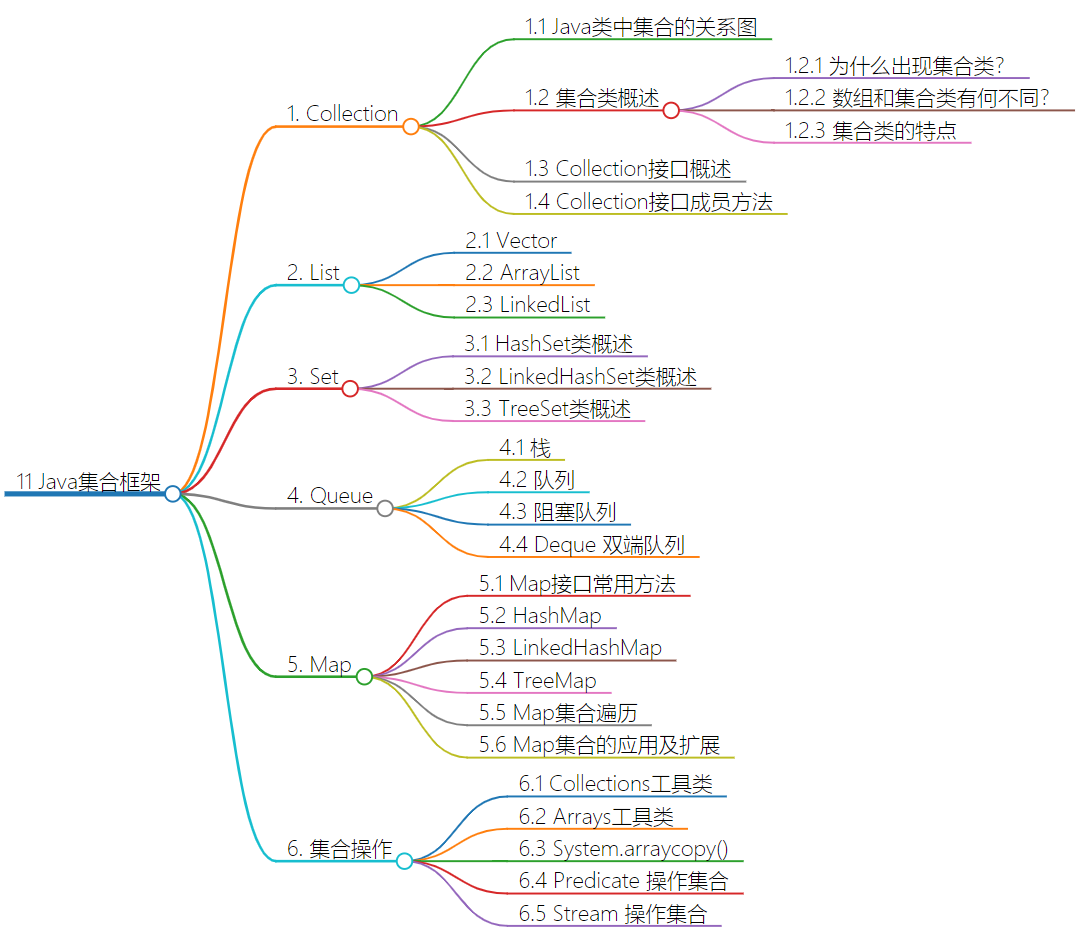
1. Collection
1.1 Java类中集合的关系图


1.2 集合类概述
在程序中可以通过数组来保存多个对象,但在某些情况下开发人员无法预先确定需要保存对象的个数,此时数组将不再适用,因为数组的长度不可变。例如,要保存一个学校的学生信息,由于不停有新生来报道,同时也有学生毕业离开学校,这时学生的数目就很难确定。为了在程序中可以保存这些数目不确定的对象,JDK中提供了一系列特殊的类,这些类可以存储任意类型的对象,并且长度可变,在Java中这些类被统称为集合。集合类都位于java.util包中,在使用时一定要注意导包的问题,否则会出现异常。
1.2.1 为什么出现集合类?
面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,Java就提供了集合类。
1.2.2 数组和集合类有何不同?

