文章目录
一、概述
流操作是Java8提供一个重要新特性,它允许开发人员以声明性方式处理集合,其核心类库主要改进了对集合类的API和新增Stream操作。
Stream类中每一个方法都对应集合上的一种操作。将真正的函数式编程引入到Java中,能让代码更加简洁,极大地简化了集合的处理操作,提高了开发的效率和生产力。
同时stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。在Stream中的操作每一次都会产生新的流,内部不会像普通集合操作一样立刻获取值,而是惰性取值,只有等到用户真正需要结果的时候才会执行。
二、集合操作演进对比
1、JDK7传统方式
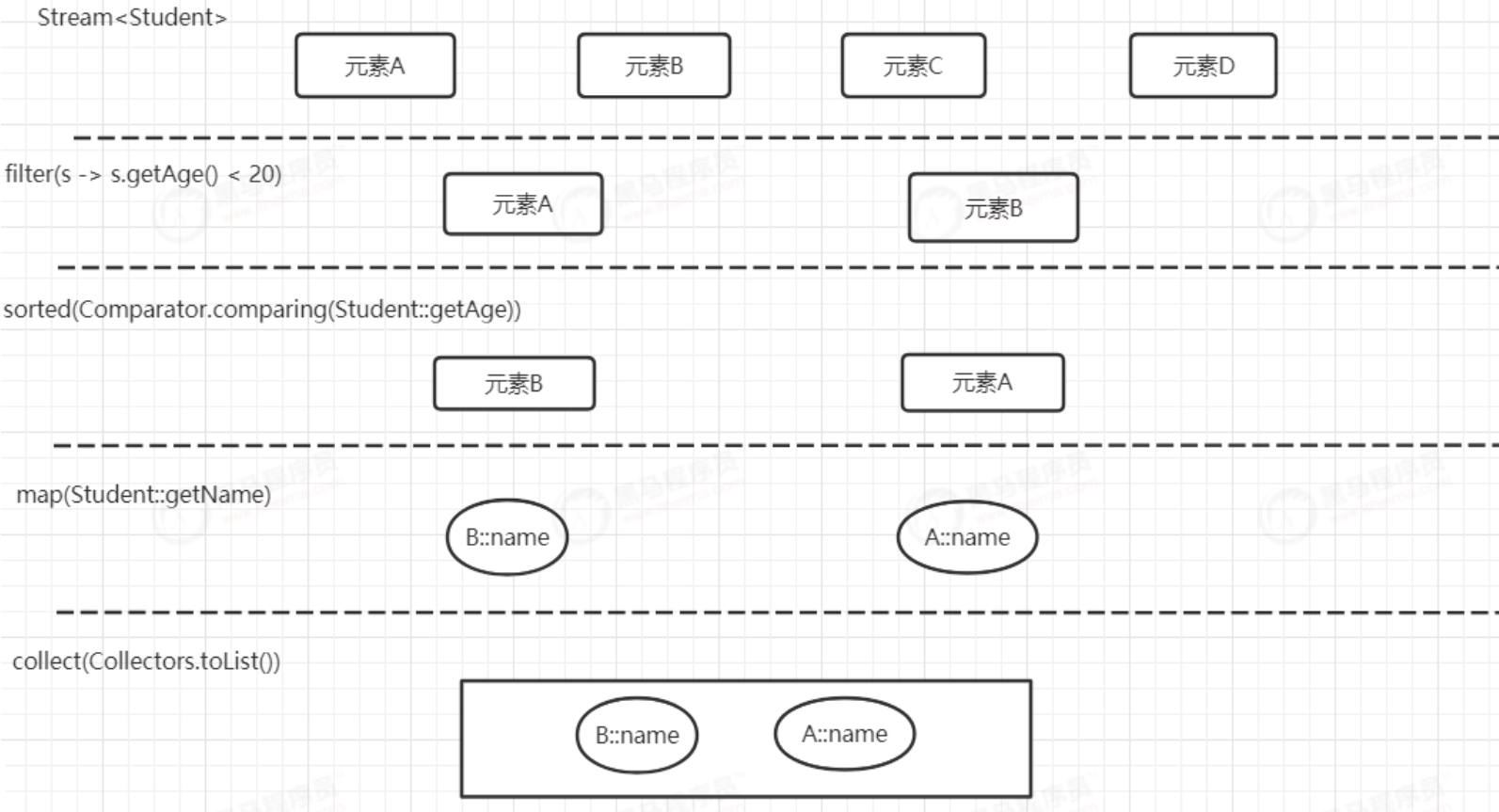
此处以操作学生集合为例,查询年龄小于20岁的学生,并且根据年龄进行排序,得到学生姓名,生成新集合
public class Demo1 {
public static void main(String[] args) {
//java7 查询年龄小于20岁的学生,并且根据年龄进行排序,得到学生姓名,生成新集合
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19));
studentList.add(new Student(1,"李四","M",18));
studentList.add(new Student(1,"王五","F",21));
studentList.add(new Student(1,"赵六","F",20));
//条件筛选
List<Student> result = new ArrayList<>();
for (Student student : studentList) {
if (student.getAge() < 20){
result.add(student);
}
}
//排序
Collections.sort(result, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return Integer.compare(o1.getAge(),o2.getAge());
}
});
//获取学生姓名
List<String> nameList = new ArrayList<>();
for (Student student : result) {
nameList.add(student.getName());
}
System.out.println(nameList.toString());
}
}
上述代码中产生了两个垃圾变量声明,result和nameList,他们两个作用就是作为一个中间数据存储容器。并且整体的操作需要产生多次遍历。
2、JDK8 使用Stream
如何通过Java8的Stream流式处理的话,又会变成什么样子呢?
public class Demo2 {
public static void main(String[] args) {
//java8 查询年龄小于20岁的学生,并且根据年龄进行排序,得到学生姓名,生成新集合
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19));
studentList.add(new Student(1,"李四","M",18));
studentList.add(new Student(1,"王五","F",21));
studentList.add(new Student(1,"赵六","F",20));
List<String> result = studentList.stream()
.filter(s -> s.getAge() < 20) //过滤出年龄小于20岁的学生
.sorted(Comparator.comparing(Student::getAge)) // 根据年龄进行排序
.map(Student::getName) //得到学生姓名
.collect(Collectors.toList());//生成新集合
System.out.println(result);
}
}
通过上述代码的执行,可以发现无需再去定义过多的冗余变量。我们可以将多个操作组成一个调用链,形成数据处理的流水线。在减少代码量的同时也更加的清晰易懂。
并且对于现在调用的方法,本身都是一种高层次构件,与线程模型无关。因此在并行使用中,开发者们无需再去操心线程和锁了。Stream内部都已经做好了。
3、小结

如果刚接触流操作的话,可能会感觉不太舒服。其实理解流操作的话可以对比数据库操作。把流的操作理解为对数据库中数据的查询操作:
集合 = 数据表
元素 = 表中的每条数据
属性 = 每条数据的列
流API = sql查询
以上面案例为例,转换为sql的话:
SELECT name FROM student WHERE age < 20 ORDER BY age;
三、流实现思想
1、外部迭代
在java8之前,在使用集合时,无非就是在集合上进行迭代,然后处理每一个元素。以统计学生总数为例:
public class Demo3 {
//统计学生总数
public static void main(String[] args) {
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19));
studentList.add(new Student(1,"李四","M",18));
studentList.add(new Student(1,"王五","F",21));
studentList.add(new Student(1,"赵六","F",20));
int count = 0;
for (Student student : studentList)
{
count++;
}
System.out.println(count);
}
}
这种方式对于功能实现没有任何问题,但是它也存在一些问题:
1)for 循环是串行的,而且必须按照集合中元素的顺序进行依次处理,要想改造成并行的话,需要修改每个for循环;
2)使用是及早求值,返回的是另一个值或空。使用性能上存在一点点的瑕疵;
3)易读性不好,如果for中嵌套大量循环与功能代码,阅读起来简直是灾难;

根据上图的说明,所有的集合迭代所及都是在我们自己编写的代码中,所以这种显式的方式称之为外部迭代。其主要关注于数据本身。并且一般都是串行的。
2、内部迭代
而内部迭代来说,它所操作的就是不是一个集合了,而是一个流。它会将所有的操作融合在流中,由其在内部进行处理,这种隐式的方式称之为内部迭代。
并且内部迭代支持并行处理,更利于集合操作的性能优化。其关注与对数据的计算。
四、函数式编程
五、流操作详解
1、流的分类
(1)中间操作
基本上,一个参数的是无状态操作,两个参数的是有状态操作。
所有操作是链式调用, 一个元素只迭代一次,每一个中间操作返回一个新的流。
并行流中,有状态操作会把无状态操作截断,单独处理(有状态操作需要依赖于其他元素,无状态操作每个元素是独立的)。
无状态操作:
map/mapToxxx
flatMap/flatMapToxxx
filter
peek
unordered
有状态操作:
distinct
sorted
limit/skip
(2)终止操作
终止操作返回流的最终执行结果,这个流就结束了。
非短路操作:
forEach/forEachOrdered
collect/toArray
reduce
min/max/count
短路操作:
findFirse/findAny
allMatch/anyMatch/noneMatch
2、构建流
(1)基于集合创建流
集合自带的stream方法,可以返回一个流。
List<String> list = new ArrayList<>();
// 从集合创建
list.stream();
list.parallelStream(); // 并行流
(2)基于值创建流
在Stream中提供了一个静态方法of,它可以接收任意数量参数,显式的创建一个流。并且会根据传入的参数类型,构建不同泛型的流。
Stream<String> stringStream = Stream.of("1", "2", "3");
stringStream.forEach(v-> System.out.println(v));
Stream<Object> objectStream = Stream.of("1", 2, true, new St());
其内部就是基于Arrays中的stream方法将传入的多个参数转换为数组,然后创建流,并遍历数组,将每一个元素放入流中。
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
(3)基于数组创建流
与基于值创建流相同。
Integer[] numbers = new Integer[]{
1,2,3,4,5,6};
Stream<Integer> stream = Arrays.stream(numbers);
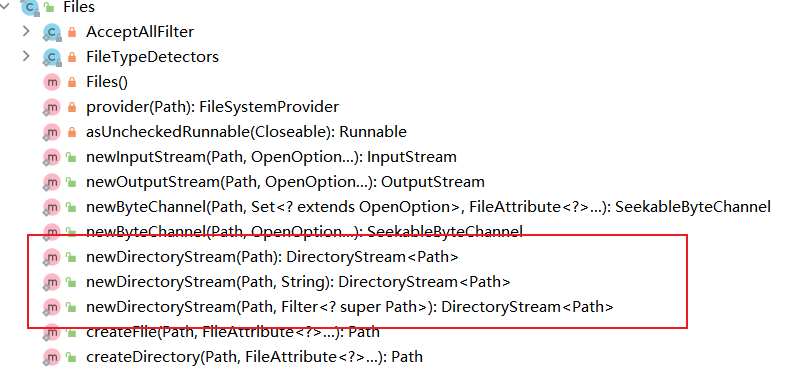
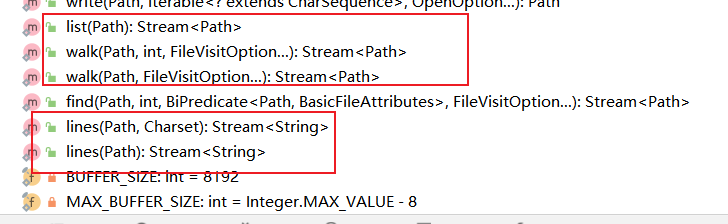
(4)基于文件创建流
在Java中提供了Files类,该类中提供了一些对于文件操作的相关方法。可以看下面对于Files类中部分方法截图
public class FileDemo {
public static void main(String[] args) throws IOException {
//获取所有的文件列表信息
//Files.list(Paths.get("D:\\workspace\\demo")).forEach(path-> System.out.println(path));
Files.list(Paths.get("D:\\workspace\\demo")).forEach(path-> {
System.out.println(path);
//读取每一个文件中的内容信息
try {
Files.lines(path).forEach(content-> System.out.println(content));
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
3、筛选
对于集合的操作,经常性的会涉及到对于集中符合条件的数据筛选,Stream中对于数据筛选两个常见的API:filter(过滤)、distinct(去重)。
(1)基于filter()实现数据过滤
(①) 使用案例
该方法会接收一个返回boolean的函数作为参数,最终返回一个包括所有符合条件元素的流。
//获取所有年龄20岁以下的学生
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19));
studentList.add(new Student(1,"李四","M",18));
studentList.add(new Student(1,"王五","F",21));
studentList.add(new Student(1,"赵六","F",20));
//java7
List<Student> resultList = new ArrayList<>();
for (Student student : studentList) {
if (student.getAge() < 20){
resultList.add(student);
}
}
//java8 Stream
//中间操作
Stream<Student> studentStream = studentList.stream()
.filter(s -> s.getAge() < 20);
//终端操作
List<Student> list = studentStream.collect(Collectors.toList());
// 可以合并为一行
//List<Student> result = studentList.stream().filter(s -> s.getAge() < 20).collect(Collectors.toList());
System.out.println(list);
//获取所有及格学生的信息
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19,true));
studentList.add(new Student(1,"李四","M",18,false));
studentList.add(new Student(1,"王五","F",21,true));
studentList.add(new Student(1,"赵六","F",20,false));
