一般来说,神经网络和大数据的关系十分复杂,影响因素包括:模型的大小,数据集的大小,计算性能, 还有其他因素, 如:人力、时间等。下面对现有的内容做了一个整理:
一、 数据量VS网络性能
1.总述
在《Revisiting Unreasonable Effectiveness of Data in Deep Learning Era》中,Sun等人将过去10年来的计算机视觉技术取得了重大成功的原因归功于:1>复杂度更高的模型,2>计算性能的提高【参考1,参考2】,3>大规模标签数据集的出现。
针对第一个问题,我们每年都可以看到计算性能和模型复杂度的提高,从2017年7层的AlexNet发展到2015年101层的ResNet,以及现在参数量更加庞大的Transformer技术。
针对第二个问题,可以参考1和2,总的来说,研究学者发现,每年通过更新GPU,提升GPU性能所带来的性能提高甚至要高于对模型本身的更新。新GPU所带来强大的计算量,可以让模型推理更加迅速和高效。
针对第三个问题,我们都知道深度学习是数据驱动的,那么训练集扩大10倍,100倍,精确度是否会成倍提高,是否存在瓶颈?下面重点探讨这个问题。
2. 研究目标

该文章指出近年来,模型大小和GPU性能都在提高,而数据集并未提高,因此他们构建了3亿张图的数据集进行实验验证。他们的研究目标在于:
1)使用当前的算法,如果提供越来越多带噪声标签的图片,视觉表现是否仍然可以得到优化;
2)对于标准的视觉任务,例如分类、对象探测,以及图像分割,数据和性能之间的关系是什么;
3)利用大规模学习技术,开发能胜任计算机视觉领域各类任务的最先进的模型。
3. 数据构建
问题在于数据集怎么构建,好在Google一直努力构建这样的数据集,以优化计算机视觉算法。在Geoff Hinton、Francois Chollet等人的努力下,Google内部构建了一个包含3亿张图片的数据集,将其中的图片标记为18291个类,并将其命名为JFT-300M(未开源)。
该数据集的图片标记所用的算法混合了复杂的原始网络信号,以及网页和用户反馈之间的关联。通过这种方法,这3亿张图片获得了超过10亿个标签(一张图片可以有多个标签)。在这10亿个标签中,约3.75亿个通过算法被选出,使所选择图片的标签精确度最大化。然而,这些标签中依然存在噪声:被选出图片的标签约有20%是噪声。简单来说就是,数据量越大,噪声越大,对模型的训练难度更大。
4. 核心的实验结果
作者通过实验验证得到了一些结果:
* 更好的表征学习(Representation Learning)能带来帮助。
我们观察到的首个现象是,大规模数据有助于表征学习,从而优化我们所研究的所有视觉任务的性能。我们的发现表明,建立用于预训练的大规模数据集很重要。这还说明无监督表征学习,以及半监督表征学习方法有良好的前景。看起来,数据规模继续压制了标签中存在的噪声。
* 随着训练数据数量级的增加,任务性能呈对数上升。
或许最令人惊讶的发现在于,视觉任务性能和表现学习训练数据量(取对数)之间的关系。我们发现,这样的关系仍然是线性的。即使训练图片规模达到3亿张,我们也没有观察到性能上升出现停滞。如下图所示:

* 模型容量非常关键。
我们观察到,如果希望完整利用3亿张图的数据集,我们需要更大容量(更深)的模型。
例如,对于ResNet-50,COCO对象探测得分的上升很有限,只有1.87%,而使用ResNet-152,这一得分上升达到3%。
* 长尾训练。
我们的数据有很长的尾巴,但表示学习似乎有效。这种长尾似乎不会对 ConvNets 的随机训练产生不利影响(训练仍然会收敛)。
* 新的最高水准结果。
我们的论文用JFT-300M去训练模型,多项得分都达到了业界最高水准。例如,对于COCO对象探测得分,单个模型目前可以实现37.4 AP,高于此前的34.3 AP。
需要指出,我们使用的训练体系、学习进度以及参数基于此前用ImageNet 1M图片训练ConvNets获得的经验。
由于我们并未在这项工作中探索最优的超参数(这将需要可观的计算工作),因此很有可能,我们还没有得到利用这一数据集进行训练能取得的最佳结果。因此我们认为,量化的性能报告可能低估了这一数据集的实际影响。
这项工作并未关注针对特定任务的数据,例如研究更多边界框是否会影响模型的性能。我们认为,尽管存在挑战,但获得针对特定任务的大规模数据集应当是未来研究的一个关注点。
此外,构建包含300M图片的数据集并不是最终目标。我们应当探索,凭借更庞大的数据集(包含超过10亿图片),模型是否还能继续优化。
5. 其他实验结果