1.2.3 集合类的特点
集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。
1.3 Collection接口概述
Collection:单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两个重要的子接口,分别是List和Set。其中,List的特点是元素有序、元素可重复。Set的特点是元素无序,而且不可重复。List接口的主要实现类有ArrayList和LinkedList,Set接口的主要实现类有HashSet和TreeSet。
Collection 层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。

1.4 Collection接口成员方法
集合层次结构中的根接口。Collection表示一组对象,这些对象也称为Collection的元素。一些Collection允许有重复的元素,而另一些则不允许。一些Collection是有序的,而另一些则是无序的。
添加功能
| 方法声明 | 功能描述 |
|---|---|
| add() | 添加元素 |
| addAll() | 添加一个集合的元素 |
删除功能
| 方法声明 | 功能描述 |
|---|---|
| remove() | 删除元素 |
| removeAll() | 删除一个集合的元素 |
| clear() | 清空集合 |
判断功能
| 方法声明 | 功能描述 |
|---|---|
| contains() | 判断集合是否包含指定的元素 |
| containsAll() | 判断一个集合是否包含一个集合的元素 |
| isEmpty() | 判断集合是否为空 |
获取功能
| 方法声明 | 功能描述 |
|---|---|
| size() | 获取集合的长度 |
| retainAll() | 取两个集合的交集 |
其他功能
| 方法声明 | 功能描述 |
|---|---|
| toArray() | 把集合转成数组,可以实现集合的遍历 |
| iterator() | 迭代器,集合的专用遍历方式 |

2. List
有序的 collection(也称为序列/线性表)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。与 set 不同,列表通常允许重复的元素。
List接口是Collection接口的一个子接口,List集合的特性是:有序,可重复,元素有索引,List接口有三个实现类
- ArrayList:底层数据结构是数组,查询快,增删慢,非线程安全,效率高,数据增长为原来的50%
- Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,数据增长为原来的一倍
- LinkedList:底层数据结构是链表,查询慢,增删快,非线程安全,效率高
2.1 Vector
底层数据结构是数组,查询快,增删慢,线程安全,效率低。
Vector类特有功能
- public void addElement(E obj):添加元素
- public E elementAt(int index):根据索引获取元素
- public Enumeration elements():获取所有的元素
2.2 ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
ArrayList 继承了 AbstractList ,并实现了 List 接口。
底层数据结构是数组,查询快,增删慢,线程不安全,效率高。
Java ArrayList 常用方法列表如下:
| 方法声明 | 功能描述 |
|---|---|
| add() | 将元素插入到指定位置的 arraylist 中 |
| addAll() | 添加集合中的所有元素到 arraylist 中 |
| clear() | 删除 arraylist 中的所有元素 |
| clone() | 复制一份 arraylist |
| contains() | 判断元素是否在 arraylist |
| get() | 通过索引值获取 arraylist 中的元素 |
| indexOf() | 返回 arraylist 中元素的索引值 |
| removeAll() | 删除存在于指定集合中的 arraylist 里的所有元素 |
| remove() | 删除 arraylist 里的单个元素 |
| size() | 返回 arraylist 里元素数量 |
| isEmpty() | 判断 arraylist 是否为空 |
| subList() | 截取部分 arraylist 的元素 |
| set() | 替换 arraylist 中指定索引的元素 |
| sort() | 对 arraylist 元素进行排序 |
| toArray() | 将 arraylist 转换为数组 |
| toString() | 将 arraylist 转换为字符串 |
| ensureCapacity() | 设置指定容量大小的 arraylist |
| lastIndexOf() | 返回指定元素在 arraylist 中最后一次出现的位置 |
| retainAll() | 保留 arraylist 中在指定集合中也存在的那些元素 |
| containsAll() | 查看 arraylist 是否包含指定集合中的所有元素 |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数 |
| removeRange() | 删除 arraylist 中指定索引之间存在的元素 |
| replaceAll() | 将给定的操作内容替换掉数组中每一个元素 |
| removeIf() | 删除所有满足特定条件的 arraylist 元素 |
| forEach() | 遍历 arraylist 中每一个元素并执行特定操作 |
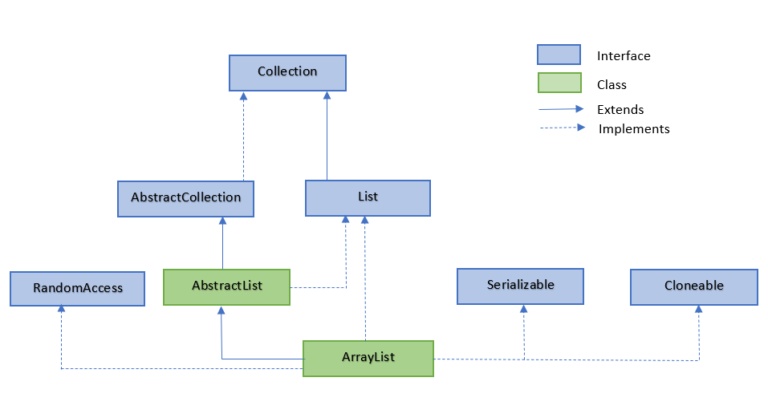
2.3 LinkedList
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
链表可分为单向链表和双向链表。
一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接。

一个双向链表有三个整数值: 数值、向后的节点链接、向前的节点链接。

Java LinkedList(链表) 类似于 ArrayList,是一种常用的数据容器。
与 ArrayList 相比,LinkedList 的增加和删除的操作效率更高,而查找和修改的操作效率较低。
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
LinkedList 继承了 AbstractSequentialList 类。
LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 List 接口,可进行列表的相关操作。
LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。
LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
常用方法
| 方法声明 | 功能描述 |
|---|---|
| public boolean add(E e) | 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public void add(int index, E element) | 向指定位置插入元素。 |
| public boolean addAll(Collection c) | 将一个集合的所有元素添加到链表后面,返回是否成功,成功为 true,失败为 false。 |
