0 RAY相关资料
ray 官网:https://docs.ray.io/en/latest/index.html
Ray分布式计算框架详解:https://zhuanlan.zhihu.com/p/460600694
b站视频:https://www.bilibili.com/video/BV1bP41167x7/
1 ray的简要介绍
Ray是UC Berkeley RISELab新推出的高性能分布式的 Python 框架。该框架能够与 PyTorch 配对,是一款面向AI应用的分布式计算框架。
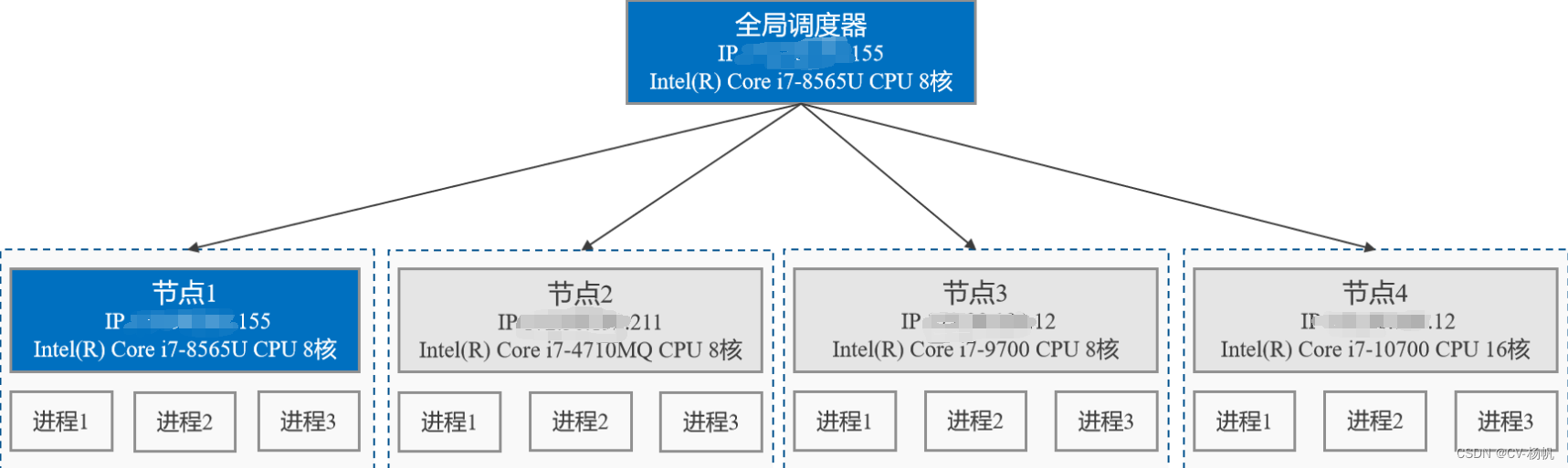