* 预训练权重的fine-tuning十分重要
二、预训练权重VS性能
1. 总述
Google研究人员发表了一篇名为BigTransfer的论文《Big Transfer (BiT): General Visual Representation Learning》,探索了如何有效利用超常规的图像数据规模来对模型进行预训练,并对训练过程进行的系统深入的研究。
为了探索数据规模对于模型性能的影响,他们重新审视了目前常用的预训练配置(包括激活函数和权重的归一化,模型的宽度和深度以及训练策略),同时利用了三个不同规模的数据集包括:ILSVRC-2012 (1000类128万张图像), ImageNet-21k (2.1万类的1400万张图像) 和 JFT (1.8万类的三亿张图像),更重要的是基于这些数据研究人员可以探索先前未曾涉足的数据规模。
2. 研究内容
* 数据集规模和模型容量间的关系
作者选择了ResNet不同的变体进行训练。从标准大小的“R50x1”到x4倍宽度的,再到更深度152层“R152x4”,都在上面的数据集上进行了训练。随后研究人员获得了关键的发现,如果想要充分利用大数据的优势,就必须同时增加模型的容量。

左半部分显示了随着数据量的增加需要扩充模型的容量,红色箭头的扩大意味着小模型架构在大数据集下变差,而大模型架构则得到改善。右图显示了在大数据集下的预训练并不一定改善,而是需要提高训练时间和计算开销来充分利用大数据的优势。
训练的时间对模型性能也具有关键的作用。如果在大规模数据集上没有进行充分地训练调整计算开销的话,性能会有显著下降(上图中有半部分红色点到蓝色点下降),但通过适当地调整模型训练时间就能得到显著的性能提升。
* 适当的归一化BN可以有效地提高性能
1>将批归一化BN替换为组归一化GN后可以有效提升预训练模型在大规模数据集上的性能,其原因主要来源于两个方面:
- 首先在从预训练迁移到目标任务时BN的状态需要进行调整,而GN却是无状态的从而避开了需要调整的困难;
- 其次,BN利用每一批次的统计信息,但这对于每个设备上的小批量来说这种统计信息会变得不可靠,而对于大型模型来说多设备上的训练不可避免。由于GN不需要计算每个批次的统计信息,又一次成功避开了这一问题;
* 迁移学习
基于构建BERT过程中的方法,研究人员将BiT模型在一系列下游任务上进行调优,而在调优的过程中只使用了非常有限的数据,预训练模型已经对视觉特征有着良好的理解,

