导航:
【Java笔记+踩坑汇总】Java基础+进阶+JavaWeb+SSM+SpringBoot+瑞吉外卖+SpringCloud+黑马旅游+谷粒商城+学成在线+MySQL高级篇+设计模式+牛客面试题
目录
5. 排序优化
5.1 排序优化建议
问题:在 WHERE 条件字段上加索引,但是为什么在 ORDER BY 字段上还要加索引呢?
在MySQL中,支持两种排序方式,分别是 FileSort 和 Index 排序。
- Index排序:索引排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高,推荐使用。
- FileSort排序:FileSort 排序则一般在内存中进行排序,占用CPU较多。如果待排结果较大,会产生临时文件 I/O 到磁盘进行排序的情况,效率较低。
优化建议:
- 优化器自动选择排序方式:MySQL支持索引排序和FileSort排序,索引保证记录有序性,性能高,推荐使用。FileSort排序是内存中排序,数据量大时产生临时文件在磁盘里排序,效率低还占用大量CPU。并不是说FileSort一定效率低,一些情况它可能效率高。例如没覆盖索引的左模糊、“不等于”查询,全表扫描效率比索引遍历再回表更高。
- 要符合最左前缀:where后条件和order by字段创建联合索引,顺序要需要符合最左前缀。例如索引(a,b,c),查询where a=1 order by b,c。
- 范围查询右边排序索引失效:例如索引(a,b,c),查询where a>1 order by b,c,导致b,c排序不能走索引,需要filesort。
- 要么全升序要么全降序:排序顺序必须要么全部DESC,要么全部ASC。乱序会导致索引失效。
- 待排序数量大时会导致索引失效:待排序数据量大约超过一万个,就不走索引走filesort了。建议用limit和where过滤,减少数据量。数据量很大时,索引排序完需要回表查所有数据,性能很差,还不如FileSort在内存中排序效率高。并不是说使用limit一定会走索引排序,关键看的是数据量,数据量过大时优化器会使用FileSort排序。
- 优先范围字段加索引:当【范围条件】和【group by 或者 order by】的字段出现二选一时,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。这样即使范围查询导致排序索引失效,效率依然比只索引排序字段时候高。如果只能过滤一点点,那就优先索引放到排序字段上。
- 调优FileSort :无法使用 Index 排序时,需要对 FileSort 方式进行调优。例如增大sort_buffer_size(排序缓冲区大小)和 max_length_for_sort_data(排序数据最大长度)
5.2 测试
5.2.1 案例验证
删除student表和class表中已创建的索引。
# 方式1 DROP INDEX idx_monitor ON class; DROP INDEX idx_cid ON student; DROP INDEX idx_age ON student; DROP INDEX idx_name ON student; DROP INDEX idx_age_name_classId ON student; DROP INDEX idx_age_classId_name ON student; # 方式2:call调用删除函数 call proc_drop_index('atguigudb2','student');
以下是否能使用到索引,能否去掉using filesort
不加索引直接走filesort排序:
#索引失败。没有limit
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid; 
加索引后,order by 时不limit导致数据量过大,从而索引失效:
CREATE INDEX idx_age_classid_name ON student(age,classId,name);
#索引失败。没有limit
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid;
#索引成功,key_len为73
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classid LIMIT 10000;
过程三:order by 时顺序错误,索引失效
#创建索引age,classid,stuno
#call proc_drop_index('atguigudb2','student');
CREATE INDEX idx_age_classid_stuno ON student (age,classid,stuno);
#索引失效,不符合最左前缀
EXPLAIN SELECT * FROM student ORDER BY classid LIMIT 10;
#索引失效,不符合最左前缀
EXPLAIN SELECT * FROM student ORDER BY classid,name LIMIT 10;
#索引失效,不符合最左前缀
EXPLAIN SELECT * FROM student WHERE classid=1 ORDER BY age,stuno;
#全走索引,虽然不符合最左前缀,但因为查询量小,优化器先排序三个字段,再where找10个返回。
