目录
【一】YOLO系列中输入侧结构的特点
YOLO系列中的输入侧结构主要包含了输入图像,数据增强算法以及一些预处理操作。
输入侧可谓是通用性最强的一个部分,具备很强的向目标检测其他模型,图像分类,图像分割,目标跟踪等方向迁移应用的价值。
从业务侧,竞赛侧,研究侧等角度观察,输入侧结构也能在这些方面比较好的融入,从容。
【二】YOLOv1 输入侧解析
YOLOv1的输入侧有着朴素的逻辑,做的最多的工作是调整输入图像的尺寸以支持对图像细粒度特征的挖掘与检测。
同样的,YOLO系列的grid逻辑(“分而治之”)也从输入侧开始展开,直到Head侧输出相应结果。


【Rocky的延伸思考】
- 业务侧:YOLOv1 输入侧逻辑非常适合作为新业务的实验性Baseline,快速搭建,快速试错。
- 竞赛侧:YOLOv1 输入侧坦率来说在竞赛中已不具备竞争力,但作为Baseline入场模型也未尝不可。
【三】YOLOv2 输入侧解析
YOLOv2的输入侧在YOLOv1的基础上引入了多尺度训练(Multi-Scale Training),并且优化了预训练模型(High Resolution Classifier)。
多尺度训练(Multi-Scale Training)的逻辑是模型每训练一定的Epoch,改变输入图片的尺寸,使得模型对不同的输入尺寸更鲁棒,能够从容地对不同尺寸的图像进行检测。
论文中使用32的倍数作为输入的尺寸,具体使用了320、352、384、416、448、480、512、544、576、608这10种尺寸。
在预训练模型这块,YOLOv2使用了High Resolution Classifier思想。一般基于ImageNet预训练的模型的输入尺寸都是小于256*256的。YOLOv2使用的输入尺寸是448*448,比YOLOv1的要大,故预训练模型网络需要使用大分辨率输入在ImageNet上进行微调。经过这个操作,YOLOv2的mAP提升了4%。
【Rocky的延伸思考】
- 业务侧:YOLOv2 输入侧的多尺度训练思想完全可以应用于业务baseline模型。
- 竞赛侧:YOLOv2 输入侧的多尺度训练思想在竞赛侧是一个提分利器。
- 研究侧:YOLOv2 输入侧的多尺度训练思想以及High Resolution Classifier具备作为baseline的价值,不管是进行拓展研究还是单纯学习思想。
【四】YOLOv3 输入侧解析
在YOLOv3输入侧Rocky想引入常用基础数据增强技术和高阶数据增强算法。

因为不管是YOLO系列还是二阶段目标检测系列;不管是目标检测还是图像分类和分割,基础数据增强技术和高阶数据增强算法都有很强的实用价值。
高阶数据增强算法:

其中RandErasing将图像的部分区域替换为随机值,或者是训练集的平均像素值。

而GridMask则使用了一个网格掩码,并将掩码进行随机翻转,与原图相乘,从而得到增广后的图像,通过超参数控制生成的掩码网格的大小。

基于NAS搜索的AutoAugment在一系列图像增强子策略的搜索空间中通过搜索算法找到适合特定数据集的图像增强方案。针对不同类型的数据***包含不同数量的子策略。每个子策略中都包含两种变换,针对每张图像都随机的挑选一个子策略,然后以一定的概率来决定是否执行子策略中的每种变换方法。

