作者的话
前言:总结下知识点,自己偶尔看一看。
一、数据库设计
数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构,并据此建立数据库及其应用系统
1.1概述
1.1.1数据库设计的特点
- 数据库建设的基本规律 三分技术,七分管理,十二分基础数据
- 结构(数据)设计和行为(处理)设计相结合
1.1.2数据库设计方法
- 基于E-R模型的数据库设计方法
- 3NF(第三范式)的设计方法
- 面向对象的数据库设计方法
- 统一建模语言(UML)方法
1.1.3数据库设计的基本步骤
- 需求分析
- 概念结构设计
- 逻辑结构设计
- 物理结构设计
- 数据库实施
- 数据库运行和维护
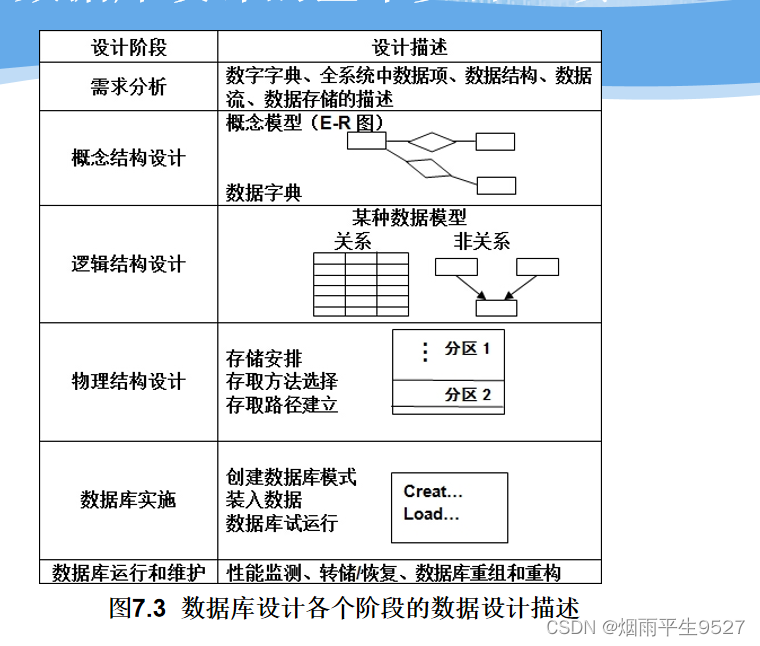
需求分析和概念设计独立于任何数据库管理系统
逻辑设计和物理设计与选用的数据库管理系统密切相关
六个阶段不断反复
1.1.4数据库设计过程中的各级模式
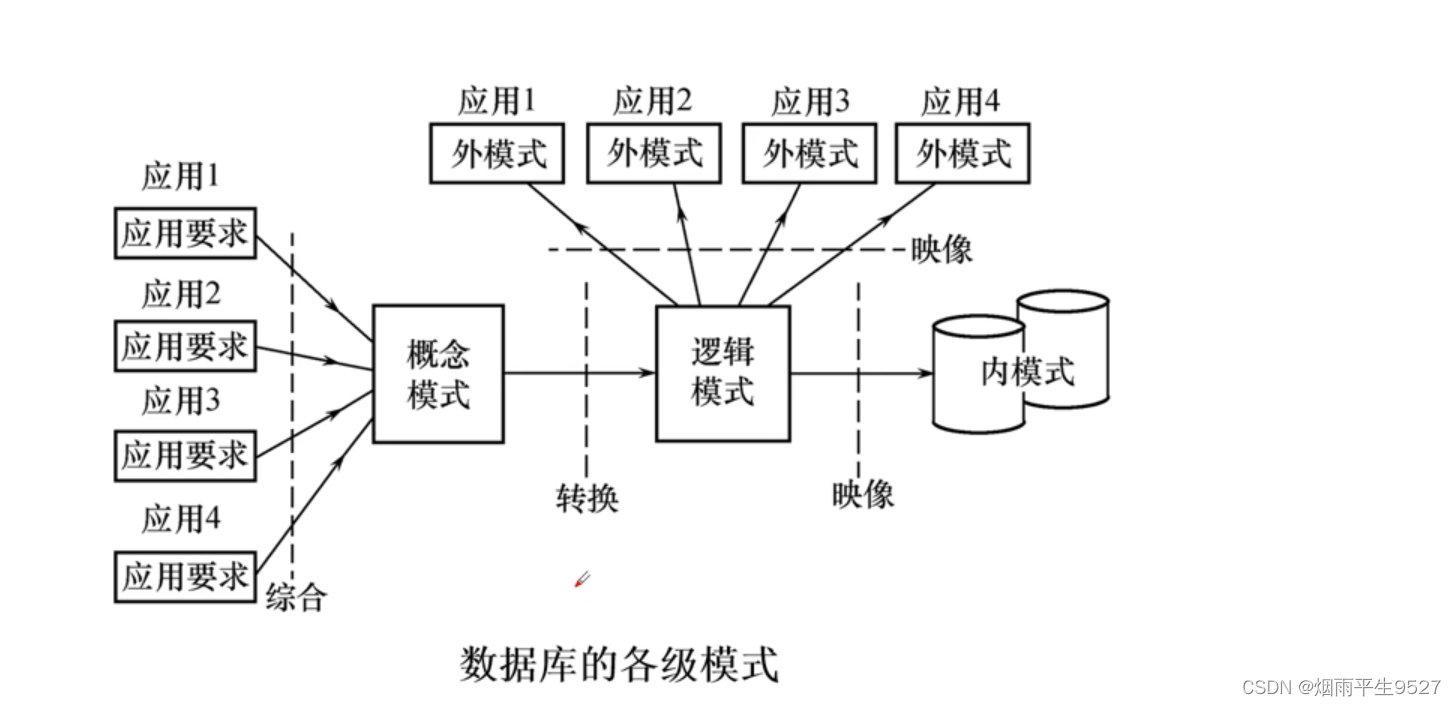
1.2需求分析
调查的重点是“数据”和“处理”,获得用户对数据库的要求
1.2.1需求分析的方法
结构化分析方法(Structured Analysis,简称SA方法)
SA方法从最上层的系统组织机构入手 采用自顶向下、逐层分解的方式分析系统
需求分析报告
1.2.2数据字典
数据字典是关于数据库中数据的描述,即元数据,不是数据本身
1.2.3 概念结构设计
- E-R模型
- 扩展的E-R模型
- UML
1.2.4逻辑结构设计
把概念结构设计阶段设计好的基本E-R图转换为与选用数据库管理系统产品所支持的数据模型相符合的逻辑结构

定义数据库模式主要是从系统的时间效率、空间效率、易维护等角度出发。
- 使用更符合用户习惯的别名
- 针对不同级别的用户定义不同的视图,以保证系统的安全性。
- 简化用户对系统的使用
1.2.5物理结构设计
数据库在物理设备上的存储结构与存取方法称为数据库的物理结构,它依赖于选定的数据库管理系统。
关系模式存取方法选择
- .B+树索引存取方法
- Hash索引存取方法
- 在等值连接条件中或主要出现在等值比较选择条件中
- 聚簇存取方法
- 可以提高查询效率
确定数据库的存储结构
确定数据库物理结构主要指确定数据的存放位置和存储结构,包括:确定关系、索引、聚簇、日志、备份等的存储安排和存储结构,确定系统配置等。
确定数据的存放位置和存储结构要综合考虑存取时间、存储空间利用率和维护代价3个方面的因素
影响数据存放位置和存储结构的因素
硬件环境
应用需求
- 存取时间
- 存储空间利用率
- 维护代价
1.2.6 数据库的实施和维护
数据的载入和应用程序的调试
数据库的试运行
- 功能测试
- 性能测试
数据库的运行和维护
数据库的转储和恢复
数据库的安全性、完整性控制
数据库性能的监督、分析和改进
数据库的重组织与重构造
1.2.7小结

 二、数据库恢复技术
二、数据库恢复技术
2.1事务的基本概念

COMMIT
事务正常结束
提交事务的所有操作(读+更新)
事务中所有对数据库的更新写回到磁盘上的物理数据库中ROLLBACK
事务异常终止