//java7写法
List<Student> resultList = new ArrayList<>();
for (Student student : studentList) {
if (student.getIsPass()){
resultList.add(student);
}
}
//Stream
List<Student> result = studentList.parallelStream().filter(Student::getIsPass).collect(Collectors.toList());
System.out.println(result);
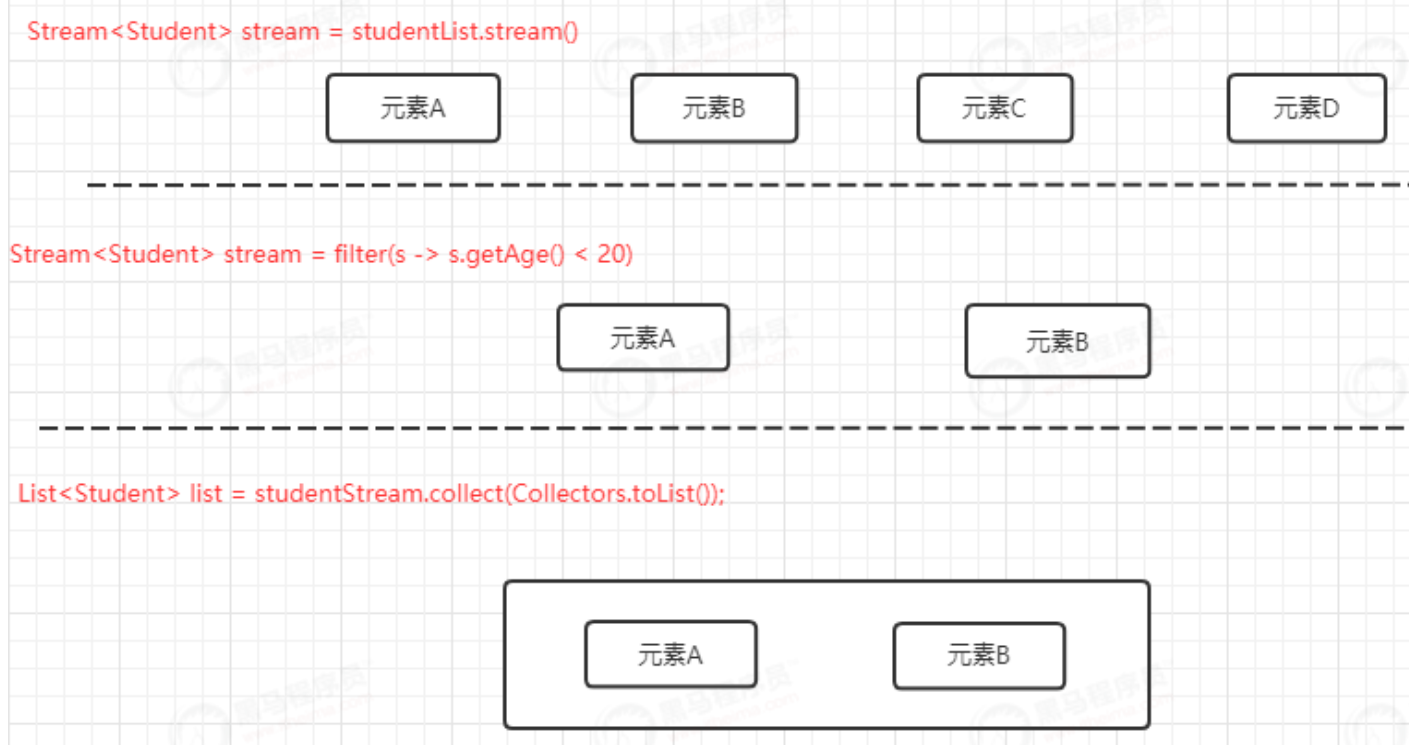
(②) 源码分析
我们可以看到filter方法接收了Predicate函数式接口。
filter方法是一个中间操作,返回一个无状态的中间操作的基类StatelessOp,并且会根据传入的Predicate判断元素是否会流入下一个流。
// java.util.stream.Stream#filter
Stream<T> filter(Predicate<? super T> predicate);
// java.util.stream.ReferencePipeline#filter
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u)) // 传入的判断
downstream.accept(u);
}
};
}
};
}
(2)基于distinct实现数据去重
(①) 使用案例
在java7之前对集合中的内容去重,有多种的实现方式,如通过set去重、遍历后赋值给另一个集合
public class DistinctDemo {
public static void main(String[] args) {
//对数据模2后结果去重
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 1, 2, 3, 4);
/* List<Integer> integers = demo1(numberList);
System.out.println(integers);
List<Integer> result = demo2(numberList);
System.out.println(result);*/
List<Integer> result = demo3(numberList);
System.out.println(result);
}
/**
* java7 将一个集合的值赋给另一个集合
* @param numberList
* @return
*/
public static List<Integer> demo1(List<Integer> numberList){
List<Integer> resultList = new ArrayList<>();
for (Integer number : numberList) {
if (number % 2 ==0){
resultList.add(number);
}
}
List<Integer> newList = new ArrayList<>();
for (Integer number : numberList) {
if (!newList.contains(number)){
newList.add(number);
}
}
return newList;
}
/**
* java7 利用set去重
* @param numberList
* @return
*/
public static List<Integer> demo2(List<Integer> numberList){
List<Integer> newList = new ArrayList();
Set set = new HashSet();
for (Integer number : numberList) {
if (number % 2 ==0){
if (set.add(number)){
newList.add(number);
}
}
}
return newList;
}
/**
* 通过stream中的distinct完成数据去重
* @param numberList
* @return
*/
public static List<Integer> demo3(List<Integer> numberList){
List<Integer> result = numberList.stream()
.filter(n -> n % 2 == 0)
.distinct() // 去重操作
.collect(Collectors.toList());
return result;
}
}
注意!要对对象进行去重的话,还需要在对象内部重写,
hashCode()和equals()方法才可以实现去重。
(②) 源码解析
根据其源码,我们可以知道在distinct()内部,makeRef方法是基于LinkedHashSet对流中数据进行去重,并最终返回一个新的流。
// java.util.stream.ReferencePipeline#distinct
@Override
public final Stream<P_OUT> distinct() {
return DistinctOps.makeRef(this);
}
4、切片
(1)基于limit()实现数据截取
(①) 使用案例
该方法会返回一个不超过给定长度的流。
List<Integer> numberList= Arrays.asList(1, 2, 3, 4, 1, 2, 3, 4);
List<Integer> result = numberList.stream().limit(5).collect(Collectors.toList());
System.out.println(result); // [1, 2, 3, 4, 1]
(②) 源码分析
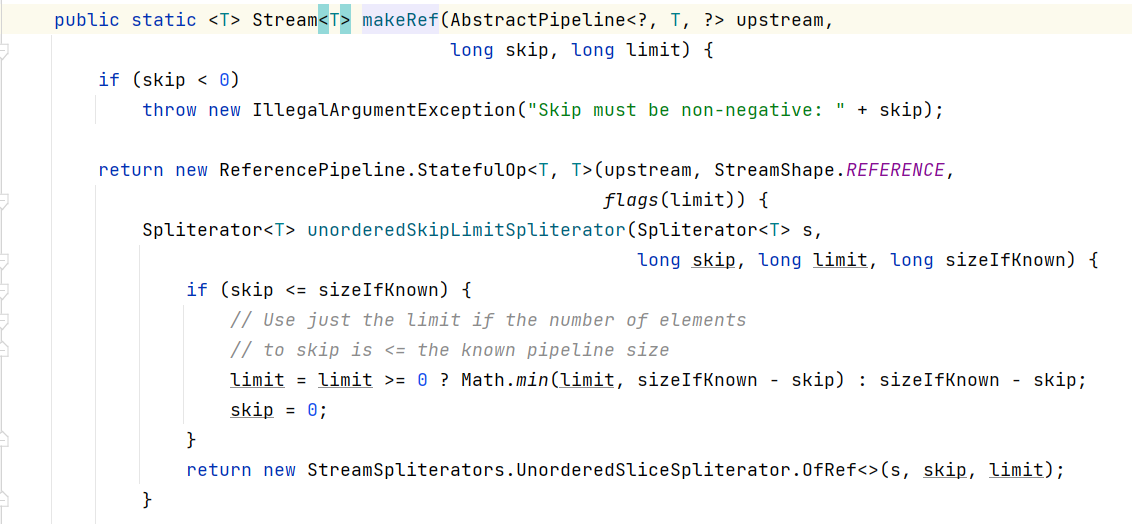
对于limit方法的实现,它会接收截取的长度,如果该值小于0,则抛出异常,否则会继续向下调用SliceOps.makeRef()。
该方法中this代表当前流,skip代表需要跳过元素,比方说本来应该有4个元素,当跳过元素值为2,会跳过前面两个元素,获取后面两个。
maxSize代表要截取的长度
// java.util.stream.ReferencePipeline#limit
@Override
public final Stream<P_OUT> limit(long maxSize) {
if (maxSize < 0)
throw new IllegalArgumentException(Long.toString(maxSize));
return SliceOps.makeRef(this, 0, maxSize);
}
在makeRef方法中的unorderedSkipLimitSpliterator()中接收了四个参数Spliterator,skip(跳过个数)、limit(截取个数)、sizeIfKnown(已知流大小)。如果跳过个数小于已知流大小,则判断跳过个数是否大于0,如果大于则取截取个数或已知流大小-跳过个数的两者最小值,否则取已知流大小-跳过个数的结果,作为跳过个数。最后对集合基于跳过个数和截取个数进行切割。
(2)基于skip()实现数据跳过
(①) 使用案例
使用skip()对结果只获取后几个。其与limit()的使用是相辅相成的。
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 1, 2, 3, 4);
List<Integer> result = numberList.stream().skip(2).limit(5).collect(Collectors.toList());
System.out.println(result); // [3, 4, 1, 2, 3]
(②) 源码分析
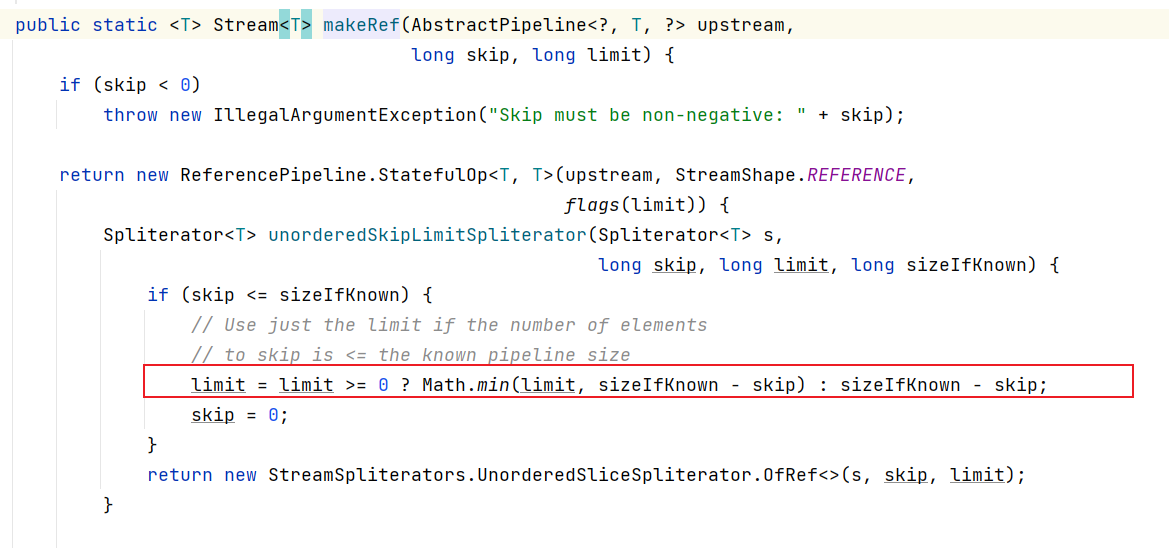
在skip方法中接收的n代表的是要跳过的元素个数,如果n小于0,抛出非法参数异常,如果n等于0,则返回当前流。如果n小于0,才会调用makeRef()。同时指定limit参数为-1。
@Override
public final Stream<P_OUT> skip(long n) {
if (n < 0)
throw new IllegalArgumentException(Long.toString(n));
if (n == 0)
return this;
else
return SliceOps.makeRef(this, n, -1);
}
此时可以发现limit和skip都会进入到该方法中,在确定limit值时,如果limit<0,则获取已知集合大小长度-跳过的长度。最终进行数据切割。
5、映射
(1)基于map实现元素映射
在对集合进行操作的时候,我们经常会从某些对象中选择性的提取某些元素的值,就像编写sql一样,指定获取表中特定的数据列。
-- 指定获取特定列
SELECT name FROM student;
在Stream API中也提供了类似的方法,map()。它接收一个函数作为方法参数,这个函数会被应用到集合中每一个元素上,并最终将其映射为一个新的元素。
(①) 使用案例
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19,true));
studentList.add(new Student(2,"李四","M",18,false));
studentList.add(new Student(3,"王五","F",21,true));
studentList.add(new Student(4,"赵六","F",20,false));
//获取每一个学生的名字,并形成一个新的集合
List<Integer> nameList = studentList.stream()
.map(Student::getName)
.map(String::length) //也可以继续 向下获取每一个名称的长度
.collect(Collectors.toList());
System.out.println(nameList);
//提出name信息,转换为一个新的集合
List<String> result = studentList.stream().map(Student::getName).collect(Collectors.toList());
System.out.println(result); // [张三, 李四, 王五, 赵六]
List<String> numberList = Arrays.asList("1","2","3","4");
int sum = numberList.stream().mapToInt(s -> Integer.parseInt(s)).sum();
System.out.println(sum); // 10
(②) 源码分析
将当前流给定函数中的元素,包含到一个新的流中进行返回。
其会接收一个Function函数式接口,内部对Function函数式接口中的apply方法进行实现,接收一个对象,返回另外一个对象,并把这个内容存入当前流中,最后返回。
// java.util.stream.ReferencePipeline#map
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
6、匹配
在日常开发中,有时还需要判断集合中某些元素是否匹配对应的条件,如果有的话,在进行后续的操作。在Stream API中也提供了相关方法供我们进行使用,如anyMatch、allMatch等。他们对应的就是&&和||运算符。
(1)基于anyMatch()判断条件至少匹配一个元素
(①) 使用案例
anyMatch()主要用于判断流中是否至少存在一个符合条件的元素,它会返回一个boolean值,并且对于它的操作,一般叫做短路求值。
对于集合的一些操作,我们无需处理整个集合就能得到结果,比方说通过&&或者||连接一个判断条件,这就是短路。
对于流来说,某些操作不用操作整个流就可以得到结果。
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19,true));
studentList.add(new Student(2,"李四","M",18,false));
studentList.add(new Student(3,"王五","F",21,true));
studentList.add(new Student(4,"赵六","F",20,false));
if (studentList.stream().anyMatch(s->s.getAge()<20)){
System.out.println("有符合条件的数据");
}
根据上述例子可以看到,当流中只要有一个符合条件的元素,则会立刻中止后续的操作,立即返回一个布尔值,无需遍历整个流。
(②) 源码分析
// java.util.stream.ReferencePipeline#anyMatch
@Override
public final boolean anyMatch(Predicate<? super P_OUT> predicate) {
return evaluate(MatchOps.makeRef(predicate, MatchOps.MatchKind.ANY));
}
内部实现会调用makeRef(),其接收一个Predicate函数式接口,并接收一个枚举值,该值代表当前操作执行的是ANY。
enum MatchKind {
/** Do all elements match the predicate? */
ANY(true, true),
/** Do any elements match the predicate? */
ALL(false, false),
/** Do no elements match the predicate? */
NONE(true, false);
private final boolean stopOnPredicateMatches;
private final boolean shortCircuitResult;
private MatchKind(boolean stopOnPredicateMatches,
boolean shortCircuitResult) {
this.stopOnPredicateMatches = stopOnPredicateMatches;
this.shortCircuitResult = shortCircuitResult;
}
}
如果test()抽象方法执行返回值==MatchKind中any的stopOnPredicateMatches,则将stop中断置为true,value也为true。并最终进行返回。无需进行后续的流操作。
// java.util.stream.MatchOps#makeRef
publicstatic <T> TerminalOp<T, Boolean> makeRef(Predicate<? super T> predicate,
MatchKind matchKind) {
Objects.requireNonNull(predicate);
Objects.requireNonNull(matchKind);
class MatchSink extends BooleanTerminalSink<T> {
MatchSink() {
super(matchKind);
}
@Override
public void accept(T t) {
if (!stop && predicate.test(t) == matchKind.stopOnPredicateMatches) {
stop = true;
value = matchKind.shortCircuitResult;
}
}
}
return new MatchOp<>(StreamShape.REFERENCE, matchKind, MatchSink::new);
}
(2)基于allMatch()判断条件是否匹配所有元素
(①) 使用案例
allMatch()的工作原理与anyMatch()类似,但是anyMatch执行时,只要流中有一个元素符合条件就会返回true,而allMatch会判断流中是否所有条件都符合条件,全部符合才会返回true。
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19,true));
studentList.add(new Student(2,"李四","M",18,true));
studentList.add(new Student(3,"王五","F",21,true));
studentList.add(new Student(4,"赵六","F",20,false));
if (studentList.stream().allMatch(Student::getIsPass)){
System.out.println("所有的学生都及格");
}else{
System.out.println("至少有一个学生不及格");
}
7、查找
对于集合操作,有时需要从集合中查找中符合条件的元素,Stream中也提供了相关的API,findAny()和findFirst(),他俩可以与其他流操作组合使用。findAny用于获取流中随机的某一个元素,findFirst用于获取流中的第一个元素。至于一些特别的定制化需求,则需要自行实现。
(1)基于findAny()查找元素
(①) 使用案例
findAny用于获取流中随机的某一个元素,并且利用短路在找到结果时,立即结束。
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",18,true));
studentList.add(new Student(2,"李四","M",19,true));
studentList.add(new Student(3,"王五","F",21,true));
studentList.add(new Student(4,"赵六1","F",15,false));
studentList.add(new Student(5,"赵六2","F",16,false));
studentList.add(new Student(6,"赵六3","F",17,false));
studentList.add(new Student(7,"赵六4","F",18,false));
studentList.add(new Student(8,"赵六5","F",19,false));
for (int i = 0; i < 1000; i++) {
Optional<Student> optional = studentList.stream().filter(s -> s.getAge() < 20).findAny();
if (optional.isPresent()){
Student student = optional.get();
System.out.println(student);
}
}
根据上述例子的运行结果,可以发现。它最终获取到的是第一个符合条件的元素,如果让它循环多次的话,是什么结果呢?
(②) 源码分析
根据这一段源码介绍,findAny对于同一数据源的多次操作会返回不同的结果。但是,我们现在的操作是串行的,所以在数据较少的情况下,一般会返回第一个结果,但是如果在并行的情况下,那就不能确保返回的是第一个了。这种设计主要是为了获取更加高效的性能。
// java.util.stream.ReferencePipeline#findAny
@Override
public final Optional<P_OUT> findAny() {
return evaluate(FindOps.makeRef(false));
}
// 在该方法中,主要用于判断对于当前的操作执行并行还是串行。
// java.util.stream.AbstractPipeline#evaluate(java.util.stream.TerminalOp<E_OUT,R>)
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
在该方法中的wrapAndCopyInto()内部做的会判断流中是否存在符合条件的元素,如果有的话,则会进行返回。结果最终会封装到Optional中的IsPresent中。

根据上面的解析可以,得知,当为串行流且数据较少时,获取的结果一般为流中第一个元素,但是当为并流行的时候,则会随机获取。请看下面测试:
此处使用了并行流,根据结果可以看到,是随机进行获取的。
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",18,true));
studentList.add(new Student(2,"李四","M",19,true));
studentList.add(new Student(3,"王五","F",21,true));
studentList.add(new Student(4,"赵六1","F",15,false));
studentList.add(new Student(5,"赵六2","F",16,false));
studentList.add(new Student(6,"赵六3","F",17,false));
studentList.add(new Student(7,"赵六4","F",18,false));
studentList.add(new Student(8,"赵六5","F",19,false));
for (int i = 0; i < 1000; i++) {
Optional<Student> optional = studentList.parallelStream().filter(s -> s.getAge() < 20).findAny();
if (optional.isPresent()){
Student student = optional.get();
System.out.println(student);
}
}
(2)基于findFirst()查找元素
findFirst使用原理与findAny类似,但不管是在并行还是串行,指定返回流中的第一个元素。
// 此处不管使用串行流还是并行流,得到的都是流中的第一个元素。
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",18,true));
studentList.add(new Student(2,"李四","M",19,true));
studentList.add(new Student(3,"王五","F",21,true));
studentList.add(new Student(4,"赵六1","F",15,false));
studentList.add(new Student(5,"赵六2","F",16,false));
studentList.add(new Student(6,"赵六3","F",17,false));
studentList.add(new Student(7,"赵六4","F",18,false));
studentList.add(new Student(8,"赵六5","F",19,false));
for (int i = 0; i < 1000; i++) {
Optional<Student> optional = studentList.stream().filter(s -> s.getAge() < 20).findFirst();
if (optional.isPresent()){
Student student = optional.get();
System.out.println(student);
}
}
8、归约
我们经常会涉及对元素进行统计计算之类的操作,如求和、求最大值、最小值等,从而返回不同的数据结果。
(1)基于reduce()进行累积求和
(①) 使用案例
当求总和时,在java7中的写法思想,一般是如下面样子的:
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
numbers.add(6);
numbers.add(7);
int sum =0;
for (Integer number : numbers) {
sum+=number;
}
System.out.println(sum);
对numbers数组中的每一个元素进行取出,反复迭代求出最终的结果,这种操作就是一个归约操作:将多个值经过操作或计算来得到一个最终结果。
那么通过Stream可以如何实现上述操作呢?如下面代码所示:
// 通过Stream实现累加
Integer reduce = numbers.stream().reduce(0, (a, b) -> a + b);
// 优化:Integer类中提供了sum方法,用于对两个数求和,这里我们可以直接基于lambda方法调用的形式来使用
Integer reduce = numbers.stream().reduce(0, Integer::sum);
// 优化:加上判空
Optional<Integer> optional = numbers.stream().reduce(Integer::sum);
if (optional.isPresent()){
Integer integer = optional.get();
System.out.println(integer);
}
(②) 源码分析:两个参数的reduce方法
// identity相当于初始化值。
// accumulator相当于当前做的操作
@Override
public final P_OUT reduce(final P_OUT identity, final BinaryOperator<P_OUT> accumulator) {
return evaluate(ReduceOps.makeRef(identity, accumulator, accumulator));
}
// 对于流中元素的操作,当执行第一个元素,会进入begin方法,将初始化的值给到state,state就是最后的返回结果。并执行accept方法,对state和第一个元素根据传入的操作,对两个值进行计算。并把最终计算结果赋给state。
// 当执行到流中第二个元素,直接执行accept方法,对state和第二个元素对两个值进行计算,并把最终计算结果赋给state。后续依次类推。
// java.util.stream.ReduceOps#makeRef(U, java.util.function.BiFunction<U,? super T,U>, java.util.function.BinaryOperator<U>)
public static <T, U> TerminalOp<T, U>
makeRef(U seed, BiFunction<U, ? super T, U> reducer, BinaryOperator<U> combiner) {
Objects.requireNonNull(reducer);
Objects.requireNonNull(combiner);
class ReducingSink extends Box<U> implements AccumulatingSink<T, U, ReducingSink> {
@Override
public void begin(long size) {
state = seed;
}
@Override
public void accept(T t) {
state = reducer.apply(state, t);
}
@Override
public void combine(ReducingSink other) {
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, U, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
};
}
// 可以按照下述代码进行理解
T result = identity;
for (T element : this stream){
result = accumulator.apply(result, element)
}
return result;
(③) 源码分析:一个参数的reduce方法
// java.util.stream.ReferencePipeline#reduce(java.util.function.BinaryOperator<P_OUT>)
@Override
public final Optional<P_OUT> reduce(BinaryOperator<P_OUT> accumulator) {
return evaluate(ReduceOps.makeRef(accumulator));
}
// 在这部分实现中,对于匿名内部类中的empty相当于是一个开关,state相当于结果。
// 对于流中第一个元素,首先会执行begin()将empty置为true,state为null。接着进入到accept(),判断empty是否为true,如果为true,则将empty置为false,同时state置为当前流中第一个元素,当执行到流中第二个元素时,直接进入到accpet(),判断empty是否为true,此时empty为false,则会执行apply(),对当前state和第二个元素进行计算,并将结果赋给state。后续依次类推。
// 当整个流操作完之后,执行get(), 如果empty为true,则返回一个空的Optional对象,如果为false,则将最后计算完的state存入Optional中。
// java.util.stream.ReduceOps#makeRef(java.util.function.BinaryOperator<T>)
public static <T> TerminalOp<T, Optional<T>>
makeRef(BinaryOperator<T> operator) {
Objects.requireNonNull(operator);
class ReducingSink
implements AccumulatingSink<T, Optional<T>, ReducingSink> {
private boolean empty;
private T state;
public void begin(long size) {
empty = true;
state = null;
}
@Override
public void accept(T t) {
if (empty) {
empty = false;
state = t;
} else {
state = operator.apply(state, t);
}
}
@Override
public Optional<T> get() {
return empty ? Optional.empty() : Optional.of(state);
}
@Override
public void combine(ReducingSink other) {
if (!other.empty)
accept(other.state);
}
}
return new ReduceOp<T, Optional<T>, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
};
}
// 可以按照下述代码进行理解:
boolean flag = false;
T result = null;
for (T element : this stream) {
if (!flag) {
flag = true;
result = element;
}else{
result = accumulator.apply(result, element);
}
}
return flag ? Optional.of(result) : Optional.empty();
(2)获取流中元素的最大值
(①) 使用案例
// Integer除了提供sum()外,还提供了其他的操作,如获取最大值,获取最小值等。基于上述reduce的讲解,可以做如下实现:
//获取最大值
Optional<Integer> maxOptional = numbers.stream().reduce(Integer::max);
// 优化:判空
Optional<Integer> maxOptional = numbers.stream().max(Integer::compareTo);
if (maxOptional.isPresent()){
System.out.println(maxOptional.get());
}
(②) 源码分析
// 该方法会接收Comparator函数式接口。
@Override
public final Optional<P_OUT> max(Comparator<? super P_OUT> comparator) {
return reduce(BinaryOperator.maxBy(comparator));
}
// 其内部实现原理很简单,循环的对流中两个元素进行比较。
public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
(3)获取流中元素的最小值
(①) 使用案例
//获取最小值
Optional<Integer> minOptional = numbers.stream().min(Integer::compareTo);
System.out.println(minOptional.get());
(②) 源码分析
// 接收Comparator函数式接口
public static <T> BinaryOperator<T> minBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;
}
9、收集器
(1)收集器简介
通过使用收集器,可以让代码更加方便的进行简化与重用。其内部主要核心是通过Collectors完成更加复杂的计算转换,从而获取到最终结果。并且Collectors内部提供了非常多的常用静态方法,直接拿来就可以了。比方说:toList。
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",18,90,true));
studentList.add(new Student(2,"李四","M",18,55,false));
studentList.add(new Student(3,"王五","F",20,100,true));
studentList.add(new Student(4,"赵六","F",20,40,false));
//java7 根据学生的性别对学生信息进行分组,并最终完成数据返回 Map<String,List<Student>>
Map<String,List<Student>> map = new HashMap<>();
for (Student student : studentList) {
String sex = student.getSex();
if (map.get(sex)==null){
List<Student> list = new ArrayList<>();
list.add(student);
map.put(sex,list);
}else{
List<Student> list = map.get(sex);
list.add(student);
}
}
System.out.println(map);
// Stream
Map<String, List<Student>> map = studentList.stream().collect(Collectors.groupingBy(Student::getSex));
System.out.println(map);
(2)结果转为List、Set、Collection

Set<Integer> ages = students.stream().map(Student::getAge)
.collect(Collectors.toCollection(TreeSet::new));
(2)通过counting()统计集合总数
//集合总数统计获取
Long result = studentList.stream().collect(Collectors.counting());
// 简写
long count = studentList.stream().count();
