分析&回答
一般来说,数据一致性模型可以分为强一致性和弱一致性,强一致性也叫做线性一致性,除此以外,所有其他的一致性都是弱一致性的特殊情况。弱一致性根据不同的业务场景,又可以分解为更细分的模型,不同一致性模型又有不同的应用场景。
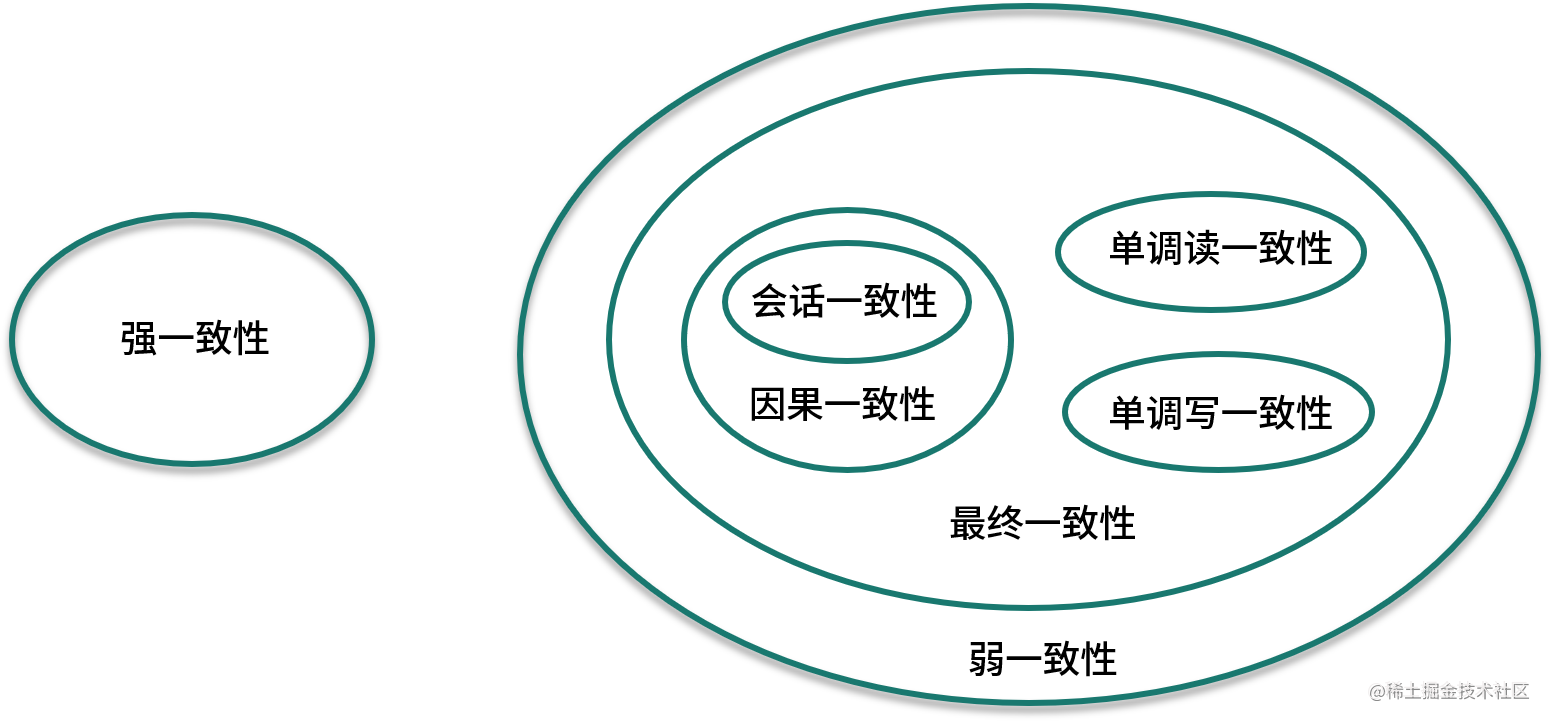
强一致性
当更新操作完成后,任何多个后续进行访问时都会返回最新的值,就是用户刚提交就能看到更新了的数据,这对用户是最友好的。但根据CAP理论,这势必也要牺牲可用性。
弱一致性
系统在写入数据成功后,不承诺立即能读到最新的值,也不承诺什么时候能读到,但是过一段时间之后用户可以看到更新后的值。那么用户读不到最新数据的这段时间被称为“不一致窗口时间”。 「最终一致性」 最终一致性作为弱一致性中的特例,强调的是所有数据副本,在经过一段时间的同步后,最终能够到达一致的状态,不需要实时保证系统数据的强一致性。
最终一致性
Base 理论中我们讲过:最终一致性要求系统中数据副本最终能够一致,而不需要实时保证数据副本一致。
最终一致性可以分为客户端和服务端两个不同的视角。
从客户端的角度看
从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题,最终一致性有以下 4 个变种。
| 一致性变种 | 说明 |
|---|---|
| 因果一致性 | 如果进程 A 通知进程 B 它已更新了一个数据项,那么,进程 B 的后续访问将返回更新后的值,且一次写入将保证取代前一次写入。与进程 A 无因果关系的进程 C 的访问遵守一般的最终一致性规则。 |
| 会话一致性 | 这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话。 |
| 单调读一致性 | 如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。 |
| 单调写一致性 | 系统保证来自同一个进程的写操作顺序执行。 |
从服务器的角度看
从服务端来看,如何尽快地将更新后的数据分布到整个系统,降低达到最终一致性的时间窗口,是提高系统的可用度和用户体验度非常重要的方面。
分布式数据系统有以下特性:
- N 为数据复制的份数。
- W 为更新数据时需要进行写操作的节点数。
- R 为读取数据的时候需要读取的节点数。
- 如果 W+R>N,写的节点和读的节点重叠,则是强一致性。例如,对于典型的一主一备同步复制的关系型数据库(N=2, W=2,R=1),则不管读的是主库还是备库的数据,都是一致的。
- 如果 W+R≤N,则是弱一致性。例如,对于一主一备异步复制的关系型数据库(N=2,W=1,R=1),如果读的是备库,则可能无法读取主库已经更新过的数据,所以是弱一致性。对于分布式系统,为了保证高可用性,一般设置 N≥3。设置不同的N、W、R 组合,是在可用性和一致性之间取一个平衡,以适应不同的应用场景。
- 如果N=W 且 R=1,则任何一个写节点失效,都会导致写失败,因此可用性会降低。但是由于数据分布的 N 个节点是同步写入的,因此可以保证强一致性。
- 如果 N=R 且 W=1,则只需要一个节点写入成功即可,写性能和可用性都比较高。但是读取其他节点的进程可能不能获取更新后的数据,因此是弱一致性。在这种情况下,如果 W<(N+1)/2,并且写入的节点不重叠,则会存在写冲突。
反思&扩展
喵呜面试助手: 一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!