个人觉得PE结构中RVA–>RAW、IAT、EAT等是较难理解的内容,在此做一个笔记(本文中部分内容来自网络,侵删)
PE
PE(Portable Executable)文件是运行与windows系统下的可执行文件格式,像我们平常所见到的.exe、.dll都是PE文件,除此之外,像.sys(驱动文件)、.obj(对象文件)等都是PE文件。
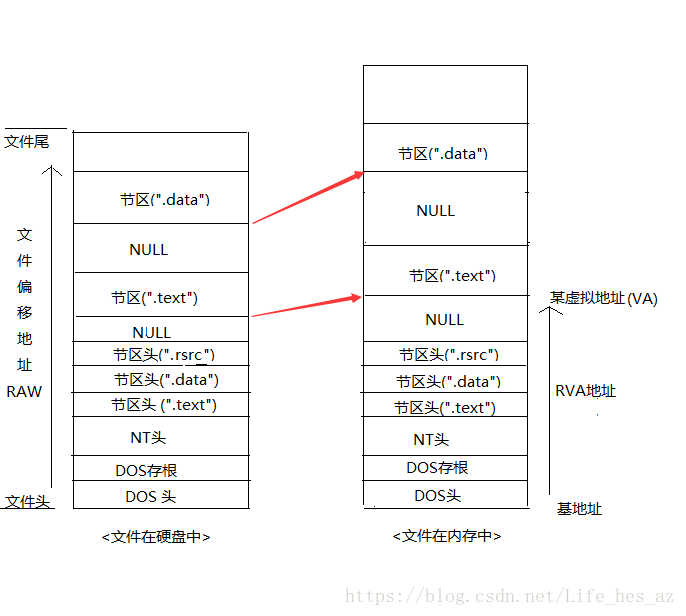
个人觉得,在学习PE结构最难的就是理解硬盘文件–>内存文件,PE结构中定义了许多结构体,这些结构体中定义的一些量,有些是已经确定的,有些是当文件被PE加载器,加载后再确定的(内存中的);
一、RVA、VA
RVA(相对虚拟地址)这是一个概念,代表一类地址,RVA是为了更好的表示(硬盘->内存)地址。每个RVA都有它相对参考的值(不同位置的RVA所参考的值(基准位置)不一定相同)。
VA指的是进程虚拟内存的绝对地址,即为实际的内存地址(VA),RVA(relative virtual address)是指从某个基准位置(ImageBase)开始的相对地址,PE头内部信息大多以RVA形式存在。原因是在一个可执行文件中,有许多在内存中的地址必须被指定的位置。PE文件可以被加载到进程地址空间的任何位置。当PE文件(主要是DLL,因为每个exe文件总是使用独立的虚拟地址空间)加载到进程虚拟内存的特定位置时,该位置可能已经被占用。此时必须重定位(Relocation)到其他空白位置,若PE头信息使用VA,则无法正常访问,而使用RVA来定位信息,即使发生了重定位,只要相对于基准位置的相对地址没有变化,就能正常访问。
VA = 基地址 + RVA
RVA是需要加上基地址(imagebase)才能获得线性地址的数值。基地址就是PE映象文件被装入内存的地址,并且可能会随着一次又一次的调用而变化。
PE文件可以被加载到进程地址空间的任何位置。当PE文件(主要是DLL)加载到进程虚拟内存的特定位置时,该位置可能已经被占用。此时必须重定位(Relocation)到其他空白位置,若PE头信息使用VA,则无法正常访问,而使用RVA来定位信息,即使发生了重定位,只要相对于基准位置的相对地址没有变化,就能正常访问。
文件偏移地址(File Offset Address,FOA)和内存无关,他是指某个位置距离文件头的偏移。
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature; // PE00
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
二、几个结构
2.1、IMAGE_FILE_HEADER
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader; //指出IMAGE_OPRIONAL_HEADER32结构体的长度
WORD Characteristics; //表示文件属性
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
2.2、IMAGE_OPRIONAL_HEADER32
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
typedef struct _IMAGE_OPTIONAL_HEADER {
//
// Standard fields.
//
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint; //EP
DWORD BaseOfCode;
DWORD BaseOfData;
//
// NT additional fields.
