一、etcd 概述
etcd 是 CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。
- etcd 内部采用 raft 协议作为一致性算法,etcd基于Go语言实现。
- 完全复制:集群中的每个节点都可以使用完整的存档
- 高可用性:Etcd可用于避免硬件的单点故障或网络问题
- 一致性:每次读取都会返回跨多主机的最新写入
- 简单:包括一个定义良好、面向用户的API(gRPC)
- 安全:实现了带有可选的客户端证书身份验证的自动化TLS
- 快速:每秒10000次写入的基准速度
- 可靠:使用Raft算法实现了强一致、高可用的服务存储目录
ETCD 集群运维相关的基本知识:
- 读写端口为: 2379, 数据同步端口: 2380
- ETCD集群是一个分布式系统,使用Raft协议来维护集群内各个节点状态的一致性。
- 主机状态 Leader, Follower, Candidate
- 当集群初始化时候,每个节点都是Follower角色,通过心跳与其他节点同步数据
- 通过Follower读取数据,通过Leader写入数据
- 当Follower在一定时间内没有收到来自主节点的心跳,会将自己角色改变为Candidate,并发起一次选主投票
- 配置etcd集群,建议尽可能是奇数个节点,而不要偶数个节点,推荐的数量为 3、5 或者 7 个节点构成一个集群。
- 使用 etcd 的内置备份/恢复工具从源部署备份数据并在新部署中恢复数据。恢复前需要清理数据目录
- 数据目录下 snap: 存放快照数据,etcd防止WAL文件过多而设置的快照,存储etcd数据状态。
- 数据目录下 wal: 存放预写式日志,最大的作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要先写入到WAL中。
- 一个 etcd 集群可能不应超过七个节点,写入性能会受影响,建议运行五个节点。一个 5 成员的 etcd 集群可以容忍两个成员故障,三个成员可以容忍1个故障。
常用配置参数:
- ETCD_NAME 节点名称,默认为defaul
- ETCD_DATA_DIR 服务运行数据保存的路
- ETCD_LISTEN_PEER_URLS 监听的同伴通信的地址,比如http://ip:2380,如果有多个,使用逗号分隔。需要所有节点都能够访问,所以不要使用 localhost
- ETCD_LISTEN_CLIENT_URLS 监听的客户端服务地址
- ETCD_ADVERTISE_CLIENT_URLS 对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点
- ETCD_INITIAL_ADVERTISE_PEER_URLS 对外公告的该节点同伴监听地址,这个值会告诉集群中其他节
- ETCD_INITIAL_CLUSTER 集群中所有节点的信息
- ETCD_INITIAL_CLUSTER_STATE 新建集群的时候,这个值为 new;假如加入已经存在的集群,这个值为existing
- ETCD_INITIAL_CLUSTER_TOKEN 集群的ID,多个集群的时候,每个集群的ID必须保持唯一
二、安装etcdctl工具
【官网】https://github.com/etcd-io/etcd/releases
#查看版本号
cat /etc/kubernetes/manifests/etcd.yaml |grep image
#输入版本号:v3.5.4
$ install_etcdctl.sh
#!/bin/bash
read -p "输入·etcd的版本号": VERSION
ETCD_VER=$VERSION
ETCD_DIR=etcd-download
DOWNLOAD_URL=https://ghproxy.com/github.com/coreos/etcd/releases/download
# 下载
cd /usr/local
mkdir ${ETCD_DIR}
cd ${ETCD_DIR}
rm -rf *
wget ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar -xzvf etcd-${ETCD_VER}-linux-amd64.tar.gz
# 安装etcdctl
cd etcd-${ETCD_VER}-linux-amd64
#重命名,便于识别
cp etcdctl /usr/local/bin/
#删除安装数据目录
cd /usr/local&& rm -rf ${ETCD_DIR}
#添加环境变量
echo "ETCDCTL_API=3" >>/etc/profile
#查看版本
etcdctl version
chmod o+x install_etcdctl.sh
sh install_etcdctl.sh
输入:v3.5.4
三、kubeadm部署方式部署
基本了解:
- K8s 使用etcd数据库实时存储集群中的数据,安全起见,一定要备份!
- 备份只需要在一个节点上备就可以了(为了避免刚好损坏的是备份节点,建议备份两个节点),每个节点上的数据是同步的;但是数据恢复是需要在每个节点上进行。
- ectd容器是与宿主机网络共享的,采用hostNetwork方式,2379数据端口就可以在宿主机上查看到( ss -ntlp|grep 2379)。
[root@k8s-master-01 etcd_backup]# ss -ntlp|grep 2379
LISTEN 0 128 192.168.4.114:2379 *:* users:(("etcd",pid=1841,fd=9))
LISTEN 0 128 127.0.0.1:2379 *:* users:(("etcd",pid=1841,fd=8))
- kubeadm方式部署的集群,其中etcd是通过静态pod方式部署启动,在/etc/kubernetes/manifests目录下有它的yaml文件,里面记录了启动镜像、版本、证书路劲、数据目录等内容。
[root@k8s-master-01 ~]# cat /etc/kubernetes/manifests/etcd.yaml |grep -A 10 volumes:
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /data/k8s/etcd
type: DirectoryOrCreate
name: etcd-data
status: {}
注意etcd数据目录是否更换,默认是/var/lib/etcd/此处etcd数据目为/data/k8s/etcd,否则将会导致集群不能恢复。
1)备份
- 最好备份两个节点,避免刚好备份机器故障
#创建命名空间
kubectl create ns test
#部署
cat > nginx-deployment.yaml<<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: test
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: test
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePort
EOF
#部署
kubectl apply -f nginx-deployment.yaml
#创建备份目录
mkdir -p /data/etcd_backup
cd /data/etcd_backup
#备份
ETCDCTL_API=3 etcdctl \
snapshot save snap.db_$(date +%F) \
--endpoints=https://192.168.4.114:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
#检查
[root@k8s-master-01 etcd_backup]# ETCDCTL_API=3 etcdctl --write-out=table snapshot status /opt/etcd_backup/snap.db_2023-08-24
Deprecated: Use `etcdutl snapshot status` instead.