#优化器认为索引比filesort效率高,就用了索引
EXPLAIN SELECT * FROM student WHERE classid=1 ORDER BY age,stuno LIMIT 10;
#索引成功,符合最左前缀
EXPLAIN SELECT * FROM student ORDER BY age,classid,stuno LIMIT 10;
#索引成功,符合最左前缀
EXPLAIN SELECT * FROM student ORDER BY age,classid LIMIT 10;过程四:order by 时规则不一致,索引失效(顺序错,不索引;方向反,不索引)
必须符合最左前缀和“全升序或全降序”
#创建索引age,classid,stuno
CREATE INDEX idx_age_classid_stuno ON student (age,classid,stuno);
#没符合“全升序或全降序”,索引失效
EXPLAIN SELECT * FROM student ORDER BY age DESC,classid ASC LIMIT 10;
#没符合最左前缀,索引失效
EXPLAIN SELECT * FROM student ORDER BY classid DESC,name DESC LIMIT 10;
#没符合“全升序或全降序”,索引失效
EXPLAIN SELECT * FROM student ORDER BY age ASC,classid DESC LIMIT 10;
#符合最左前缀,符合“全升序或全降序”,索引成功
EXPLAIN SELECT * FROM student ORDER BY age DESC,classid DESC LIMIT 10;过程五:limit数据量小时,不满足最左前缀也可能走索引,先排序再where筛选。
CREATE INDEX idx_age_classid_stuno ON student (age,classid,stuno);
CREATE INDEX idx_age_classid_name ON student(age,classId,name);
#都走了索引。
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid LIMIT 10;
#都走了索引。
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classid,name;
#都没用索引,不符合最左前缀
EXPLAIN SELECT * FROM student WHERE classid=45 order by age;
#全走了索引。因为limit数据量小,优化器直接先用排序字段索引排序,然后再where筛选10个
EXPLAIN SELECT * FROM student WHERE classid=45 order by age limit 10;
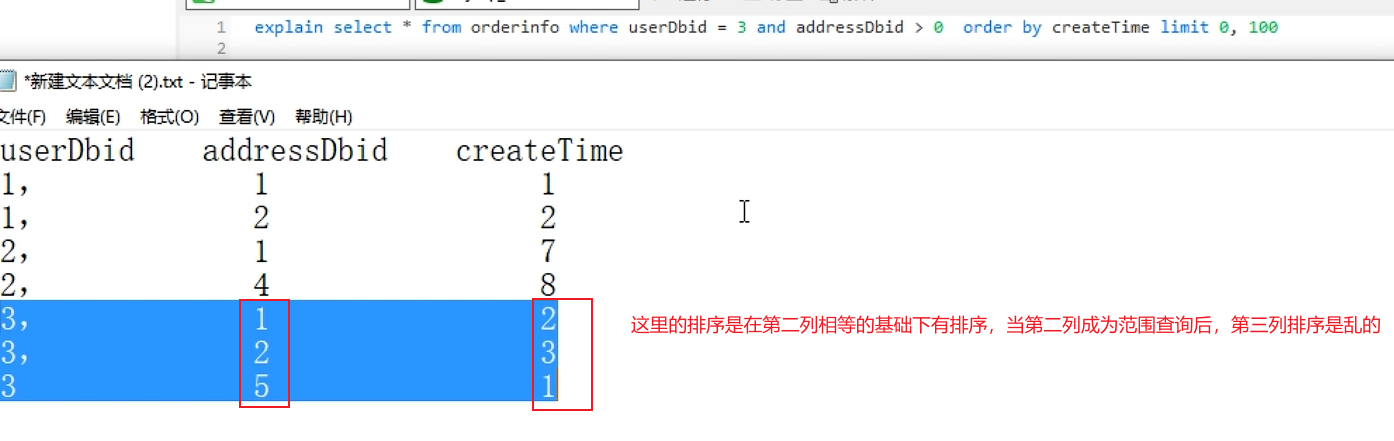
范围查找导致索引失效:下面有索引(userDbid,addressDbid,createTime),userDbid,addressDbid走了索引,因为addressDbid是范围查找,导致createTime索引失败。
5.3.2 练习
INDEX a_b_c(a,b,c)
order by 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by 能使用索引
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
不能使用索引进行排序
- ORDER BY a ASC,b DESC,c DESC /* 排序不一致 */
- WHERE g = const ORDER BY b,c /*丢失a索引*/
- WHERE a = const ORDER BY c /*丢失b索引*/
- WHERE a = const ORDER BY a,d /*d不是索引的一部分*/
- WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/
5.3 范围查询时索引字段选择
- mysql自动选择最优的方案:两个索引同时存在,mysql自动选择最优的方案。(对于这个例子,mysql选择 idx_age_stuno_name)。但是, 随着数据量的变化,选择的索引也会随之变化的。
- 过滤比例高时优先过滤字段加索引:当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序。
执行案例前先清除student上的索引,只留主键:
DROP INDEX idx_age ON student; DROP INDEX idx_age_classid_stuno ON student; DROP INDEX idx_age_classid_name ON student; #或者 call proc_drop_index('atguigudb2','student');
场景:查询年龄为30岁的,且学生编号小于101000的学生,按用户名称排序
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME ;

查询结果如下:
mysql> SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME;
+---------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+---------+--------+--------+------+---------+
| 922 | 100923 | elTLXD | 30 | 249 |
| 3723263 | 100412 | hKcjLb | 30 | 59 |
| 3724152 | 100827 | iHLJmh | 30 | 387 |
| 3724030 | 100776 | LgxWoD | 30 | 253 |
| 30 | 100031 | LZMOIa | 30 | 97 |
| 3722887 | 100237 | QzbJdx | 30 | 440 |
| 609 | 100610 | vbRimN | 30 | 481 |
| 139 | 100140 | ZqFbuR | 30 | 351 |
+---------+--------+--------+------+---------+
8 rows in set, 1 warning (3.16 sec)
结论:type 是 ALL,即最坏的情况。Extra 里还出现了 Using filesort,也是最坏的情况。优化是必须的。
方案一: 为了去掉filesort我们创建索引,查询效率高了一点
#创建新索引
CREATE INDEX idx_age_name ON student(age,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME;
只有age走了索引:

这样我们优化掉了 using filesort
查询结果如下:

方案二:尽量让where的过滤条件和排序使用上索引,发现查询效率更高
建一个三个字段的组合索引,发现using filesort依然存在:
DROP INDEX idx_age_name ON student;
CREATE INDEX idx_age_stuno_name ON student (age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME;
age和stuno走了索引:

我们发现using filesort依然存在,所以name并没有用到索引,而且type还是range光看名字其实并不美好。原因是,因为stuno是一个范围过滤,所以索引后面的字段不会在使用索引了 。
结果如下:
mysql> SELECT SQL_NO_CACHE * FROM student
-> WHERE age = 30 AND stuno <101000 ORDER BY NAME ;
+-----+--------+--------+------+---------+
| id | stuno | name | age | classId |
+-----+--------+--------+------+---------+
| 167 | 100168 | AClxEF | 30 | 319 |
| 323 | 100324 | bwbTpQ | 30 | 654 |
| 651 | 100652 | DRwIac | 30 | 997 |
| 517 | 100518 | HNSYqJ | 30 | 256 |
| 344 | 100345 | JuepiX | 30 | 329 |
| 905 | 100906 | JuWALd | 30 | 892 |
| 574 | 100575 | kbyqjX | 30 | 260 |
| 703 | 100704 | KJbprS | 30 | 594 |
| 723 | 100724 | OTdJkY | 30 | 236 |
| 656 | 100657 | Pfgqmj | 30 | 600 |
| 982 | 100983 | qywLqw | 30 | 837 |
| 468 | 100469 | sLEKQW | 30 | 346 |
| 988 | 100989 | UBYqJl | 30 | 457 |
| 173 | 100174 | UltkTN | 30 | 830 |
| 332 | 100333 | YjWiZw | 30 | 824 |
+-----+--------+--------+------+---------+
15 rows in set, 1 warning (0.00 sec)
结果竟然是,filesort运行速度比索引还快,而且快了很多,几乎一瞬间就出现了结果。
原因:
所有的排序都是在条件过滤之后才执行的。所以,如果条件过滤掉大部分数据的话,剩下几百几千条数据进行排序其实并不是很消耗性能,即使索引优化了排序,但实际提升性能很有限。相对的 stuno<101000 这个条件,如果没有用到索引的话,要对几万条的数据进行扫描,这是非常消耗性能的,所以索引放在这个字段上性价比最高,是最优选择
结论:
- 两个索引同时存在,mysql自动选择最优的方案。(对于这个例子,mysql选择 idx_age_stuno_name)。但是, 随着数据量的变化,选择的索引也会随之变化的。
- 当【范围条件】和【group by 或者 order by】的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
思考:这里我们使用如下索引,是否可行?
DROP INDEX idx_age_stuno_name ON student; CREATE INDEX idx_age_stuno ON student(age,stuno);当然可以。
5.4 filesort算法
5.4.1 双路排序和单路排序
排序的字段若不在索引列上,则filesort会有两种算法:双路排序和单路排序
双路排序 (慢)
- MySQL 4.1之前是使用双路排序 ,字面意思就是两次扫描磁盘,最终得到数据, 读取行指针和 order by列 ,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出
- 从磁盘取排序字段,在buffer进行排序,再从磁盘取其他字段 。
取一批数据,要对磁盘进行两次扫描,众所周知,IO是很耗时的,所以在mysql4.1之后,出现了第二种 改进的算法,就是单路排序。
单路排序 (快)
从磁盘读取查询需要的 所有列 ,按照order by列在buffer对它们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间, 因为它把每一行都保存在内存中了。
结论及引申出的问题
-
由于单路是后出的,总体而言好过双路
-
但是用单路有问题
- 在sort_buffer中,单路要比多路多占用很多空间,因为单路是把所有字段都取出,所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排...从而多次I/O。
- 单路本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。
5.4.2 调优filesort
1. 尝试提高 sort_buffer_size

2. 尝试提高 max_length_for_sort_data
SHOW VARIABLES LIKE '%max_length_for_sort_data%';
#默认1924字节提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出sort buffer size的概率就增大,明显症状是高的磁盘IO活动和低的处理器使用率。如果需要返回的列的总长度大于max_length_for_sort data,使用双路算法,否则使用单路算法.1024-8192字节之间调整
3. Order by 时select * 是一个大忌。最好只Query需要的字段。
- 当Query的字段大小总和小于max_ength_for_sort_data,而且排序字段不是TEXTBLOB 类型时,会用改进后的算法--单路排序,否则用老算法——多路排序。
- 两种算法的数据都有可能超出sort_bufer_size的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/0,但是用单路排序算法的风险会更大一些,所以要 提高sort_buffer_size。
6. 分组优化
- 跟排序优化近似:group by 使用索引的原则几乎跟order by一致 ,group by 即使没有过滤条件用到索引,也可以直接使用索引。
- 最左前缀:group by 先排序再分组,遵照索引建的最佳左前缀法则
- 调优FileSort:当无法使用索引列,增大 max_length_for_sort_data 和 sort_buffer_size 参数的设置
- where效率高于having,能写在where限定的条件就不要写在having中了。where是分组前过滤,having是分组后过滤。
- 尽量不排序分组、节省cpu:减少使用order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。Order by、group by、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 使用limit:包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行 以内,否则SQL会很慢。
7. 分页查询优化
7.1 深分页查询优化
一般分页查询时,通过创建覆盖索引能够比较好地提高性能。
目前问题: offset非常大时,需要查询大量无用的数据量再分页,性能差。
一个常见又非常头疼的问题就是limit 2000000,10此时需要MySQL排序前200000010 记录,仅仅返回2000000~2000010 的记录,其他记录丢弃,查询排序的代价常大。并且select *需要回表,更耗费时间。
EXPLAIN SELECT * FROM student LIMIT 2000000,10; 
主键自增的表:直接查范围之后的10个数据。可以把Limit 查询转换成某个位置的查询 。
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;

主键不自增的表:当前表内连接排序截取后的主键表,连接字段是主键。
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a WHERE t.id = a.id;
也可以用子查询,子查询优化成关联查询。

7.2 带排序的深分页优化
优化前: 查询根据age逆序排列的深分页
EXPLAIN SELECT * FROM student order by age desc LIMIT 2000000,10; 优化方案一: 优化思路跟之前一样,内连接字段是id
EXPLAIN SELECT * FROM student t1,(SELECT id FROM student ORDER BY age desc LIMIT 2000000,10) t2 WHERE t1.id=t2.id优化方案二:如果是顺序翻页,可以得到上一页最后一条记录x,那么目标页码的所有记录id都比x.id小(因为逆序,且排序依据其实是age,id),目标页码的所有记录age都比x.age小或等于。
EXPLAIN SELECT * FROM student WHERE id<#{x.id} AND age>=#{x.age} ORDER BY age DESC LIMIT 10;