//
DWORD ImageBase; //基地址
DWORD SectionAlignment; //内存中节区的对齐值(存在的最小单位)
DWORD FileAlignment; //磁盘文件的对齐值 内存节区/磁盘文件一定是~Alignment的整数倍,不足用0填充
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage; //当PE加载到内存中时,其指定PE image在内存中所占的大小
DWORD SizeOfHeaders; //整个PE头的大小
DWORD CheckSum;
WORD Subsystem; //来区分是驱动文件(.sys)还是普通的可执行文件(.exe,.dll)
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes; //指定DateDirectory数组的个数
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];//是一个由IMAGE_DATA_DIRECTORY结构体组成的数组,其中第一、第二个数组分别指向EAT、IAT的起始地址(相当重要)
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
2.3、IMAGE_SECTION_HEASER(40byte)
#define IMAGE_SIZEOF_SHORT_NAME 8
typedef struct _IMAGE_SECTION_HEADER {
BYTEName[IMAGE_SIZEOF_SHORT_NAME]; //节区名称
union {
DWORD PhysicalAddress;
DWORD VirtualSize; //内存中节区的大小
} Misc;
DWORD VirtualAddress; //(RVA)内存中节区的起始位置
DWORD SizeOfRawData; //硬盘文件中节区的大小
DWORD PointerToRawData; //磁盘文件中节区的起始位置
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics; //节区属性(由or连接)
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
三、几个概念
RVA–> RAW(文件偏移地址)
该部分参考了看雪论坛的一篇文章,帮助理解
只有以节的起始地址为参考的相对偏移才是固定的
通常我们使用工具对PE文件进行分析,得到一个字符串的地址(内存中的mRVA),要想在文件中找到它,需要找到这个mRVA所在的节区,用mRVA减去这节区的起始位置(即VirtualAddress),得到的这个值再加上,文件中此节区的起始地址,就得到了文件偏移
iRVA:该RVA是以ImageBase为参考的,iRVA = VA - ImageBase (我们常说为RVA)
mRVA:该RVA是以VOffset(如.text节的起始地址)为参考的;
真正的文件偏移为fRVA;
虚拟地址转文件偏地址fRVA fRVA = mRVA + ROffset
由于mRVA(内存节偏移)= iRVA - VOffset,再由于iRVA = 虚拟地址-ImageBase,
所以,mRVA = (虚拟地址 - ImageBase) - VOffset;
所以,fRVA = (虚拟地址 - ImageBase) - VOffset + ROffset;
最终得到:
fRVA = (虚拟地址 - ImageBase) - VOffset + ROffset
内存偏移 - 该段起始的RVA(VirtualAddress) = 文件偏移 - 该段的PointerToRawData
四、IAT和EAT
4.1、IAT(Import_Address_Table)导出地址表
每一个结构体就代表存在一个库函数(xxx.dll),这些库函数组成了IID(IMAGE_IMPORT_DESCRIPTOR的简称) 数组结构。在这个IID 数组中,并没有指出有多少个项(就是没有明确指明有多少个链接文件),但它最后是以一个全为NULL的IID 作为结束的标志。
typedef struct _IMAGE_IMPORT_DESCRIPTOR { //20Byte
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // (RVA)INT address (import name table)
};
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain;
DWORD Name; //库(dll)名称的地址(RVA)
DWORD FirstThunk; // (RVA) IAT address (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
//INT
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint; //Ordinal序号
BYTE Name[1]; //函数的名称
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
OriginalFirstThunk –> INT–>IMAGE_IMPORT_BY_NAME
- INT是一个包含导入函数信息(Ordinal,Name)的结构体指针数组,只有获得了这些信息,才能在加载到进程内存的库中准确求出相应函数的起始地址.INT由地址数组组成(数组以NULL结尾)
FirstThunk(IAT的地址) –> IAT(在内存和硬盘中值不同)
当IAT地址值的最高位为1时,表示函数以序号方式输入,这时候低31位被看作一个函数序号.当IMAGE_THUNK_DATA值的最高位为0时,表示函数以字符串类型的函数名方式输入,这时双字的值是一个RVA,指向一个IMAGE_IMPORT_BY_NAME 结构
PE装载器把导入函数输入到IAT(真正IAT)的顺序
1.先从IID的Name中读取需要的dll 的名称
2.装载到相应库,用LoadLibrary("xxxx.dll")
3.在从OriginalFirstThunk中得到INT的地址
4.逐一读取INT数组中的值,获取IMAGE_IMPORT_BY_NAME的地址
5.获取函数的起始位置(通过Hint或Name项)
6.读取IID中FirstThunk,得到IAT地址
7.将上面获得的函数地址赋给相应的IAT数组值
8.重复4-7,直到INT结束(遇到NULL)(去查函数)
通俗一点说,先找到需要的dll 文件,在通过OriginalFirstThunk找到INT(此值不能被改写),获得函数的起始地址,再从FirstThunk获得IAT的地址,最后将5中获取的函数地址赋给IAT数组。开始的时候地址未知,当Windows加载器加载到内存中才会填充。先找dll,再找到具体函数,再填充IAT
4.2、EAT 导出表
主要存在于dll文件中,为不同的应用程序提供库文件(dll)中的函数
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name; //库名称的地址(RVA)
DWORD Base; //Ordial base 基数
DWORD NumberOfFunctions; //Export函数的实际个数(RVA)
DWORD NumberOfNames; //Export函数中具有函数名的函数个数(RVA)
DWORD AddressOfFunctions; //Export函数地址数组(RVA)
DWORD AddressOfNames; //函数名称地址数组(RVA)
DWORD AddressOfNameOrdinals; //Ordinal地址数组(可以理解为导出函数名称的编号,可用于查找没有函数名称的导出函数)(RVA)
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
EAT的转载过程
1.获取EAT的RVA
2.从EAT中获取base(起始序号)
3.将需要查找的导出序号减去起始序号,得到函数在入口地址表中的索引
4.与NumberOfFunctions数比较(不能超过它)
(5.用这个索引值在AddressOfFunctions 字段指向的导出函数入口地址表中取出相应的项目,这就是函数入口地址的RVA 值,当函数被装入内存的时候,这个RVA 值加上模块实际装入的基地址,就得到了函数真正的入口地址)此为无名函数的查找方式
5.找到AddressOfNames --> 函数名称数组
6.通过比较string,查找到函数名,并记下这个函数名在字符串地址表中的索引值
7.在利用AddressOfNameOrdinals --> ordinal数组, 指向的数组中以同样的索引值取出数组项的值(该数+base与函数名一一对应)
8.利用该到AddressOfFunctions(此中函数顺序未知,要依靠索引)索引相应函数
未完待续