| public boolean addAll(int index, Collection c) | 将一个集合的所有元素添加到链表的指定位置后面,返回是否成功,成功为 true,失败为 false。 |
| public void addFirst(E e) | 元素添加到头部。 |
| public void addLast(E e) | 元素添加到尾部。 |
| public boolean offer(E e) | 向链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerFirst(E e) | 头部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerLast(E e) | 尾部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public void clear() | 清空链表。 |
| public E removeFirst() | 删除并返回第一个元素。 |
| public E removeLast() | 删除并返回最后一个元素。 |
| public boolean remove(Object o) | 删除某一元素,返回是否成功,成功为 true,失败为 false。 |
| public E remove(int index) | 删除指定位置的元素。 |
| public E poll() | 删除并返回第一个元素。 |
| public E remove() | 删除并返回第一个元素。 |
| public boolean contains(Object o) | 判断是否含有某一元素。 |
| public E get(int index) | 返回指定位置的元素。 |
| public E getFirst() | 返回第一个元素。 |
| public E getLast() | 返回最后一个元素。 |
| public int indexOf(Object o) | 查找指定元素从前往后第一次出现的索引。 |
| public int lastIndexOf(Object o) | 查找指定元素最后一次出现的索引。 |
| public E peek() | 返回第一个元素。 |
| public E element() | 返回第一个元素。 |
| public E peekFirst() | 返回头部元素。 |
| public E peekLast() | 返回尾部元素。 |
| public E set(int index, E element) | 设置指定位置的元素。 |
| public Object clone() | 克隆该列表。 |
| public Iterator descendingIterator() | 返回倒序迭代器。 |
| public int size() | 返回链表元素个数。 |
| public ListIterator listIterator(int index) | 返回从指定位置开始到末尾的迭代器。 |
| public Object[] toArray() | 返回一个由链表元素组成的数组。 |
| public T[] toArray(T[] a) | 返回一个由链表元素转换类型而成的数组。 |
代码示例:使用LinkedList来模拟一个栈数据结构
package cn.itcast;
import java.util.LinkedList;
/*
*使用LinkedList模拟栈数据结构的集合,并测试
*1、栈的特点先进后出
*2、 LinkedList的特有添加功能addFirst()
*/
class MyStack {
private LinkedList link;
public MyStack() {
link = new LinkedList();
}
public void add(Object obj) {
// 将指定元素插入此列表的开头
link.addFirst(obj);
}
public Object get() {
// 移除并返回此列表的第一个元素。
// return link.getFirst();
return link.removeFirst();
}
public boolean isEmpty() {
return link.isEmpty();
}
}
/*
* MyStack的测试
*/
public class MyStackDemo {
public static void main(String[] args) {
// 创建集合对象
MyStack ms = new MyStack();
// 添加元素
ms.add("hello");
ms.add("world");
ms.add("java");
ms.add("android");
ms.add("javase");
while (!ms.isEmpty()) {
System.out.println(ms.get());
}
}
}
3. Set
一个不包含重复元素的 collection,无序。
哈希表确定元素是否相同
1、 判断的是两个元素的哈希值是否相同。
如果相同,再判断两个对象的内容是否相同。
2、 判断哈希值相同,其实判断的是对象的HashCode方法。判断内容相同,用的是equals方法。
3.1 HashSet类概述

- 不保证 set 的迭代顺序,特别是它不保证该顺序恒久不变。
- HashSet如何保证元素唯一性
- 底层数据结构是哈希表(元素是链表的数组)
- 哈希表依赖于哈希值存储
- 添加功能底层依赖两个方法:int hashCode()、boolean equals(Object obj)
HashSet集合之所以能确保不出现重复的元素,是因为它在存入元素时做了很多工作。当调用HashSet集合的add()方法存入元素时,首先调用当前存入对象的hashCode()方法获得对象的哈希值,然后根据对象的哈希值计算出一个存储位置。如果该位置上没有元素,则直接将元素存入,如果该位置上有元素存在,则会调用equals()方法让当前存入的元素依次和该位置上的元素进行比较,如果返回的结果为false就将该元素存入集合,返回的结果为true则说明有重复元素,就将该元素舍弃。
package cn.itcast;
import java.util.HashSet;
class Dog {
private String name;
private int age;
private String color;
private char sex;
public Dog() {
super();
}
public Dog(String name, int age, String color, char sex) {
super();
this.name = name;
this.age = age;
this.color = color;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((color == null) ? 0 : color.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + sex;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Dog other = (Dog) obj;
if (age != other.age)
return false;
if (color == null) {
if (other.color != null)
return false;
} else if (!color.equals(other.color))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (sex != other.sex)
return false;
return true;
}
}
/*
* HashSet集合存储自定义对象并遍历。如果对象的成员变量值相同即为同一个对象
*
* 注意了: 你使用的是HashSet集合,这个集合的底层是哈希表结构。 而哈希表结构底层依赖:hashCode()和equals()方法。
