本文推荐浙大团队的一项研究成果:LPCG:Lidar Point Cloud Guided Monocular 3D Object Detection,该论文被ECCV2022接收。

LPCG:用激光点云指导单目的3D物体检测如果用激光点云指导单目的3D物体检测,效果怎么样? https://mp.weixin.qq.com/s?__biz=MzUyMDc5OTU5NA==&mid=2247500597&idx=1&sn=8f2b62adc81e09afaa5c9f0f314b7035&chksm=f9e65730ce91de26820692da915cb13a102e52f5f9cb5c3fbf471674943d996784aaf319c3e9&token=212338627&lang=zh_CN#rd01 简要
https://mp.weixin.qq.com/s?__biz=MzUyMDc5OTU5NA==&mid=2247500597&idx=1&sn=8f2b62adc81e09afaa5c9f0f314b7035&chksm=f9e65730ce91de26820692da915cb13a102e52f5f9cb5c3fbf471674943d996784aaf319c3e9&token=212338627&lang=zh_CN#rd01 简要
在自动驾驶和计算机视觉领域,单目3D物体检测是一项极具挑战性的任务。以前大多数的工作都是手动标注的3D标签框,标注成本很高。
作者团队在工作中有个一个有趣的违反直觉的发现:在单目3D检测中,精确、仔细标注的标签可能并非是必要的!使用受干扰的粗标签的检测器与使用地面真实标签的检测器相比,精度非常接近。作者团队深入研究了这一现象,然后根据经验发现:与标签的其他部分相比,3D位置部分的标签是极其关键的。
受上述结论的启发,并考虑到激光雷达3D测量的精确性,作者团队提出了一种简单有效的框架,称为激光雷达点云引导下的单目3D物体检测(LPCG)。该框架能够在不引入额外注释成本的情况下降低注释成本或显著提高检测精度。
具体来说,它从未标记的LiDAR点云生成伪标签。因为它们的3D位置信息是精确的,所以这种伪标签可以在单目3D检测器的训练中取代手动标注的标签。LPCG可以应用于任何单目3D检测器,以在自动驾驶系统中充分利用大量未标记数据。
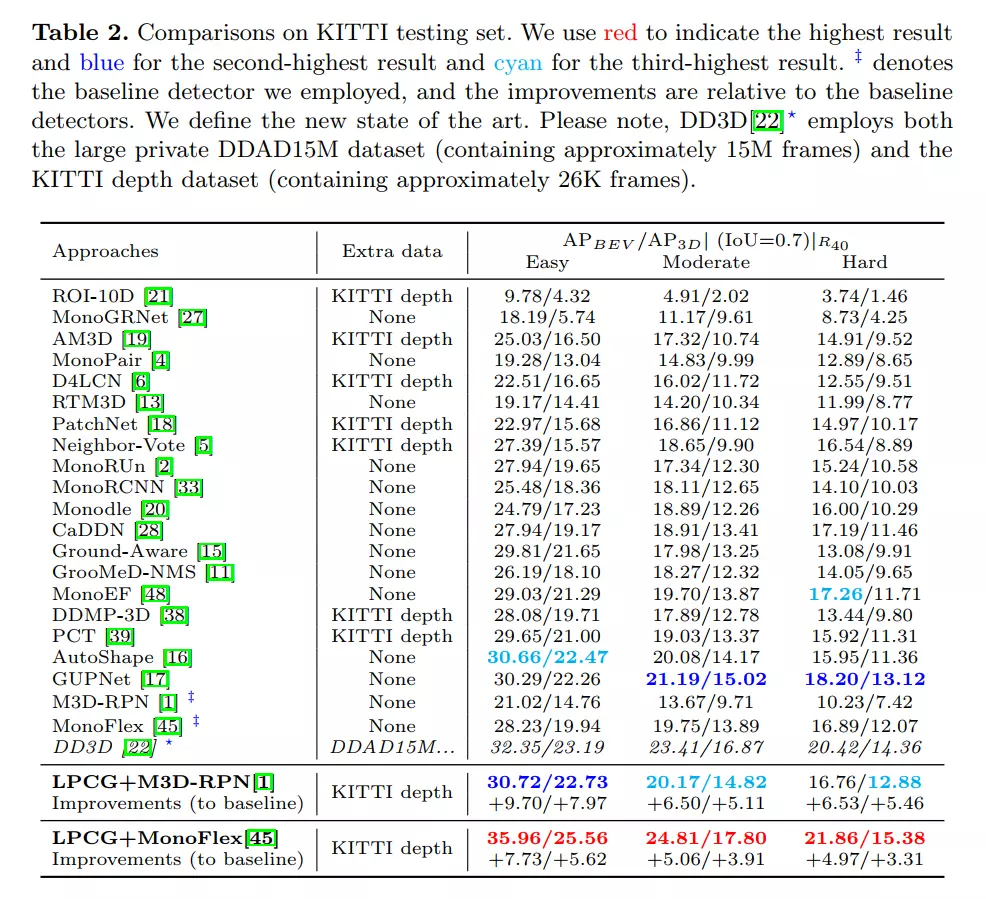
在KITTI基准测试中,LPCG框架在单目3D和BEV(鸟瞰图)检测方面都取得了第一,具有显著的优势。在Waymo基准测试中,作者团队使用10%标记数据的方法与使用100%标记数据的基线检测器的精度相当。

02 模型介绍
首先,如图所示,手动标注的完美标签对于单目3D检测是非必要的。受干扰标签的准确率(5%)与完美标签的准确度相当。当实施大干扰(10%和20%)时,可以看到位置(Location)主导性能(AP仅在干扰位置时显著降低)。这表明,具有精确位置的粗略伪3D box标签可以替代完美的带注释的3D box标签。

