文章目录
Redis底层数据结构
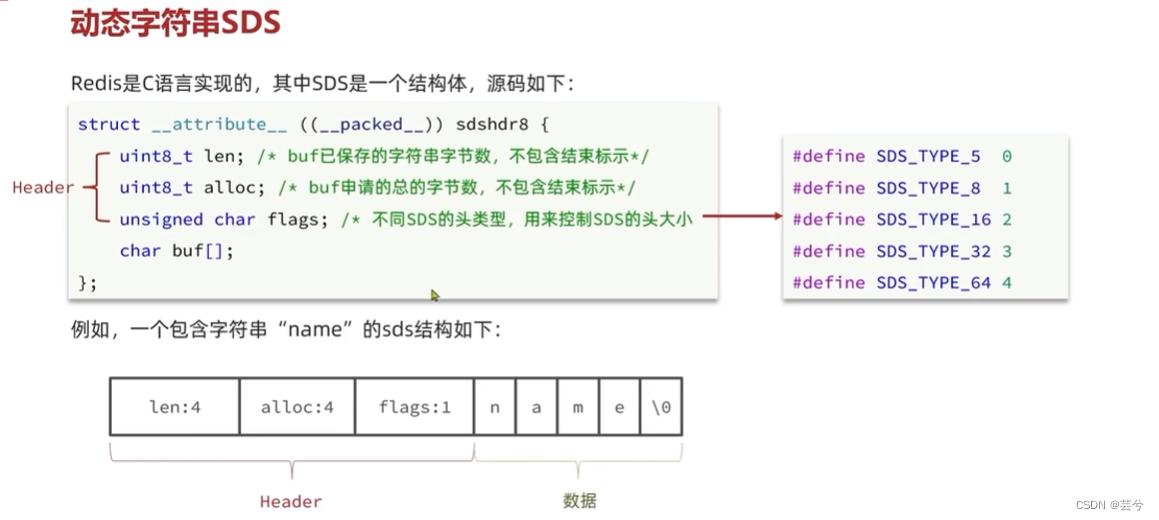
SDS 动态字符串
Redis自身构建了一种新的字符串结构,称为简单动态字符串,简称SDS。


IntSet 整数集合




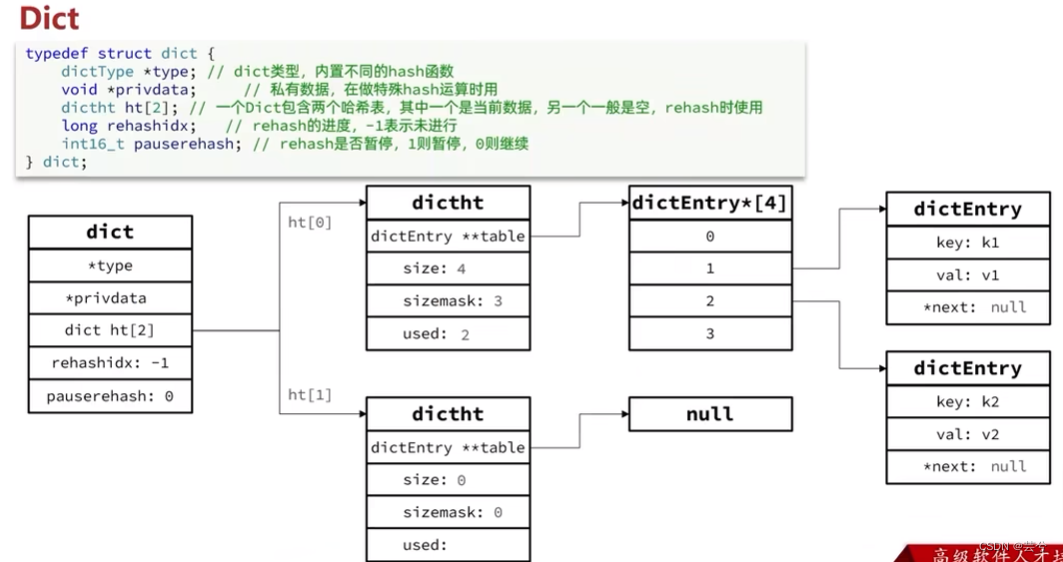
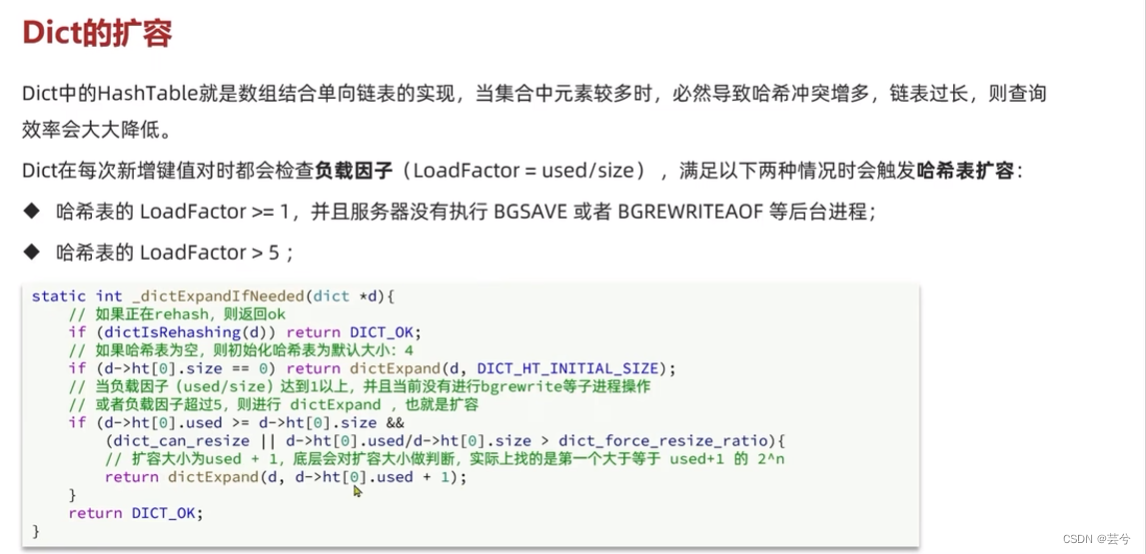
Dict 字典
-
Dict由三部分组成,分别是:哈希表、哈希节点、字典。
-
字典Dict包含两个哈希表,其中一个是当前数据,另一个一般为空,rehash时使用。
-
哈希表中的每个节点是哈希节点,哈希节点类似于链表的节点。