System.out.println(count);
// counting()中内部做的调用reducing()进行数据汇总,源码如下:
public static <T> Collector<T, ?, Long>
counting() {
return reducing(0L, e -> 1L, Long::sum);
}
(3)通过maxBy()与minBy()获取最大值最小值
//获取集合中学生年龄的最大值与最小值
Optional<Student> optional = studentList.stream().collect(Collectors.maxBy(Comparator.comparing(Student::getAge)));
if (optional.isPresent()){
System.out.println(optional.get());
}
// 优化
Optional<Student> optional = studentList.stream().max(Comparator.comparing(Student::getAge));
Optional<Student> min = studentList.stream().min(Comparator.comparing(Student::getAge));
if (optional.isPresent()){
System.out.println(optional.get());
}
// maxBy()中做的同样是调用reducing方法在内部进行数据比较,源码如下:
public static <T> Collector<T, ?, Optional<T>>
maxBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.maxBy(comparator));
}
(4)通过summingInt()进行数据汇总
//获取所有学生的年龄并汇总
Integer collect = studentList.stream().collect(Collectors.summingInt(Student::getAge));
// 优化
int sum = studentList.stream().mapToInt(Student::getAge).sum();
System.out.println(sum);
System.out.println(collect);
(5)通过averagingInt()进行平均值获取
//获取集合中所有学生年龄的平均值
Double collect1 = studentList.stream().collect(Collectors.averagingInt(Student::getAge));
// 优化
OptionalDouble average = studentList.stream().mapToDouble(Student::getAge).average();
if (average.isPresent()){
System.out.println(average.getAsDouble());
}
System.out.println(collect1);
(6)复杂结果返回
Collectors提供了相关静态方法进行解决,这三个方法可以,返回的都是收集器。其内部已经包含了多种结果内容
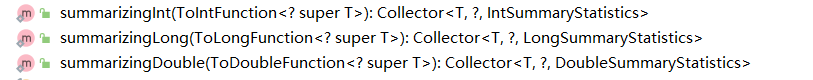
// summarizingInt方法返回了IntSummaryStatistics类,其内部提供了相关getter方法用于获取汇总值、总和、最大值最小值等方法,直接调用即可
IntSummaryStatistics collect = studentList.stream().collect(Collectors.summarizingInt(Student::getAge));
long count = collect.getCount();
long sum = collect.getSum();
int max = collect.getMax();
int min = collect.getMin();
double average = collect.getAverage();
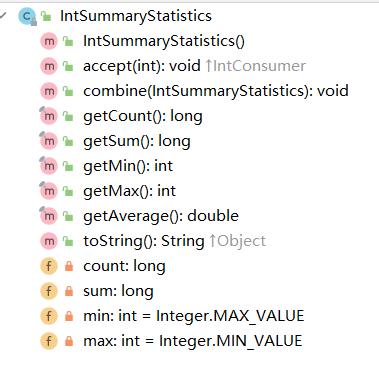
对于另外的summarizingDouble()和summarizingLong()使用方式都是相同的。只不过他们适用于收集属性数据类型为double和long而已。
(7)通过joining()进行数据拼接
//拼接所有的学生姓名,用,分割
String collect = studentList.stream().map(Student::getName).collect(Collectors.joining(","));
System.out.println(collect);
这种方式相当于将流中每一个元素的name属性获取映射,内部通过StringBuilder来把每一个映射的值进行拼接。
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter) {
return joining(delimiter, "", "");
}
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}
10、分组
(1)分组简介
在数据库操作中,经常会通过group by对查询结果进行分组。同时在日常开发中,也经常会涉及到这一类操作,如通过性别对学生集合进行分组。如果通过普通编码的方式需要编写大量代码且可读性不好。
对于这个问题的解决,java8也提供了简化书写的方式。通过Collectors。groupingBy()即可。
Map<Integer, List<Student>> map = studentList.stream().collect(Collectors.groupingBy(Student::getAge))
(2)多级分组
//多级分组
// 对于这个结果外层分组产生的map生成了两个值:18、20。同时他们各自的值又是一个map,key是二级分组的返回值,值是流中元素的具体值。对于这种多级分组操作,可以扩展至无限层级。
Map<Integer, Map<String, List<Student>>> collect = studentList.stream().collect(Collectors.groupingBy(Student::getAge, Collectors.groupingBy(student -> {
if (student.getIsPass()) {
return "pass";
} else {
return " not pass";
}
})));
System.out.println(collect);
// {18={ not pass=[Student{id=2, name='李四', sex='M', age=18, score=55, isPass=false}], pass=[Student{id=1, name='张三', sex='M', age=18, score=90, isPass=true}]}, 20={ not pass=[Student{id=4, name='赵六', sex='F', age=20, score=40, isPass=false}], pass=[Student{id=3, name='王五', sex='F', age=20, score=100, isPass=true}]}}
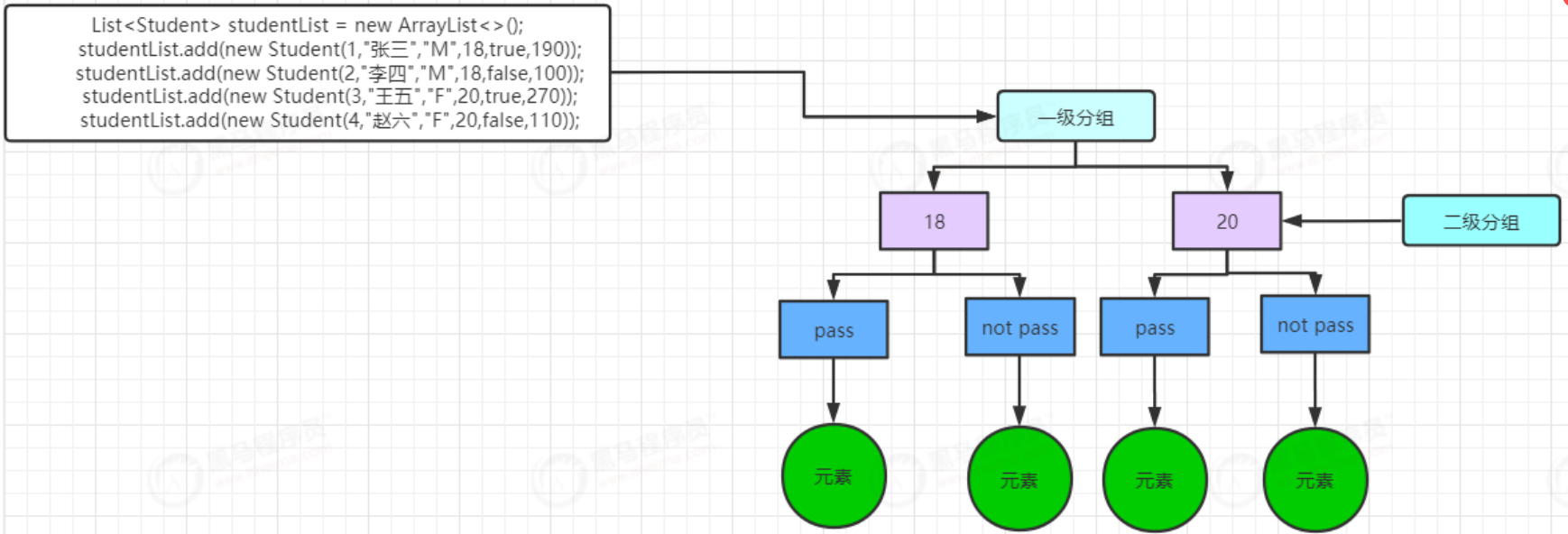
groupingBy重载方法在接收普通函数之外,还会再接收一个Collector类型的参数,其会在内层分组(第二个参数)结果,传递给外层分组(第一个参数)作为其继续分组的依据。
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
return groupingBy(classifier, HashMap::new, downstream);
}
(3)多级分组变形
在日常开发中,我们很有可能不是需要返回一个数据集合,还有可能对数据进行汇总操作,比方说对于年龄18岁的通过的有多少人,未及格的有多少人。因此,对于二级分组收集器传递给外层分组收集器的可以任意数据类型,而不一定是它的数据集合。
在对收集器的使用中,将多个收集器嵌套起来使用非常常见。通过这些收集器的嵌套,可以完成很多较为复杂的业务逻辑实现。
//根据年龄进行分组,获取并汇总人数
Map<Integer, Long> collect = studentList.stream().collect(Collectors.groupingBy(Student::getAge, Collectors.counting()));