* 如果你认为对象的成员变量值相同即为同一个对象的话,你就应该重写这两个方法。 如何重写呢?不同担心,自动生成即可。
*/
public class DogDemo {
public static void main(String[] args) {
// 创建集合对象
HashSet<Dog> hs = new HashSet<Dog>();
// 创建狗对象
Dog d1 = new Dog("秦桧", 25, "红色", '男');
Dog d2 = new Dog("高俅", 22, "黑色", '女');
Dog d3 = new Dog("秦桧", 25, "红色", '男');
Dog d4 = new Dog("秦桧", 20, "红色", '女');
Dog d5 = new Dog("魏忠贤", 28, "白色", '男');
Dog d6 = new Dog("李莲英", 23, "黄色", '女');
Dog d7 = new Dog("李莲英", 23, "黄色", '女');
Dog d8 = new Dog("李莲英", 23, "黄色", '男');
// 添加元素
hs.add(d1);
hs.add(d2);
hs.add(d3);
hs.add(d4);
hs.add(d5);
hs.add(d6);
hs.add(d7);
hs.add(d8);
// 遍历
for (Dog d : hs) {
System.out.println(d.getName() + "---" + d.getAge() + "---"
+ d.getColor() + "---" + d.getSex());
}
}
}
3.2 LinkedHashSet类概述
元素有序唯一,由链表保证元素有序,由哈希表保证元素唯一。
3.3 TreeSet类概述
使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。
-
TreeSet是如何保证元素的排序和唯一性
底层数据结构是红黑树(红黑树是一种自平衡的二叉树) -
TreeSet判断元素唯一性的方式
就是根据比较方法的返回结果是否是0,是0,就是相同元素,不存。 -
TreeSet对元素进行排序的方式一
让元素自身具备比较功能,元素就需要实现Comparable接口,覆盖compareTo方法。
如果不要按照对象中具备的自然顺序进行排序。如果对象中不具备自然顺序。怎么办? -
可以使用TreeSet集合第二种排序方式
让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。将该类对象作为参数传递给TreeSet集合的构造函数。
package cn.itcast;
import java.util.Comparator;
import java.util.TreeSet;
class Student {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
class MyComparator implements Comparator<Student> {
public int compare(Student s1, Student s2) {
// int num = this.name.length() - s.name.length();
// this -- s1
// s -- s2
// 姓名长度
int num = s1.getName().length() - s2.getName().length();
// 姓名内容
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
// 年龄
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
}
/*
* 需求:请按照姓名的长度排序
*
* TreeSet集合保证元素排序和唯一性的原理 唯一性:是根据比较的返回是否是0来决定。 排序: A:自然排序(元素具备比较性)
* 让元素所属的类实现自然排序接口 Comparable B:比较器排序(集合具备比较性) 让集合的构造方法接收一个比较器接口的子类对象 Comparator
*/
public class TreeSetDemo {
public static void main(String[] args) {
// 创建集合对象
// TreeSet<Student> ts = new TreeSet<Student>(); //自然排序
// public TreeSet(Comparator comparator) //比较器排序
// TreeSet<Student> ts = new TreeSet<Student>(new MyComparator());
// 如果一个方法的参数是接口,那么真正要的是接口的实现类的对象
// 而匿名内部类就可以实现这个东西
TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() {
public int compare(Student s1, Student s2) {
// 姓名长度
int num = s1.getName().length() - s2.getName().length();
// 姓名内容
int num2 = num == 0 ? s1.getName().compareTo(s2.getName())
: num;
// 年龄
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2;
return num3;
}
});
// 创建元素
Student s1 = new Student("linqingxia", 27);
Student s2 = new Student("zhangguorong", 29);
Student s3 = new Student("wanglihong", 23);
Student s4 = new Student("linqingxia", 27);
Student s5 = new Student("liushishi", 22);
Student s6 = new Student("wuqilong", 40);
Student s7 = new Student("fengqingy", 22);
Student s8 = new Student("linqingxia", 29);
// 添加元素
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
ts.add(s5);
ts.add(s6);
ts.add(s7);
ts.add(s8);
// 遍历
for (Student s : ts) {
System.out.println(s.getName() + "---" + s.getAge());
}
}
}
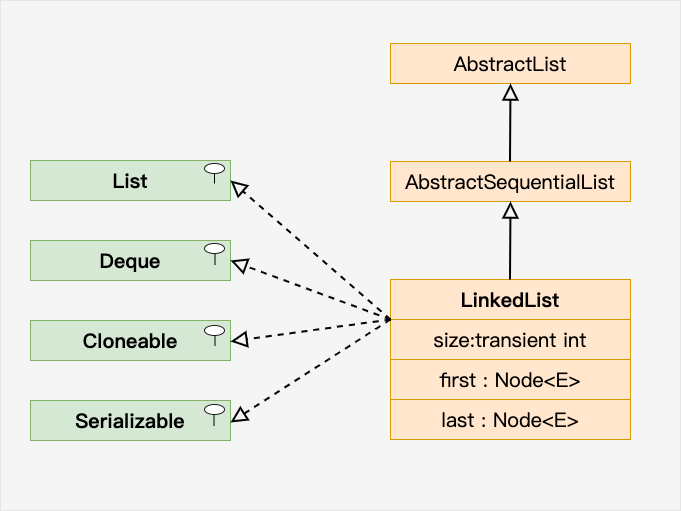
4. Queue
4.1 栈
栈(stack)是一种用于存储数据的简单数据结构。栈一个有序线性表,只能在表的一端(PS:栈顶)执行插人和删除操作。最后插人的元素将被第一个删除。所以,栈也称为后进先出(Last In First Out,LIFO)或先进后出(First In Last Out,FILO)线性表。
栈的实现可以有数组实现的顺序栈和链表结构的链式栈
java预定义的栈实现
public class Stack<E> extends Vector<E>
实现方式为自定义实现的可变长数组,线程安全
Java集合框架中的Stack 继承自Vector
- 由于 Vector 有 4 个构造函数,加上 Stack 本身的一种,也就是说有 5 中创建 Stack 的方法
- 跟 Vector 一样,它是可以由数组实现的栈。
栈的集中主要操作:
- E push(E item) 把项压入堆栈顶部
