背景
在用spring boot+mybatis plus实现增删改查的时候,总是免不了各种模糊查询和分页的查询。每个数据表设计一个模糊分页,这样代码就造成了冗余,且对自身的技能提升没有帮助。那么有没有办法实现一个通用的增删改查的方法呢?今天的shigen闲不住,参照gitee大神蜗牛的项目,实现了通用的查询+分页的封装。
在此之前,希望你对于
mybatis plus的基本API有一定的了解。
那么我先列举一下我之前写的代码,实现的模糊查询和分页吧。
Page<SlowLogData> page = new Page<>(queryVo.getPageNum(), queryVo.getPageSize());
if (StrUtil.isAllNotBlank(sortColumn, isAsc)) {
OrderItem orderItem = new OrderItem(sortColumn, Boolean.parseBoolean(isAsc));
page.addOrder(orderItem);
}
LambdaQueryWrapper<SlowLogData> queryWrapper = new LambdaQueryWrapper<SlowLogData>()
.like(keywordIsNotEmpty, SlowLogData::getInstanceId, keyword)
.or()
.like(keywordIsNotEmpty, SlowLogData::getInstanceName, keyword)
.or()
.like(keywordIsNotEmpty, SlowLogData::getDatabase, keyword)
.or()
.like(keywordIsNotEmpty, SlowLogData::getSqlText, keyword)
.or()
.like(keywordIsNotEmpty, SlowLogData::getUserName, keyword)
.gt(startTime != null, SlowLogData::getTimestamp, startTime)
.lt(endTime != null, SlowLogData::getTimestamp, endTime);
return getBaseMapper().selectPage(page, queryWrapper);
怎么样,我只能先肯定的说这个肯定比mybatis更好一些,至少我的Java字段名变了,我这边就可以在编译的时候报错,提示去修改。那么,shigen是个喜欢把代码写优雅的人,这样的代码是活不久的。
改造
先分析一下我需要的效果或者说是功能:
- 根据某些字段的值精确匹配
- 根据某些字段的值进行模糊匹配
- 根据某些字段排序,可以升序降序
- 还要进行数据的分页展示
所以,如果停留在第一阶段:代码能实现,那我以上的代码就可以实现。但是有更高的要求和代码的复用性上,我推荐我一下的实现。
查询条件封装
我写了一个工具类AggregateQueriesUtil,实现动态查询条件的封装。

public class AggregateQueriesUtil {
/**
* 聚合查询对象拼接
*
* @param queries 查询对象
* @param aggregate 聚合查询对象
* @return {@link QueryWrapper}<{@link Q}>
*/
public static <Q, T, R> QueryWrapper<Q> splicingAggregateQueries(QueryWrapper<Q> queries, AggregateQueries<T, R> aggregate) {
if (aggregate.hasEqualsQueries()) {
equalsQueries(queries, aggregate.getEqualsQueries());
}
if (aggregate.hasFuzzyQueries()) {
fuzzyQueries(queries, aggregate.getFuzzyQueries());
}
if (aggregate.hasSortField()) {
aggregate.setSortType(aggregate.hasSortType() ? aggregate.getSortType() : 0);
applySort(queries, aggregate.getSortField(), aggregate.getSortType());
}
return queries;
}
/**
* equals查询对象拼接
*
* @param queries 查询对象
* @param obj 聚合查询属性对象
*/
public static <Q> void equalsQueries(QueryWrapper<Q> queries, Object obj) {
Field[] declaredFields = obj.getClass().getDeclaredFields();
for (Field field : declaredFields) {
field.setAccessible(true);
String underlineCase = StrUtil.toUnderlineCase(field.getName());
try {
if (field.get(obj) != null) {
queries.eq(underlineCase, field.get(obj));
}
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
/**
* 模糊查询对象拼接
*
* @param queries 查询对象
* @param obj 模糊查询属性对象
*/
public static <Q> void fuzzyQueries(QueryWrapper<Q> queries, Object obj) {
Field[] declaredFields = obj.getClass().getDeclaredFields();
for (Field field : declaredFields) {
field.setAccessible(true);
String underlineCase = StrUtil.toUnderlineCase(field.getName());
try {
if (field.get(obj) != null) {
queries.like(underlineCase, field.get(obj));
}
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
/**
* 排序
*
* @param wrapper 查询对象
* @param sortField 排序字段
* @param sortType 排序类型
*/
private static <Q> void applySort(QueryWrapper<Q> wrapper, String sortField, int sortType) {
String field = StrUtil.toUnderlineCase(sortField);
if (sortType == 1) {
wrapper.orderByDesc(field);
} else {
wrapper.orderByAsc(field);
}
}
}
第一个方法就是核心的方法:实现聚合查询对象的拼接,分别处理equals查询、like查询和排序。也可以看到这里用到了反射,实现对象属性名的获取,然后通过属性名获得传进来的对象的值。
那这里涉及到AggregateQueries,它到底是什么呢?这个就是我们查询条件的聚合类。
查询条件聚合类
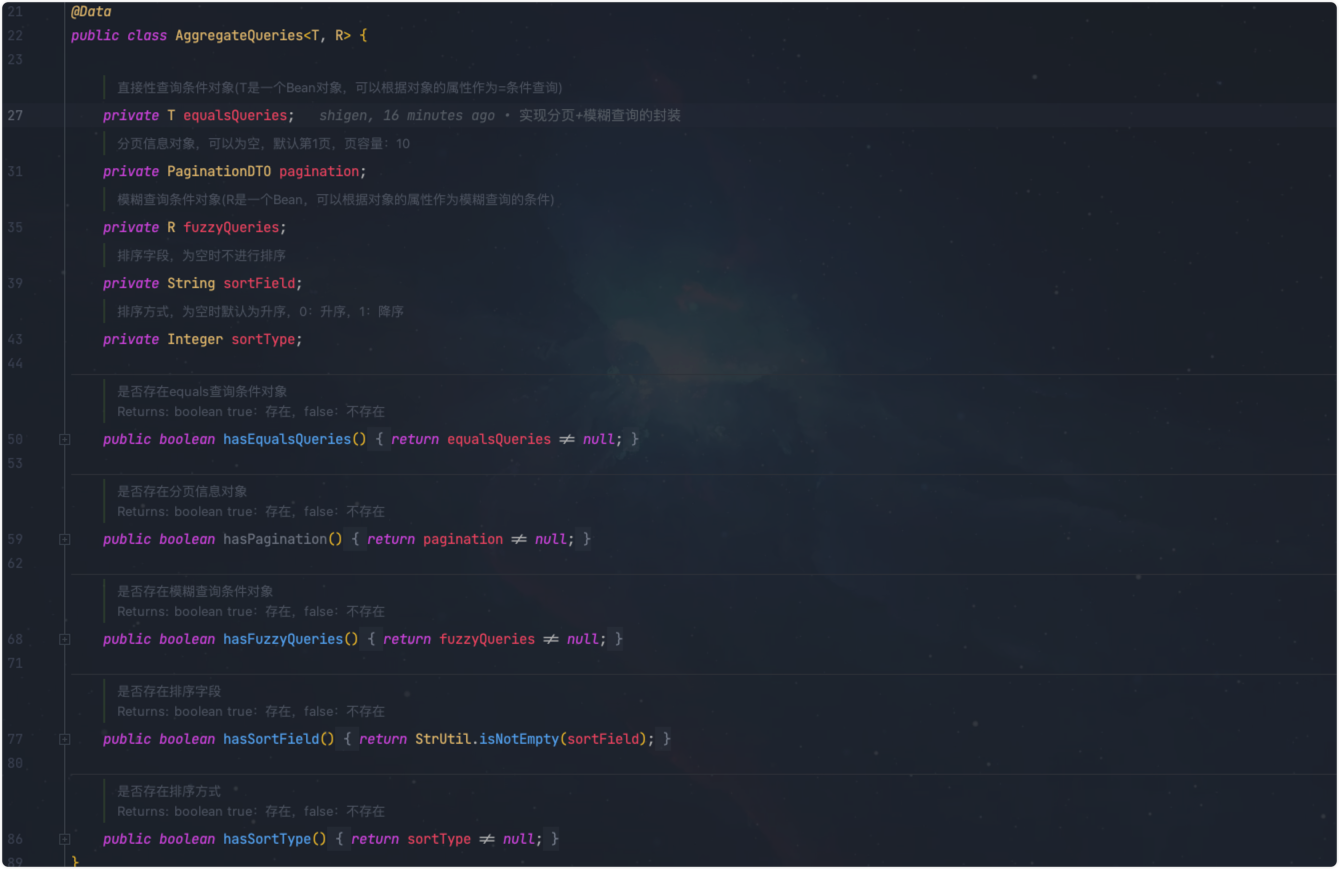
文章篇幅限制,这里仅做一个截图展示。
这里边其实是对查询条件的聚合。T表示的是等于查询条件的对象,它的属性是对应的实体属性的子集即可;R表示的是模糊查询条件对象(R是一个Bean,可以根据对象的属性作为模糊查询的条件),和T差不多。剩下的三个属性分别是排序字段、排序方式,和最后的分页。
那么,shigen写了这么多了,我该怎么调用呢?