System.out.println(collect);
//根据年龄与是否及格进行分许,并汇总人数
Map<Integer, Map<Boolean, Long>> collect = studentList.stream().collect(Collectors.groupingBy(Student::getAge, Collectors.groupingBy(Student::getIsPass, Collectors.counting())));
System.out.println(collect);
//根据年龄与是否集合进行分组,并获取每组中分数最高的学生
Map<Integer, Map<Boolean, Student>> collect = studentList.stream().collect(
Collectors.groupingBy(Student::getAge,
Collectors.groupingBy(Student::getIsPass,
Collectors.collectingAndThen(
Collectors.maxBy(
Comparator.comparing(Student::getScore)
), Optional::get
)))
);
System.out.println(collect);
(4)自定义收集器
对于自定义收集器实现,可以对Collector接口中的方法进行实现。
根据源码,Collector接口需要三个参数。T:流中要收集的元素类型、A:累加器的类型、R:收集的结果类型。
如想自定义收集器,需要实现Collector接口中的五个方法:supplier、accumulator、finisher、combiner、characteristics。

supplier:用于创建一个容器,在调用它时,需要创建一个空的累加器实例,供后续方法使用。
accumulator:基于supplier中创建的累加容器,进行累加操作。
finisher:当遍历完流后,在其内部完成最终转换,返回一个最终结果。
combiner:用于在并发情况下,将每个线程的容器进行合并。
characteristics:用于定义收集器行为,如是否可以并行或使用哪些优化。其本身是一个枚举,内部有三个值,分别为:
CONCURRENT:表明收集器是并行的且只会存在一个中间容器。
UNORDERED:表明结果不受流中顺序影响,收集是无序的。
IDENTITY_FINISH:表明累积器的结果将会直接作为归约的最终结果,跳过finisher()。
// 自定义收集器,返回所有合格的学员
public class MyCollector implements Collector<Student, List<Student>,List<Student>> {
@Override
public Supplier<List<Student>> supplier() {
return ArrayList::new;
}
@Override
public BiConsumer<List<Student>, Student> accumulator() {
return ((studentList, student) -> {
if (student.getIsPass()){
studentList.add(student);
}
});
}
@Override
public BinaryOperator<List<Student>> combiner() {
return null;
}
@Override
public Function<List<Student>, List<Student>> finisher() {
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
return EnumSet.of(Characteristics.IDENTITY_FINISH,Characteristics.UNORDERED);
}
}
//使用自定义收集器
public class MyCollectorTest {
public static void main(String[] args) {
List<Student> studentList = new ArrayList<>();
studentList.add(new Student(1,"张三","M",19,true));
studentList.add(new Student(2,"李四","M",18,true));
studentList.add(new Student(3,"王五","F",21,true));
studentList.add(new Student(4,"赵六","F",20,false));
List<Student> list = studentList.stream().collect(new MyCollector());
System.out.println(list);
}
}
11、数据并行化
为了让数据处理更加高效,Java8对于Stream也提供了并行的操作方式,在Java7之前如果要对数据并行处理,需要开发人员做的事情很多,如数据如何进行分块、开启多少个线程、哪个线程负责哪部分数据、出现线程竞争怎么办等等的问题。
Java8对于数据并行化处理的实现非常简单,直接调用一个parallelStream()就可以开启并行化处理。
(1)并行流使用
// 对于并行流的使用,只需要改变一个方法调用就可以实现,让你获得并行的操作。
// 当将stream()切换为parallelStream()后,则完成了串行转换为并行的实现。
int sum = numbers.parallelStream().mapToInt(i -> i).sum();
(2)并行流原理介绍
对于并行流,其在底层实现中,是沿用了Java7提供的fork/join分解合并框架进行实现。fork根据cpu核数进行数据分块,join对各个fork进行合并。实现过程如下所示:
假设现在的求和操作是运行在一台4核的机器上。
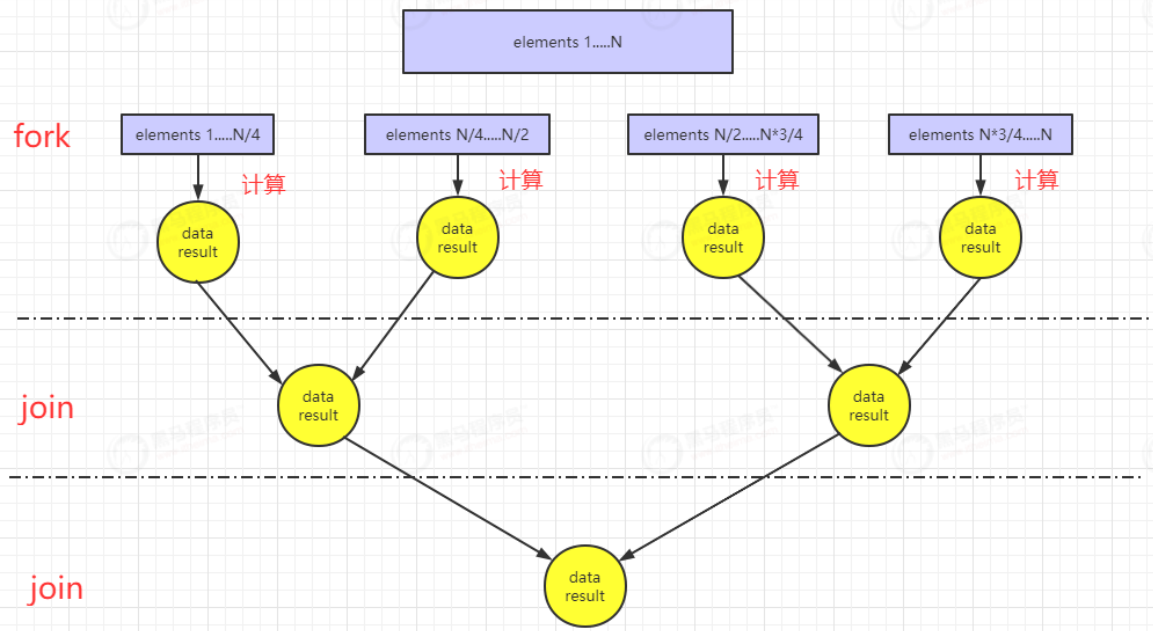
(3)使用注意事项
对于并行流,一定不要陷入一个误区:并行一定比串行快。并行在不同的情况下它不一定是比串行快的。影响并行流性能主要存在5个因素:
- 1)数据大小:输入数据的大小,直接影响了并行处理的性能。因为在并行内部实现中涉及到了fork/join操作,它本身就存在性能上的开销。因此只有当数据量很大,使用并行处理才有意义。
- 2)源数据结构:fork时会对源数据进行分割,数据源的特性直接影响了fork的性能。
ArrayList、数组或IntStream.range,可分解性最佳,因为他们都支持随机读取,因此可以被任意分割。
HashSet、TreeSet,可分解性一般,其虽然可被分解,但因为其内部数据结构,很难被平均分解。
LinkedList、Streams.iterate、BufferedReader.lines,可分解性极差,因为他们长度未知,无法确定在哪里进行分割。
- 3)装箱拆箱:尽量使用基本数据类型,避免装箱拆箱。
- 4)CPU核数:fork的产生数量是与可用CPU核数相关,可用的核数越多,获取的性能提升就会越大。
- 5)单元处理开销:花在流中每个元素的时间越长,并行操作带来的性能提升就会越明显。
(4)性能测试
我们可以对他通过基本类型、对象类型和复杂对象来对普通for循环、串行流和并行流进行分别的性能测试。
此处使用常见线上服务器配置。12核24线程,96G内存的配置。
(①)基本类型
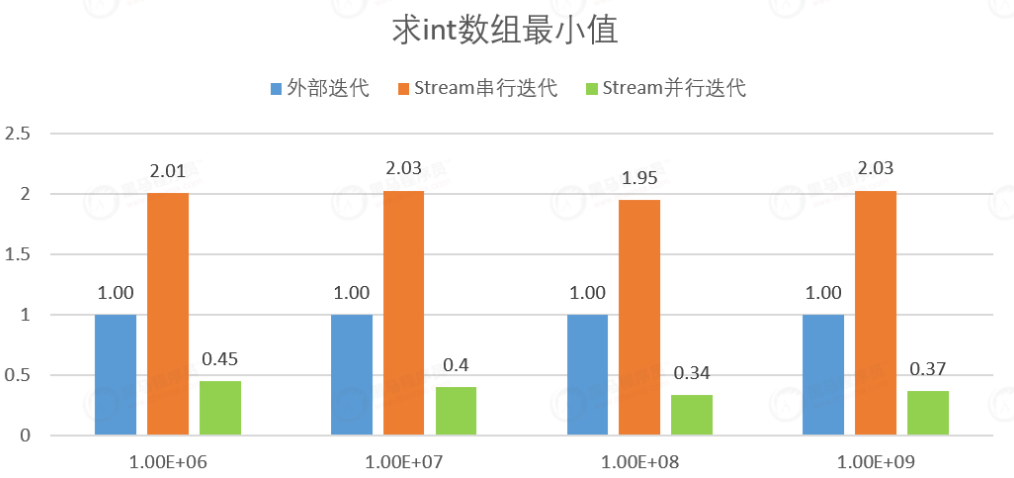
从上图可知,对于基本数据类型Stream串行的性能开销是普通for循环的两倍左右。同时Stream并行的性能比普通for循环和串行都要好。
Stream串行>for循环>Stream并行
(②) 对象

根据上图可知,当操作对象类型时,Stream串行的性能开销仍高于普通for循环一倍左右。同时Stream并行的性能比普通for循环和串行都要好。
Stream串行>for循环>Stream并行
(③) 复杂对象
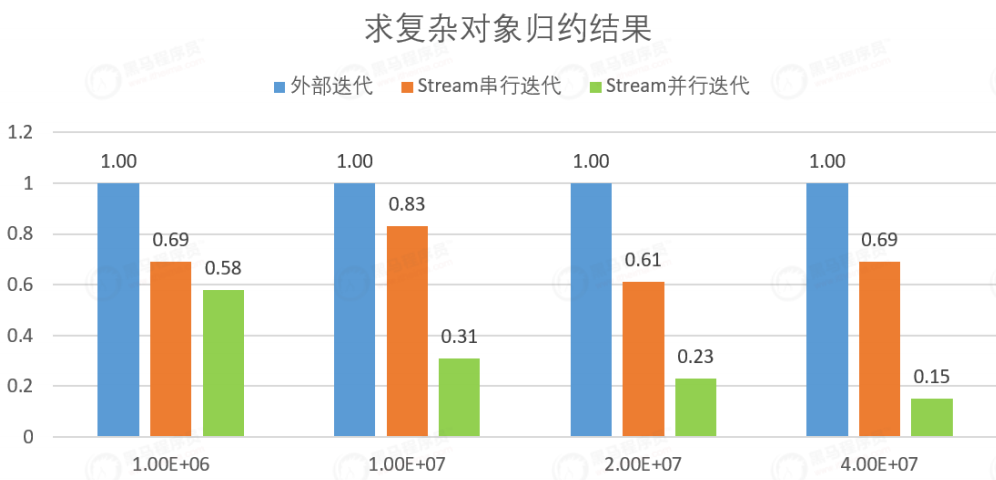
根据上图可知,当操作复杂对象时,普通for循环的性能开销会高于Stream串行,同时仍然是Stream并行性能最优。
for循环>Stream串行>Stream并行
(④) 结论
根据上述测试可知,对于简单操作,如果环境机是多核的话,建议使用Stream并行,同时在不考虑核数的情况下,普通for循环性能要明显高于Stream串行,相差两倍左右。对于复杂操作,推荐使用Stream API操作。