事务运行的过程中发生了故障,不能继续执行
系统将事务中对数据库的所有已完成的操作全部撤销
事务滚回到开始时的状态
事务的ACID特性:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持续性(Durability )
保证事务ACID特性是事务处理的任务
2.2数据库恢复技术概述
数据库管理系统必须具有把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态)的功能,这就是数据库的恢复管理系统对故障的对策
2.3故障的种类
事务没有达到预期的终点(COMMIT或者显式的ROLLBACK),数据库可能处于不正确状态。
事务故障的恢复:事务撤消(UNDO)
强行回滚(ROLLBACK)该事务
撤销该事务已经作出的任何对数据库的修改,使得该事务象根本没有启动一样
系统故障(UNDO & REDO)
称为软故障,是指造成系统停止运转的任何事件,使得系统要重新启动。
常见的原因有:
特定类型的硬件错误(如CPU故障)
操作系统故障
数据库管理系统代码错误
系统断电
发生系统故障时,一些尚未完成的事务的结果可能已送入物理数据库,造成数据库可能处于不正确状态。
恢复策略:系统重新启动时,恢复程序让所有非正常终止的事务回滚,强行撤消(UNDO)所有未完成事务发生系统故障时,有些已完成的事务可能有一部分甚至全部留在缓冲区,尚未写回到磁盘上的物理数据库中,系统故障使得这些事务对数据库的修改部分或全部丢失
恢复策略:系统重新启动时,恢复程序需要重做(REDO)所有已提交的事务
介质故障
介质故障破坏数据库或部分数据库,并影响正在存取这部分数据的所有事务
计算机病毒
2.4恢复的技术实现
1.建立冗余数据(数据转储 & 登记日志文件)
2.利用冗余数据进行数据库恢复
数据转储
转储是指数据库管理员定期地将整个数据库复制到磁带、磁盘或其他存储介质上保存起来的过程
备用的数据文本称为后备副本(backup)或后援副本
重装后备副本只能将数据库恢复到转储时的状态
要想恢复到故障发生时的状态,必须重新运行自转储以后的所有更新事务
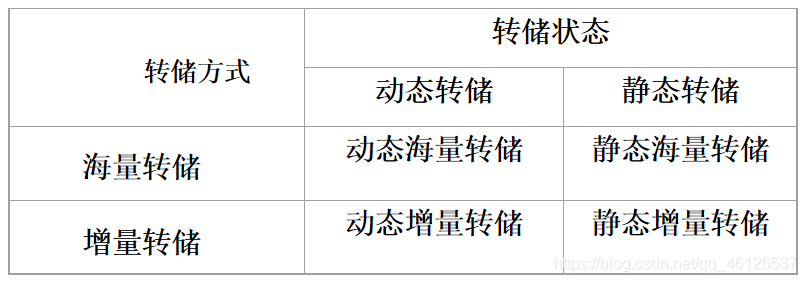
静态转储与动态转储
静态转储 在系统中无运行事务时进行的转储操作
动态转储 转储操作与用户事务并发进行
海量转储与增量转储
海量转储: 每次转储全部数据库
增量转储: 只转储上次转储后更新过的数据
从恢复角度看,使用海量转储得到的后备副本进行恢复往往更方便
如果数据库很大,事务处理又十分频繁,则增量转储方式更实用更有效
登记日志文件
日志文件(log file)是用来记录事务对数据库的更新操作的文件
日志文件的作用:
进行事务故障恢复
进行系统故障恢复
协助后备副本进行介质故障恢复
常用的格式有以记录为单位的日志文件 和 以数据块为单位的日志文件
以记录为单位的日志文件包括:
各个事务的开始标记(BEGIN TRANSACTION)
各个事务的结束标记(COMMIT或ROLLBACK)
各个事务的所有更新操作
以记录为单位的日志文件,每条日志记录的内容
事务标识(标明是哪个事务)
操作类型(插入、删除或修改)
操作对象(记录ID、Block NO.)