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 4c5447a8 | 2333766 | 1308 | 6.9 MB |
+----------+----------+------------+------------+
#集群节点状态
[root@k8s-master-01 etcd_backup]# ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" member list -w table
+------------------+---------+---------------+----------------------------+----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+---------------+----------------------------+----------------------------+------------+
| c3509e57d5f53562 | started | k8s-master-01 | https://192.168.4.114:2380 | https://192.168.4.114:2379 | false |
+------------------+---------+---------------+----------------------------+----------------------------+------------+
#任意节点查看 etcd 集群信息
[root@k8s-master-01 etcd_backup]# ETCDCTL_API=3 etcdctl --endpoints https://127.0.0.1:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" endpoint status --cluster -w table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.4.114:2379 | c3509e57d5f53562 | 3.5.4 | 6.9 MB | true | false | 10 | 2649811 | 2649811 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
- 部署之前存在nginx,删除nginx,恢复etcd确认nginx存在。
[root@k8s-master-01 etcd_backup]# kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-ff6774dc6-7mm2j 1/1 Running 0 11s
nginx-deployment-ff6774dc6-hdvbf 1/1 Running 0 11s
nginx-deployment-ff6774dc6-zcf8m 1/1 Running 0 11s
[root@k8s-master-01 ~]#kubectl delete -f nginx-deployment.yaml
[root@k8s-master-01 etcd_backup]# kubectl get pods -n test
2)恢复
kubeadm
- kubeadm 部署的集群中的 etcd 是以静态容器的方式运行的,静态容器的配置文件存放目录是 /etc/kubernetes/manifests/。
- 核心流程就是:停止 api-server 和 etcd 服务 -> 执行还原 -> 重启 api-server 和 etcd 服务
#先停止api server和etcd服务。因为是静态Pod部署,监控这个目录下的yaml文件,当把目录备份后就直接相当于停服
mkdir -p /tmp/etcd/manifests/
mv /etc/kubernetes/manifests/{kube-apiserver.yaml,etcd.yaml} /tmp/etcd/manifests/
mv /data/k8s/etcd /data/k8s/etcd.`date +%Y%m%d`
#查看api-server是否停止
[root@k8s-master-01 ~]# kubectl get pod
The connection to the server 192.168.4.114:6443 was refused - did you specify the right host or port?
#使用snap.db文件恢复数据到/var/lib/etcd目录。
ETCDCTL_API=3 etcdctl snapshot restore snap.db_2023-08-24 --endpoints=https://192.168.4.114:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --data-dir=/data/k8s/etcd
#启动kube-apiserver和etcd容器
mv /tmp/etcd/manifests/{kube-apiserver.yaml,etcd.yaml} /etc/kubernetes/manifests/
#查看结果,数据恢复
[root@k8s-master-01 etcd_backup]# kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
nginx-deployment-ff6774dc6-ch9p2 1/1 Running 0 2m3s
nginx-deployment-ff6774dc6-cklzj 1/1 Running 0 2m3s
nginx-deployment-ff6774dc6-fb6wb 1/1 Running 0 2m3s
#检查集群是否正常
[root@k8s-master-01 etcd_backup]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
四、定时备份
- 最好备份两个节点,避免刚好备份机器故障
#创建etcd脚本存放目录
mkdir -p /opt/etcd_backup
#创建etcd数据备份目录
mkdir -p /data/etcd_backup
#创建定时备份脚本
[root@master etcd]# cat /opt/etcd_backup/etcd_backup.sh
#!/bin/bash
CACERT="/etc/kubernetes/pki/etcd/ca.crt "
CERT="/etc/kubernetes/pki/etcd/server.crt"
EKY="/etc/kubernetes/pki/etcd/server.key"
ENDPOINTS="192.168.4.114:2379"
ETCDCTL_API=3 etcdctl \
--cacert="${CACERT}" \
--cert="${CERT}" \
--key="${EKY}" \
--endpoints=${ENDPOINTS} \
snapshot save /data/etcd_backup/etcd-snapshot-`date +%Y-%m-%d_%H:%M:%S`.db
# 备份保留30天
find /data/etcd_backup/ -name *.db -mtime +30 -exec rm -f {} \;
