在前面的文章中,我们实现了用户微服务、商品微服务和订单微服务之间的远程调用,并且实现了服务调用的负载均衡。
但是,现在系统中存在着一个很明显的问题:那就是如果系统的并发量上来后,系统并没有容错的能力,这可能会导致系统不可用或者直接宕机,所以,我们的系统需要支持容错的能力
1. 并发对系统的影响
当一个系统的架构设计采用微服务架构模式时,会将庞大而复杂的业务拆分成一个个小的微服务,各个微服务之间以接口或者 RPC 的形式进行互相调用。
在调用的过程中,就会涉及到网路的问题,再加上微服务自身的原因,例如很难做到 100% 的高可用等。如果众多微服务当中的某个或某些微服务出现问题,不可用或者宕机了,那么其他微服务调用这些微服务的接口时就会出现延迟。如果此时有大量请求进入系统,就会造成请求任务的大量堆积,甚至会造成整体服务的瘫痪。
2. 压测
2.1 压测说明
为了更加直观的说明当系统没有容错能力时,高并发、大流量场景对于系统的影响,我们在这里模拟一个并发的场景:
在订单微服务 shop-order的 OrderController类中新增一个 concurrentRequest() 方法,源码如下所示:
@GetMapping("/concurrentRequest")
public String concurrentRequest() {