更新前数据的旧值(对插入操作而言,此项为空值)
更新后数据的新值(对删除操作而言, 此项为空值)
以数据块为单位的日志文件,每条日志记录的内容
事务标识
被更新的数据块
必须先写日志文件,后写数据库
2.5恢复策略
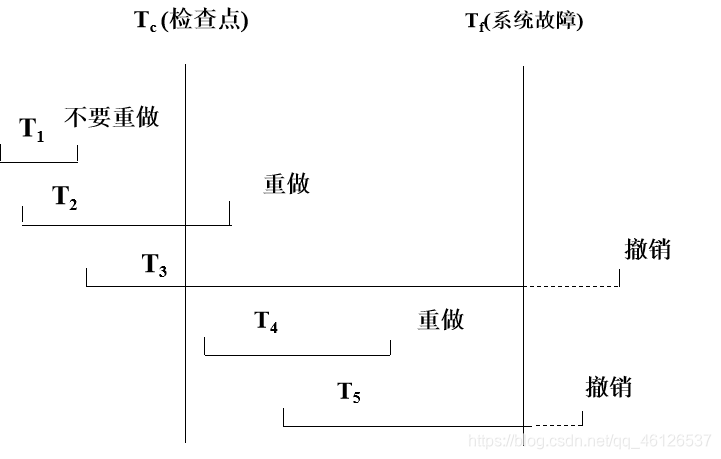
事务故障恢复(UNDO)
事务故障:事务在运行至正常终止点前被终止
恢复方法:由恢复子系统利用日志文件撤消(UNDO)此事务已对数据库进行的修改
事务故障的恢复由系统自动完成,对用户是透明的,不需要用户干预步骤:
1.反向扫描文件日志
2.对该事务的更新操作执行逆操作
3. 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理
4. 直至读到此事务的开始标记
系统故障恢复
系统故障造成数据库不一致状态的原因
未完成事务对数据库的更新可能已写入数据库——UNDO
已提交事务对数据库的更新可能还留在缓冲区没来得及写入数据库——REDO
系统故障的恢复由系统在重新启动时自动完成,不需要用户干预
步骤:
1.正向扫描日志文件得到重做(REDO) 队列 和 撤销 (UNDO)队列
2.对撤销(UNDO)队列事务进行撤销(UNDO)处理——参考上面
3.对重做(REDO)队列事务进行重做(REDO)处理
介质故障恢复
1.重装数据库
2.重做已经完成的事务
步骤:
1.装入最新后备数据库副本(动态的需要装入日志文件)
2.装入有关的日志文件的副本(转储结束时刻的日志文件副本),重做已经完成的事务
介质故障的恢复需要数据库管理员介入
具有检查点的恢复技术
检查点恢复技术是为了解决搜索整个日志和重做出理耗费大量的事件
具有检查点的恢复技术:
在日志文件中增加检查点记录
增加重新开始文件
恢复子系统在登录日志文件期间动态地维护日志
检查点记录的内容:
建立检查点时刻所有正在执行的事务清单
这些事务最近一个日志记录的地址
重新开始文件的内容:
记录各个检查点记录在日志文件中的地址
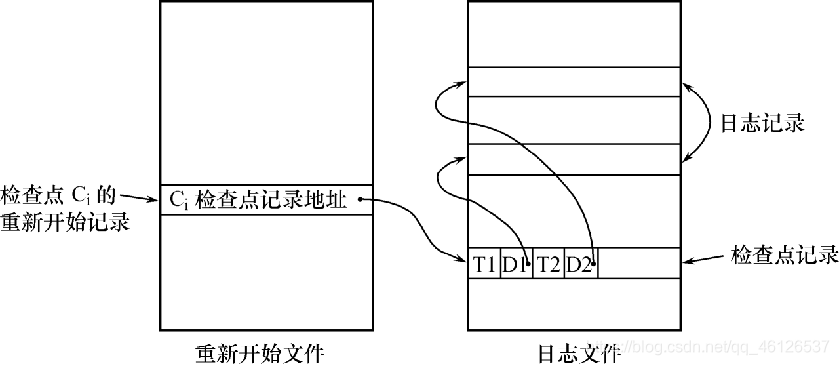
步骤:
1.将当前日志缓冲区中的所有日志记录写入磁盘的日志文件上
2.在日志文件中写入一个检查点记录
3.将当前数据缓冲区的所有数据记录写入磁盘的数据库中
4.把检查点记录在日志文件中的地址写入一个重新开始文件
检查点的保存可以是定期的也可以是不定期的
数据库镜像
数据库管理系统自动把整个数据库或其中的关键数据复制到另一个磁盘上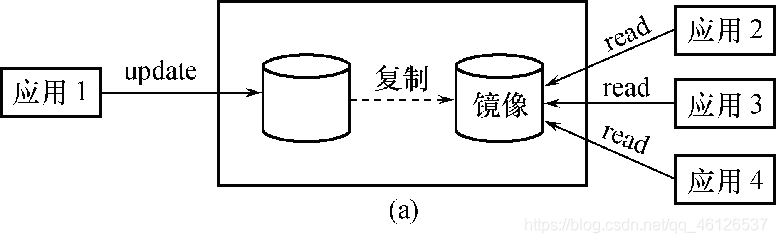
发生故障时使用镜像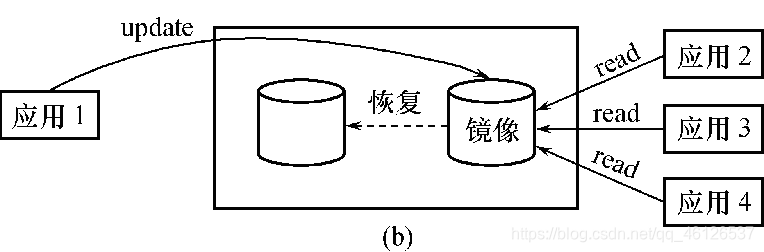
在实际应用中用户往往只选择对关键数据和日志文件镜像
三、并发控制
并发控制的基本概述
事务是并发控制的基本单位
并发控制的任务:
对并发操作进行正确调度
保证事务的隔离性
保证数据库的一致性种类
- 事务串行执行
- 交叉并发方式
- 同时并发方式
并发操作带来的数据不一致性:
1.丢失修改(Lost Update)
2.不可重复读(Non-repeatable Read)
3.读“脏”数据(Dirty Read)数据不一致性:由于并发操作破坏了事务的隔离性
并发控制就是要用正确的方式调度并发操作,使一个用户事务的执行不受其他事务的干扰,从而避免造成数据的不一致性
