在项目中经常会遇到中文传参数,在后台接收到乱码问题。那么在遇到这种情况下我们应该怎么进行处理让我们传到后台接收到的参数不是乱码是我们想要接收的到的,下面就是我的一些认识和理解。
get请求url中带有中文参数,有三种方式进行处理防止中文乱码
1、如果使用tomcat作为服务器,那么修改tomcat配置文件conf/server.xml中,在 <Connector port="8082" protocol="HTTP/1.1" 中加入 URIEncoding="utf-8"的编码集
2、前台需要对中文参数进行编码,调用js方法encodeURI(url),将url编码,然后请求。
后台接受时,需处理String str = new String(request.getParameter("param").getBytes("iso8859-1"),"UTF-8");
原因:tomcat不设置编码时,默认是iso8859-1,即tomcat默认会以iso8859-1编码接收get参数。 以上操作是将参数以iso8859-1编码转化为字节数组,然后再以UTF-8将字节数组转化为字符串。
另外需注意在框架的使用中:request.setCharacterEncoding(encoding);只对post请求有效。而且,spring的CharacterEncodingFilter也只是做了request(和response).setCharacterEncoding(encoding);的操作。所以spring的filter配置不作用于get参数接收。
3、解决get请求,后台接受中文参数乱码处理的方法(搜索功能带参数)

(1)前台获取数据,在js中进行编码处理

encodeURI函数采用utf-8进行编码,而在服务器的进行解码时候,默认都不是以uft-8进行解码,所以就会出现乱码。
两次encodeURI,第一次编码得到的是UTF-8形式的URL,第二次编码得到的依然是UTF-8形式的URL,但是在效果上相当于首先进行了一 次UTF-8编码(此时已经全部转换为ASCII字符),再进行了一次iso-8859-1编码,因为对英文字符来说UTF-8编码和ISO- 8859-1编码的效果相同。
(2)后台解码处理
在后台接收参数时候,首先通过request.getParameter()自动进行第一次解码(可能是 gb2312,gbk,utf-8,iso-8859-1等字符集,对结果无影响)得到ascii字符,然后再使用UTF-8进行第二次解码,通常使用 java.net.URLDecoder("","UTF-8")方法。
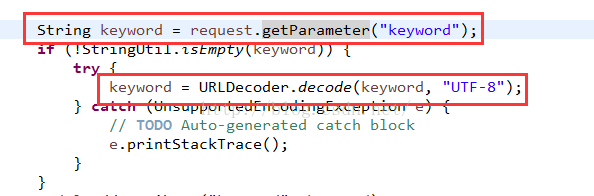
两次编码两次解码的过程为:
UTF-8编码->UTF-8(iso-8859-1)编码->iso-8859-1解码->UTF-8解码,编码和解码的过程是对称的,所以不会出现乱码。
注:
1:这种两次encodeURI方式不用去知道服务器的解码方式,也可以得到正确的数据。
2:get请求建议尽量不带中文参数,如果使用建议使用两次encodeURI进行编码