log.info("测试业务在高并发场景下是否存在问题");
return "concurrentRequest";
}
接下来,为了更好的演示效果,我们限制下Tomcat处理请求的最大并发数,在订单微服务shop-order
的resources目录下的application.yml文件中添加如下配置:
server:
port: 8080
tomcat:
max-threads: 20
限制 Tomcat 一次最多只能处理 20 个请求。接下来,我们就使用 JMeter 对
http://localhost:8080/order/submit_order 接口进行压测。
由于订单微服务中没有做任何的容错处理,当对 http://localhost:8080/order/submit_order 接口的请求压力过大时,我们再访问http://localhost:8080/order/concurrentRequest 接口时,会发现http://localhost:8080/order/concurrentRequest 接口会受到并发请求的影响,访问很慢甚至根本访问不到
2.2 压测实战
使用 JMeter 对 http://localhost:8080/order/submit_order 接口进行压测,JMeter 的配置过程如下所示。
1、打开 JMeter 的主界面,如下所示:
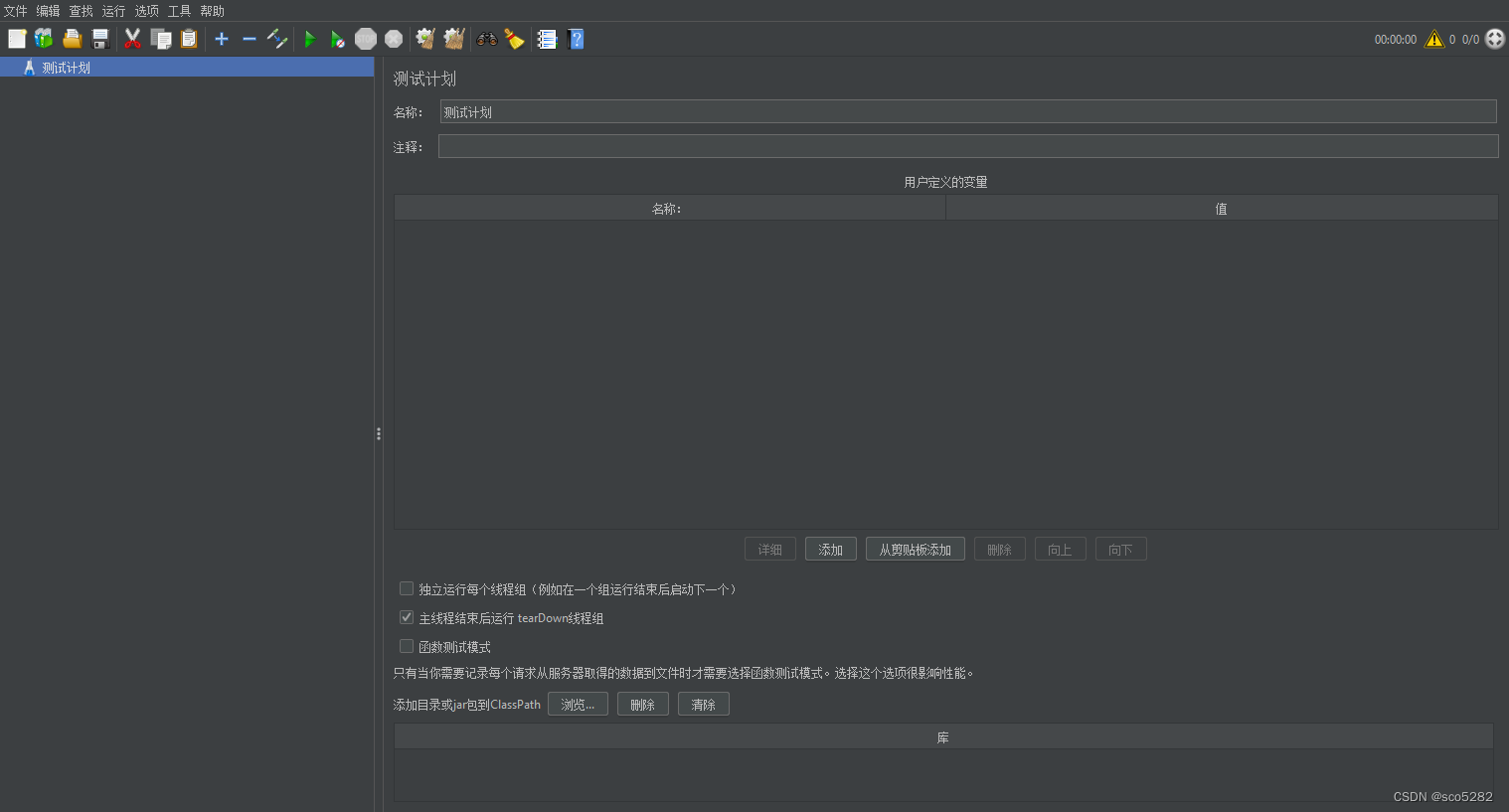
2、在JMeter中右键测试计划添加线程组,如下所示:
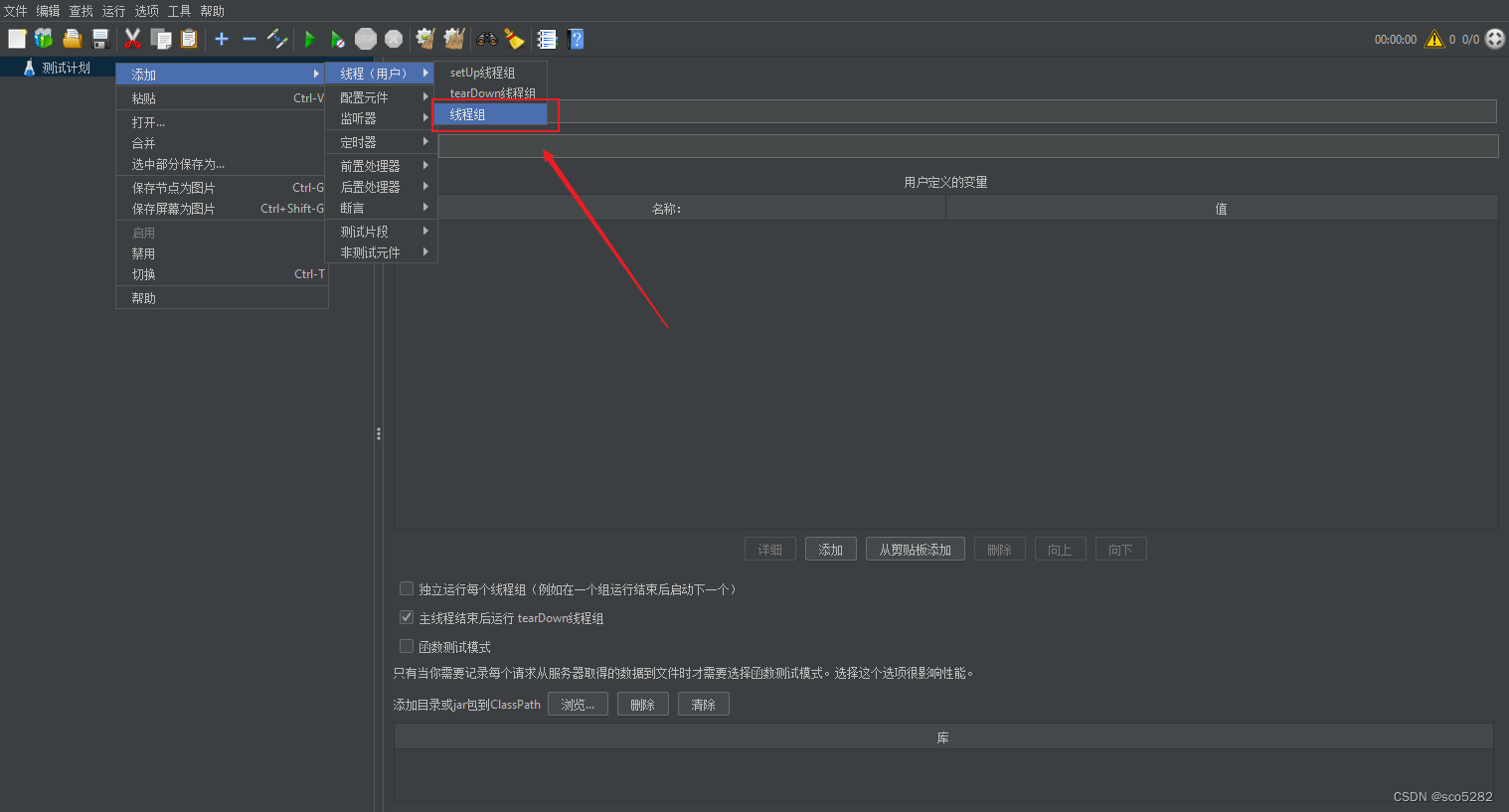
3、在 JMeter 中的线程组中配置并发线程数,如下所示:
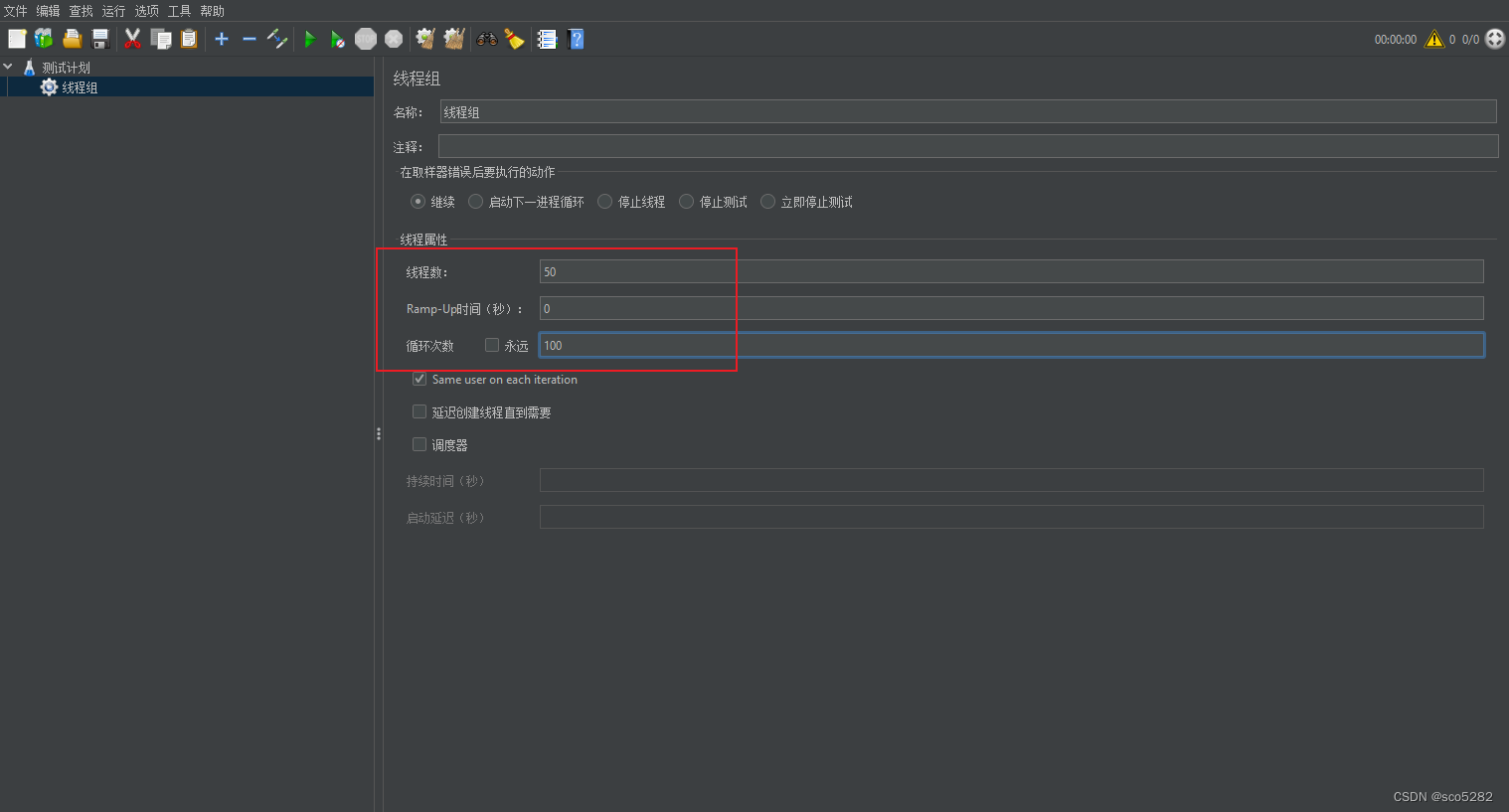
配置信息如下:
- 线程数:50
- Ramp-Up 时间:0
- 循环次数:100
配置信息的意思:表示 JMeter 每次会在同一时刻向系统发送 50 个请求,发送 100 次为止
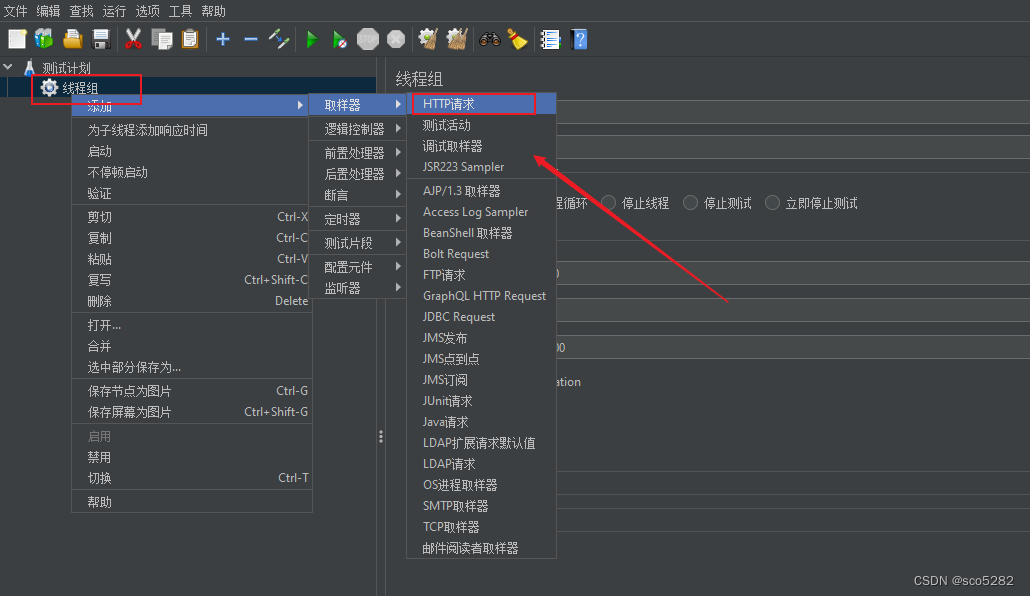
4、在 JMeter 中右键线程组添加 HTTP 请求,如下所示:
5、在 JMeter 中配置 HTTP 请求,如下所示:
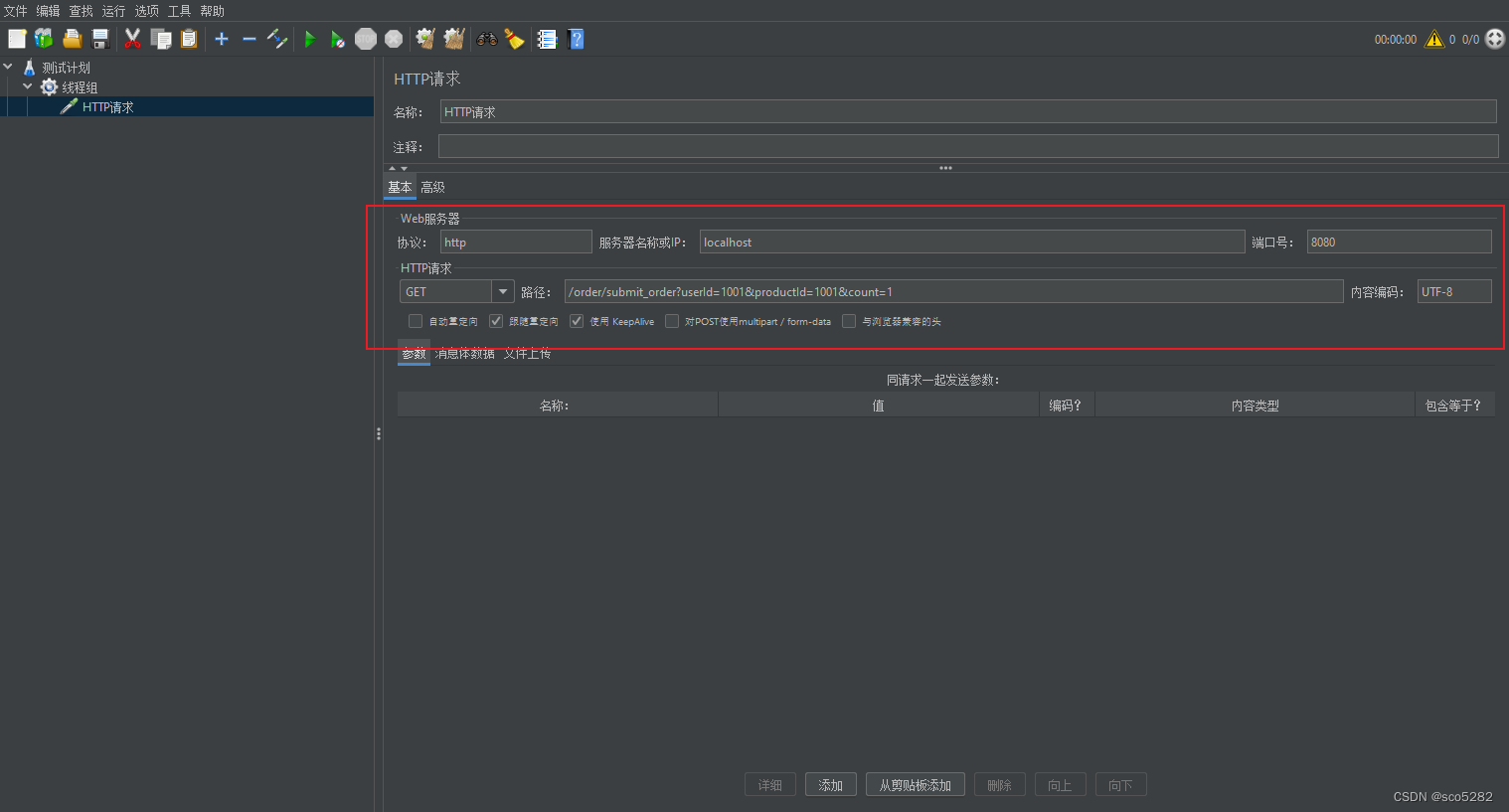
具体配置如下所示:
- 协议:http
- 服务器名称或IP:localhost
- 端口号:8080
- 方法:GET
- 路径:/order/submit_order?userId=1001&productId=1001&count=1
- 内容编码:UTF-8