- synchronized E pop() 移除堆栈顶部的对象,并作为此函数的值返回该对象
- synchronized E peek() 查看堆栈顶部的对象,但不从堆栈中移除它
- boolean empty() 测试堆栈是否为空
- synchronized int search(Object o) 返回对象在堆栈中的位置,以 1 为基数
4.2 队列
- Queue接口
- PriorityQueue 优先队列
- ConcurrentLinkedQueue 支持并发访问的基于链表的队列
- 插入
- add()
- offer()
- 删除
- remove()
- poll()
- 检查
- element()
- peek()
4.3 阻塞队列
阻塞队列可以阻塞,当阻塞队列当队列里面没有值时,会阻塞直到有值输入。输入也一样,当队列满的时候,会阻塞,直到队列有空间。
BlockingQueue
- ArrayBlockingQueue 顺序阻塞队列
- LinkedBlockingQueue 链式阻塞队列
- PriorityBlockingQueue 优先阻塞队列
- SynchronousQueue 同步阻塞队列
- DelayQueue
- BlockingDeque 双端阻塞队列
- LinkedBlockingDeque 基于链表的双端阻塞队列
阻塞队列提供了另外4个非常有用的方法:
- put(E e):用来向队尾存入元素,如果队列满,则等待;
- take():用来从队首取元素,如果队列为空,则等待;
- offer(E e,long timeout, TimeUnit unit):用来向队尾存入元素,如果队列满,则等待一定的时间,当时间期限达到时,如果还没有插入成功,则返回false;否则返回true;
- poll(long timeout, TimeUnit unit):用来从队首取元素。如果队列空,则会等待 timeout 时间后进行一次重试,如果取不到,则返回null;否则返回取得的元素;
4.4 Deque 双端队列
可以当成队列和栈使用
- ArrayDeque
- LinkedBlockingDeque
- LinkedList
| 方法说明 | 功能说明 |
|---|---|
| addFirst() | 队首添加元素 |
| addLast() | 队尾添加元素 |
| offerFirst() | 队首添加元素 |
| offerLast() | 队尾添加元素 |
| removeFirst() | 删除队首元素 |
| removeLast() | 删除队尾元素 |
| pollFirst() | 返回并删除队首元素 |
| pollLast() | 返回并删除队尾元素 |
| getFirst() | 获取队首元素,如果队列为空,则抛异常 |
| getLast() | 获取队尾元素,如果队列为空,则抛异常 |
| peekFirst() | 获取队首元素,如果队列为空,则返回null |
| peekLast() | 获取队尾元素,如果队列为空,则返回null |
5. Map
Map:双列集合类的根接口,用于存储具有键(Key)、值(Value)映射关系的元素,每个元素都包含一对键值,在使用Map集合时可以通过指定的Key找到对应的Value,例如根据一个学生的学号就可以找到对应的学生。Map接口的主要实现类有HashMap和TreeMap。
将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值。其实Map集合中存储的就是键值对。map集合中必须保证键的唯一性。
Map接口和Collection接口的不同
- Map是双列的,Collection是单列的
- Map的键唯一,Collection的子体系Set是唯一的
- Map集合的数据结构值针对键有效,跟值无关
- Collection集合的数据结构是针对元素有效
Map常用的子类:
- Hashtable:内部结构是哈希表,是同步的。不允许null作为键,null作为值。
- Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
- HashMap:内部结构式哈希表,不是同步的。允许null作为键,null作为值。
- TreeMap:内部结构式二叉树,不是同步的。可以对Map结合中的键进行排序。
- HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持。
5.1 Map接口常用方法
| 方法声明 | 功能描述 |
|---|---|
| put(K key, V value) | 有添加和替换功能 |
| putAll(Map m) | 添加一个Map的元素 |
| clear() | 清空集合 |
| remove(Object key) | 根据键删除一个元素 |
| containsKey() | 判断集合是否包含指定的键 |
| containsValue() | 判断集合是否包含指定的值 |
| isEmpty() | 判断集合是否为空 |
| get(Object key) | 根据键获取值 |
| keySet() | 获取所有的键 |
| values() | 获取所有的值 |
| entrySet() | 获取所有的Entry |
| size() | 获取集合元素的个数 |
5.2 HashMap
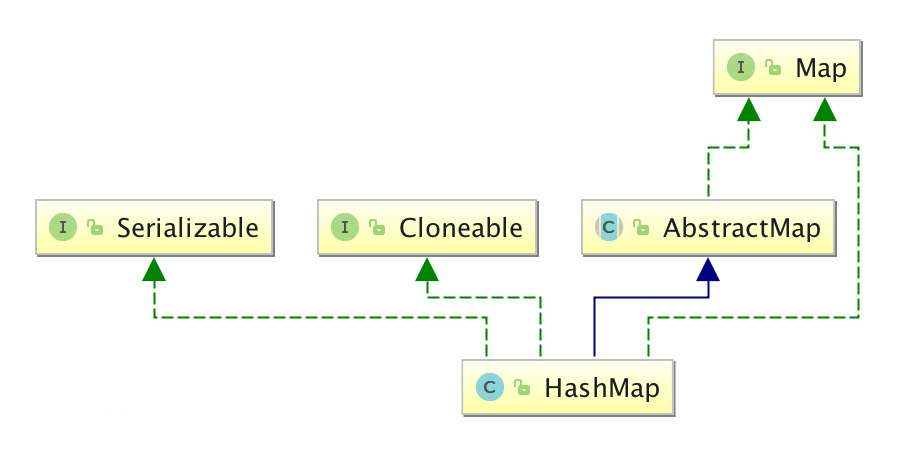
键是哈希表结构,可以保证键的唯一性
5.3 LinkedHashMap
Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。
5.4 TreeMap
键是红黑树结构,可以保证键的排序和唯一性,自然排序,比较器排序。
5.5 Map集合遍历
方式1:根据键找值。获取所有键的集合,遍历键的集合,获取到每一个键,根据键找值。
package cn.itcast;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
* Map集合的遍历。
* Map -- 夫妻对
* 思路:
* A:把所有的丈夫给集中起来。
* B:遍历丈夫的集合,获取得到每一个丈夫。
* C:让丈夫去找自己的妻子。
*
* 转换:
* A:获取所有的键
* B:遍历键的集合,获取得到每一个键
* C:根据键去找值
*/
public class MapDemo {
public static void main(String[] args) {
// 创建集合对象
Map<String, String> map = new HashMap<String, String>();
// 创建元素并添加到集合
map.put("杨过", "小龙女");
map.put("郭靖", "黄蓉");
map.put("杨康", "穆念慈");
map.put("陈玄风", "梅超风");
// 遍历
// 获取所有的键
Set<String> set = map.keySet();
// 遍历键的集合,获取得到每一个键
for (String key : set) {
// 根据键去找值
String value = map.get(key);
System.out.println(key + "---" + value);
}
}
}
方式2:根据键值对对象找键和值。
- 获取所有键值对对象的集合
- 遍历键值对对象的集合,获取到每一个键值对对象
- 根据键值对对象找键和值
package cn.itcast;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/*
* Map集合的遍历。
* Map -- 夫妻对
*
* 思路:
* A:获取所有结婚证的集合
* B:遍历结婚证的集合,得到每一个结婚证
* C:根据结婚证获取丈夫和妻子
*
* 转换:
* A:获取所有键值对对象的集合
* B:遍历键值对对象的集合,得到每一个键值对对象
* C:根据键值对对象获取键和值
*
* 这里面最麻烦的就是键值对对象如何表示呢?