封锁
封锁就是事务T在对某个数据对象(例如表、记录等)操作之前,先向系统发出请求,对其加锁,加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其它的事务不能更新此数据对象。
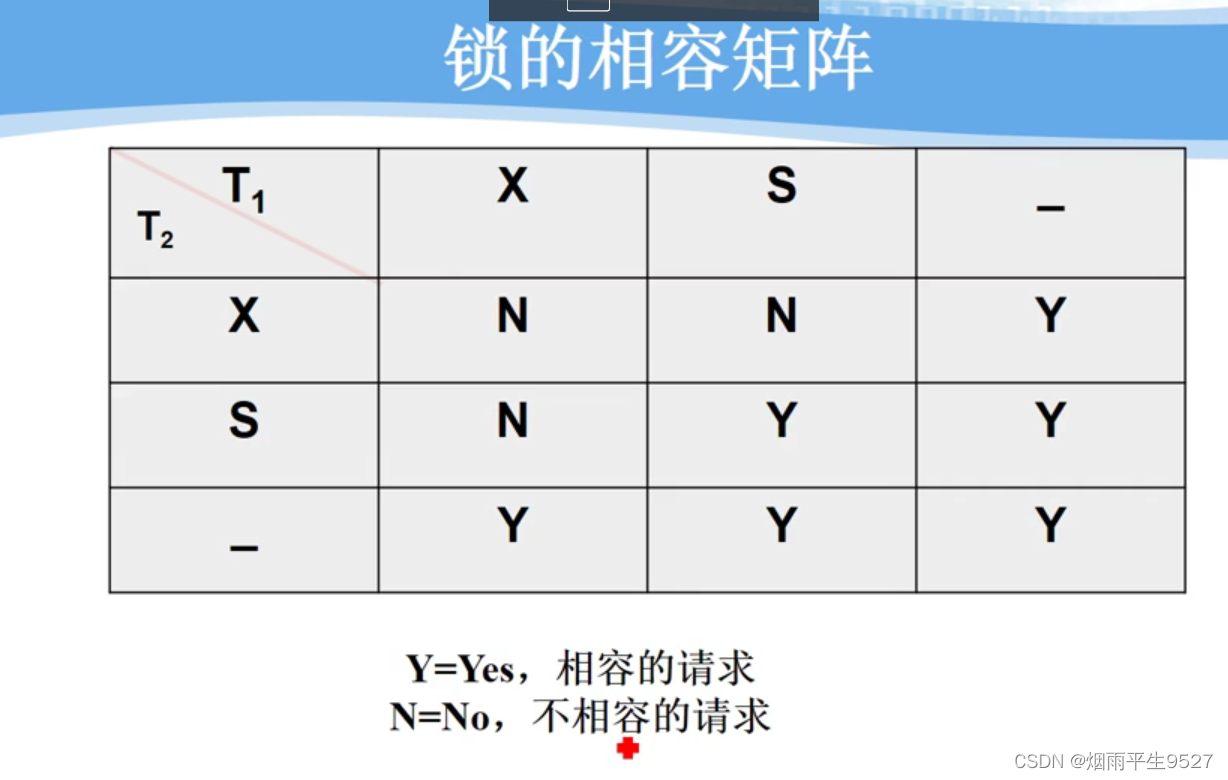
基本封锁类型:排他锁(X锁) & 共享锁(S锁)
排他锁
排它锁又称为写锁
若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁
保证其他事务在T释放A上的锁之前不能再读取和修改A
共享锁
共享锁又称为读锁
若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁
保证其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改
封锁协议
在运用X锁和S锁对数据对象加锁时,需要约定一些规则,这些规则为封锁协议(Locking Protocol)。
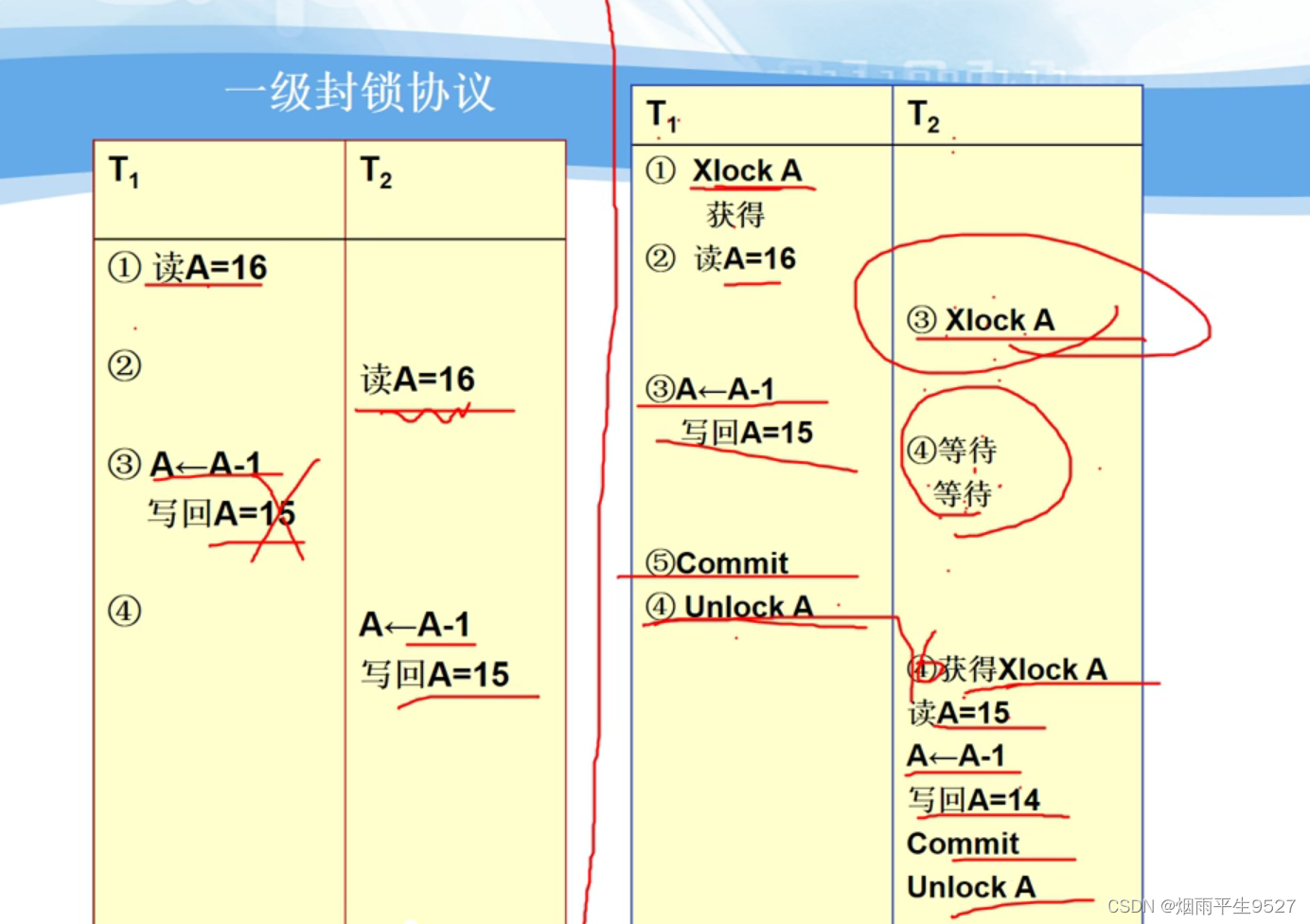
一级封锁协议——不可重复读 & 读脏数据
事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。
一级封锁协议可防止丢失修改,并保证事务T是可恢复的。
在一级封锁协议中,如果仅仅是读数据不对其进行修改,是不需要加锁的,所以它不能保证可重复读和不读“脏”数据。
 二级封锁协议——丢失修改 & 读脏数据
二级封锁协议——丢失修改 & 读脏数据

