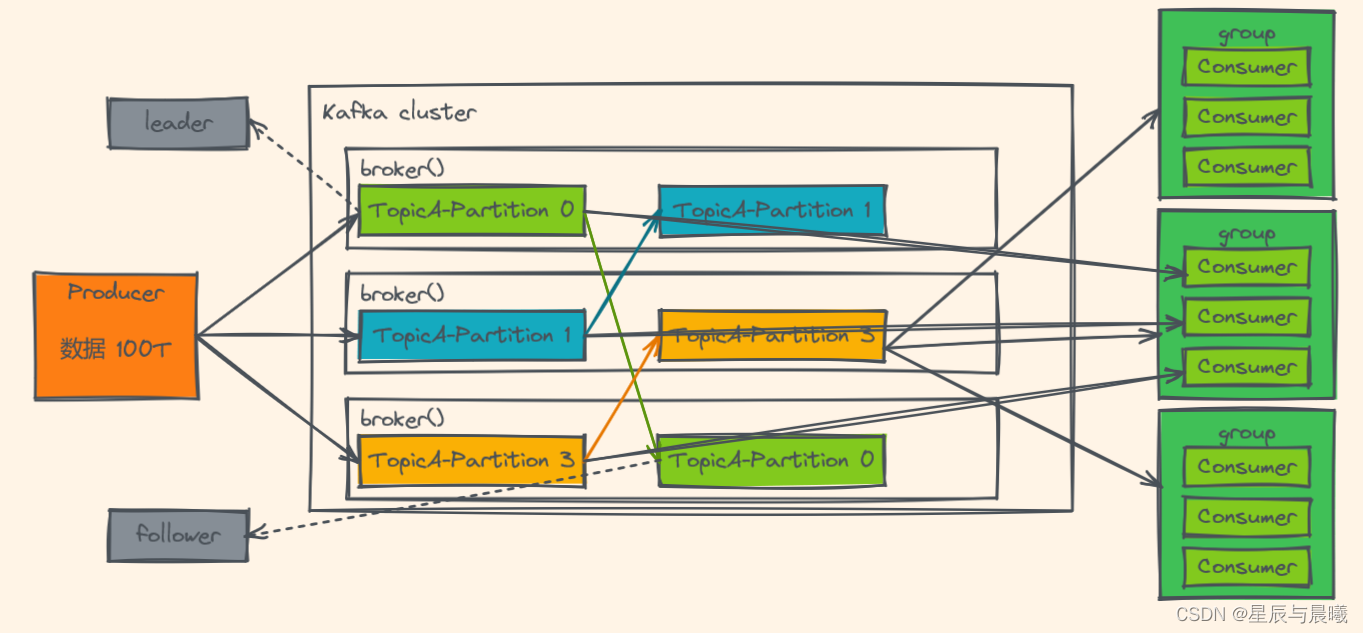
- 为方便扩展,并提高吞吐量,一个topic分为多个partiton
- 配合分区的设计,提高消费者组的概念,组内每个消费者并行消费
- 为提高可用性,为每一个partition 增加若干副本,类似NameNode HA
- ZK中记录谁是leader,Kafka 2.8.0以后的版本也可以配置不采用ZK
- Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
- Consumer:消息消费者,向 Kafka broker 取消息的客户端。
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
Kafka 的优势
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅模式 | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持Java优先 | 语言无关 | 支持Java优先 | 支持 |
| 单机吞吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微妙级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 底 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供的快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 底 | 中 | 高 |
在大数据技术领域,一些重要的组件、框架都支持Apache Kafka,不论成成熟度、社区、性能、可靠性,Kafka都是非常有竞争力的一款产品。