1、python form xxx import xxx *
from XXX improt *
XXX是可以是模块或者你自己编写的PY文件名
假设 有一个文件test.py,它里面定义了一个函数prints
#test.py
def prints(参数)
print 参数
如果你想在别的文件里调用这个文件的prints函数,那么有2种方法:
1. import test
这个时候想要调用prints函数就是
test.prints() #文件名加点
2. from test import *
这时候把test.prints()直接可以写成prints()。#把前面的test.不要了
*号表示那个文件里的所有东西都import
如果想调用个别的函数或者变量,可以写成
from test import prints #只是import prints这个函数
2、import numpy as np
Numpy是Python的一个科学计算的库,提供了矩阵运算的功能,其一般与Scipy、matplotlib一起使用。其实,list已经提供了类似于矩阵的表示形式,不过numpy为我们提供了更多的函数。
numpy还是很强大的,这里把一些矩阵基本操作做一些整理,方便大家,也方便我自己码代码的时候查找。
有句话对于我这个初学者来说觉得还是挺符合的,翻书看视频浏览教程贴啊什么的,会发现很多知识点,一开始并不用非得记下都有些什么函数,问题是好像也记不住,学过去之后只要知道这个东西它都能实现什么些什么功能能干些什么事就够了,在你写程序的时候你需要实现什么,这时候再去查找就足够了,用着用着自然就记住了。
犹记得那时候苦翻C++ Primer Plus那本书时的悲痛,学语言不用的话真是看后面忘前面。
1.函数库的导入
import numpy #或者
import numpy as np2.基本运算
2.1.求和 .sum()
2.2.求最大值 .max()
2.3.求最小值 .min()
2.4.求平均值 .mean()
import numpy as np
test1 = np.array([[5, 10, 15],
[20, 25, 30],
[35, 40, 45]])
test1.sum()
# 输出 225
test1.max()
# 输出 45
test1.min()
# 输出 5
test1.mean()
# 输出 25.02.5.矩阵行求和 .sum(axis=1)
test1 = np.array([[5, 10, 15],
[20, 25, 30],
[35, 40, 45]])
test1.sum(axis=1)
# 输出 array([30, 75, 120])2.6.矩阵列求和 .sum(axis=0)
test1 = np.array([[5, 10, 15],
[20, 25, 30],
[35, 40, 45]])
test1.sum(axis=0)
# 输出 array([60, 75, 90])2.7.矩阵乘法
import numpy as np
a = np.array([[1, 2],
[3, 4]])
b = np.array([[5, 6],
[7, 8]])
print (a*b) # 对应位置元素相乘
print (a.dot(b)) # 矩阵乘法
print (np.dot(a, b)) # 矩阵乘法,同上
# 输出 [[5 12]
[21 32]]
[[19 22]
[43 50]]
[[19 22]
[43 50]] 2.8.元素求平方: a**2
a = np.range(4)
print (a)
print (a**2)
# 输出 [0, 1, 2, 3]
[0, 1, 4, 9]2.9.元素求e的n次幂: np.exp(test)
元素开根号: np.sqrt(test)
import numpy as np
test = np.arange(3)
print (test)
print (np.exp(test)) #e的n次幂
print (np.sqrt(test)) #开根号
# 输出 [0 1 2]
[1. 2.71828183 7.3890561]
[0 1. 1.41421356]2.10.向下取整: .floor()
import numpy as np
test = np.floor(10*np.random.random((3, 4)))
print (test)
# 输出 [[ 3. 8. 7. 0.]
[ 5. 9. 8. 2.]
[ 3. 0. 9. 0.]]2.11.平坦化数组: .ravel()
# 二维n行n列转换为一维数组
test.ravel()
# 输出 array([ 3., 8., 7., 0., 5., 9., 8., 2., 3., 0., 9., 0.])
# 数据接上面,下同2.12.矩阵转置: .T
test.shape = (6, 2)
print (test)
# 输出 [[ 3. 8.]
[ 7. 0.]
[ 5. 9.]
[ 8. 2.]
[ 3. 0.]
[ 9. 0.]]
test.T # test的转置
# 输出 array([[ 3., 7., 5., 8., 3., 9.],
[ 8., 0., 9., 2., 0., 0.]])2.13.矩阵拼接按行: np.vstack((a, b))
矩阵拼接按列: np.hstack((a, b))
import numpy as np
a = np.floor(10*np.random.random((2, 2)))
b = np.floor(10*np.random.random((2, 2)))
print (a)
print ('---')
print (b)
print ('---')
print (np.vstack((a, b))) # 按行拼接,也就是竖方向拼接
print ('---')
print (np.hstack((a, b))) # 按列拼接,也就是横方向拼接
# 输出 [[ 5. 3.]
[ 8. 0.]]
---
[[ 3. 0.]
[ 6. 3.]]
---
[[ 5. 3.]
[ 8. 0.]
[ 3. 0.]
[ 6. 3.]]
---
[[ 5. 3. 3. 0.]
[ 8. 0. 6. 3.]]2.14.矩阵分割按列: np.hsplit(a, 3) 和 np.hsplit(a, (3, 4))
import numpy as np
a = np.floor(10*np.random.random((2, 12)))
print (a)
# 输出 [[ 6. 7. 5. 7. 9. 1. 2. 3. 1. 9. 5. 7.]
[ 6. 5. 2. 0. 1. 7. 8. 2. 7. 0. 5. 9.]]
print (np.hsplit(a, 3)) # 按列分割,也就是横方向分割,参数a为要分割的矩阵,参数3为分成三份
print ('---')
print (np.hsplit(a, (3, 4))) # 参数(3, 4)为在维度3前面也就是第4列前切一下,在维度4也就是第5列前面切一下
# 输出 [array([[ 6., 7., 5., 7.],
[ 6., 5., 2., 0.]]), array([[ 9., 1., 2., 3.],
[ 1., 7., 8., 2.]]), array([[ 1., 9., 5., 7.],
[ 7., 0., 5., 9.]])]