一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后即可释放S锁。
在二级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
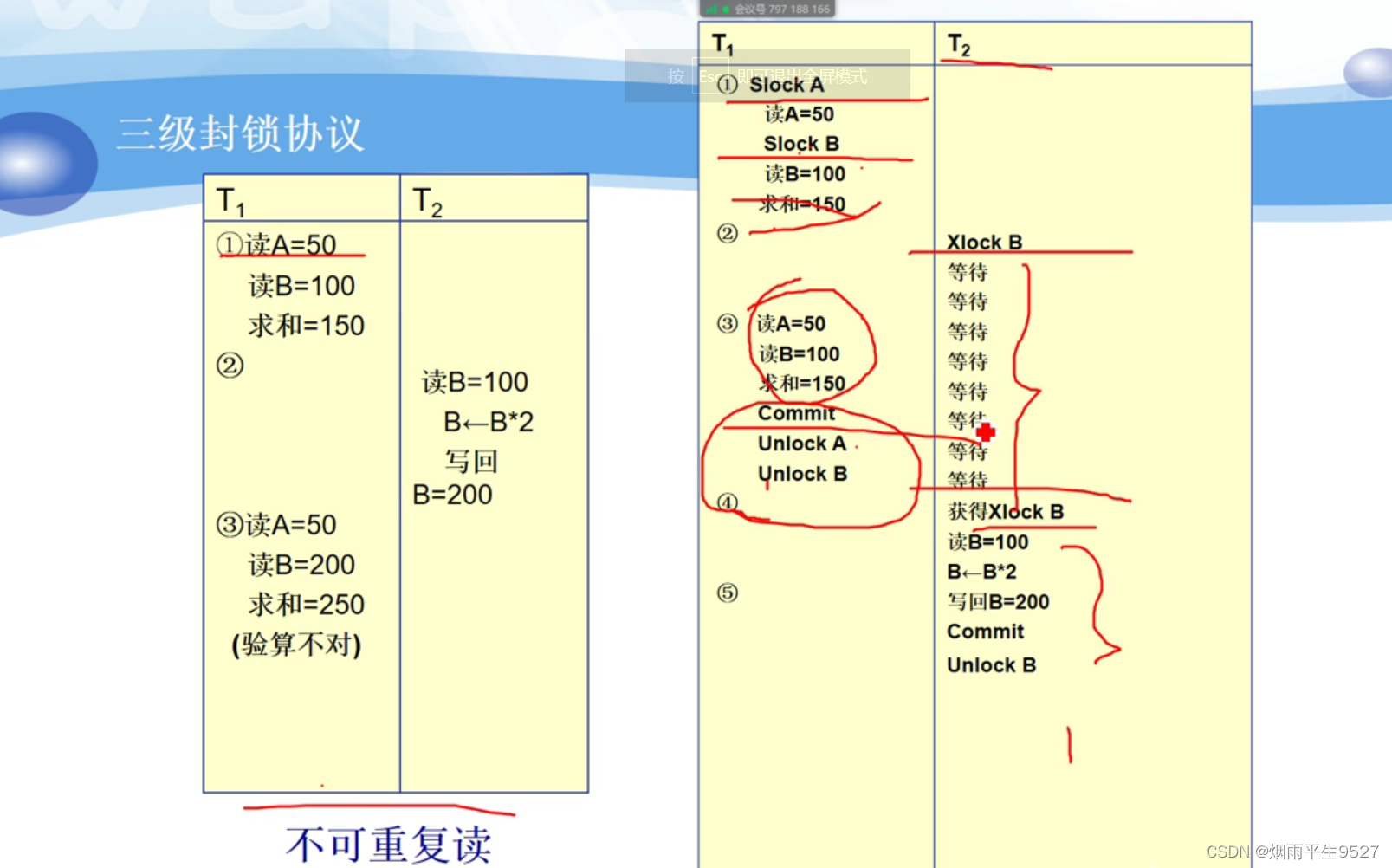
三级封锁协议——丢失修改 & 读脏数据 & 不可重复读
一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
活锁和死锁
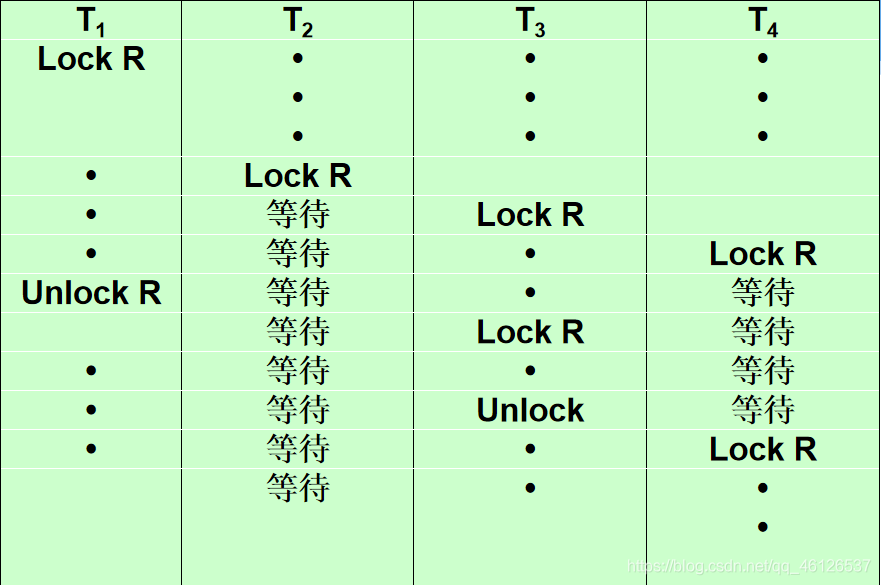
活锁
避免活锁:采用先来先服务的策略
当多个事务请求封锁同一数据对象时
按请求封锁的先后次序对这些事务排队
该数据对象上的锁一旦释放,首先批准申请队列中第一个事务获得锁
死锁
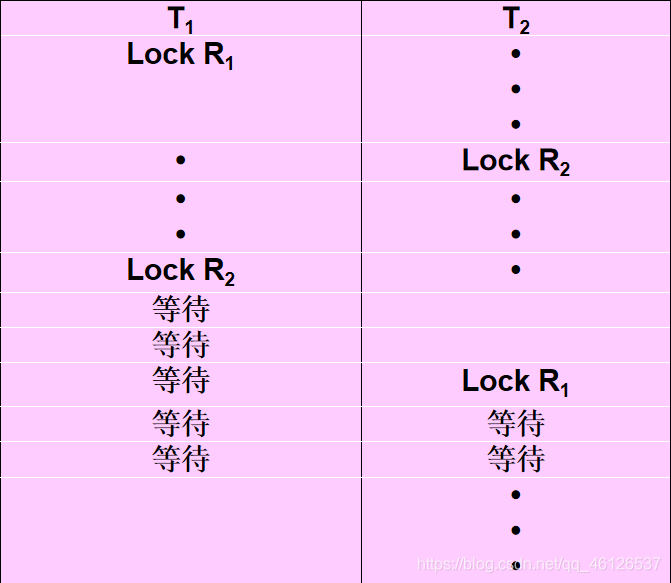
死锁的预防
预防死锁的发生就是要破坏产生死锁的条件
一次封锁法
要求每个事务必须一次将所有要使用的数据全部加锁,否则就不能继续执行
会降低系统并发度
顺序封锁法
顺序封锁法是预先对数据对象规定一个封锁顺序,所有事务都按这个顺序实行封锁。
会导致维护成本很高,并且往往难以实现
死锁的诊断与解除
超时法
如果一个事务的等待时间超过了规定的时限,就认为发生了死锁
优点:实现简单
缺点:有可能误判死锁,时限若设置得太长,死锁发生后不能及时发现
等待图法
用事务等待图动态反映所有事务的等待情况
若T1等待T2,则T1,T2之间划一条有向边,从T1指向T2
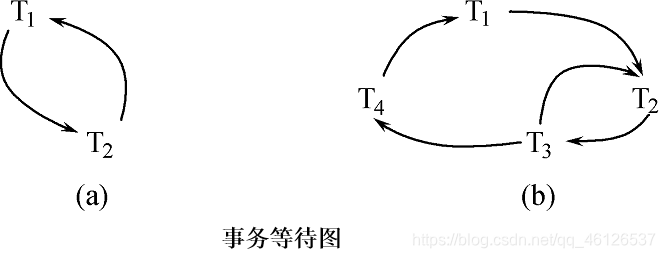