其余方法的细节知识,Rocky将在后续的高阶数据增强专题文章中依次展开,大家敬请期待。
常用基础数据增强技术:
- 颜色变换:在色彩通道空间进行数据增强,比如将某种颜色通道关闭,或者改变亮度值。
- 旋转变换:选择一个角度,左右旋转图像,可以改变图像内容朝向。
- 添加噪声:从高斯等分布中采样出的随机值矩阵加入到图像中。
- 锐化和模糊:使用高斯算子,拉普拉斯算子等处理图像。
- 缩放变换:图像按照比例进行放大和缩小并不改变图像中的内容。
- 平移变换:向上下左右四个维度移动图像。
- 翻转变换:关于水平或者竖直的轴进行图像翻转操作。
- 裁剪变换:主要有中心裁剪与随机裁剪。
- 仿射变换:对图像进行一次线性变换并接上一个平移变换。
【Rocky的延伸思考】
- 基础数据增强技术和高阶数据增强算法不管是在业务侧,竞赛侧还是研究侧都能非常稳定的带来性能的提升。
【五】YOLOv4 输入侧解析
YOLOv4的输入侧在YOLOv3的基础上,使用了Mosaic和CutMix高阶数据增强来提升模型的整体性能。
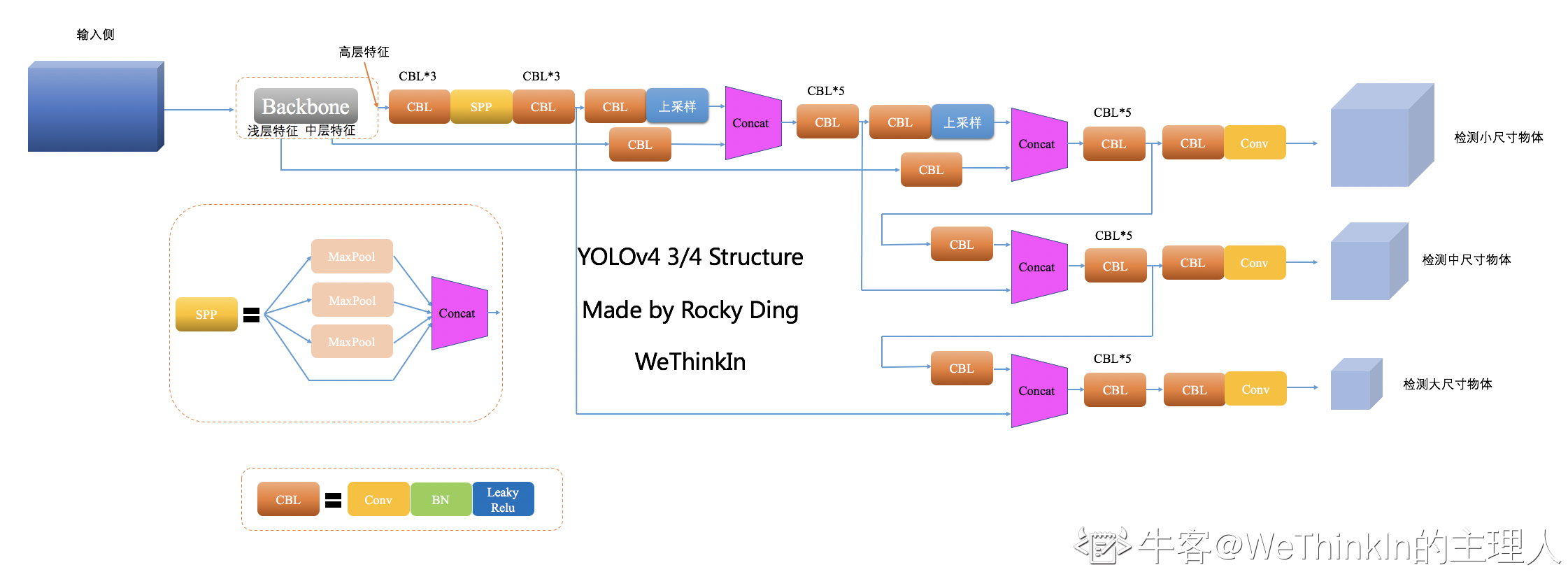
Mosaic数据增强技术从经典的CutMix优化而来。在CutMix的逻辑中,使用两张图片分别选取部分像素进行拼接,产生新的数据。而Mosaic则在此基础上图片数量增加到四张,并采用随机缩放,裁剪和排布的方式进行拼接。

Mosaic数据增强的优点:
- 优化模型对小目标的检测效果。
- 减少训练算力,由于一次性可以计算4张图片,所以Batch Size可以不用很大,也为YOLOv4在一张GPU卡上完成训练奠定了数据基础。
- 依然是一种增强数据操作,让模型的鲁棒性与泛化性能更优。
而上面提到的CutMix则从Mixup和Cutout优化而来。

由上图可知,Mixup将两张图片按比例混合,其label也按同等比例分配;Cutout则是将图片中的部分像素区域置0,但是label不变;CutMix则是在Cutout的基础上对置0的像素区域随机填充其他图像的部分像素值,label则按同等比例进行分配。