---
[array([[ 6., 7., 5.],
[ 6., 5., 2.]]), array([[ 7.],
[ 0.]]), array([[ 9., 1., 2., 3., 1., 9., 5., 7.],
[ 1., 7., 8., 2., 7., 0., 5., 9.]])]2.15.矩阵分割按行: np.vsplit(a, 3) 和 np.vsplit(a, (3, 4))
import numpy as np
a = np.floor(10*np.random.random((12, 2)))
print (a)
# 输出 [[ 5. 4.]
[ 8. 7.]
[ 3. 1.]
[ 6. 0.]
[ 4. 4.]
[ 4. 5.]
[ 2. 4.]
[ 7. 3.]
[ 1. 6.]
[ 6. 9.]
[ 2. 1.]
[ 3. 0.]]
print (np.vsplit(a, 3)) # 按行分割,也就是横竖方向分割,参数a为要分割的矩阵,参数3为分成三份
print ('---')
print (np.vsplit(a, (3, 4))) # 参数(3, 4)为在维度3前面也就是第4行前切一下,在维度4也就是第5行前面切一下
# 输出 [array([[ 5., 4.],
[ 8., 7.],
[ 3., 1.],
[ 6., 0.]]), array([[ 4., 4.],
[ 4., 5.],
[ 2., 4.],
[ 7., 3.]]), array([[ 1., 6.],
[ 6., 9.],
[ 2., 1.],
[ 3., 0.]])]
---
[array([[ 5., 4.],
[ 8., 7.],
[ 3., 1.]]), array([[ 6., 0.]]), array([[ 4., 4.],
[ 4., 5.],
[ 2., 4.],
[ 7., 3.],
[ 1., 6.],
[ 6., 9.],
[ 2., 1.],
[ 3., 0.]])]2.16.查找并修改矩阵特定元素
例如下面代码中,x_data是我代码中的一个矩阵,但是矩阵数据中有缺失值是用?表示的,我要做一些数据处理,就需要把?换掉,比如换成0
x_data[x_data == '?'] = 03.创建数组: .array
首先需要创建数组才能对其进行其它操作,通过给array函数传递Python的序列对象创建数组,如果传递的是多层嵌套的序列,将创建多维数组(如c):
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array((5, 6, 7, 8))
c = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [7, 8, 9, 10]])
print (a)
print ('---')
print (b)
print ('---')
print (c)
# 输出 [1 2 3 4]
---
[5 6 7 8]
---
[[ 1 2 3 4]
[ 4 5 6 7]
[ 7 8 9 10]]- 若导入numpy用的是
import numpy命令,那么在创建数组的时候用a = numpy.array([1, 2, 3, 4])的形式 - 若导入numpy用的是
import numpy as np命令,那么用a = np.array([1, 2, 3, 4])
4.查询数据类型: .dtype
# 接上面数据
print (c.dtype)
# 输出 int32关于数据类型:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
4.1.创建时指定元素类型
import numpy as np
a = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [7, 8, 9, 10]])
b = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [7, 8, 9, 10]], dtype='str')
print (a)
print ('---')
print (b)
# 输出 [[ 1 2 3 4]
[ 4 5 6 7]
[ 7 8 9 10]]
---
[['1' '2' '3' '4']
['4' '5' '6' '7']
['7' '8' '9' '10']]4.2.转换数据类型: .astype
# 接上面数据
b = b.astype(int)
print (b)
# 输出 [[ 1 2 3 4]
[ 4 5 6 7]
[ 7 8 9 10]]4.3. array数组的数据类型
bool -- True , False
int -- int16 , int32 , int64
float -- float16 , float32 , float64
string -- string , unicode5.查询矩阵的大小: .shape
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [7, 8, 9, 10]])
print (a.shape)
print ('---')
print (b.shape)
# 输出 (4,)
---
(3, 4)(4, )shape有一个元素即为一维数组,数组中有4个元素
(3, 4)shape有两个元素即为二维数组,数组为3行4列
5.1.通过修改数组的shape属性,在保持数组元素个数不变的情况下,改变数组每个轴的长度。下面的例子将数组b的shape改为(4, 3),从(3, 4)改为(4, 3)并不是对数组进行转置,而只是改变每个轴的大小,数组元素在内存中的位置并没有改变:
b.shape = 4, 3
print (b)
# 输出 [[ 1 2 3]
[ 4 4 5]
[ 6 7 7]
[ 8 9 10]]5.2.当某个轴的元素为-1时,将根据数组元素的个数自动计算该轴的长度,下面程序将数组b的shape改为了(2, 6):
b.shape = 2, -1
print (b)
# 输出 [[ 1 2 3 4 4 5]
[ 6 7 7 8 9 10]]5.3.使用数组的reshape方法,可以创建一个改变了尺寸的新数组,原数组的shape保持不变:
a = np.array((1, 2, 3, 4))
b = a.reshape((2, 2))
b
# 输出 array([[1, 2],
[3, 4]])6.复制(1): =
a和b共享数据存储内存区域,因此修改其中任意一个数组的元素都会同时修改另外一个数组或矩阵的内容:
a[2] = 100 # 将数组a的第3个元素改为100,数组d中的2即第三个元素也发生了改变
b
# 输出 array([[1, 2],
[100, 4]])import numpy as np
a = np.arange(12)
b = a
print (a)
print (b)
print (b is a) # 判断b是a?