#设置定时任务
crontab -e
#每天凌晨2点执行
0 2 * * * sh /opt/etcd_backup/etcd_backup.sh
#停止apisever和etcd
mkdir -p /tmp/etcd/manifests/
mv /etc/kubernetes/manifests/{kube-apiserver.yaml,etcd.yaml} /tmp/etcd/manifests/
mv /data/k8s/etcd /data/k8s/etcd.`date +%Y-%m-%d_%H:%M:%S`
#恢复命令
ETCDCTL_API=3 etcdctl snapshot restore /data/etcd_backup/etcd-snapshot-20230825.db \
--endpoints=https://192.168.4.114:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--data-dir=/data/k8s/etcd
#启动kube-apiserver和etcd容器
mv /tmp/etcd/manifests/{kube-apiserver.yaml,etcd.yaml} /etc/kubernetes/manifests/
#查看集群
kubectl get cs
五、二进制部署备份
| 节点 | IP |
|---|---|
| etdc_1 | 192.168.4.114 |
| etdc_2 | 192.168.4.115 |
| etdc_3 | 192.168.4.116 |
1)备份
- 最好备份两个节点,避免刚好备份机器故障
ETCDCTL_API=3 etcdctl \
snapshot save snap.db \
--endpoints=https://192.168.4.114:2379 \ #备份节点IP
--cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem \
--key=/opt/etcd/ssl/server-key.pem
2)恢复
- etcd 集群以服务的形式在多台服务器运行,与容器方式不同的仅仅是服务的 endpoints 不一样,备份与 kubeadm 相同。
- 恢复顺序:停止kube-apiserver –> 停止ETCD –> 恢复数据 –> 启动ETCD –> 启动kube-apiserve
1、停止apiserver和etcd
#每个etcd节点需要先手动停止kube-apiserver和etcd服务
systmectl stop kube-apiserver
systemctl stop etcd
mv /var/lib/etcd/default.etcd /var/lib/etcd/default.etcd.`date +%Y-%m-%d_%H:%M:%S`
2、etcd_1恢复
- 恢复需要在每个 etcd 节点进行恢复。
# 每个etcd依次恢复,需要修改 name, initialadvertise-peer-urls等参数
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd_1 \ # 每台节点name不一样,根据当前节点etcd配置文件即可
--initial-cluster="etcd-1=https:/192.168.4.114:2380,etcd-1=https://192.168.4.115:2380,etcd-1=https:/192.168.4.116:2380" \ #描述集群节点信息
--initial-cluster-token=etcd-cluster \
--initialadvertise-peer-urls=https://192.168.4.114:2380 \ # 修改为当前节点ip
--data-dir=/vaf/lib/default.etcd #注意数据目录
3、etcd_2恢复
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd_2 \
--initial-cluster="etcd-1=https:/192.168.4.114:2380,etcd-1=https://192.168.4.115:2380,etcd-1=https:/192.168.4.116:2380" \
--initial-cluster-token=etcd-cluster \
--initialadvertise-peer-urls=https://192.168.4.115:2380 \
--data-dir=/vaf/lib/default.etcd
4、etcd_3恢复
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd_3 \
--initial-cluster="etcd-1=https:/192.168.4.114:2380,etcd-1=https://192.168.4.115:2380,etcd-1=https:/192.168.4.116:2380" \
--initial-cluster-token=etcd-cluster \
--initialadvertise-peer-urls=https://192.168.4.116:2380 \
--data-dir=/vaf/lib/default.etcd
5、启动etcd和apiserver
#启动 kube-apiserver和etcd 服务
systemctl start kube-apiserver
systemctl start etcd
6、检查集群
#查看集群状态
ETCDCTL_API=3 /opt/etcd/bin/etcdctl \
--cacert=/opt/etcd/ssl/etcd-ca.pem \
--cert=/opt/etcd/ssl/server.pem \
--key=/opt/etcd/ssl/server-key.pem \
--endpoints="https://192.168.4.114:2379,https://192.168.4.115:2379,https://192.168.4.116:2379" endpoint health \
--write-out=table
#查看集群
[root@k8s-master-01 k8s]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
提示:
- 备份还原后集群会出现短暂的不可用现象,原因是重启 apiserver 和 etcd 服务。
- etcdctl 为快照备份,不会记录最新写入的数据,因此从备份恢复可能会丢失最新的数据。
- etcd 不能备份存储在 PV 数据卷的业务数据。
- etcd 为全局备份,不能针对某个命名空间做备份还原。
六、安装velero
Velero 地址:https://github.com/vmware-tanzu/velero
ACK 插件地址:https://github.com/AliyunContainerService/velero-plugin
1)Velero简介
Velero使用对象存储系统进行备份,所以在安装Velero之前,需要先安装一个对象存储系统,例如Ceph或者Minio。Minio安装相对简单一些,也推荐使用Minio作为Velero的备份存储系统。
利用 velero 用户可以安全的备份、恢复和迁移 Kubernetes 集群资源和持久卷。它的基本原理就是将集群的数据,例如集群资源和持久化数据卷备份到对象存储中,在恢复的时候将数据从对象存储中拉取下来。除了灾备之外它还能做资源移转,支持把容器应用从一个集群迁移到另一个集群,这也是 velero 一个非常成功的使用场景
Velero 主要包括两个核心组件,分别为服务端和客户端。服务端运行在具体的 Kubernetes 集群中,客户端是运行在本地的命令行工具,只要配置好 kubectl 及 kubeconfig 即可使用,非常简单。
Velero 基于其实现的 kubernetes 资源备份能力,可以轻松实现 Kubernetes 集群的数据备份和恢复、复制 kubernetes 集群资源到其他 kubernetes 集群或者快速复制生产环境到测试环境等功能。
在资源备份方面,velero 支持将数据备份到众多的云存储中,例如AWS S3或S3兼容的存储系统、Azure Blob、Google Cloud存储、Aliyun OSS等。与备份整个 kubernetes 的数据存储引擎 etcd 相比,velero 的控制更加细化,可以对 Kubernetes 集群内对象级别进行备份,还可以通过对 Type、Namespace、Label 等对象进行分类备份或者恢复。
2)工作流程
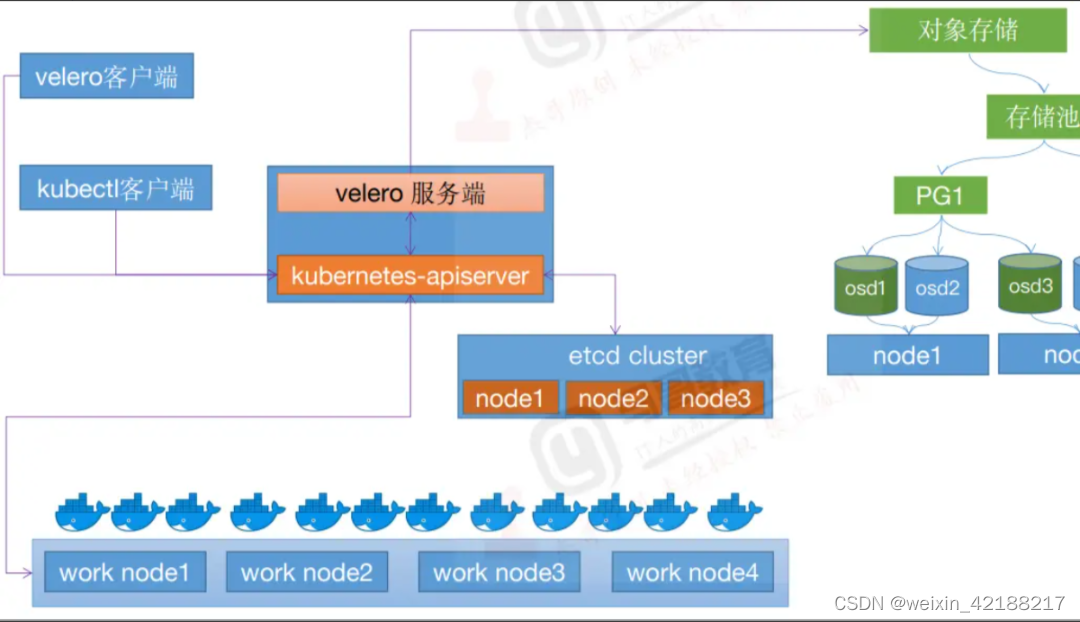
以核心的数据备份为例,当执行velero backup create my-backup时:
- Velero 客户端首先调用 Kubernetes API 服务器以创建 Backup 对象;
- BackupController 将收到通知有新的 Backup 对象被创建并执行验证;
- BackupController 开始备份过程,它通过查询 API 服务器以获取资源来收集数据以进行备份;
- BackupController 将调用对象存储服务,例如,AWS S3 -上传备份文件。默认情况下,velero backup create支持任何持久卷的磁盘快照,可以通过指定其他标志来调整快照,运行velero backup create --help可以查看可用的标志,也可以使用–snapshot-volumes=false选项禁用快照。
关于备份存储位置和卷快照,Velero 有两个自定义资源 BackupStorageLocation 和 VolumeSnapshotLocation,用于配置 Velero 备份及其关联的持久卷快照的存储位置。
BackupStorageLocation 主要支持的后端存储是 S3 兼容的存储,存储所有Velero数据的存储区中的前缀以及一组其他特定于提供程序的字段。比如:Minio 和阿里云 OSS 等 ;
VolumeSnapshotLocation(pv 数据),主要用来给 PV 做快照,需要云提供商提供插件,完全由提供程序提供的特定的字段(例如AWS区域,Azure资源组,Portworx快照类型等)定义。以对数据一致性最为敏感的数据库和中间件为例,开源存储插件 Carina 也即将提供数据库感知的 velero 卷快照功能,可以实现中间件数据的快速备份及恢复。
3)整体流程
面是实现 Kubernetes Velero 的整体步骤:
| 步骤 | 描述 |
|---|
- 安装 Velero |在 Kubernetes 集群中安装 Velero
- 创建 Velero 后端存储 |配置 Velero 使用的云存储或本地存储
- 创建 Velero 证书和身份验证 |生成 TLS 证书和密钥,并创建 Kubernetes Secret
- 配置 Velero |创建 Velero 的配置文件
- 创建和配置 Velero 的存储桶 |在 Velero 后端存储中创建存储桶
- 配置 Velero 插件 |安装和配置 Velero 插件
- 创建 Velero Schedule |配置 Velero 创建备份的计划
4)nfs持久卷
[root@k8s-master ~]# vim nfs.sh
#!/bin/bash
IPADDR=$(ip a|grep brd|grep ens160|awk '{print $2}'|grep -o -E "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}")
read -p "请输入本机IP:" -t 30 HOST_IP
yum install -y nfs-utils
mkdir -p /data/nfs
chmod -R 777 /data/nfs
#增加配置文件
echo "/data/nfs s $IPADDR/24(rw,sync,no_subtree_check,no_root_squash)" >>/etc/exports
#查看配置文件
cat /etc/exports
#授权(chown 修改文件和文件夹的用户和用户组属性)
chown nfsnobody:nfsnobody /data/nfs
#启动和增加开启自启动
systemctl restart nfs-server.service
systemctl enable nfs-server.service
systemctl status nfs-server.service
#创建数据目录
mkdir -p /opt/nfs-storageclass
cd /opt/nfs-storageclass
cat >nfs-client-provisioner.yaml<<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: gcr.io/k8s-staging-sig-storage/nfs-subdir-external-provisioner:v4.0.1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: nfs # 存储分配器的默认名称 ,根据自己的名称来修改,与 storageclass.yaml 中的 provisioner 名字一致
- name: NFS_SERVER
value: $HOST_IP # NFS服务器所在的 ip
- name: NFS_PATH
value: /data/nfs # 共享存储目录
volumes:
- name: nfs-client-root
nfs:
server: $HOST_IP # NFS服务器所在的 ip
path: /data/nfs # 共享存储目录
EOF
sed -i 's#gcr.io/k8s-staging-sig-storage/nfs-subdir-external-provisioner:v4.0.1# dyrnq/nfs-subdir-external-provisioner:v4.0.1#g' nfs-client-provisioner.yaml
cat >rbac.yaml<<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
EOF
cat >storageclass.yaml<<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: nfs # 或者选择其他名称,必须匹配部署变量 PROVISIONER_NAME'
parameters:
archiveOnDelete: "false" #当设置为“false”时,在删除PVC时,您的pv将不会被配置程序存档。
EOF
kubectl apply -f /opt/nfs-storageclass/.
