系列文章目录
大家移步下面链接中,里面详细介绍了stable diffusion的原理,操作等(本文只是下面系列文章的一个写作模板)。
stable diffusion实践操作
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
经过SDXL0.9和SDXL Beta的迭代,终于SDXL1.0正式版发布了! 之前使用AIGC生成图片,一般都是生成512512的图,然后再进行放大,以达到高清出图的要求。但是这里有个问题是底模其实都是海量的512512图片训练出来的,所以出图效果上经常不如人意,在细节上会差一些。这次SDXL1.0直接使用10241024的海量图片训练底模,而且分为了文生图用的base模型和图生图进行优化和放大的refiner模型,从而实现了不输于Midjourney的出图效果。
经过SDXL0.9和SDXL Beta的迭代,终于SDXL1.0正式版发布了!
之前使用AIGC生成图片,一般都是生成512512的图,然后再进行放大,以达到高清出图的要求。但是这里有个问题是底模其实都是海量的512512图片训练出来的,所以出图效果上经常不如人意,在细节上会差一些。这次SDXL1.0直接使用10241024的海量图片训练底模,而且分为了文生图用的base模型和图生图进行优化和放大的refiner模型,从而在开源免费的文生图软件上实现了不输于Midjourney的出图效果。
提示:以下是本篇文章正文内容,下面案例可供参考
1. SDXL 有哪些优化
1. SDXL和SD1.5模型有什么差别
SDXL与原来的SD1.5模型除了大小不同外,最大区别是SDXL由base基础模型和refiner优化模型两组模型构成。您需要先运行基础模型,然后再运行细化模型。基础模型设置全局组成,而细化模型则添加更细节的细节。您也可以选择仅运行基础模型。
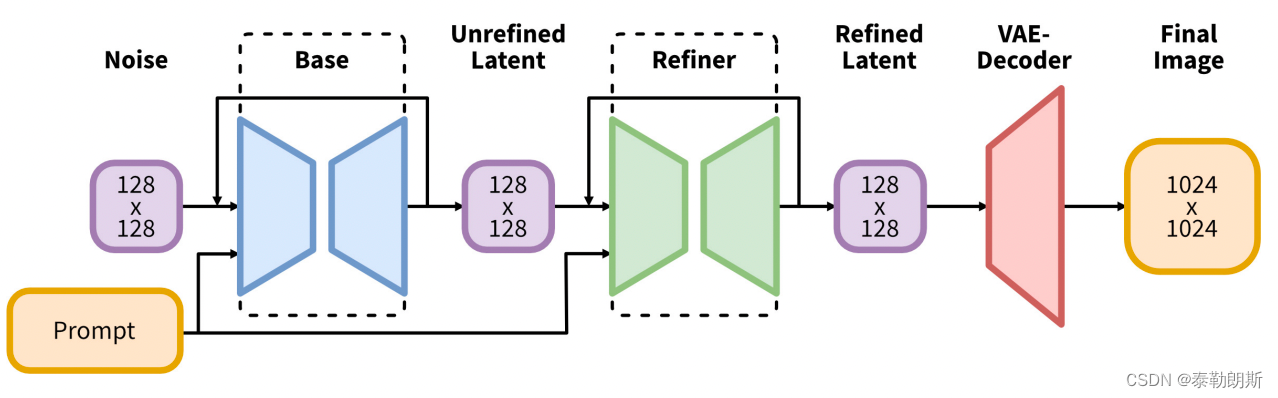
语言模型(理解您Prompt提示的模块)是最大的OpenClip模型(ViT-G/14)和OpenAI专有的CLIP ViT-L的组合。这是一个聪明的选择,因为Stable Diffusion v2仅使用OpenClip,很难提示成功。重新引入OpenAI的CLIP可以使提示更容易。在v1.5上有效的提示在SDXL上也有很好的甚至更佳的效果。
扩散模型中最重要的部分U-Net现在大了3倍。加上更大的语言模型,SDXL模型可以生成与提示紧密匹配的高质量图像。
因为底模是10241024训练的,比原来的512512大了4倍,所以底模base基础模型大小也达到接近7GB,refiner也是差不多7GB,对硬件(GPU显存)的要求更高了!如果只有8G以下的显存,建议还是别碰SDXL了
2. 图片的真实感更强
因为对提示词的语义理解更准确,加上底模的分辨率更高,所以对光线、画质、镜头、角度、焦点等等的渲染更到位,以下是我使用提示直接基于XL base模型产生的图片。
photo of young Chinese woman, highlight hair, sitting outside restaurant, wearing dress,
rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus,
tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes,
high detailed skin, skin pores
 ## 3.对文字的渲染更可靠 之前在SD1.5时,是无法在提示词中提升图片中有哪些文字的,现在在SDXL中,可以比较好的实现对英文单词的渲染,不过有时候也要看运气,经常也会渲染的有些瑕疵,不过瑕不掩瑜,聊胜于无,总是一个不小的进步。这是提示词:
## 3.对文字的渲染更可靠 之前在SD1.5时,是无法在提示词中提升图片中有哪些文字的,现在在SDXL中,可以比较好的实现对英文单词的渲染,不过有时候也要看运气,经常也会渲染的有些瑕疵,不过瑕不掩瑜,聊胜于无,总是一个不小的进步。这是提示词:
A fast food restaurant on the moon with name "zhoulilian"

2、安装下载
SDXL1.0大模型和vae下载
当前我们并没有下载SDXL1.0的底模,需要手动从HuggingFace下载,具体URL:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors
这两个文件是底模,大约7个G每个文件。
下载到GPU服务器后,需要放到stable-diffusion-webui/models/Stable-diffusion文件夹中。另外还有一个VAE文件,是可选的,下载地址:
https://huggingface.co/stabilityai/sdxl-vae/resolve/main/sdxl_vae.safetensors
下载后放到stable-diffusion-webui/models/VAE 文件夹中。
然后我们来SD WebUI,刷新底模列表,即可看到XL的base和refiner模型。
至于VAE,默认是不显示在UI中的,可
总结
`1.之前在SDXL1.0发布之前,需要给sd-webui安装Demo扩展才能使用SDXL,现在不需要了,所以如果之前已经安装了Demo扩展的可以删除掉了。
2.直接出尺寸在1024或者之上的图,不要出512*512的图。
3.之前下载的Lora和底模、Embedding等都不能在SDXL1.0上使用,所以需要重新从C站下载专门的SDXL版。很多Lora都没有出XL版Lora,所以大家还是等等生态丰富了再作为生产工具吧。
4.Lora训练工具也更新了,有对应的SDXL版本分支,所以要搞Lora训练的同学,记得切换训练工具的版本,重新训练属于自己的XL Lora。
