通常来讲,训练更大规模的网络模型可以在多种任务上取得更好的效果,如提升图像分类任务的准确率。然而,随着参数规模的扩大,AI 加速卡存储(如 GPU 显存)容量问题和卡的协同计算问题成为了训练超大模型的瓶颈。流水线并行从模型切分和调度执行两个角度解决了这些问题,下面将以飞桨流水线并行为例,介绍下基本原理和使用方法。
一、原理介绍¶
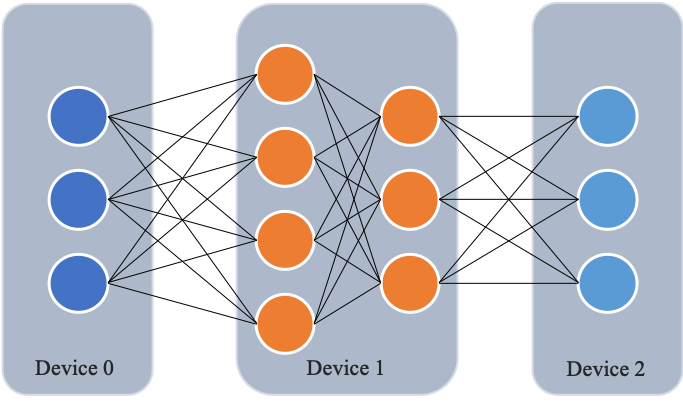
与数据并行不同,流水线并行将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。以上图为例,示例模型包含四个模型层。该模型被切分为三个部分,并分别放置到三个不同的计算设备。即,第 1 层放置到设备 0,第 2 层和第三 3 层放置到设备 1,第 4 层放置到设备 2。相邻设备间通过通信链路传输数据。具体地讲,前向计算过程中,输入数据首先在设备 0 上通过第 1 层的计算得到中间结果,