6、配置好 JMeter 后,点击 JMeter 上的绿色小三角开始压测,如下所示:
点击后会弹出需要保存JMeter脚本的弹出框,根据实际需要点击保存即可。
7、查看结果:右键 HTTP 请求:添加->监听器->察看结果树:
8、正式压测。启动 用户、商品、订单微服务
点击保存后,开始对 http://localhost:8080/order/submit_order 接口进行压测,在压测的过程中会发现订单微服务打印日志时,会比较卡顿,同时在浏览器或其他工具中访问 http://localhost:8080/order/concurrent_request 接口会卡顿,甚至根本访问不到。
说明订单微服务中的某个接口一旦访问的并发量过高,其他接口也会受到影响,进而导致订单微服务整体不可用。为了说明这个问题,我们再来看看服务雪崩是个什么鬼
3. 服务雪崩
系统采用分布式或微服务的架构模式后,由于网络或者服务自身的问题,一般服务是很难做到 100% 高可用的。如果一个服务出现问题,就可能会导致其他的服务级联出现问题,这种故障性问题会在整个系统中不断扩散,进而导致服务不可用,甚至宕机,最终会对整个系统造成灾难性后果
为了最大程度的预防服务雪崩,组成整体系统的各个微服务需要支持服务容错的功能。
4. 服务容错方案