其中,M是二进制0,1矩阵,用来标记需要裁剪的区域和保留的区域,裁剪的区域值均为,其余位置为。图片和组合得到新样本,最后两个图的label也对应求加权和。
CutMix的优势:
- 由于采用填充的形式,合成的图片不会有不自然的混合情形。
- 高价值信息增多,提升训练效率,优化算法性能。
- 作为YOLOv4的Bag of freebies,其不增加模型的推理耗时。
- 增加算法的局部识别与局部定位能力。
- 在输入侧,起到了类似dropout的作用。
【Rocky的延伸思考】
- 业务侧:YOLOv4 输入侧中使用的高阶数据增强可以方便地在业务场景中使用。
- 竞赛侧:YOLOv4 输入侧中提到的Mosaic,CutMix等高阶数据增强在竞赛中是比较有效的Tricks。
- 研究侧:YOLOv4 输入侧具备作为研究Baseline的价值。
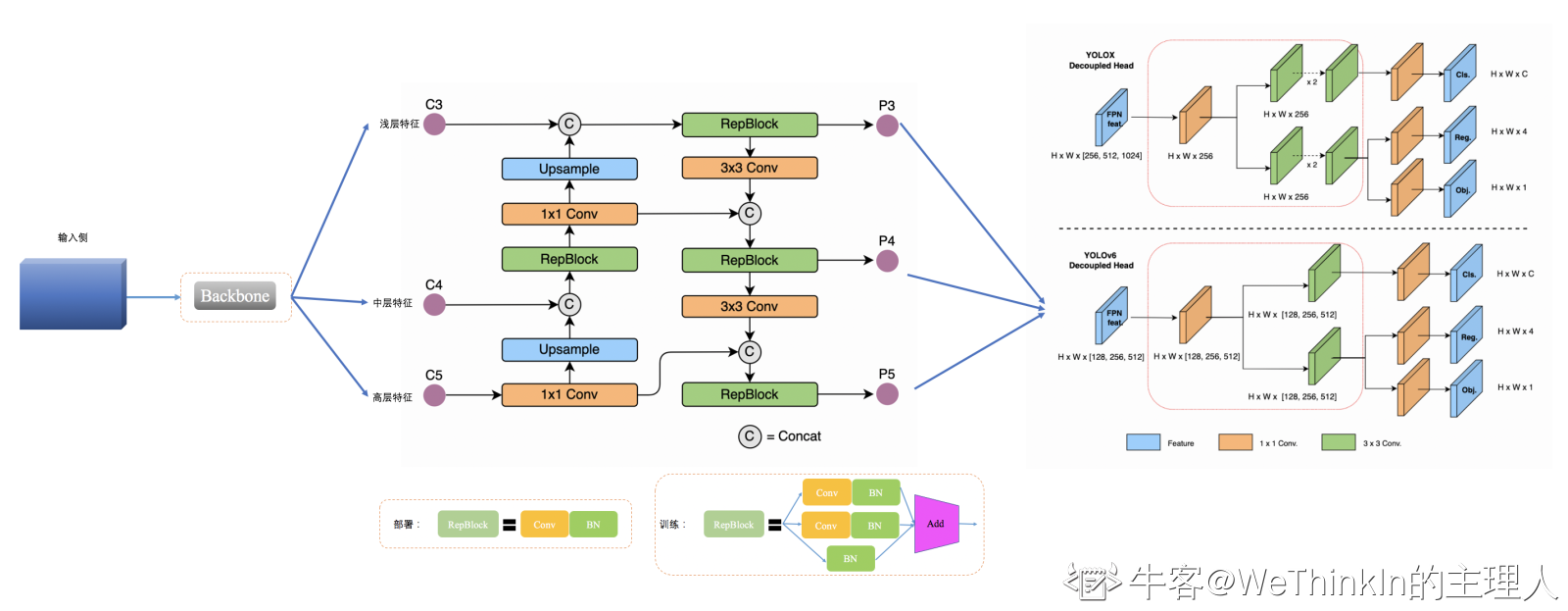
【六】YOLOv5 输入侧解析
YOLOv5的输入侧同样使用了Mosaic高阶数据增强策略,并增加自适应图像调整策略。

值得一提的是,正是Mosaic论文的作者提出了YOLOv5,并且YOLOv5的输入侧做了很多工程优化,对工业界非常友好。
而自适应图像调整策略可以优化常规图像缩放填充引入过多无效信息导致Inference耗时增加的问题。其逻辑主要是计算图像原生尺寸与输入尺寸的缩放比例,并获得缩放后的图像尺寸,最后再进行自适应填充获得最后的输入图像,具体代码逻辑可以在datasets.py的letterbox函数中查看。
【Rocky的延伸思考】
- YOLOv5 输入侧的易用性使得其不管在业务侧,竞赛侧还是研究侧都非常友好。
【七】YOLOx 输入侧解析
YOLOx的输入侧在YOLOv5的基础上摒弃了预训练逻辑,并使用Mosaic和MixUp高阶数据增强算法。
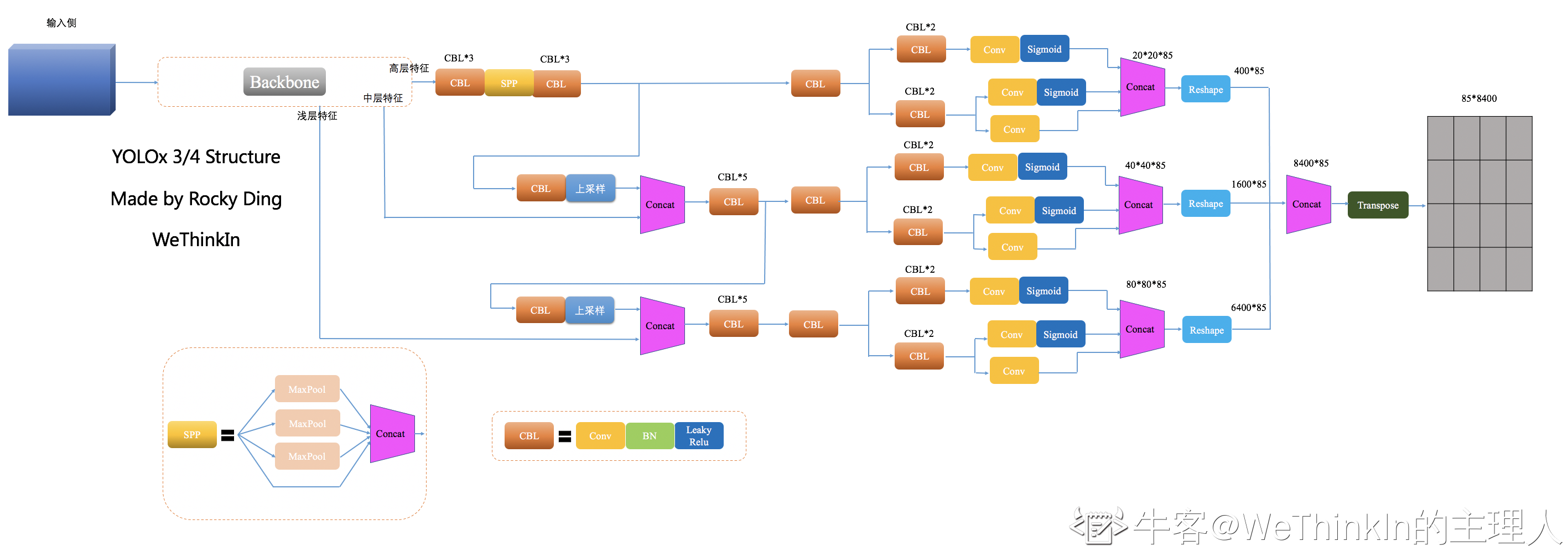
MixUp最初应用在分类任务上,将两张图片通过设定的融合系数进行融合,两个图片上的label也对应融合。

由于Mosaic和MixUp高阶数据增强算法已经足够强大,在这种情况下ImageNet预训练并不能带来有效增益,故YOLOx摒弃了预训练逻辑,并从头训练。
【Rocky的延伸思考】
- YOLOx 输入侧的逻辑给业务侧,竞赛侧以及研究侧提供了一些新思路,可以尝试将分类和分割领域的高阶增强算法往目标检测迁移应用。
【八】YOLOv6-v7 输入侧解析
YOLOv6-v7的输入侧沿用了YOLOv5的整体逻辑,并没有引入新的Tricks,故就不再展开赘述。