# 输出 [ 0 1 2 3 4 5 6 7 8 9 10 11]
[ 0 1 2 3 4 5 6 7 8 9 10 11]
True
b.shape = 3, 4
print (a.shape)
# 输出 (3, 4)
print (id(a))
print (id(b))
# 输出 2239367199840
22393671998407.复制(2)–浅复制: .view()
# The view method creates a new array object that looks at the same data.
import numpy as np
a = np.arange(12)
b = a.view() # b是新创建出来的数组,但是b和a共享数据
b is a # 判断b是a?
# 输出 False
print (b)
# 输出 [ 0 1 2 3 4 5 6 7 8 9 10 11]
b.shape = 2, 6 # 改变b的shape,a的shape不会受影响
print (a.shape)
print (b)
# 输出 (12,)
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
b[0, 4] = 1234 # 改变b第1行第5列元素为1234,a对应位置元素受到影响
print (b)
# 输出 [[ 0 1 2 3 1234 5]
[ 6 7 8 9 10 11]]
print (a)
# 输出 [ 0 1 2 3 1234 5 6 7 8 9 10 11]8.复制(3)–深复制: .copy()
# The copy method makes a complete copy of the array and its data.
import numpy as np
a = np.arange(12)
a.shape = 3, 4
a[1, 0] = 1234
c = a.copy()
c is a
c[0, 0] = 9999 # 改变c元素的值,不会影响a的元素
print (c)
print (a)
# 输出 [[9999 1 2 3]
[1234 5 6 7]
[ 8 9 10 11]]
[[ 0 1 2 3]
[1234 5 6 7]
[ 8 9 10 11]]9.查询维度: .ndim
import numpy as np
a = np.array([[5, 10, 15],
[20, 25, 30],
[35, 40, 45]])
a.ndim
# 输出 210.查询元素个数: .size
import numpy as np
a = np.array([[5, 10, 15],
[20, 25, 30],
[35, 40, 45]])
a.size
# 输出 911.创建0矩阵: .zeros
np.zeros((3, 4)) # 创建3行4列的0矩阵
np.zeros((3, 4), dtype=np.str) # 可以在创建的时候指定数据类型12.创建1矩阵: .ones
np.noes((3, 4)) # 创建3行4列的1矩阵13.区间内按等差创建矩阵: .arange
np.arange(10, 30, 5) # 10开始到30,没加5生成一个元素
# 输出array([10, 15, 20, 25])
# 可以通过修改shape属性改变维度,参考上文
np.arange(0, 2, 0.3) # 0开始到2,没加0.3生成一个元素
# 输出array([0, 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
np.arange(12).reshape(3, 4) # 从0开始每加1共生成12个元素,并通过reshape设定矩阵大小为3行4列
# 输出array([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]])
np.random.random((2, 3)) # 生成2行3列矩阵,元素为0-1之间的随机值14.区间内按元素个数取值: .linspace
from numpy import pi
np.linspace(0, 2*pi, 100) # 0到2*pi,取100个值15.利用==判断数组或矩阵中是否存在某个值
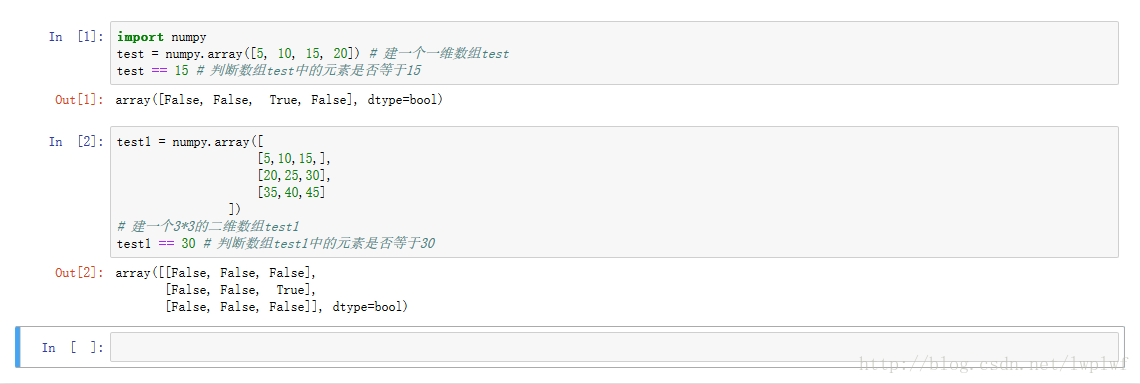
将判断结果赋给某个变量
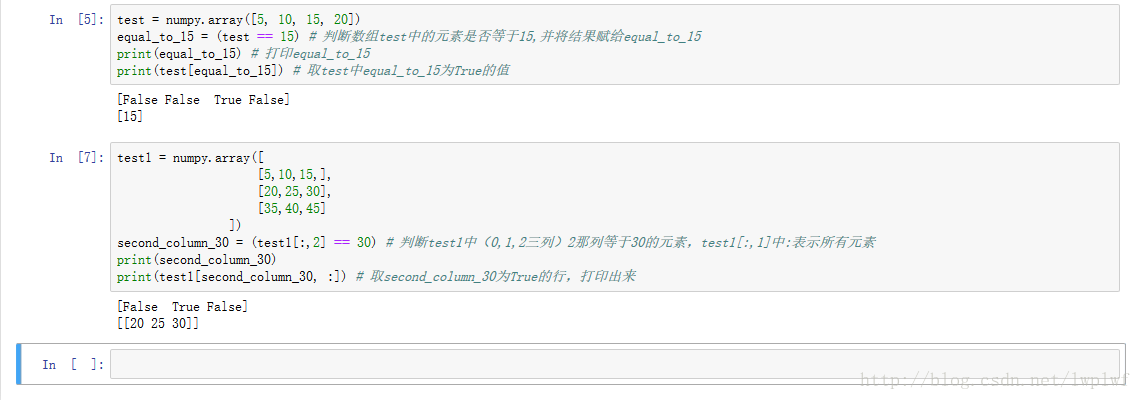
一次判断多个条件
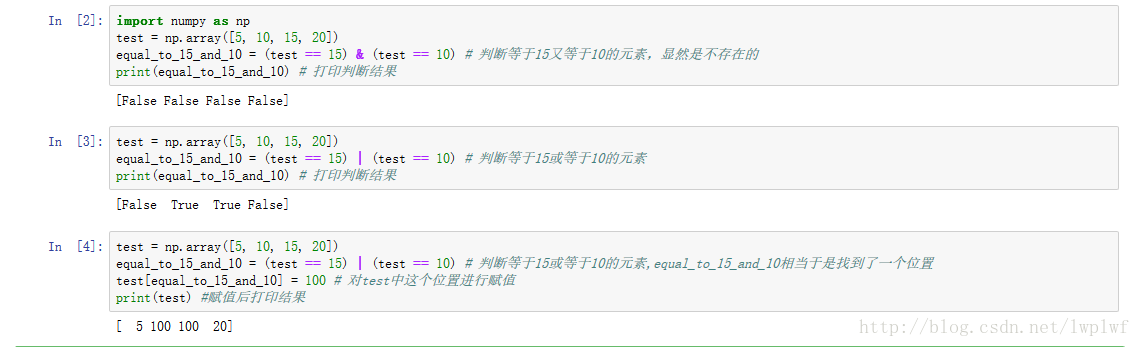
16.numpy tolist() 将数组或者矩阵转换成列表
对于矩阵来说情况也是一样的
3、import matplotlib.pyplot
pyplot介绍
matplotlib.pyplot是一个有命令风格的函数集合,它看起来和MATLAB很相似。每一个pyplot函数都使一副图像做出些许改变,例如创建一幅图,在图中创建一个绘图区域,在绘图区域中添加一条线等等。在matplotlib.pyplot中,各种状态通过函数调用保存起来,以便于可以随时跟踪像当前图像和绘图区域这样的东西。绘图函数是直接作用于当前axes(matplotlib中的专有名词,图形中组成部分,不是数学中的坐标系。)