* 看看我们开始的一个方法:
* Set<Map.Entry<K,V>> entrySet():返回的是键值对对象的集合
*/
public class MapDemo {
public static void main(String[] args) {
// 创建集合对象
Map<String, String> map = new HashMap<String, String>();
// 创建元素并添加到集合
map.put("杨过", "小龙女");
map.put("郭靖", "黄蓉");
map.put("杨康", "穆念慈");
map.put("陈玄风", "梅超风");
// 获取所有键值对对象的集合
Set<Map.Entry<String, String>> set = map.entrySet();
// 遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : set) {
// 根据键值对对象获取键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "---" + value);
}
}
}
5.6 Map集合的应用及扩展
package cn.itcast;
import java.util.Scanner;
import java.util.Set;
import java.util.TreeMap;
/*
* 需求 :"aababcabcdabcde",获取字符串中每一个字母出现的次数要求结果:a(5)b(4)c(3)d(2)e(1)
*
* 分析:
* A:定义一个字符串(可以改进为键盘录入)
* B:定义一个TreeMap集合
* 键:Character
* 值:Integer
* C:把字符串转换为字符数组
* D:遍历字符数组,得到每一个字符
* E:拿刚才得到的字符作为键到集合中去找值,看返回值
* 是null:说明该键不存在,就把该字符作为键,1作为值存储
* 不是null:说明该键存在,就把值加1,然后重写存储该键和值
* F:定义字符串缓冲区变量
* G:遍历集合,得到键和值,进行按照要求拼接
* H:把字符串缓冲区转换为字符串输出
*
* 录入:linqingxia
* 结果:result:a(1)g(1)i(3)l(1)n(2)q(1)x(1)
*/
public class TreeMapDemo {
public static void main(String[] args) {
// 定义一个字符串(可以改进为键盘录入)
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String line = sc.nextLine();
// 定义一个TreeMap集合
TreeMap<Character, Integer> tm = new TreeMap<Character, Integer>();
// 把字符串转换为字符数组
char[] chs = line.toCharArray();
// 遍历字符数组,得到每一个字符
for (char ch : chs) {
// 拿刚才得到的字符作为键到集合中去找值,看返回值
Integer i = tm.get(ch);
// 是null:说明该键不存在,就把该字符作为键,1作为值存储
if (i == null) {
tm.put(ch, 1);
} else {
// 不是null:说明该键存在,就把值加1,然后重写存储该键和值
i++;
tm.put(ch, i);
}
}
// 定义字符串缓冲区变量
StringBuilder sb = new StringBuilder();
// 遍历集合,得到键和值,进行按照要求拼接
Set<Character> set = tm.keySet();
for (Character key : set) {
Integer value = tm.get(key);
sb.append(key).append("(").append(value).append(")");
}
// 把字符串缓冲区转换为字符串输出
String result = sb.toString();
System.out.println("result:" + result);
}
}
示例2:在很多项目中,应用比较多的是一对多的映射关系,这就可以通过嵌套的形式将多个映射定义到一个大的集合中,并将大的集合分级处理,形成一个体系。
package cn.itcast;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Set;
class Student {
private String name;
private int age;
public Student() {
super();
}
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
/*
* 黑马程序员
* bj 北京校区
* jc 基础班
* 林青霞 27
* 风清扬 30
* jy 就业班
* 赵雅芝 28
* 武鑫 29
* sh 上海校区
* jc 基础班
* 郭美美 20
* 犀利哥 22
* jy 就业班
* 罗玉凤 21
* 马征 23
* gz 广州校区
* jc 基础班
* 王力宏 30
* 李静磊 32
* jy 就业班
* 郎朗 31
* 柳岩 33
* xa 西安校区
* jc 基础班
* 范冰冰 27
* 刘意 30
* jy 就业班
* 李冰冰 28
* 张志豪 29
*/
public class HashMapDemo {
public static void main(String[] args) {
// 创建大集合
HashMap<String, HashMap<String, ArrayList<Student>>> czbkMap = new HashMap<String, HashMap<String, ArrayList<Student>>>();
// 北京校区数据
HashMap<String, ArrayList<Student>> bjCzbkMap = new HashMap<String, ArrayList<Student>>();
ArrayList<Student> array1 = new ArrayList<Student>();
Student s1 = new Student("林青霞", 27);
Student s2 = new Student("风清扬", 30);
array1.add(s1);
array1.add(s2);
ArrayList<Student> array2 = new ArrayList<Student>();
Student s3 = new Student("赵雅芝", 28);
Student s4 = new Student("武鑫", 29);
array2.add(s3);
array2.add(s4);
bjCzbkMap.put("基础班", array1);
bjCzbkMap.put("就业班", array2);
czbkMap.put("北京校区", bjCzbkMap);
// 西安校区数据
HashMap<String, ArrayList<Student>> xaCzbkMap = new HashMap<String, ArrayList<Student>>();
ArrayList<Student> array3 = new ArrayList<Student>();
Student s5 = new Student("范冰冰", 27);
Student s6 = new Student("刘意", 30);
array3.add(s5);
array3.add(s6);
ArrayList<Student> array4 = new ArrayList<Student>();
Student s7 = new Student("李冰冰", 28);
Student s8 = new Student("张志豪", 29);
array4.add(s7);
array4.add(s8);
xaCzbkMap.put("基础班", array3);
xaCzbkMap.put("就业班", array4);
czbkMap.put("西安校区", xaCzbkMap);
// 遍历集合
Set<String> czbkMapSet = czbkMap.keySet();
for (String czbkMapKey : czbkMapSet) {
System.out.println(czbkMapKey);
HashMap<String, ArrayList<Student>> czbkMapValue = czbkMap
.get(czbkMapKey);
Set<String> czbkMapValueSet = czbkMapValue.keySet();