数据量大小,ILSVRC< ImageNet<JFT-300M,当利用非常少的样本对BiT进行迁移学习时,研究人员发现随着预训练过程中使用的数据量和架构容量的增加,所得到迁移后的模型性能也在显著增加。当在较小数据集ILSVRC上增加模型容量时,1-shot和5-shot情况下迁移CIFAR得到的增益都较小(下图中绿线)。而在大规模的JFT数据集上进行预训练时,模型容量增加会带来显著的增益(红棕色线所示),BiT-L可以在单样本和五样本上达到64%和95%的精度。
3. 结论
本研究发现在大规模通用数据的训练下,简单的迁移策略就可以达到令人瞩目的成果,无论是基于大数据还是小样本数据甚至单样本数据,通过大规模预训练的模型在下游任务中都能取得显著的性能提升。BiT预训练模型将为视觉研究人员提供代替ImageNet预训练模型的全新选择。
三、两个知乎的优秀答案
1. 角度1
建议仔细读一读PRML这本经典教材的第3.2节(当然为了读懂3.2,必须先读完第1章),它详细解释了在数据量增加的情况下会发生什么事情。其中最核心的结论是如下分解:
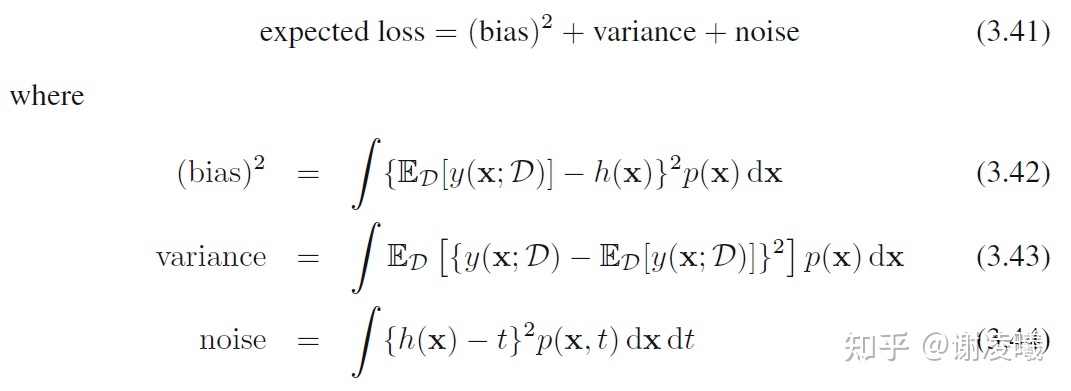
在数据量固定的情况下,bias和variance之间存在一个tradeoff,一个增加另一个就会减少。在数据量增加的情况下,这两项之和可以进一步减小,但是noise项是无法消除的。
因此,这个问题有如下简单而初步的结论:
- 如果数据量无限且有精确标注,那么理论上机器学习模型能够拟合出完美函数,前提是这个模型具有足够的复杂度和精确度。顺便,无限精确数据的场景是可能存在的,比如使用虚拟引擎去生成数据。此时,虽然一个模型无法在有限时间内使用无限数据,但是随着训练的进行,数据量可以趋于无穷。
- 如果数据量无限但是没有精确标注,那么最终模型的精度会受限于标注的噪声。
- 如果数据量有限,那么模型必须在bias和variance之间权衡:要让模型在广泛的测试数据上表现稳定(variance比较小),模型的普遍预测精度就会下降(bias比较大);要让模型在某些测试数据的子集上表现良好(bias比较小),模型就必须牺牲其他可能的测试数据的精度。
2. 角度2
特别地,当你的训练数据足够多时,泛化误差是有可能减小的非常小的。这可以从经典的机器学习理论得到结论:
若为有限空间且0 <
< 1,则对任意的
都有:
其中m表示训练数据的数量,当m趋于无穷大,即训练样本足够多,学习得到的分类器与理想的分类器
之前的差异越老越小,在上式中表示二者差异小于一特别小的数的概率大于
,即此事发生的概率非常之大。
再次,这样的网络会过拟合吗?过拟合是机器学习领域的重要问题,其与你的网络结构、训练方式、数据难度等都有密切关系。例如,如果你的数据虽然量多、但是几乎都雷同(数据之间相似度度高),那么这个网络其实是欠拟合的,因为真实世界中的数据更加复杂;另一个极端视角,如果你的数据不仅多而且各不相同,那当然会过拟合。
最后,数据量巨大时,网络可能会饱和。但和上一个问题一样,仍然取决于你数据的质量。理想状态下用一个网络拟合世界上所有已知数据,那么当然会饱和啦。
注:上式理论中提到假设空间是有限的。但我们无法确定当训练数据特别多时,假设空间是否真的有限,所以仍然无法回答这个问题。毕竟机器学习是基于数据的科学。
四、个人思考:
数据量,预训练模型权重,数据质量, 神经网络的容量
数据越多,预测越好,但是当训练样本量大,如果网络层次太少,特征训练不充分,将会导致训练不充分。所以数据集越大,效果越好的,其中的一个前提是网络的特征提取能力不能太差(神经网络容量问题)。
数据量越多,样本量要求越多,数据质量需要提高, 里面不能包含过多的噪点和相似数据,这些都会对网络的学习产生负面影响。
大数据集上的预训练模型的权重在其他数据集上有着很好的迁移效果。
参考:
https://blog.csdn.net/emprere/article/details/98858910