举一个简单的例子:
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.ylabel('some numbers')
plt.show()运行结果
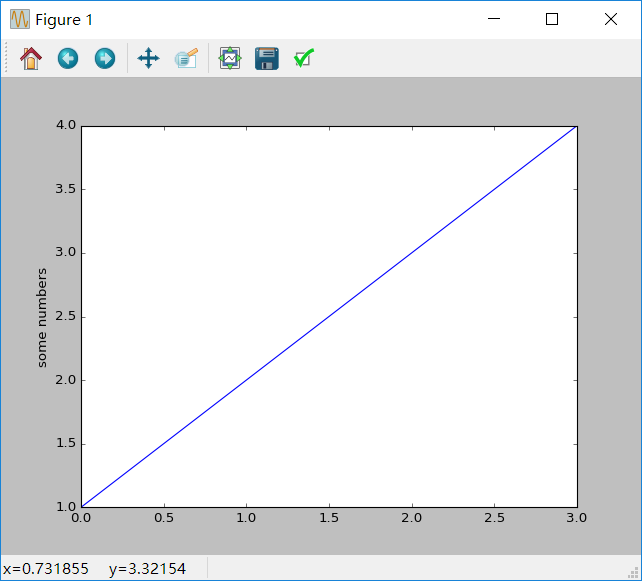
你可能会很疑惑X和Y轴为什么是0~3和1~4。原因是这样的,这里我们只是为plot()命令提供 了一个list或者是array,matplotlib就会假设这个序列是Y轴上的取值,并且会自动为你生成X轴上的值。因为python中的范围是从0开始的,因此X轴就是从0开始,长度与Y的长度相同,也就是[0,1,2,3]。
plot()是一个灵活的命令,它的参数可以是任意数量,比如:
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])这表示的是(x,y)对,(1,1)(2,4)(3,9)(4,16)。这里有第三个可选参数,它是字符串格式的,表示颜色和线的类型。该字符串格式中的字母和符号来自于MATLAB,它是颜色字符串和线的类型字符串的组合。默认情况下,该字符串参数是’b-‘,表示蓝色的实线。
举一个使用红色圆圈绘制上述点集的例子:
import matplotlib.pyplot as plt
plt.plot([1,2,3,4], [1,4,9,16], 'ro')
plt.axis([0, 6, 0, 20])
plt.show()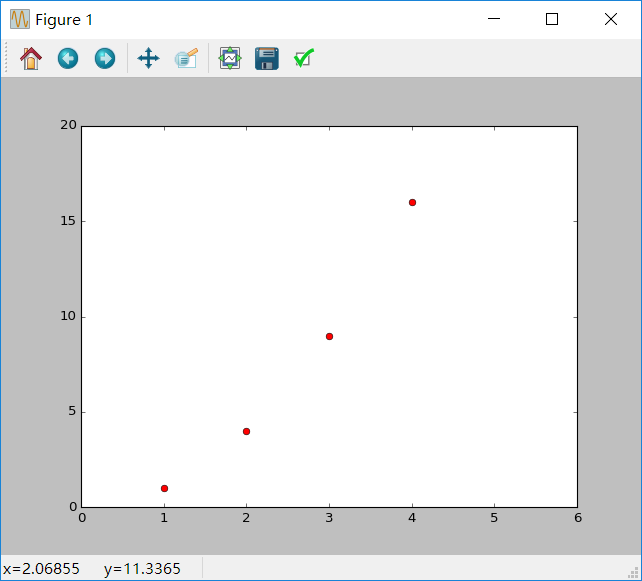
可以查看plot()的文档,那里有完整的关于线的类型的说明。axis()命令可以方便的获取和设置XY轴的一些属性。
如果matplotlib仅限于使用上面那种list,那么它将显得毫无用处。通常,我们都是使用numpy数组,实际上,所有的序列都将被在内部被转化成numpy数字。下面的例子是使用一个命令用几种不同风格的线绘制一个数组:
import numpy as np
import matplotlib.pyplot as plt
# 0到5之间每隔0.2取一个数
t = np.arange(0., 5., 0.2)
# 红色的破折号,蓝色的方块,绿色的三角形
plt.plot(t, t, 'r--', t, t**2, 'bs', t, t**3, 'g^')
plt.show()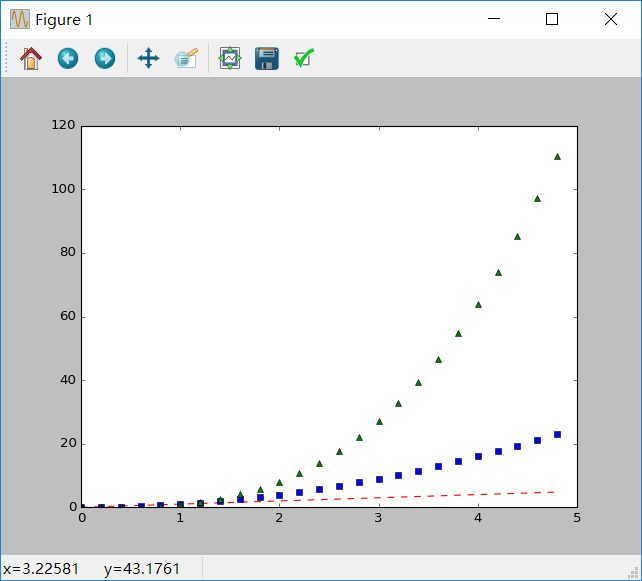
控制线的属性
线有许多属性可以设置:线宽、线的形状,平滑等等。这里有一些设置线属性的方法:- 使用关键字参数
plt.plot(x,y,linewidth=2.0)- 1
- 对线对象(Line2D)使用set_方法,plot()会返回一个线对象的列表,比如line1, line2 = plot(x1, y1, x2, y2)。下面的代码我们将假设我们只有一条线,即返回的线对象列表的长度为1。
line, = plt.plot(x, y, '-') line.set_antialiased(False) # 关闭平滑- 使用setp()命令。 下面的例子使用的是MATLAB风格的命令去设置一个线的列表的多个属性。setp()可以作用于一个列表对象或者是一个单一的对象。你可以使用python风格的关键字参数或者是MATLAB风格的string/value对为参数:
lines = plt.plot(x1, y1, x2, y2) # 使用关键字 plt.setp(lines, color='r', linewidth=2.0) # 或者是MATLAB风格的string/value对 plt.setp(lines, 'color', 'r', 'linewidth', 2.0)这是一些Line2D的属性和取值:
工作在多图形(figures)和多坐标系(axes)
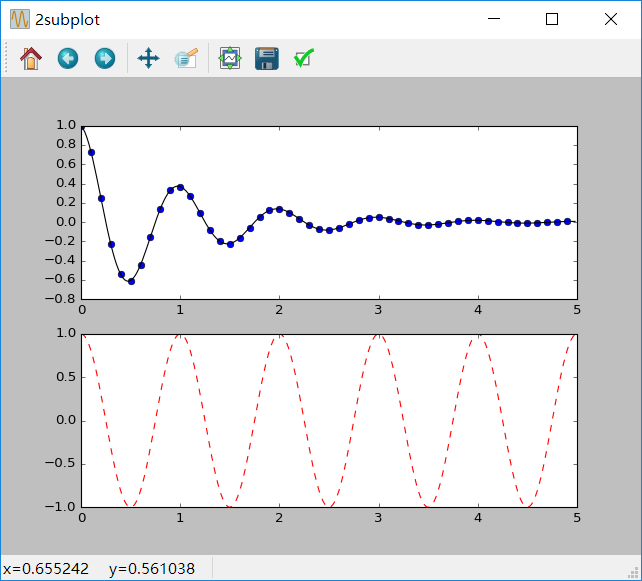
MATLAB和pyplot都有当前图形(figure)和当前坐标系(axes)的概念。所有的绘图命令都是应用于当前坐标系的。gca()和gcf()(get current axes/figures)分别获取当前axes和figures的对象。通常,你不用担心这些,因为他们都在幕后被保存了,下面是一个例子,创建了两个子绘图区域(subplot):import numpy as np import matplotlib.pyplot as plt def f(t): return np.exp(-t) * np.cos(2*np.pi*t) t1 = np.arange(0.0, 5.0, 0.1) t2 = np.arange(0.0, 5.0, 0.02) plt.figure("2subplot") plt.subplot(211) plt.plot(t1, f(t1), 'bo', t2, f(t2), 'k') plt.subplot(212) plt.plot(t2, np.cos(2*np.pi*t2), 'r--') plt.show()figure()命令在这儿可以不写,因为figure(1)将会被默认执行,同样,subplot(111)也是默认被执行的。subplot()中的参数分别指定了numrows、numcols、fignum,其中fignum的取值范围为1到numrows*numcols,分别表示的是将绘图区域划分为numrows行和numcols列个子绘图区域,fignum为当前子图的编号。编号是从1开始,一行一行由左向右编号的。其实subplot中的参数【111】本应写作【1,1,1】,但是如果这三个参数都小于10(其实就是第三个参数小于10)就可以省略逗号。你可以创建任意数量的子图(subplots)和坐标系(axes)。如果你想手动放置一个axes,也就是它不再是一个矩形方格,你就可以使用命令axes(),它可以让坐标系位于任何位置,axes([left,bottom,width,height]),其中所有的值都是0到1(axes([0.3,0.4,0.2,0.3])表示的是该坐标系位于figure的(0.3,0.4)处,其宽度和长度分别为figure横坐标和纵坐标总长的0.2和0.3)。其实subplot和axes的区别就在于axes大小和位置更加随意。
你可以创建多个figure,通过调用figure(),其参数为figure的编号。当然每个figure可以包含多个subplot或者是多个axes。例子:import matplotlib.pyplot as plt plt.figure(1) # 编号为1的figure plt.subplot(211) # figure1中的第一个子图 plt.plot([1, 2, 3]) plt.subplot(212) # figure1中的第二个子图 plt.plot([4, 5, 6]) plt.figure(2) # figure2 plt.plot([4, 5, 6]) # 默认使用subplot(111),此时figure2为当 # 前figure plt.figure(1) # 设置figure1为当前figure; # 但是subplot(212)为当前子图 plt.subplot(211) # 使subplot(211)为当前子图 plt.title('Easy as 1, 2, 3') # 对subplot(211)命名我们可以使用clf()和cla()(clear current figure/axes)清除当前figure和当前axes。
如果你创建了许多figures,你需要注意一件事:figure的内存直到显示调用close()函数才会被完全释放,否则它并没有被全部释放。如果只是删掉对figure的引用,或者是通过关闭window进程管理器关闭该figure,这都是不完全删除figure的,因为pyplot在内部维持了一个引用,直到close()被调用。文字
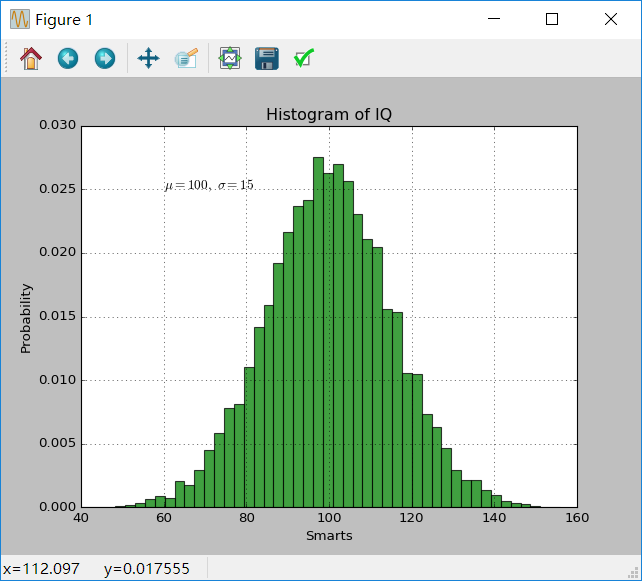
text()命令可以被用来在任何位置添加文字,xlabel()、ylabel()、title()被用来在指定位置添加文字。import numpy as np import matplotlib.pyplot as plt mu, sigma = 100, 15 x = mu + sigma * np.random.randn(10000) # 直方图 n, bins, patches = plt.hist(x, 50, normed=1, facecolor='g', alpha=0.75) plt.xlabel('Smarts') plt.ylabel('Probability') plt.title('Histogram of IQ') plt.text(60, .025, r'$\mu=100,\ \sigma=15$') plt.axis([40, 160, 0, 0.03]) plt.grid(True) plt.show()
所有text()命令返回一个matplotlib.text.Text实例,像上面的线一样,可以通过关键字参数在text()定制文本样式,也可以通过setp()来定制文字的样式:t = plt.xlabel('my data', fontsize=14, color='red') setp(t,color='blue')- 1
- 2
- 在文本中使用数学表达式
matplotlib接受任何TeX方程表达式,比如,你可以写成用”$”符号包裹的TeX表达式:
plt.title(r'$\sigma_i=15$')这里的”r”非常重要,它表示后面的字符串是一个纯粹的字符串,不会将后面的反斜杠当作转义字符。matplotlib内置有TeX表达式解释器和排版引擎,和自带的数学字体。因此你可以不用安装TeX就能使用数学表达式,如果你安装了LaTeX和dvipng,你也可以使用LaTex排版你的文字并且直接输出到figures或者是保存。
- 注释文本
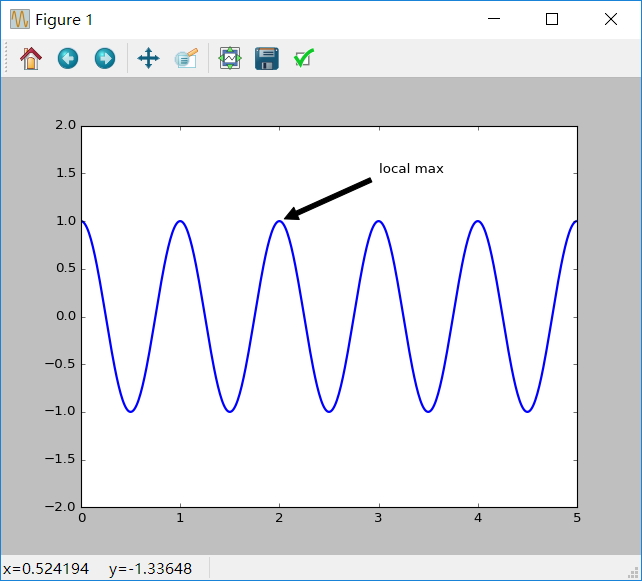