for (String czbkMapValueKey : czbkMapValueSet) {
System.out.println("\t" + czbkMapValueKey);
ArrayList<Student> czbkMapValueValue = czbkMapValue
.get(czbkMapValueKey);
for (Student s : czbkMapValueValue) {
System.out.println("\t\t" + s.getName() + "---"
+ s.getAge());
}
}
}
}
}
6. 集合操作
6.1 Collections工具类
Collections类概述
针对集合操作 的工具类,里面的方法都是静态的,可以对集合进行排序、二分查找、反转、混排等。
Collection和Collections的区别
Collection:是单列集合的顶层接口,有子接口List和Set。Collections:是针对集合操作的工具类,有对集合进行排序和二分查找等方法
Collections常用方法
public static <T> void sort(List<T> list)
使用sort方法可以根据元素的自然顺序 对指定列表按升序进行排序。列表中的所有元素都必须实现 Comparable 接口。此列表内的所有元素都必须是使用指定比较器可相互比较的
public static <T> int binarySearch(List<?> list,T key)
使用二分搜索法搜索指定列表,以获得指定对象。
public static <T> T max(Collection<?> coll)
根据元素的自然顺序,返回给定 collection 的最大元素。
public static void reverse(List<?> list)
反转指定列表中元素的顺序。
public static void shuffle(List<?> list)
混排算法所做的正好与 sort 相反: 它打乱在一个 List 中可能有的任何排列的踪迹。也就是说,基于随机源的输入重排该 List, 这样的排列具有相同的可能性(假设随机源是公正的)。这个算法在实现一个碰运气的游戏中是非常有用的。例如,它可被用来混排代表一副牌的 Card 对象的一个 List 。另外,在生成测试案例时,它也是十分有用的。
fill(List<? super T> list, T obj)
使用指定元素替换指定列表中的所有元素。
copy(List<? super T> dest, List<? extends T> src)
将所有元素从一个列表复制到另一个列表。用两个参数,一个目标 List 和一个源 List, 将源的元素拷贝到目标,并覆盖它的内容。目标 List 至少与源一样长。如果它更长,则在目标 List 中的剩余元素不受影响。
- 集合线程安全化
List<T> synchronizedList(List<T> list);//返回支持的同步(线程安全的)List集合
Map<K,V> synchronizedMap(Map<K,V> m); //返回支持的同步(线程安全的)Map集合
package cn.itcast_01;
import java.util.Collections;
import java.util.List;
import java.util.ArrayList;
/*
* Collections:是针对集合进行操作的工具类,都是静态方法。
*
* 面试题:
* Collection和Collections的区别?
* Collection:是单列集合的顶层接口,有子接口List和Set。
* Collections:是针对集合操作的工具类,有对集合进行排序和二分查找的方法
*
* 要知道的方法
* public static <T> void sort(List<T> list):排序 默认情况下是自然顺序。
* public static <T> int binarySearch(List<?> list,T key):二分查找
* public static <T> T max(Collection<?> coll):最大值
* public static void reverse(List<?> list):反转
* public static void shuffle(List<?> list):随机置换
*/
public class CollectionsDemo {
public static void main(String[] args) {
// 创建集合对象
List<Integer> list = new ArrayList<Integer>();
// 添加元素
list.add(30);
list.add(20);
list.add(50);
list.add(10);
list.add(40);
System.out.println("list:" + list);
// public static <T> void sort(List<T> list):排序 默认情况下是自然顺序。
// Collections.sort(list);
// System.out.println("list:" + list);
// [10, 20, 30, 40, 50]
// public static <T> int binarySearch(List<?> list,T key):二分查找
// System.out
// .println("binarySearch:" + Collections.binarySearch(list, 30));
// System.out.println("binarySearch:"
// + Collections.binarySearch(list, 300));
// public static <T> T max(Collection<?> coll):最大值
// System.out.println("max:"+Collections.max(list));
// public static void reverse(List<?> list):反转
// Collections.reverse(list);
// System.out.println("list:" + list);
//public static void shuffle(List<?> list):随机置换
Collections.shuffle(list);
System.out.println("list:" + list);
}
}
6.2 Arrays工具类
概述
此类包含用来操作数组(比如排序和搜索)的各种方法。此类还包含一个允许将数组作为列表来查看的静态工厂。
常用方法
Array是Java特有的数组。在你知道所要处理数据元素个数的情况下非常好用。java.util.Arrays 包含了许多处理数据的实用方法:
| 方法声明 | 功能描述 |
|---|---|
| Arrays.asList() | 可以从 Array 转换成 List。可以作为其他集合类型构造器的参数 |
| Arrays.binarySearch() | 在一个已排序的或者其中一段中快速查找 |
| Arrays.copyOf() | 如果你想扩大数组容量又不想改变它的内容的时候可以使用这个方法 |
| Arrays.copyOfRange() | 可以复制整个数组或其中的一部分 |
| Arrays.deepEquals() Arrays.deepHashCode() |
Arrays.equals/hashCode的高级版本,支持子数组的操作 |
| Arrays.equals() | 如果你想要比较两个数组是否相等,应该调用这个方法而不是数组对象中的 equals方法(数组对象中没有重写equals()方法,所以这个方法之比较引用而不比较内容)。这个方法集合了Java 5的自动装箱和无参变量的特性,来实现将一个变量快速地传给 equals()方法——所以这个方法在比较了对象的类型之后是直接传值进去比较的 |
| Arrays.fill() | 用一个给定的值填充整个数组或其中的一部分 |
| Arrays.hashCode() | 用来根据数组的内容计算其哈希值(数组对象的hashCode()不可用)。这个方法集合了Java 5的自动装箱和无参变量的特性,来实现将一个变量快速地传给 Arrays.hashcode方法——只是传值进去,不是对象 |
| Arrays.sort() | 对整个数组或者数组的一部分进行排序。也可以使用此方法用给定的比较器对对象数组进行排序 |
| Arrays.toString() | 打印数组的内容 |
如果想要复制整个数组或其中一部分到另一个数组,可以调用 System.arraycopy()方法。此方法从源数组中指定的位置复制指定个数的元素到目标数组里。这无疑是一个简便的方法。(有时候用 ByteBuffer bulk复制会更快。可以参考这篇文章).
