目标检测xml标注转txt标注
FAIR1M数据集的原始标注格式为xml标注,具体为:

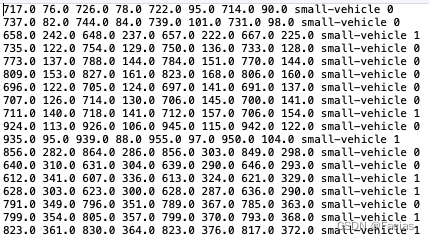
而DOTA数据集标注为txt文件,格式如下:
我想用DOTA数据集的格式去训练FAIR1M数据集,代码如下:
import os
import sys
import xml.etree.ElementTree as ET
import glob
def xml_to_txt(indir, outdir):
# os.chdir(indir) # 切换到给定目录下
annotations = os.listdir(indir)
for i, file in enumerate(annotations):
file_save = file.split('.')[0]+'.txt'
file_txt=os.path.join(outdir, file_save)
f_w = open(file_txt, mode='w+', encoding='UTF-8')
# actual parsing
in_file = open(indir + '/' + file)
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
current = list()
name = obj.find('possibleresult').find('name').text
name = name.replace(" ", "-") #FAIR1M的类别标注会有空格,用-代替
xmlbox = obj.find('points')
points = xmlbox.findall('point')
poly_list = []
for point in points:
point = point.text
point = point.split(",")
poly_list = poly_list + point
f_w.write(poly_list[0] + ' ' + poly_list[1] + ' '+ poly_list[2] + ' ' + poly_list[3] + ' ' +
poly_list[4] + ' '+ poly_list[5] + ' ' + poly_list[6] + ' ' + poly_list[7] + ' ' + name + ' ' + '0' + '\n')
f_w.close()
indir='train/labelXml' #xml目录
outdir='train/labelTxt' #txt目录
if __name__ == "__main__":
xml_to_txt(indir, outdir)
另外给出FAIR1M的类别名称统计代码:
import os
import os.path
import numpy as np
import cv2
import matplotlib.pyplot as plt
train_list = os.listdir("/workspace/FAIR1M2/train/labelTxt/")
base_path = "/workspace/FAIR1M2/train/labelTxt/"
total_dict = []
for file in train_list:
with open(base_path + file) as f:
s = f.readlines()
for si in s:
bbox_info = si.split()
if bbox_info[8] in total_dict:
continue
else:
total_dict.append(bbox_info[8])
print(total_dict)
print(len(total_dict))