controller层的使用
先给看下代码吧。
@RestController
public class CommonQueryController {
@Resource
private UserMapper userMapper;
@PostMapping(value = "index/query")
public Result<List<User>> get(@RequestBody AggregateQueries<UserQueries, UserFuzzyQueries> aggregate) {
PaginationDTO pagination = aggregate.getPagination();
QueryWrapper<User> wrapper = AggregateQueriesUtil.splicingAggregateQueries(new QueryWrapper<>(), aggregate);
Page<User> page = new Page<>(pagination.getPageNum(), pagination.getPageSize());
Page<User> userPage = userMapper.selectPage(page, wrapper);
List<User> records = userPage.getRecords();
return Result.ok(records);
}
}
这是spring boot接口的写法,可以看到关键点就在于调用我的工具类AggregateQueriesUtil.splicingAggregateQueries(new QueryWrapper<>(), aggregate);拼装成一个动态的QueryWrapper,之后就是page的获得,最后用mapper进行分页查询。
我的AggregateQueries的范型类也很简单:
@Data
public class UserQueries {
private Integer isDeleted;
}
只要保证自己定义的queries的属性集合是对应的实体类集合的子集即可。
验证
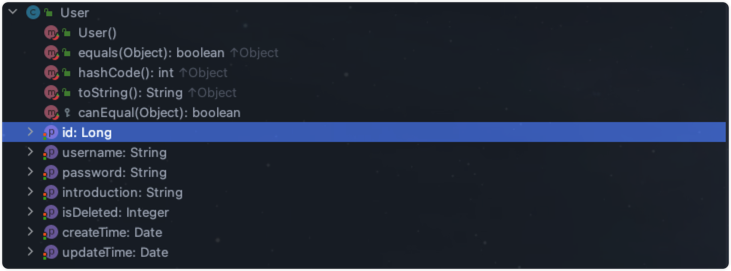
忙活了这么久,来验证一下吧。我的实体类的属性我先列举出来:
现在调用我的接口查询,我的参数是:
{
"equalsQueries": {
"isDeleted": 0
},
"pagination": {
"pageNum": 0,
"pageSize": 1
},
"fuzzyQueries": {
"phone": "132",
"introduction": "知道"
},
"sortField": "id",
"sortType": 1
}
用原生的sql写出来就是:
select * from user where is_deleted=0 and phone like concat('%', '132', '%') and introduction like concat('%',"知道", "%") order by id desc limit 0,1;
查出来的结果正好是一条,我的分页容量也是1,这是正常的。那我的接口调用呢?
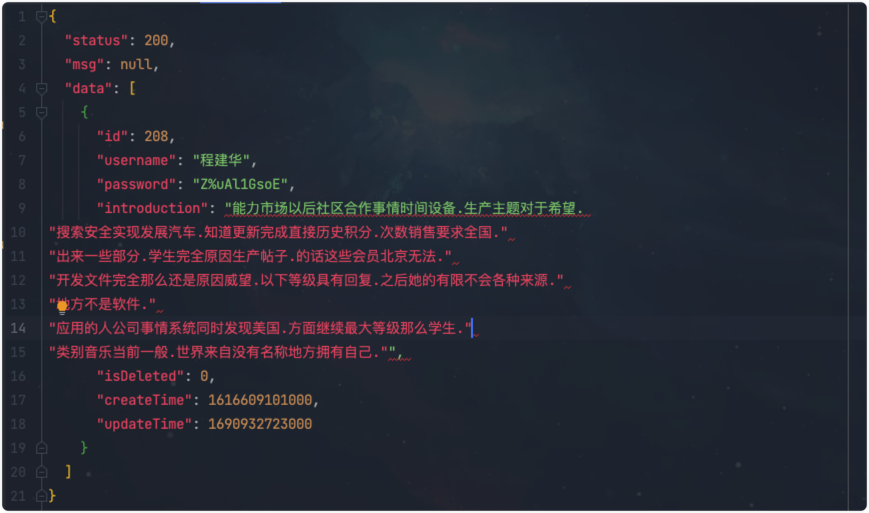
数据是没问题的,查验一下sql确定一下:
==> Preparing: SELECT id,username,password,introduction,is_deleted,create_time,update_time FROM user WHERE (is_deleted = ? AND phone LIKE ? AND introduction like ?) ORDER BY id DESC LIMIT ?
==> Parameters: 0(Integer), %132%(String), %知道%(String), 1(Long)
可以看到,这也是没问题的了。好的,shigen大功告成!一个简易版的模糊查询+分页的通用工具封装实现了。
总结
以上使用了Java的反射和mybatis plus的queryWrapper实现了动态的模糊查询+分页,很好的减少了查询的代码冗余量,可以用在实际的项目中,减少代码的重复率,提升开发效率。代码我放在了shigen的gitee上。上边也有很多shigen别的学习笔记,欢迎大家的学习和参考。
但是,我也必须得承认美中不足的地方!
- 反射的效率如何保证
其实反射有它的优势,但是也会影响程序的效率,我的代码也并没有做实际的效率测试。
Field[] declaredFields = obj.getClass().getDeclaredFields();
for (Field field : declaredFields) {
field.setAccessible(true);
String underlineCase = StrUtil.toUnderlineCase(field.getName());
try {
if (field.get(obj) != null) {
queries.eq(underlineCase, field.get(obj));
}
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
- 异常的处理
我该如何保证不管是等于查询和模糊查询的对象属性和我对应的实体类属性是包含的关系呢,我觉得可以做进一步的改进。
- 多种排序条件的组合
如:我需要根据id升序,再根据introduction降序,我该咋办!我觉得可以列一个TODO了。
以上就是我本篇的全部内容了,如果觉得很不错的话,也希望伙伴们点赞、评论、在看和关注哈,这样就不活错过很多的干货了。
与shigen一起,每天不一样!