chmod o+x nfs.sh
sh nfs.sh
输入nfs的节点IP
kubectl get pods -n kube-system|grep fs-client-provisioner-
5)安装Velero
【官方文档】
- https://velero.io/docs/v1.9/
- https://github.com/vmware-tanzu/velero/
【Velero版本和k8s版本的兼容性】
- https://github.com/vmware-tanzu/velero
| Velero version | Tested on Kubernetes version |
|---|---|
| 1.12 | 1.25.7, 1.26.5, 1.26.7, and 1.27.3 |
| 1.11 | 1.23.10, 1.24.9, 1.25.5, and 1.26.1 |
| 1.10 | 1.22.5, 1.23.8, 1.24.6 and 1.25.1 |
| 1.9 | 1.20.5, 1.21.2, 1.22.5, 1.23, and 1.24 |
- Velero支持IPv4、IPv6和双栈环境
#查看k8s版本,选择Velero版本kubeadm version
[root@k8s-master1 ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.0", GitCommit:"a866cbe2e5bbaa01cfd5e969aa3e033f3282a8a2", GitTreeState:"clean", BuildDate:"2022-08-23T17:43:25Z", GoVersion:"go1.19", Compiler:"gc", Platform:"linux/amd64"}
cd /opt/
wget -c https://ghproxy.com/github.com/vmware-tanzu/velero/releases/download/v1.10.0/velero-v1.10.0-linux-amd64.tar.gz
tar -zxvf velero-v1.10.0-linux-amd64.tar.gz
cd velero-v1.10.0-linux-amd64
mv velero /usr/local/bin
chmod +x /usr/local/bin/velero
velero version
6)安装minio
1、官方地址
【官方地址】
- https://github.com/minio/mc
- https://min.io/docs/minio/linux/index.html?ref=docs-redirect
- https://zhuanlan.zhihu.com/p/557868296
【指定镜像版本】
- https://github.com/minio/mc/tree/RELEASE.2023-08-18T21-57-55Z
2、部署yaml
这里我们可以使用 minio 来代替云环境的对象存储,在上面解压的压缩包中包含一个 examples/minio/00-minio-deployment.yaml 的资源清单文件,为了测试方便可以将其中的 Service 更改为 NodePort 类型,我们可以配置一个 console-address 来提供一个 console 页面的访问入口,完整的资源清单文件如下所示:
#配置一个 console-address 来提供一个 console 页面的访问入口
args:
- server
- /storage
- --config-dir=/config
- --console-address=:9001 #添加
。。。。。。
ports:
- containerPort: 9000
- containerPort: 9001 #添加
#暴露端口
# type: ClusterIP
# ports:
# - port: 9000
# targetPort: 9000
# protocol: TCP
type: NodePort
ports:
- name: api
port: 9000
targetPort: 9000
- name: console
port: 9001
targetPort: 9001
nodePort: 30009
#修改minio部署yaml
cd /opt/velero-v1.10.0-linux-amd64/examples/minio
#查看
[root@k8s-master1 minio]# cat 00-minio-deployment.yaml
# Copyright 2017 the Velero contributors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
---
apiVersion: v1
kind: Namespace
metadata:
name: velero
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: velero
name: minio
labels:
component: minio
spec:
strategy:
type: Recreate
selector:
matchLabels:
component: minio
template:
metadata:
labels:
component: minio
spec:
volumes:
- name: storage
emptyDir: {}
- name: config
emptyDir: {}
containers:
- name: minio
image: minio/minio:edge
imagePullPolicy: IfNotPresent
args:
- server
- /storage
- --config-dir=/config
- --console-address=:9001
env:
- name: MINIO_ACCESS_KEY
value: "minio"
- name: MINIO_SECRET_KEY
value: "minio123"
ports:
- containerPort: 9000
- containerPort: 9001
volumeMounts:
- name: storage
mountPath: "/storage"
- name: config
mountPath: "/config"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: storage
namespace: velero
spec:
storageClassName: "managed-nfs-storage"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: Service
metadata:
namespace: velero
name: minio
labels:
component: minio
spec:
# ClusterIP is recommended for production environments.
# Change to NodePort if needed per documentation,
# but only if you run Minio in a test/trial environment, for example with Minikube.
type: NodePort
ports:
# - port: 9000
# targetPort: 9000
# protocol: TCP
- name: api
port: 9000
targetPort: 9000
- name: console
port: 9001
targetPort: 9001
nodePort: 30009
selector:
component: minio
---
apiVersion: batch/v1
kind: Job
metadata:
namespace: velero
name: minio-setup
labels:
component: minio
spec:
template:
metadata:
name: minio-setup
spec:
restartPolicy: OnFailure
volumes:
- name: config
emptyDir: {}
containers:
- name: mc
image: minio/mc:edge
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- "mc --config-dir=/config config host add velero http://minio:9000 minio minio123 && mc --config-dir=/config mb -p velero/velero"
volumeMounts:
- name: config
mountPath: "/config"
访问:http://192.168.4.115:30009/login
- 用户名:minio
- 密码:minio123
minio 的数据和配置可以用比如cephfs来做持久化。
一般推荐部署在集群外部。
3、创建ID和key
可选择创建一个 Buckets, 然后需要创建 User (记住id和key) 授权到对应 bucket 才能正常上传.
- 选择users———选择create user。
- Access Key:backup
- Secret Key: Abcd123456
- select policy: readwrite
4、创建备份桶
- 选择"Buckets",创建名字为velerodata的备份所用桶。
- 选择"Create Bucket"创建,其余默认
5、测试访问
访问备份账号:http://192.168.4.115:30009/login
- 用户名:minioadmin
- 密码:minioadmin
7)安装velero服务端
创建 minio 认证文件,使用上边创建的具有 readwrite 权限的用户:
cd /opt/velero-v1.10.0-linux-amd64/
cat >velero-auth.txt << EOF
[default]
aws_access_key_id = minioadmin
aws_secret_access_key = minioadmin
EOF
velero --kubeconfig /root/.kube/config install \
--use-node-agent \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.7.0 \
--bucket velerodata --secret-file ./velero-auth.txt \
--use-volume-snapshots=false \
--namespace velero default-volumes-to-restic \
--backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://minio.velero.svc:9000
如果s3URL地址不使用k8s内部解析地址则使用数据端口9000的暴露地址(节点IP+30008)
【参数说明】
- –kubeconfig 默认找KUBECONFIG环境变量制定的认证文件
- –bucket minio创建存储名
- –secret-file 密码认证文件
- –namespace 默认是velero命名空间,指定该参数指定创建命名空间
【重要参数说明】
| 安装参数 | 参数说明 |
|---|---|
| –provider | 声明使用 aws 提供的插件类型。 |
| –plugins | 使用 AWS S3 兼容 API 插件 “velero-plugin-for-aws”。 |
| –bucket | 在对象存储 COS 创建的存储桶名。 |
| –secret-file | 访问对象存储 COS 的访问凭证文件,详情参见上述创建的 “credentials-velero” 凭证文件。 |
| –use-restic | Velero 支持使用免费开源备份工具 Restic 备份和还原 Kubernetes 存储卷数据 (不支持 hostPath 卷,详情请参见 Restic 限制),该集成是 Velero 备份功能的补充,建议开启。 |
| –default-volumes-to-restic | 启用使用 Restic 来备份所有 Pod 卷,前提是需要开启 --use-restic 参数。 |
| –backup-location-config | 备份存储桶访问相关配置,包括 region、s3ForcePathStyle、s3Url 等。 |
| region | 兼容 S3 API 的对象存储 COS 存储桶地域,例如创建地域为广州,region 参数值为 “ap-guangzhou” |
| s3ForcePathStyle | 使用 S3 文件路径格式。 |
| s3Url | 对象存储 COS 兼容的 S3 API 访问地址。请注意该访问地址中的域名不是上述创建 COS 存储桶的公网访问域名,须使用格式为 https://cos..myqcloud.com 的 URL,例如地域为广州,则参数值为 https://cos.ap-guangzhou.myqcloud.com。 |
- 其他安装参数可以使用命令 velero install --help 查看。例如,不备份存储卷数据,可以设置 --use-volume-snapshots=false 来关闭存储卷快照备份。
#查看
[root@k8s-master1 velero-v1.10.0-linux-amd64]# kubectl get backupstoragelocation -A -oyaml
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-09-05T06:08:12Z"
generation: 15
labels:
component: velero
name: default
namespace: velero
resourceVersion: "1116179"
uid: 3eb2e6ef-f95e-4674-92c7-8b296f864d57
spec:
config:
region: minio
s3ForcePathStyle: "true"
s3Url: http://minio.velero.svc:9000
default: true
objectStorage:
bucket: velerodata
provider: aws
status:
lastSyncedTime: "2023-09-05T06:14:21Z"
lastValidationTime: "2023-09-05T06:14:21Z"
phase: Available
kind: List
metadata:
resourceVersion: ""
#删除
kubectl delete -n velero backupstoragelocations.velero.io default
kubectl delete deployments.apps -n velero velero
#卸载
velero uninstall
#查看安装状态
[root@k8s-master1 ~]# kubectl get pod -n velero
NAME READY STATUS RESTARTS AGE
minio-597fcfdb94-cksx2 1/1 Running 0 18m
minio-setup-76r5g 0/1 Completed 0 18m
node-agent-frqjq 1/1 Running 0 12m
node-agent-mtb96 1/1 Running 0 12m
node-agent-nlsg7 1/1 Running 0 12m
velero-5bb5bd6699-f8z9q 1/1 Running 0 12m
[root@k8s-master1 ~]# kubectl get crd | grep velero
backuprepositories.velero.io 2023-09-05T06:08:09Z
backups.velero.io 2023-09-05T06:08:09Z
backupstoragelocations.velero.io 2023-09-05T06:08:09Z