使用text()命令可以在Axes中任意位置放置文本,一个普遍的文本用法是对一些特性进行注释,annotate()方法让添加注释变得很容易。对于注释有两点需要注意:需要被注释的地方,使用xy参数来指出,还有就是注释文本所放置的位置,使用参数xytext来指定位置,这两个参数都使(x,y)元组:
import numpy as np import matplotlib.pyplot as plt ax = plt.subplot(111) t = np.arange(0.0, 5.0, 0.01) s = np.cos(2*np.pi*t) line, = plt.plot(t, s, lw=2) plt.annotate('local max', xy=(2, 1), xytext=(3, 1.5), arrowprops=dict(facecolor='black', shrink=0.05), ) plt.ylim(-2,2) plt.show()
这里的xy和xytext所使用的坐标是根据XY轴的刻度的坐标,称为data coordinates。当然也可以使用其他坐标系统,具体参考官方文档。对数和其他非线性坐标轴(axis)
matplotlib.pylot不仅仅提供了线性的坐标,还提供了对数(logarithmic)和分对数(logit)坐标。当数据的维度跨越许多数量级时,这种坐标就很有用,改变坐标轴的刻度很容易:plt.xscale(‘log’)下面是一个例子,对于同样的数据,在Y轴使用不同刻度下的曲线图:
import numpy as np import matplotlib.pyplot as plt # 在区间[0,1]制造一些数据 # np.random.normal为高斯分布 y = np.random.normal(loc=0.5, scale=0.4, size=1000) y = y[(y > 0) & (y < 1)] y.sort() x = np.arange(len(y)) # 创建一个窗口 plt.figure(1) # 线性 plt.subplot(221) plt.plot(x, y) plt.yscale('linear') plt.title('linear') plt.grid(True) # 对数 plt.subplot(222) plt.plot(x, y) plt.yscale('log') plt.title('log') plt.grid(True) # symmetric log plt.subplot(223) plt.plot(x, y - y.mean()) plt.yscale('symlog', linthreshy=0.05) plt.title('symlog') plt.grid(True) # logit plt.subplot(224) plt.plot(x, y) plt.yscale('logit') plt.title('logit') plt.grid(True) plt.show()
4、import pandas as pd
Pandas
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
>>> from pandas import Series, DataFrame
>>> import pandas as pd
A.pandas
| 函数 | 说明 |
pd.isnull(series) pd.notnull(series) |
判断是否为空(NaN) 判断是否不为空(not NaN) |
2.2.A.1 pandas常用函数
B.Series
Series可以运用ndarray或字典的几乎所有索引操作和函数,融合了字典和ndarray的优点。| 属性 | 说明 |
| values | 获取数组 |
| index | 获取索引 |
| name | values的name |
| index.name | 索引的name |
| 函数 | 说明 |
| Series([x,y,...])Series({'a':x,'b':y,...}, index=param1) | 生成一个Series |
| Series.copy() | 复制一个Series |
Series.reindex([x,y,...], fill_value=NaN) Series.reindex([x,y,...], method=NaN) Series.reindex(columns=[x,y,...]) |
重返回一个适应新索引的新对象,将缺失值填充为fill_value 返回适应新索引的新对象,填充方式为method 对列进行重新索引 |
| Series.drop(index) | 丢弃指定项 |
| Series.map(f) | 应用元素级函数 |
| 排序函数 | 说明 |
| Series.sort_index(ascending=True) | 根据索引返回已排序的新对象 |
| Series.order(ascending=True) | 根据值返回已排序的对象,NaN值在末尾 |
| Series.rank(method='average', ascending=True, axis=0) | 为各组分配一个平均排名 |