最后,所有的集合都可以用T[] Collection.toArray( T[] a ) 这个方法复制到数组中。通常会用这样的方式调用:
return coll.toArray( new T[ coll.size() ] );
这个方法会分配足够大的数组来储存所有的集合,这样 toArray() 在返回值时就不必再分配空间了。
集合与数组的转换
(1) 将数组转换为集合
Lsit<T> asList(T... a);//返回一个受指定数组支持的固定大小的列表。
把数组变成List集合的好处:可以使用集合的思想和方法来操作数组中的元素。如:contains,get,indexOf,subList等方法。
PS:
- 将数组转换成集合,不可使用集合的增删方法,因为数组的长度是固定的。如果进行增删操作,则会产生UnsupportedOperationException的编译异常。
- 如果数组中的元素都是对象,则变成集合时,数组中的元素就直接转为集合中的元素。
- 如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在。
(2) 集合转数组
查找
int binarySearch():使用二分搜索法来搜索指定的 byte 型数组,以获得指定的值
判断
boolean equals(Object[] a, Object[] a2):判断指定的两个数组是否相等
排序
void sort():对指定的数组按数字升序进行排序。
复制
<T> T[] copyOf(T[] original, int newLength)
复制指定的数组,截取或用 null 填充(如有必要),以使副本具有指定的长度。
填充
void fill(Object[] a, Object val) 将指定的 Object 引用分配给指定 Object 数组的每个元素。
其他方法
- toString(Object[] a):返回指定数组内容的字符串表示形式。
- int hashCode(Object[] a) 基于指定数组的内容返回哈希码。
package com.heima.test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class Test {
public static void main(String[] args) {
System.out.println("1、将数组转成集合");
System.out.println("-------------------");
// asList()将数组转换为集合
List<Integer> list = Arrays.asList(87, 67, 65, 544);
for (Integer i : list) {
System.out.println(i);
}
System.out.println("2、二分查找");
System.out.println("-------------------");
// binarySearch()二分查找
int[] a = {
23, 45, 67, 8, 32, 45, 6, 7, 85, 54, 3, 432 };
int index = Arrays.binarySearch(a, 45);
System.out.println(index);
System.out.println("3、排序");
System.out.println("-------------------");
// sort()排序
System.out.println("排序前:" + Arrays.toString(a));
Arrays.sort(a);
System.out.println("排序后:" + Arrays.toString(a));
System.out.println("4、集合转成数组");
System.out.println("-------------------");
// toArray()集合转成数组
ArrayList<String> al = new ArrayList<String>();
al.add("java");
al.add("javase");
al.add("php");
al.add("ruby");
al.add("android");
String[] str = al.toArray(new String[al.size()]);
System.out.println(Arrays.toString(str));
}
}
6.3 System.arraycopy()
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
- src - 源数组
- srcPos - 源数组中的起始位置
- dest - 目标数组
- destPos - 目标数据中的起始位置
- length - 要复制的数组元素的数量
6.4 Predicate 操作集合
Predicate 谓词对象,函数式接口,可以使用Lambda表达式作为参数。
- test()
Collection的removeIf(Predicate filter)方法,批量删除符合filter条件的元素
6.5 Stream 操作集合
A sequence of elements supporting sequential and parallel aggregate operations.
- Stream是元素的集合,这点让Stream看起来用些类似Iterator;
- 可以支持顺序和并行的对原Stream进行汇聚的操作;
Stream是什么?高级迭代器
- 大家可以把Stream当成一个高级版本的Iterator
- Iterator,用户只能一个一个的遍历元素并对其执行某些操作
- Stream,用户只要给出需要对其包含的元素执行什么操作
什么是Stream api
jdk8使用流水线的方法处理数据。一堆操作符的集合。
dk8 Stream:是一个集合,但是可能接受多个环节的处理。每个环节专门的操作符(处理方法:由于非常简短看起来就像一个符号)
流式 API,获取Stream:Collection的stream()方法
- Stream
- IntStream
- LongStream
- DoubleStream
对应的Builder
- Stream.Builder
- IntStream.Builder
- LongStream.Builder
- DoubleStream.Builder
Stream
中间方法
| 方法声明 | 功能描述 |
|---|---|
| filter() | 过滤 |
| map() | 转换 |
| mapToXxx() | 一对一转换 |
| flatMap() | 集合扁平化 |
| flatMapToXxx() | |
| peek() | |
| skip() | |
| distinct() | 去重 |
| sorted() | 排序 |
| limit() | |
| concat() | 合并流 |
末端方法
| 方法声明 | 功能描述 |
|---|---|
| forEach() | 遍历 |
| toArray() | 将流中的元素转换成数组 |
| reduce() | 合并流中的元素 |
| min() | 最小值 |
| max() | 最大值 |
| count() | 获取流中元素的数量 |
| anyMatch() | |
| allMatch() | |
| nonMatch() | |
| findFirst() | 获取流中的第一个元素 |
| findAny() | 获取流中的任意一个元素 |
IntStream
| 方法声明 | 功能描述 |
|---|---|
| builder() | |
| max() | |
| min() | |
| sum() | |
| count() | |
| average() | |
| allMatch() | |
| anyMatch() | |
| map() | 一对一转换 |
| forEach() | 遍历 |