deletebackuprequests.velero.io 2023-09-05T06:08:09Z
downloadrequests.velero.io 2023-09-05T06:08:09Z
podvolumebackups.velero.io 2023-09-05T06:08:09Z
podvolumerestores.velero.io 2023-09-05T06:08:09Z
restores.velero.io 2023-09-05T06:08:10Z
schedules.velero.io 2023-09-05T06:08:10Z
serverstatusrequests.velero.io 2023-09-05T06:08:10Z
volumesnapshotlocations.velero.io 2023-09-05T06:08:10Z
#查看安装状态
[root@k8s-master1 ~]# kubectl get backupstoragelocations -A
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT
velero default Available 45s 13m true
【velero通过helm安装】
- http://www.1024sky.cn/blog/article/77733
七、部署测试应用
1)部署测试服务
部署两个测试应用,用来测试备份与恢复结果,使用minio进行备份数据的存储
- mysql 5.7
cd /opt/velero-v1.10.0-linux-amd64/
cat >mysql5.7.yaml<<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: apps/v1 #版本
kind: Deployment #创建资源的类型
metadata: #资源的元数据
name: mysql-dep #资源的名称,是元数据必填项
spec: #期望状态
replicas: 1 #创建的副本数量(pod数量),不填默认为1
selector: #
matchLabels:
app: mysql-pod
template: #定义pod的模板
metadata: #pod的元数据
labels: #labels标签,必填一个
app: mysql-pod
spec: #pod的期望状态
containers: #容器
- name: mysql #容器名称
image: mysql:5.7 #镜像
imagePullPolicy: IfNotPresent
ports: #容器的端口
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "root"
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
---
apiVersion: v1 #版本
kind: Service #创建资源的类型
metadata: #资源的元数据
name: mysql-svc #资源的名称,是元数据必填项
labels: #labels标签
app: mysql-svc
spec: #期望状态
type: NodePort #服务类型
ports: #端口
- port: 3306
targetPort: 3306 #与containerPort一样
protocol: TCP
nodePort: 30306
selector:
app: mysql-pod
EOF
- nginx部署文件
cat >nginx.yaml<<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: managed-nfs-storage
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: my-pvc
containers:
- name: nginx
image: nginx
volumeMounts:
- name: data-volume
mountPath: /var/www/html
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx
EOF
#创建
kubectl apply -f mysql5.7.yaml
kubectl apply -f nginx.yaml
2)编写测内容
kubectl exec -it -n default mysql-dep-58cb9d765f-4sd58 /bin/bash
mysql -uroot -proot
-- 创建测试数据库
CREATE DATABASE testdb;
-- 使用测试数据库
USE testdb;
-- 创建测试表
CREATE TABLE test_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
email VARCHAR(100)
);
-- 插入测试数据
INSERT INTO test_table (name, age, email) VALUES
('John Doe', 25, '[email protected]'),
('Jane Smith', 30, '[email protected]'),
('Mike Johnson', 35, '[email protected]');
select * from test_table;
+----+--------------+------+--------------------------+
| id | name | age | email |
+----+--------------+------+--------------------------+
| 1 | John Doe | 25 | [email protected] |
| 2 | Jane Smith | 30 | [email protected] |
| 3 | Mike Johnson | 35 | [email protected] |
+----+--------------+------+--------------------------+
#退出MySQL和容器
mysql> exit
Bye
bash-4.2# exit
exit
八、测试备份
1)备份总结
1、备份分类
velero 有两种备份有状态数据的方式,对比如下
| 考量维度 | 基于 CSI 快照 | 文件复制 |
|---|---|---|
| 应用性能影响 | 低,CSI 接口调用存储系统快照 | 取决于数据量,占用额外资源 |
| 数据可用性 | 依赖于存储系统,需要使用支持快照的CSI | 对象存储和生产环境隔离,独立可用性,支持跨站点可用性 |
| 数据一致性 | 支持 Crash Consistency,配合 hook 机制实现一致性 | 无保障,基于 hook |
⋓文件复制会进行加密、压缩、增量备份,压缩比在60%左右,备份文件都是加密后的二进制文件,打开乱码
两种文件复制插件:
- Restic(默认) https://restic.readthedocs.io/en/latest/100_references.html#terminology
- Kopia https://kopia.io/docs/advanced/architecture
2、备份最佳实践
- 如果你的存储支持快照,高频本地快照 + 低频 restic 备份到 s3
- 从应用角度选择合适的备份粒度和备份策略
- 多集群环境中共享同一对象存储时要防止冲突
3、同步机制
- 由于velero备份会将本次备份任务的元信息上传到s3中,当在集群中删除了备份任务,但是s3中数据为删除,velero会定时将s3的备份任务同步到集群内
4、坑
- 删除长时间未完成的备份或恢复任务,会导致 velero 阻塞无法处理后续任务
- 当使用文件复制备份方式时,备份文件系统速度变化快的应用,比如Es,Ck十有八九会备份失败
2)备份
- 备份支持全量备份、指定命名空间备份、指定选择器备份等方式,详细可以通过 velero backup create -h查看帮助。
#创建单次的备份任务,备份数据库与nginx
velero backup create test3 --include-namespaces=default --default-volumes-to-fs-backup
常用参数:
- –include-namespaces: 指定命名空间来备份,多个逗号隔开
- –include-resources:指定资源类型来备份,多个逗号隔开比如configmap,secret
- –include-cluster-resources: 设置为 true 表示备份包含集群级别的资源,多个逗号隔开
- –exclude-namespaces: 排查指定命名空间,多个逗号隔开
- exclude-resources: 排除指定某些资源类型
- velero backup get 查看备份
- velero backup describe --details 查看备份数据清单
3)定时备份
#这里我们为了测试将备份周期调整成了每分钟一次
[root@master1 yaml]# velero schedule create schedule-backup --schedule="* * * * *" --include-namespaces=default --default-volumes-to-fs-backup Schedule "schedule-backup" created successfully.