我们可以注意到LiDAR点云可以提供有价值的3D Location信息。更具体地说,在场景中,LiDAR点云可以提供精确的深度测量,而周围精确的深度信息可以提供更加精确的物体位置,这对于3D物体检测至关重要。此外,LiDAR点云可以由LiDAR设备轻松获取,允许离线收集大量LiDAR点云,无需人工成本。
基于以上分析,作者团队使用LiDAR点云生成3D立体伪标签。新生成的标签可用于训练单目3D检测器。这种简单有效的方法允许单目3D检测器学习期望目标的同时降低未标记数据的注释成本。在图1中展示了总体框架,根据对3D注释框的依赖,该方法可以在两种模式下工作。如果作者团队像以前一样使用少量的3D框标注,作者团队称之为高精度模式(High Accuracy Mode),因为这种方式会导致高性能。相比之下,如果不使用任何3D长方体注释,作者团队称之为低成本模式。
2.1 高精度模式(High Accuracy Mode)
为了利用可用的3D box标注,如图1所示,作者团队首先使用LiDAR点云和相关的3D box注释从头开始训练基于LiDAR的3D检测器。然后利用预训练的基于激光雷达的3D检测器来推断其他未标记激光雷达点云上的3D box。这样的结果被当作伪标签来训练单目3D检测器。在原文的第5.5节中,作者团队将伪标签与手动注释的完美标签进行了比较。由于精确的3D位置测量,基于LiDAR的3D探测器预测的伪标签相当准确,可以直接用于单目3D检测器的训练。
算法1概要如下:

有趣的是,对于基于LiDAR的3D检测器,使用不同的训练设置,作者团队根据经验发现,由生成的伪标签训练的单目3D检测器显示出接近的性能。这表明单目方法确实可以从LiDAR点云的指导中受益,并且只需要少量的3D注释框就足以推动单目方法实现高性能。这样,高精度模式的手动注释成本比之前的方式低得多。详细实验见原文第5.6节。请注意,对标签要求和3D Location的观察是LPCG的核心动机。LPCG能够正常工作的前提是LiDAR点提供丰富而精确的3D测量信息,从而提供精确的3D位置。
2.2 低成本模式(Low Cost Mode)
在本节中,作者团队将介绍使用LiDAR点云来消除对手动3D立体标签的依赖的方法。
首先,采用现成的2D实例分割模型对RGB图像进行分割,获得2D box和掩模估计(mask estimates)。然后,这些估计值用于构建相机平截头体(camera frustums),以便为每个对象选择相关的LiDAR RoI点,其中忽略了内部没有任何LiDAR点的框。
然而,位于同一平截头体中的激光雷达点由对象点和混合背景或遮挡点组成。为了消除不相关的点,作者团队利用DBSCAN根据密度将RoI点云划分为不同的组。在3D空间中接近的点将聚集到一个簇中。然后,作者团队将包含大多数点的簇视为与对象相对应的目标。最后,作者团队寻找覆盖所有目标点的最小3D边界框。
为了简化解决3D边界框的问题,作者团队将点投影到鸟瞰图上,减少了参数,因为可以很容易地获得对象的高度(h)和y坐标(在相机坐标系下)。因此,作者团队有:
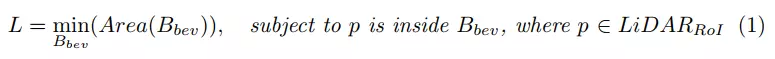
其中是指鸟瞰图(BEV)框。作者团队通过使用物体点的凸包( the convex hull),然后使用旋转卡壳(rotating calipers)获得立方体来解决这个问题。此外,高度h可以由沿着点的y轴的最大空间偏移来表示,并且通过对点的y坐标求平均来计算中心坐标y。作者团队使用限制对象维度的简单规则来删除异常值。
算法2中展示了单目方法的总体训练Pipeline。

03 在真实世界自动驾驶系统中的应用
在本节中,作者团队将描述LPCG在真实世界自动驾驶系统中的应用。

首先,作者团队在图3中说明了数据收集策略。大多数自动驾驶系统可以轻松地同步收集大量未标记的LiDAR点云数据和RGB图像。该数据由多个序列构成,其中每个序列通常指向特定场景并包含多个连续帧。由于现实世界中时间和资源有限,仅选择一些序列进行注释,以训练网络,如Waymo。此外,为了降低高注释成本,仅对所选序列中的一些关键帧进行注释,例如KITTI。因此,在实际应用程序中仍然存在大量未标记的数据。
考虑到LPCG可以充分利用未标记的数据,在现实世界的自动驾驶系统中使用是很自然的。具体而言,高精度模式只需要少量标记数据。然后,作者团队可以从单目3D检测器的剩余未标记数据中生成高质量的训练数据,以提高准确性。在实验中,作者团队定量和定性地表明,生成的3D box伪标签对于单目3D检测器来说是很不错的。此外,低成本模式不需要任何3D注释框,仍然可以提供准确的3D框伪标签。在数据要求方面,作者团队将LPCG与表1中的先前方法进行了比较。

04 总结
在本文中,首先分析了单目3D检测的标签要求。实验表明,受干扰的标签和完美的标签可以做出单目3D检测器的非常接近的性能。随着进一步的探索,作者团队根据经验发现,3D位置是3D框标签的最重要部分。此外,自动驾驶系统可以产生大量未标记的激光雷达点云,这些点云具有精准的3D测量结果。因此,作者团队提出了一个框架(LCPG),在未标记的LiDAR点云上生成伪3D box标签,以扩大单目3D检测器的训练集。在各种数据集上的大量实验验证了LCPG的有效性。但是,由于训练样本的增加,LCPG的主要限制是训练时间更长。