- 这里的标签是通过coco-annotator导出的
代码放到百度云链接中了,有需要可以自取,其中包含了一个测试用的标签
使用的时候只需要运行trans.py应该即可,使用的是相对路径,应该不需要修改就可以运行,运行效果如下
运行完毕可以在save中找到相应的标签
- 打开其中一个标签格式如下

0 0.428125 0.382031 0.7375 0.717188 0.209375 0.446875 2.0 0.079687 0.307812 2.0 0.314062 0.526562 2.0 0.207812 0.339062 2.0 0.292187 0.439062 2.0 0.271875 0.259375 2.0 0.367187 0.35 2.0 0.365625 0.142187 2.0 0.451562 0.234375 2.0 0.660937 0.560937 2.0 0.764062 0.715625 2.0
- 这里只支持只有一个类别的情况
使用的时候只需要修改
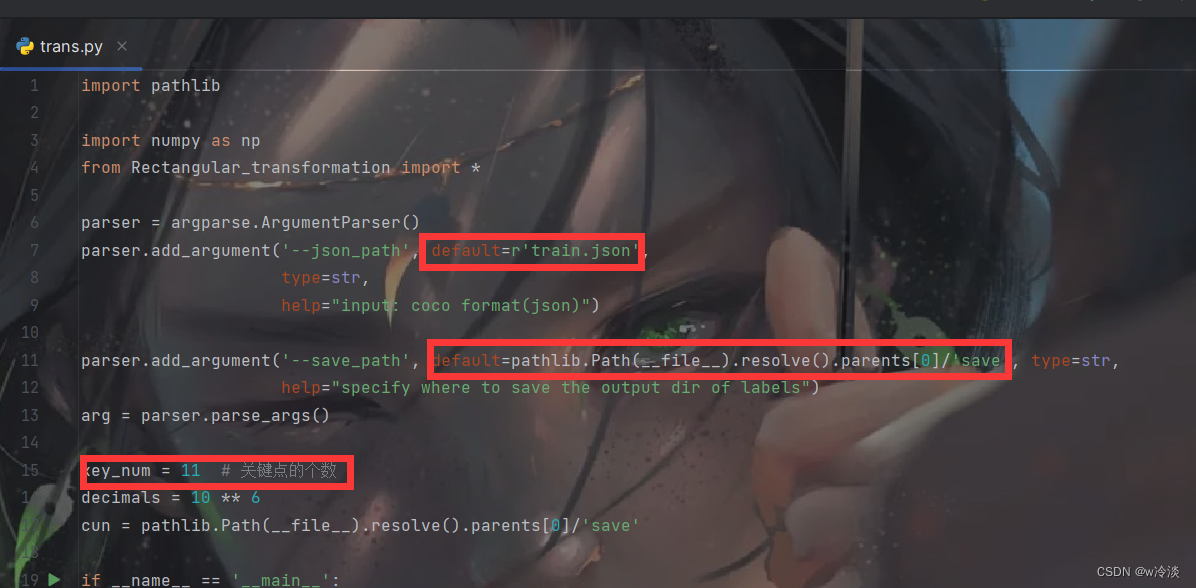
分别是json文件路径,保存的路径,关键点的个数
如果不能使用,请谅解,不通过百度云下载,可以直接复制下面的代码
# trans.py
import pathlib
import numpy as np
from Rectangular_transformation import *
parser = argparse.ArgumentParser()
parser.add_argument('--json_path', default=r'train.json',
type=str,
help="input: coco format(json)")
parser.add_argument('--save_path', default=pathlib.Path(__file__).resolve().parents[0]/'save', type=str,
help="specify where to save the output dir of labels")
arg = parser.parse_args()
key_num = 11 # 关键点的个数
decimals = 10 ** 6
cun = pathlib.Path(__file__).resolve().parents[0]/'save'
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance
ana_txt_save_path = arg.save_path
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {
}
with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:
for i, category in enumerate(data['categories']):
f.write(f"{category['name']}\n")
id_map[category['id']] = i
list_file = open(os.path.join(ana_txt_save_path, 'val.txt'), 'w')
for annotations in tqdm(data['annotations']):
img_width = annotations["width"]
img_height = annotations["height"]
img_id = annotations["image_id"]
keypoints = annotations["keypoints"]
arry_x = np.zeros([key_num , 1])
num_1 = 0
for x in keypoints[0:3*key_num :3]:
arry_x[num_1, 0] = int((x / img_width) * decimals) / decimals
num_1 += 1
arry_y = np.zeros([key_num , 1])
num_2 = 0
for y in keypoints[1:3*key_num :3]:
arry_y[num_2, 0] = int((y / img_height) * decimals) / decimals
num_2 += 1
arry_v = np.zeros([key_num , 1])
num_3 = 0
for v in keypoints[2:3*key_num :3]:
arry_v[num_3, 0] = v
num_3 += 1
list_1 = []
num_4 = 0
for i in range(key_num ):
list_1.append(float(arry_x[num_4]))
list_1.append(float(arry_y[num_4]))
list_1.append(float(arry_v[num_4]))
num_4 += 1
fil = img_id
cun_1 = os.path.join(cun, str(fil))
cun_2 = cun_1 + ".txt"
with open(cun_2, "r") as f:
read_lines = f.readlines()
x_1 = read_lines[0].strip().split(",")
x_2 = x_1 + list_1
list_xin = list(map(str, x_2))
list_xin = " ".join(list_xin)
with open(cun_2, "w") as f:
f.write(list_xin)
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt"
os.chdir(cun)
os.rename(str(img_id) + ".txt", ana_txt_name)
# Rectangular_transformation.py
import json
import os
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--json_path', default=r'train.json',
type=str, help="input: coco format(json)")
parser.add_argument('--save_path', default=r'save', type=str,
help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = round(x * dw, 6)
w = round(w * dw, 6)
y = round(y * dh, 6)
h = round(h * dh, 6)
return (x, y, w, h)
if True:
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {
}
with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:
# 写入classes.txt
for i, category in enumerate(data['categories']):
f.write(f"{category['name']}\n")
id_map[category['id']] = i
list_file = open(os.path.join(ana_txt_save_path, 'val.txt'), 'w')
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt"
f_txt = open(os.path.join(ana_txt_save_path, str(img_id) + ".txt"), 'w')
for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
f_txt.close()
list_file.write('val/%s.jpg\n' % (head))
list_file.close()