服务容错在一定程度上就是尽最大努力来兼容错误情况的发生,因为在分布式和微服务环境中,不可避免的会出现一些异常情况,我们在设计分布式和微服务系统时,就要考虑到这些异常情况的发生,使得系统具备服务容错能力。
常见的服务错误方案包含:服务限流、服务隔离、服务超时、服务熔断和服务降级等
4.1 服务限流
服务限流就是限制进入系统的流量,以防止进入系统的流量过大而压垮系统。其主要的作用就是保护服务节点或者集群后面的数据节点,防止瞬时流量过大使服务和数据崩溃(如前端缓存大量实效),造成不可用;还可用于平滑请求。
限流算法有两种,一种就是简单的请求总量计数,一种就是时间窗口限流(一般为1s),如令牌桶算法和漏牌桶算法就是时间窗口的限流算法
4.2 服务隔离
服务隔离有点类似于系统的垂直拆分,就按照一定的规则将系统划分成多个服务模块,并且每个服务模块之间是互相独立的,不会存在强依赖的关系。如果某个拆分后的服务发生故障后,能够将故障产生的影响限制在某个具体的服务内,不会向其他服务扩散,自然也就不会对整体服务产生致命的影响。
互联网行业常用的服务隔离方式有:线程池隔离和信号量隔离。
4.3 服务超时
整个系统采用分布式和微服务架构后,系统被拆分成一个个小服务,就会存在服务与服务之间互相调用的现象,从而形成一个个调用链。形成调用链关系的两个服务中,主动调用其他服务接口的服务处于调用链的上游,提供接口供其他服务调用的服务处于调用链的下游。