df.argmax() df.argmin() |
返回含有最大值的索引位置 返回含有最小值的索引位置 |
2.2.B.2 Series常用函数
reindex的method选项:C.DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
DataFrame可以通过类似字典的方式或者.columnname的方式将列获取为一个Series。行也可以通过位置或名称的方式进行获取。
为不存在的列赋值会创建新列。
>>> del frame['xxx'] # 删除列
| 属性 | 说明 |
| values | DataFrame的值 |
| index | 行索引 |
| index.name | 行索引的名字 |
| columns | 列索引 |
| columns.name | 列索引的名字 |
| ix | 返回行的DataFrame |
| ix[[x,y,...], [x,y,...]] | 对行重新索引,然后对列重新索引 |
| T | frame行列转置 |
2.2.C.1 DataFrame常用属性
| 函数 | 说明 |
DataFrame(dict, columns=dict.index, index=[dict.columnnum]) DataFrame(二维ndarray) DataFrame(由数组、列表或元组组成的字典) DataFrame(NumPy的结构化/记录数组) DataFrame(由Series组成的字典) DataFrame(由字典组成的字典) DataFrame(字典或Series的列表) DataFrame(由列表或元组组成的列表) DataFrame(DataFrame) DataFrame(NumPy的MaskedArray) |
构建DataFrame 数据矩阵,还可以传入行标和列标 每个序列会变成DataFrame的一列。所有序列的长度必须相同 类似于“由数组组成的字典” 每个Series会成为一列。如果没有显式制定索引,则各Series的索引会被合并成结果的行索引 各内层字典会成为一列。键会被合并成结果的行索引。 各项将会成为DataFrame的一行。索引的并集会成为DataFrame的列标。 类似于二维ndarray 沿用DataFrame 类似于二维ndarray,但掩码结果会变成NA/缺失值
|
df.reindex([x,y,...], fill_value=NaN, limit) df.reindex([x,y,...], method=NaN) df.reindex([x,y,...], columns=[x,y,...],copy=True) |
返回一个适应新索引的新对象,将缺失值填充为fill_value,最大填充量为limit 返回适应新索引的新对象,填充方式为method 同时对行和列进行重新索引,默认复制新对象。 |
| df.drop(index, axis=0) | 丢弃指定轴上的指定项。 |
| 排序函数 | 说明 |
df.sort_index(axis=0, ascending=True) df.sort_index(by=[a,b,...]) |
根据索引排序 |
| 汇总统计函数 | 说明 |
| df.count() | 非NaN的数量 |
| df.describe() | 一次性产生多个汇总统计 |
df.min() df.min() |
最小值 最大值 |
df.idxmax(axis=0, skipna=True) df.idxmin(axis=0, skipna=True) |
返回含有最大值的index的Series 返回含有最小值的index的Series |
| df.quantile(axis=0) | 计算样本的分位数 |
df.sum(axis=0, skipna=True, level=NaN) df.mean(axis=0, skipna=True, level=NaN) df.median(axis=0, skipna=True, level=NaN) df.mad(axis=0, skipna=True, level=NaN) df.var(axis=0, skipna=True, level=NaN) df.std(axis=0, skipna=True, level=NaN) df.skew(axis=0, skipna=True, level=NaN) df.kurt(axis=0, skipna=True, level=NaN) df.cumsum(axis=0, skipna=True, level=NaN) df.cummin(axis=0, skipna=True, level=NaN) df.cummax(axis=0, skipna=True, level=NaN) df.cumprod(axis=0, skipna=True, level=NaN) df.diff(axis=0) df.pct_change(axis=0) |