如果发现图中存在回路,则表示系统中出现了死锁。
解除死锁
选择一个处理死锁代价最小的事务,将其撤消,释放此事务持有的所有的锁,使其它事务能继续运行下去
并发调度的可穿行性
执行结果等价于串行调度的调度也是正确的,称为可串行化调度
可串行化调度
可串行化(Serializable)调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同
冲突可串行化调度
冲突操作:是指不同的事务对同一数据的读写操作 和 写写操作
不能交换的两个动作:
同一事务的两个操作
不同事务的冲突操作
一个调度Sc在保证冲突操作的次序不变的情况下,通过交换两个事务不冲突操作的次序得到另一个调度Sc’,如果Sc’是串行的,称调度Sc是冲突可串行化的调度
冲突可串行化调度是可串行化调度的充分条件
两段锁协议
数据库管理系统普遍采用两段锁协议的方法实现并发调度的可串行性,从而保证调度的正确性
两段锁协议是指所有事务必须分两个阶段对数据项加锁和解锁
在对任何数据进行读、写操作之前,事务首先要获得对该数据的封锁
在释放一个封锁之后,事务不再申请和获得任何其他封锁

事务遵守两段锁协议是可串行化调度的充分条件
遵守两段锁协议的事务可能发生死锁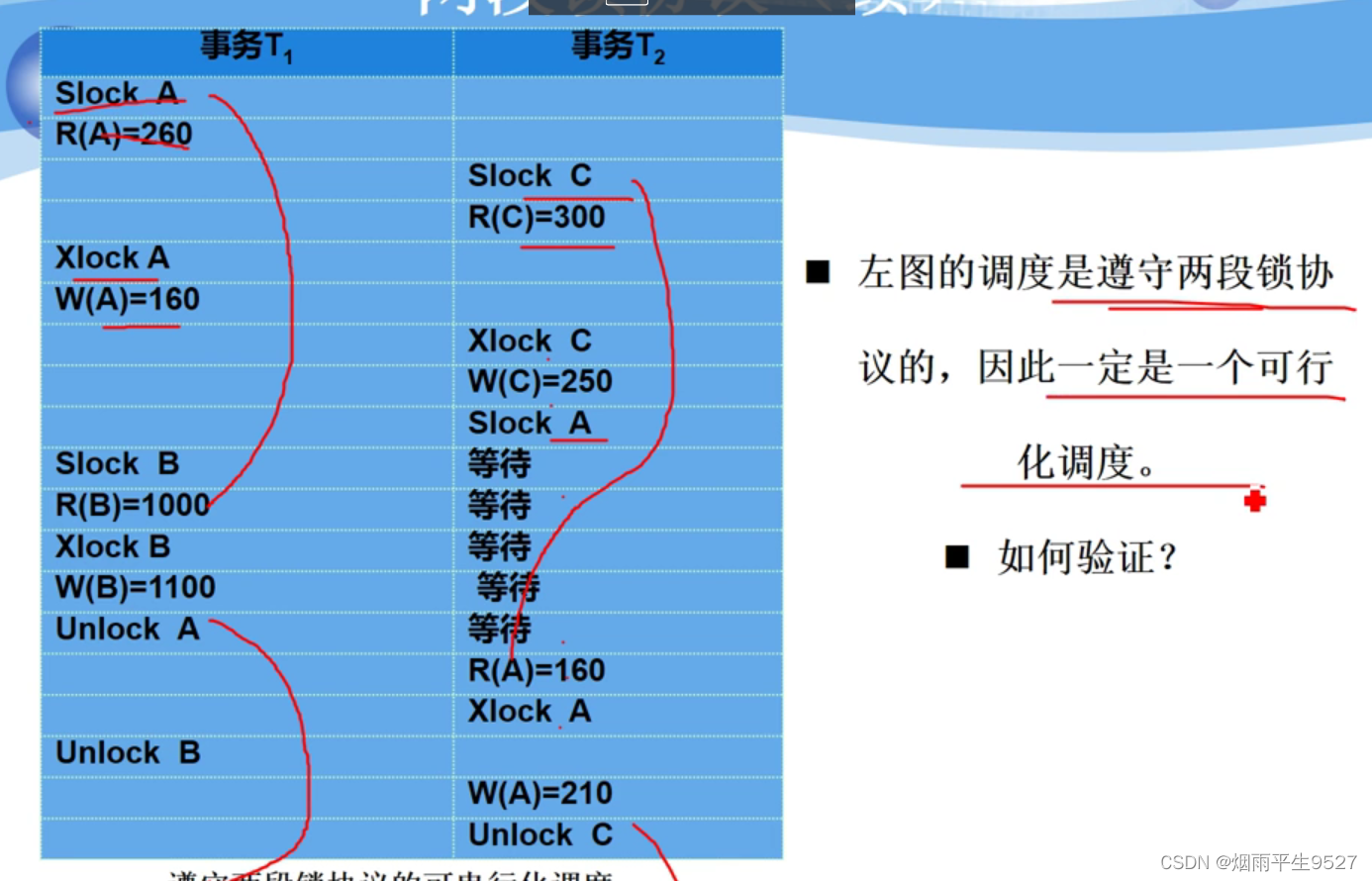
封锁粒度
封锁对象的大小称为封锁粒度
封锁的粒度越大,数据库所能够封锁的数据单元就越少,并发度就越小,系统开销也越小
同时考虑封锁开销和并发度两个因素, 适当选择封锁粒度:
需要处理多个关系的大量元组的用户事务:以数据库为封锁单位
需要处理大量元组的用户事务:以关系为封锁单元
只处理少量元组的用户事务:以元组为封锁单位
多粒度封锁
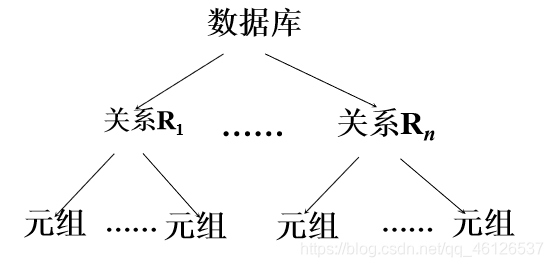
显式封锁: 直接加到数据对象上的封锁
隐式封锁:是该数据对象没有独立加锁,是由于其上级结点加锁而使该数据对象加上了锁
显式封锁和隐式封锁的效果是一样的
系统检查封锁冲突时要检查显式封锁,还要检查隐式封锁
对某个数据对象加锁,系统要检查该数据对象、所有上级结点、所有下级结点
意向锁
引进意向锁(intention lock)目的是提高对某个数据对象加锁时系统的检查效率
如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁
对任一结点加基本锁,必须先对它的上层结点加意向锁
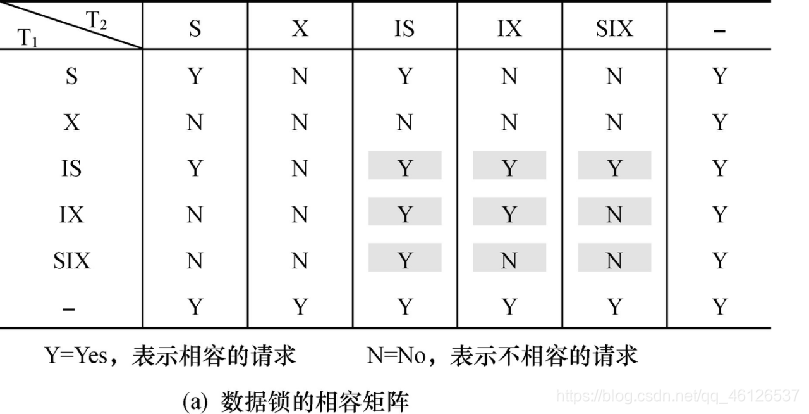
锁的强度是指它对其他锁的排斥程度
一个事务在申请封锁时以强锁代替弱锁是安全的,反之则不然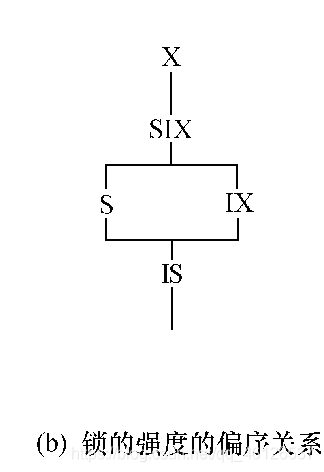
具有意向锁的多粒度封锁方法:
申请封锁时应该按自上而下的次序进行
释放封锁时则应该按自下而上的次序进行
具有意向锁的多粒度封锁方法:
提高了系统的并发度
减少了加锁和解锁的开销
在实际的数据库管理系统产品中得到广泛应用
意向共享锁(IS锁)
如果对一个数据对象加IS锁,表示它的后裔结点拟(意向)加S锁。
意向排它锁(IX锁)
如果对一个数据对象加IX锁,表示它的后裔结点拟(意向)加X锁。
共享意向排它锁(SIX锁)
如果对一个数据对象加SIX锁,表示对它加S锁,再加IX锁,即SIX = S + IX。