服务超时就是在上游服务调用下游服务时,设置一个最大响应时间,如果超过这个最大响应时间下游服务还未返回结果,则断开上游服务与下游服务之间的请求连接,释放资源。
4.4 服务熔断
在分布式与微服务系统中,如果下游服务因为访问压力过大导致响应很慢或者一直调用失败时,上游服务为了保证系统的整体可用性,会暂时断开与下游服务的调用连接。这种方式就是熔断。
服务熔断一般情况下会有三种状态:关闭、开启和半熔断。
- 关闭状态:服务一切正常,没有故障时,上游服务调用下游服务时,不会有任何限制。
- 开启状态:上游服务不再调用下游服务的接口,会直接返回上游服务中预定的方法。
- 半熔断状态:处于开启状态时,上游服务会根据一定的规则,尝试恢复对下游服务的调用。此时,上游服务会以有限的流量来调用下游服务,同时,会监控调用的成功率。如果成功率达到预期,则进入关闭状态。如果未达到预期,会重新进入开启状态。
4.5 服务降级
服务降级,说白了就是一种服务托底方案,如果服务无法完成正常的调用流程,就使用默认的托底方案来返回数据。例如,在商品详情页一般都会展示商品的介绍信息,一旦商品详情页系统出现故障无法调用时,会直接获取缓存中的商品介绍信息返回给前端页面
代码地址
代码已经上传至码云,码云地址
其中,数据库文件位于 db 文件夹下。