以100个视频的处理为例,利用ray框架将4台机器连接起来测试。全局调度器将100个任务根据机器性能自动分发给不同的机器,A机器32个任务,B机器16个任务,C机器36个任务,D机器处理16个任务,其中每台机器并行处理。
2 ray的搭建
1、将Anaconda安装至同一根目录下,将计算引擎放置在同一根目录下,连接同一网络,确保处于同一局域网下(注意:ray框架要求环境安装位置与命名相同才可进行多台服务器集群);
2、在多台服务器中创建相同命名的虚拟环境(以moon为例),python版本为同一版本;
3、进入moon虚拟环境;
输入命令:conda activate moon
4、下载ray及项目所需其他依赖包;
输入命令:pip install ray==2.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
5、查看服务器ip地址,并将其中一台设置为头节点;
输入命令:ray start --head --node-ip-address xx.xx.xx.155
6、查看服务器ip地址,并将其余服务器设置为从节点;
输入命令:
ray start --address=“xx.xx.xx.155:6379”–node-ip-address=“xx.xx.xx.211”
其中–address=“头结点的ip地址:头结点的端口号”,–node-ip-address=“从节点的ip地址”
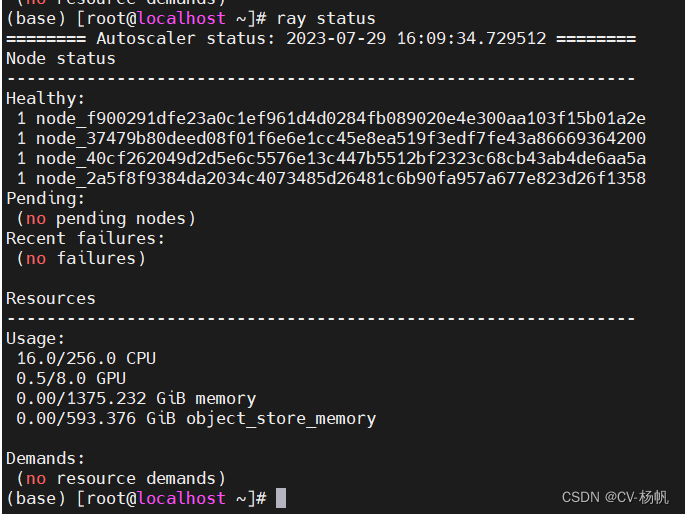
7、查看集群部署的cpu总核数,若cpu总核数与集群中设置的头节点+从节点的总核数相同,则集群无误。直接在主节点调用计算引擎,即可实现并发;
查看集群部署的cpu总核数命令:ray status
8、终止已启动的进程。
输入命令:ray stop
3 ray的调用
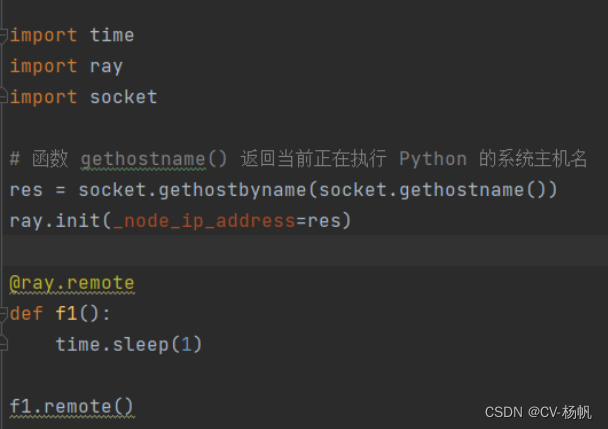
1、在原代码的基础上加入获取正在执行 Python 的系统主机名:
res = socket.gethostbyname(socket.gethostname())
ray.init(_node_ip_address=res)
2、并在需要并行运行的方法前加上:
@ray.remote
3、调用主方法改为
XX.remote
普通方法调用:

基于ray的分布式方法调用:
4 实践代码分析
这里我暂时只能展示项目中的代码
4.1 ray的配置
首先,有四台连着局域网的机器:
xx.xx.xx.247
xx.xx.xx.248
xx.xx.xx.249
xx.xx.xx.250
每台机器都需要进入到moon环节
conda activate moon
使用xx.xx.xx.247作为头节点
ray start --head --node-ip-address xx.xx.xx.247
从节点:
xx.xx.xx.248
ray start --address="xx.xx.xx.247:6379" --node-ip-address="xx.xx.xx.248"
xx.xx.xx.249
ray start --address="xx.xx.xx.247:6379" --node-ip-address="xx.xx.xx.249"
xx.xx.xx.250
ray start --address="xx.xx.xx.247:6379" --node-ip-address="xx.xx.xx.250"
4.2 代码中使用ray
下面给是相关代码
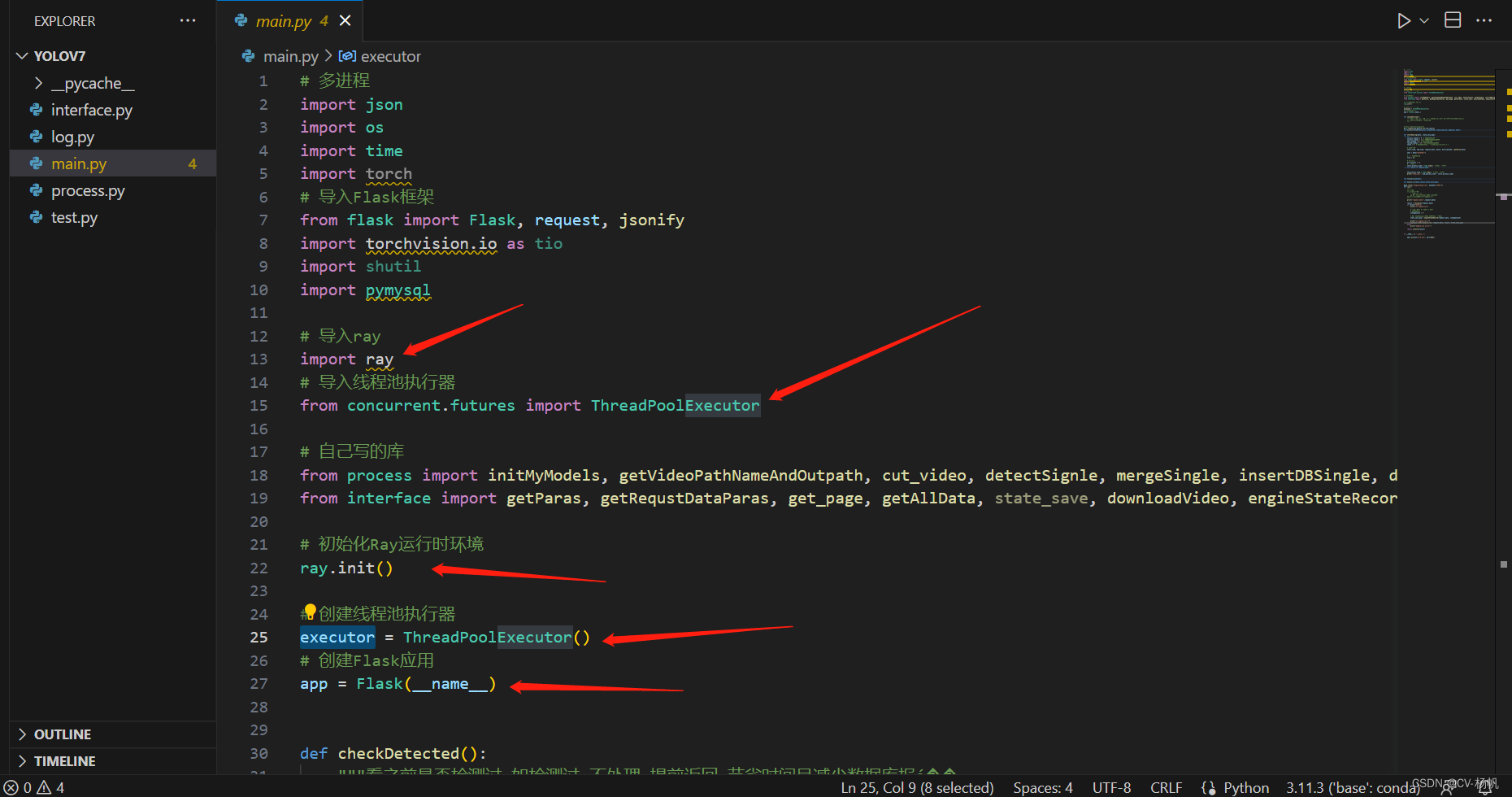
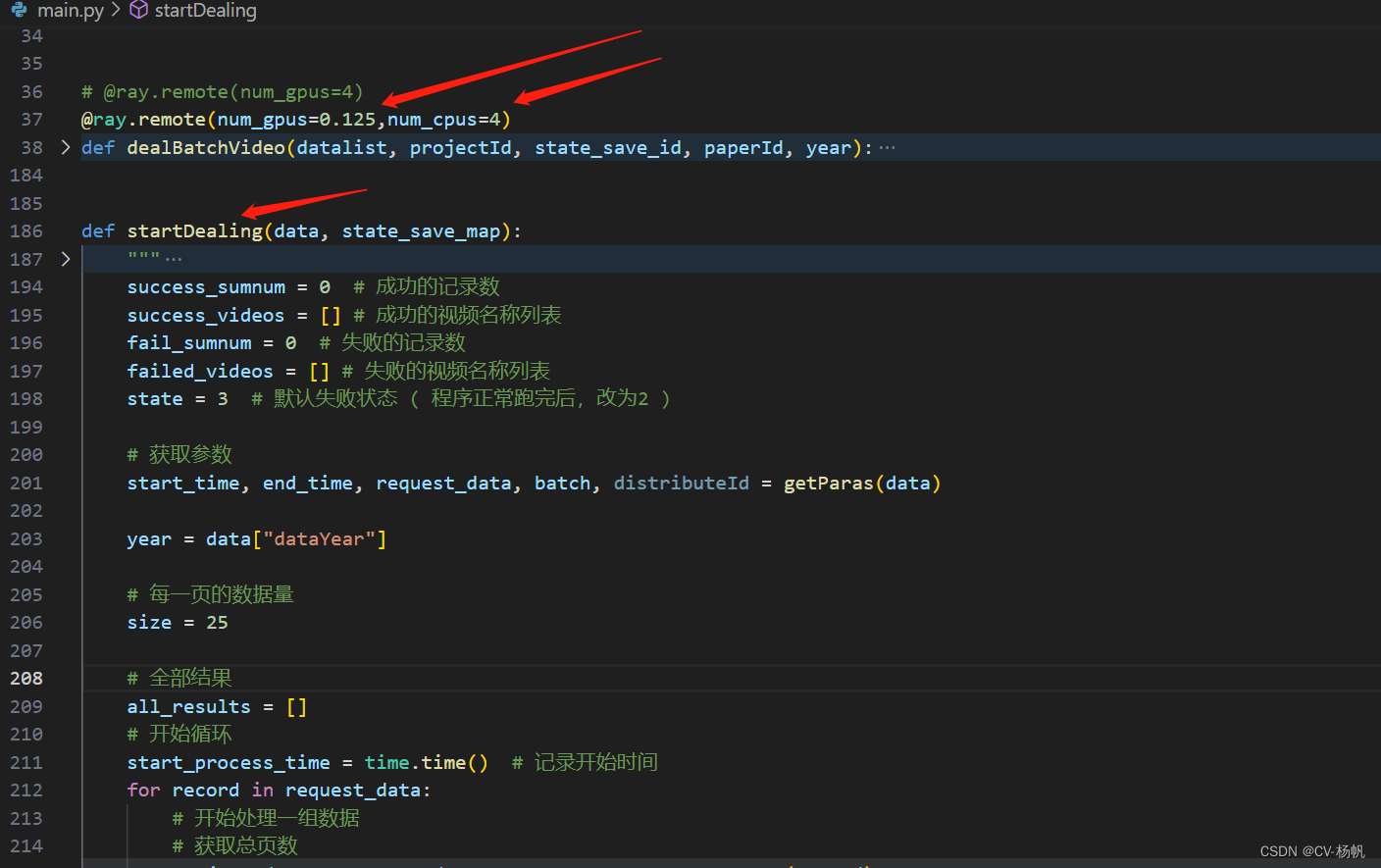
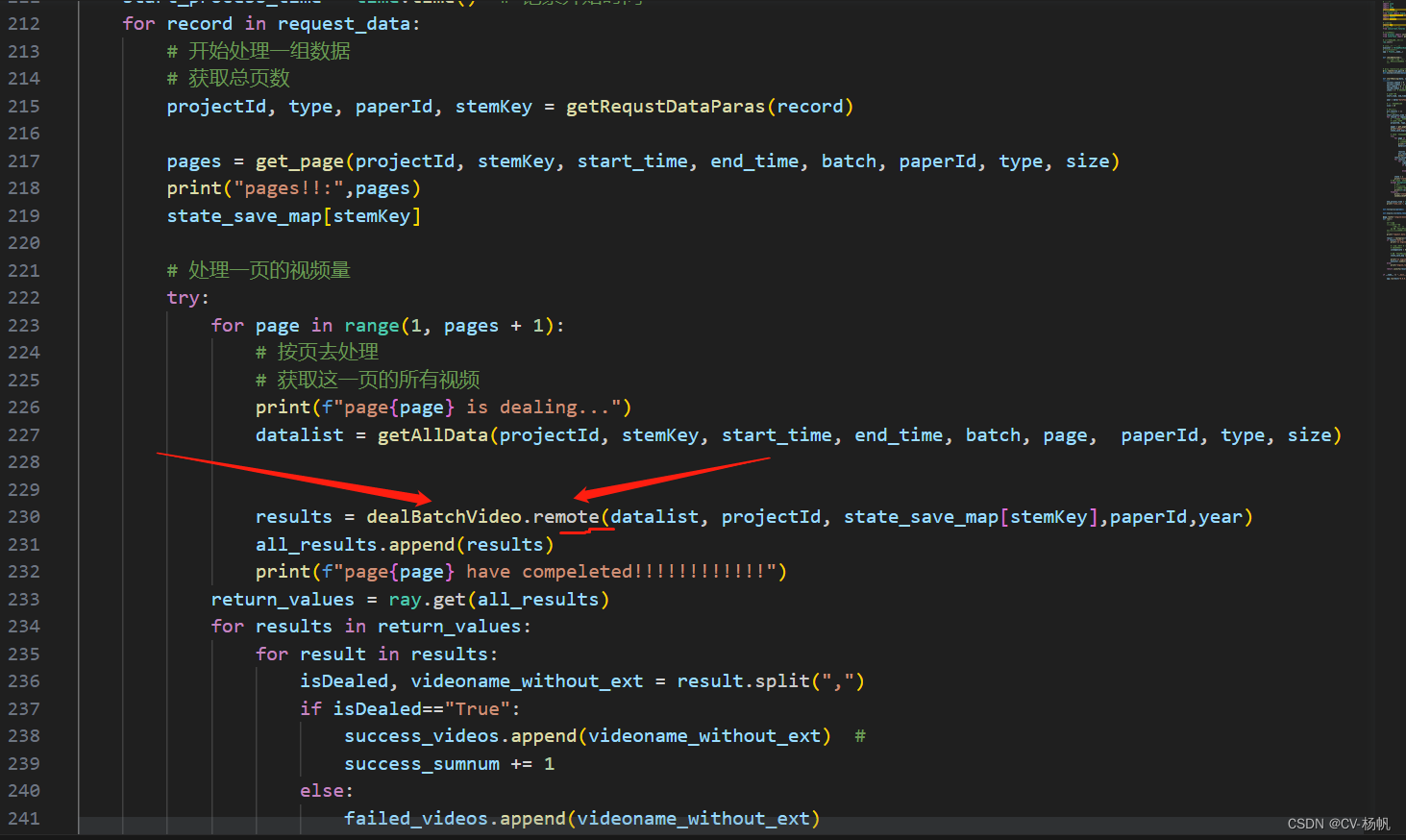
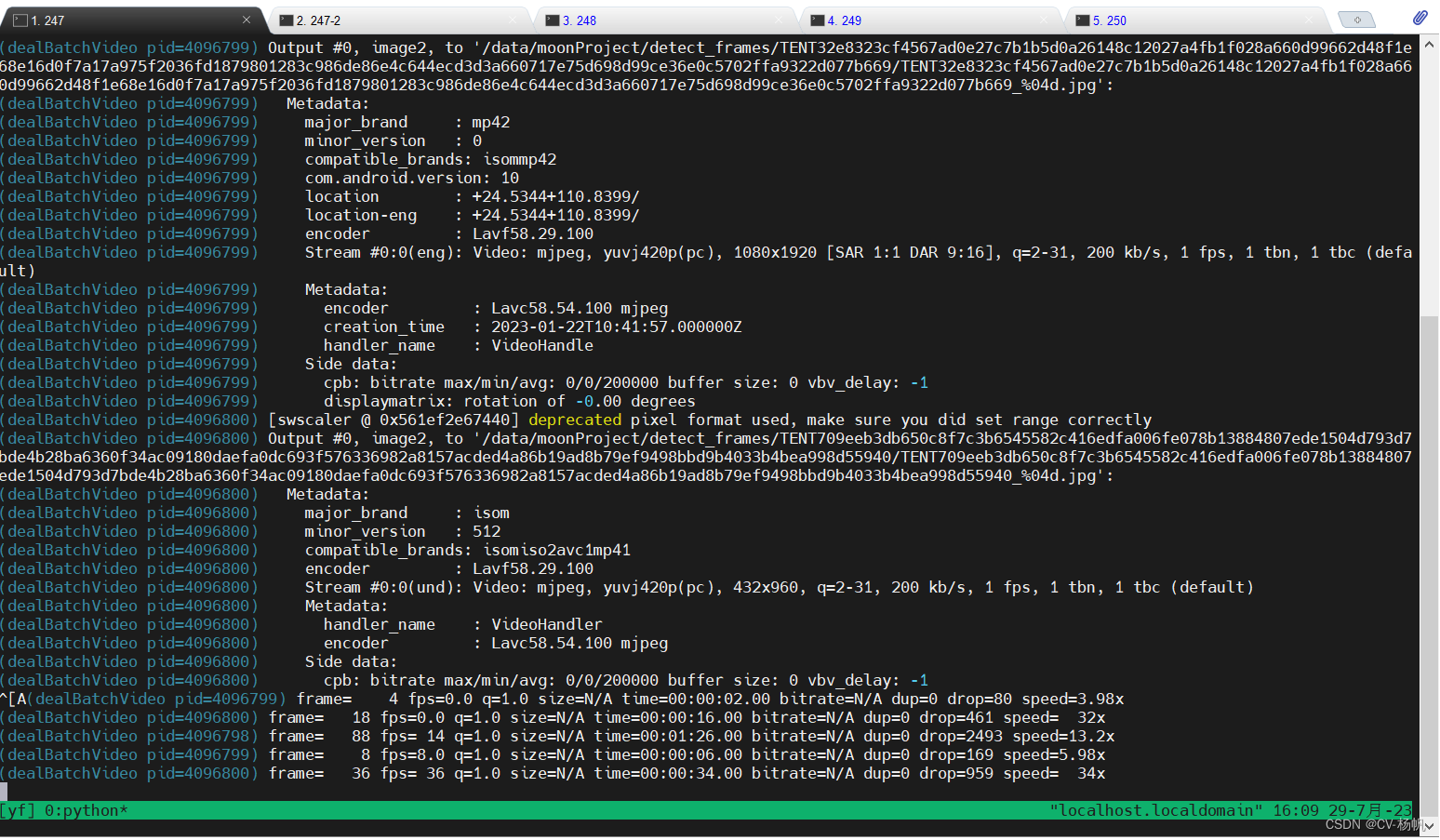
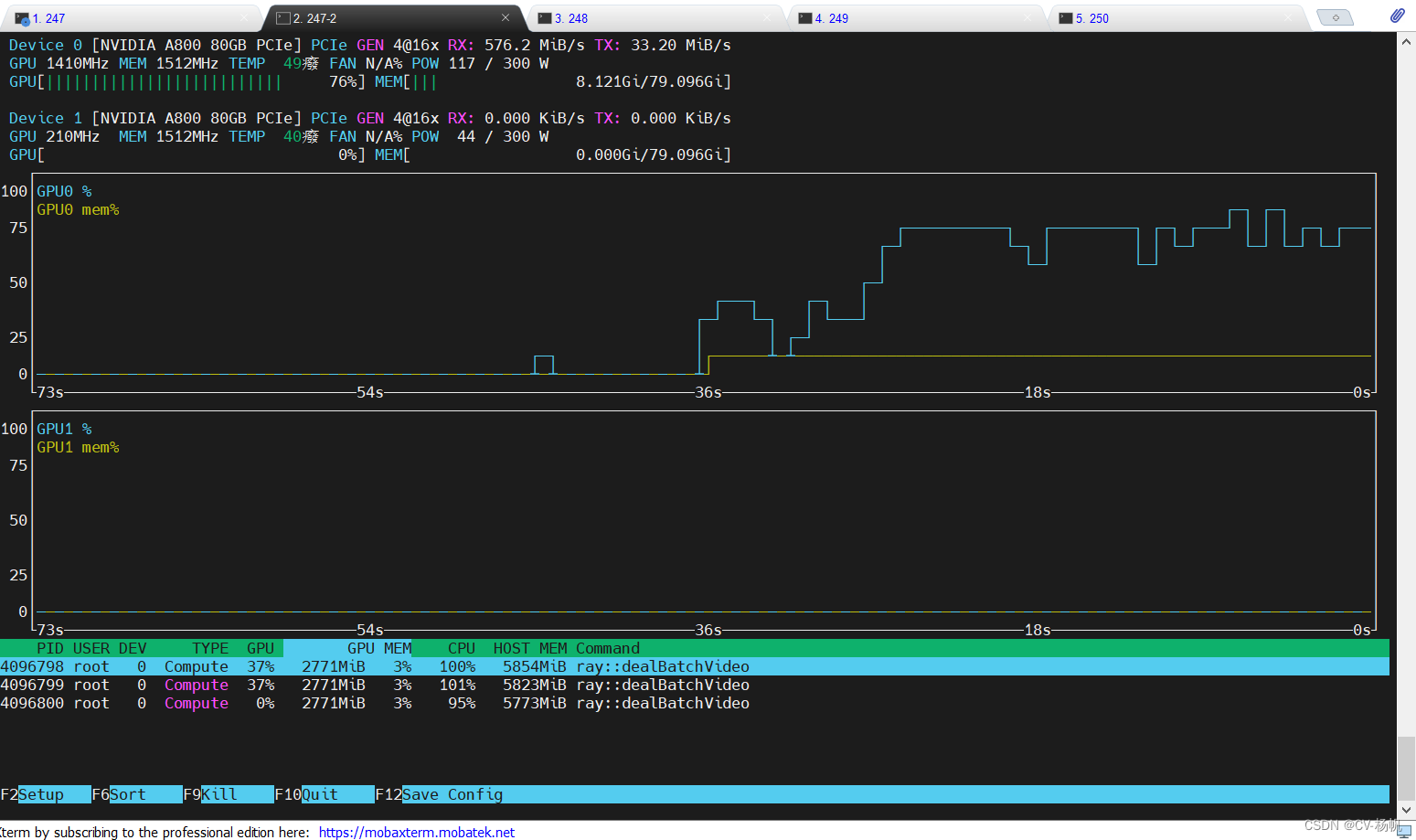
项目运行后的样子: