一、jdk1.8流实现并行是很简单的,只要在流上加parallel()方法。这个方法的并行原理是使用了fork/join递归的方式进,我们在开发中使用并行时,最关注的一个问题是共享变量。一种常用的方式是每次在使用时克隆这个变量,通过修改克隆变量而不影响原变量的方式,达到已占用更多的内存换取性能。当然这里不是我要讨论的,本次要讲的流并行时,如何分割数据或者说是任务。
1、我们做一个简单的字符串的单词个数计算,计算字符串有多少个单词,现有的流提供的操作方法中没有相应的处理,这里变通一下处理,把String变成Stream流,代码下如:

对字符处理的逻辑放在CounterWord类中,因为需要保存上一个字符是否为空。我们用流的reduce方法做归约统计。下面是CounterWord类的代码:

发现结果是7,正确,然后我们用并行来执行这段代码:
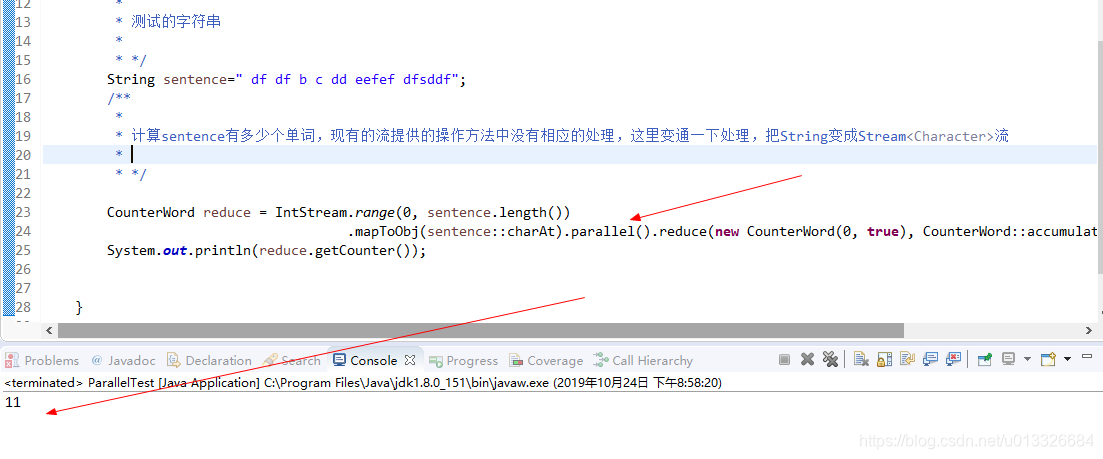
发现结果是11呢,原因并行时用fork/join方式,分割时把字符串里的有些单词给拆分成两个单词,所以单词数结果比正常的要多。我们要约束它的分割策略。
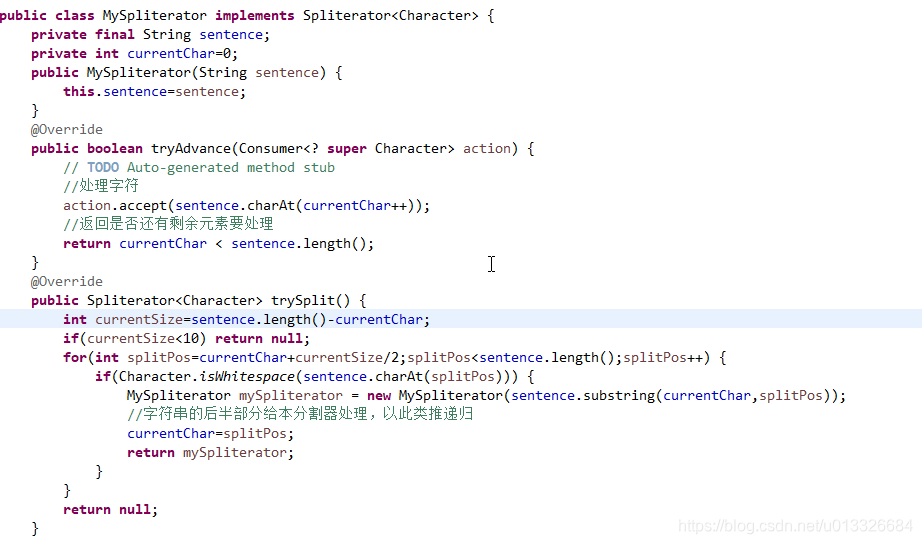
2、Spliterator接口就是给客户自定义分割器的,看它类的继承结构,你会发现有大量它的实现。它有以下几个抽象接口:
tryAdvance(Consumer<? super T> action),如果流中还有剩余的元素就消费它,同时返回true,否则返回false,表示流中已没有元素要处理。
trySplit(),处理分割策略的逻辑方法,返回一个Spliterator分割器。
estimateSize(),评估剩余还需要分割的大小,只是评估,不准确。
characteristics(),分割器的一些特性。
以下是分割的实现代码:


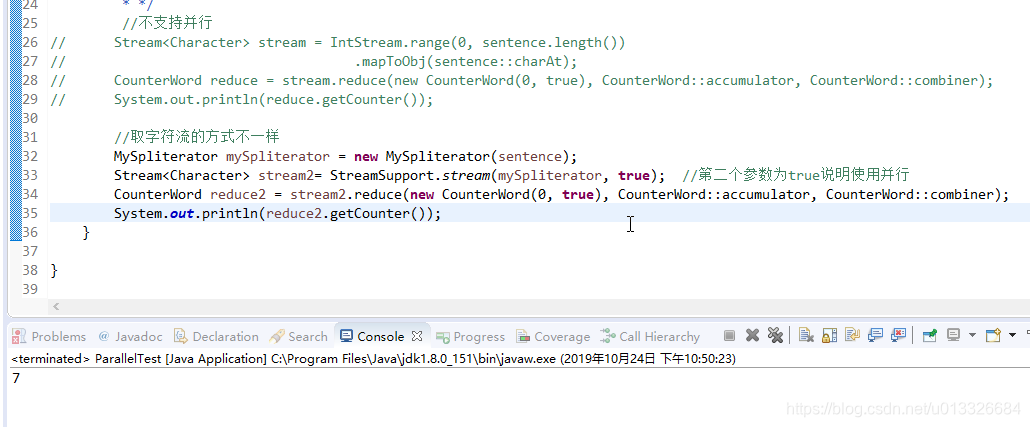
这里要区分自定义的分割器跟计算单词个数的处理器。两个都是递归操作,前面是分割字符串,后面的是计数单词。换句话,就是前面的分割器会并行的分割成几个字符串数据源,后面的计数器也并行的对各个数据源进行递归计算。
stream并行自定义分割器spliterator
猜你喜欢
转载自blog.csdn.net/u013326684/article/details/102711168
今日推荐
周排行