[root@master1 yaml]# kubectl get schedule -A
NAMESPACE NAME STATUS SCHEDULE LASTBACKUP AGE PAUSED
velero schedule-backup Enabled * * * * * 15s
八、恢复
- 首先删除mysql与nginx,我们这里手动删除了nginx与mysql,模拟数据丢失
#删除
cd /opt/velero-v1.10.0-linux-amd64/
kubectl delete -f mysql5.7.yaml
kubectl delete -f nginx.yaml
#查看
kubectl get pod -n default
kubectl get all -n default
-开始恢复,创建恢复策略,从我们之前备份过的备份任务恢复
#查看备份
[root@k8s-master1 ~]# kubectl get backup -A
NAMESPACE NAME AGE
velero test3 5m47s
#恢复
[root@k8s-master1 ~]# velero restore create --from-backup test3
Restore request "test3-20230905145431" submitted successfully.
Run `velero restore describe test3-20230905145431` or `velero restore logs test3-20230905145431` for more details.
#查看恢复记录
[root@k8s-master1 ~]# kubectl get restore -A
NAMESPACE NAME AGE
velero test3-20230905145431 26s
#查看恢复的数据
[root@k8s-master1 ~]# kubectl get pods -n default
NAME READY STATUS RESTARTS AGE
mysql-dep-58cb9d765f-4sd58 0/1 PodInitializing 0 64s
nginx-deployment-7bb559659f-w6tpw 1/1 Running 0 64s
- 等待一会后发现pod已经全部running,检查MySQL是否存在数据。
[root@k8s-master1 ~]# kubectl exec -it -n default mysql-dep-58cb9d765f-4sd58 /bin/bash
bash-4.2# mysql -uroot -proot
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb |
+--------------------+
5 rows in set (0.00 sec)
mysql> use testdb;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from test_table;
+----+--------------+------+--------------------------+
| id | name | age | email |
+----+--------------+------+--------------------------+
| 1 | John Doe | 25 | [email protected] |
| 2 | Jane Smith | 30 | [email protected] |
| 3 | Mike Johnson | 35 | [email protected] |
+----+--------------+------+--------------------------+
3 rows in set (0.00 sec)
九、集群数据迁移
#首先,在集群 1 中创建备份(默认 TTL 是 30 天,你可以使用 --ttl 来修改):
velero backup create <BACKUP-NAME>
#然后,为集群 2 配置 BackupStorageLocations 和 VolumeSnapshotLocations,指向与集群 1 相同的备份和快照路径,并确保 BackupStorageLocations 是只读的(使用 --access-mode=ReadOnly)。接下来,稍微等一会(默认的同步时间为 1 分钟),等待 Backup 对象创建成功。
velero backup describe <BACKUP-NAME>
#最后,执行数据恢复:
velero restore create --from-backup <BACKUP-NAME>
velero restore get
velero restore describe <RESTORE-NAME-FROM-GET-COMMAND>
十、参考地址
【kubeadm】
- http://wed.xjx100.cn/news/186281.html?action=onClick
- http://www.inspinia.net/a/216380.html?action=onClick
- https://www.cnblogs.com/xiaozhi1223/p/16570606.html
- https://cloud.tencent.com/developer/article/2098673
【脚本】
- https://www.cnblogs.com/zhangmingcheng/p/13892140.html
- https://www.cnblogs.com/xiaozhi1223/p/16570606.html
【二进制部署参考】
- https://www.yii666.com/blog/509712.html
- https://www.cnblogs.com/xiaozhi1223/p/16570606.html
【Velero工具】
- https://github.com/vmware-tanzu/velero
【重点参考】
- https://www.jb51.cc/k8s/3812803.html
- https://blog.51cto.com/u_16175439/6627299
- http://yunxue521.top/archives/velero
【腾讯云文档】
- https://www.tencentcloud.com/zh/document/product/457/38939
【备份工具kanister】
- https://zhuanlan.zhihu.com/p/391732609
【优秀博客】
- https://www.hi-linux.com/posts/60858.html