返回一个含有求和小计的Series 返回一个含有平均值的Series 返回一个含有算术中位数的Series 返回一个根据平均值计算平均绝对离差的Series 返回一个方差的Series 返回一个标准差的Series 返回样本值的偏度(三阶距) 返回样本值的峰度(四阶距) 返回样本的累计和 返回样本的累计最大值 返回样本的累计最小值 返回样本的累计积 返回样本的一阶差分 返回样本的百分比数变化 |
| 计算函数 | 说明 |
df.add(df2, fill_value=NaN, axist=1) df.sub(df2, fill_value=NaN, axist=1) df.div(df2, fill_value=NaN, axist=1) df.mul(df2, fill_value=NaN, axist=1) |
元素级相加,对齐时找不到元素默认用fill_value 元素级相减,对齐时找不到元素默认用fill_value 元素级相除,对齐时找不到元素默认用fill_value 元素级相乘,对齐时找不到元素默认用fill_value |
| df.apply(f, axis=0) | 将f函数应用到由各行各列所形成的一维数组上 |
| df.applymap(f) | 将f函数应用到各个元素上 |
| df.cumsum(axis=0, skipna=True) | 累加,返回累加后的dataframe |
2.2.C.2 Dataframe常用函数
| 索引方式 | 说明 |
| df[val] | 选取DataFrame的单个列或一组列 |
| df.ix[val] | 选取Dataframe的单个行或一组行 |
| df.ix[:,val] | 选取单个列或列子集 |
| df.ix[val1,val2] | 将一个或多个轴匹配到新索引 |
| reindex方法 | 将一个或多个轴匹配到新索引 |
| xs方法 | 根据标签选取单行或者单列,返回一个Series |
| icol、irow方法 | 根据整数位置选取单列或单行,并返回一个Series |
| get_value、set_value | 根据行标签和列标签选取单个值 |
2.2.C.3 Dataframe常用索引方式
运算:
默认情况下,Dataframe和Series之间的算术运算会将Series的索引匹配到的Dataframe的列,沿着列一直向下传播。若索引找不到,则会重新索引产生并集。
D.Index
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。Index对象不可修改,从而在多个数据结构之间安全共享。
| 主要的Index对象 | 说明 |
| Index | 最广泛的Index对象,将轴标签表示为一个由Python对象组成的NumPy数组 |
| Int64Index | 针对整数的特殊Index |
| MultiIndex | “层次化”索引对象,表示单个轴上的多层索引。可以看做由元组组成的数组 |
| DatetimeIndex | 存储纳秒级时间戳(用NumPy的Datetime64类型表示) |
| PeriodIndex | 针对Period数据(时间间隔)的特殊Index |
2.2.D.1 主要的Index属性
| 函数 | 说明 |
| Index([x,y,...]) | 创建索引 |
| append(Index) | 连接另一个Index对象,产生一个新的Index |
| diff(Index) | 计算差集,产生一个新的Index |
| intersection(Index) | 计算交集 |
| union(Index) | 计算并集 |
| isin(Index) | 检查是否存在与参数索引中,返回bool型数组 |
| delete(i) | 删除索引i处元素,得到新的Index |
| drop(str) | 删除传入的值,得到新Index |
| insert(i,str) | 将元素插入到索引i处,得到新Index |
| is_monotonic() | 当各元素大于前一个元素时,返回true |
| is_unique() | 当Index没有重复值时,返回true |
| unique() | 计算Index中唯一值的数组 |
2.2.D.2 常用Index函数
5、python中的size,shape,len,count
len():返回对象的长度,注意不是length()函数
len([1,2,3]),返回值为3
len([[1,2,3],[3,4,5]]),返回值为2
count():计算包含对象个数
[1,1,1,2].count(1),返回值为3
‘asddf’.count(‘d’),返回值为2
size()和shape () 是numpy模块中才有的函数
size():计算数组和矩阵所有数据的个数
a = np.array([[1,2,3],[4,5,6]])
np.size(a),返回值为 6
np.size(a,1),返回值为 3
shape ():得到矩阵每维的大小
np. shape (a),返回值为 (2,3)
另外要注意的是,shape和size既可以作为函数,也可以作为ndarray的属性
a.size,返回值为 6,
a.shape,返回值为 (2,3)