Dict伸缩中的渐进式再哈希



ZipList 压缩列表



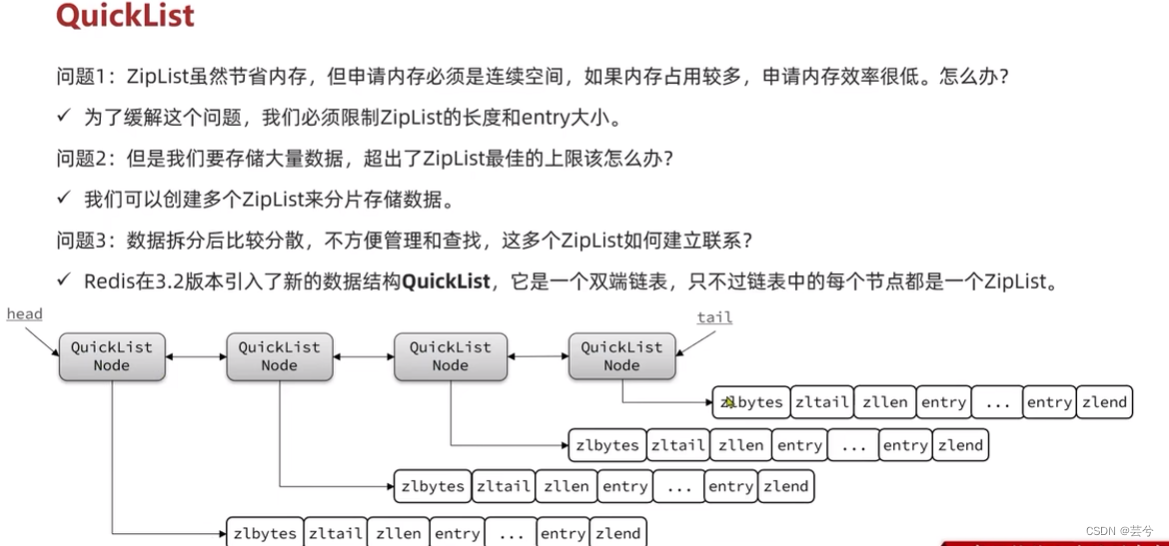
QuickLisk 快速列表
ZipList虽然节省内存,但是申请内存必须是连续空间,如果内存占用较多,申请内存效率较低。
QuickList特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题。
- 中间节点可以压缩,进一步节省了内存。
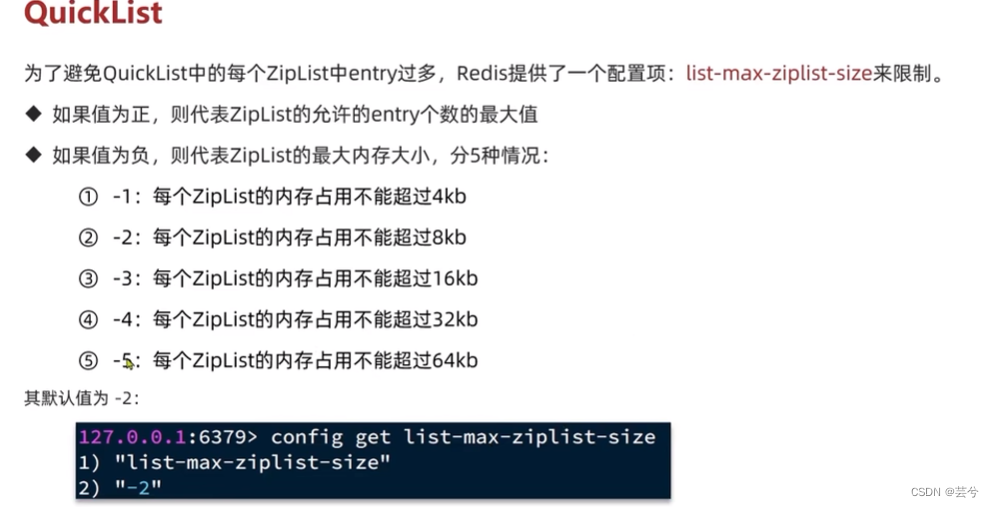


SkipList 跳表
跳表是对原始链表的改进,原始链表查询每个节点都要进行O ( n ) O(n)O(n)的遍历,而跳表借鉴了二分查找的思路对链表的索引进行了分级处理,跳表本质是可以实现二分查找的有序链表。
SkipList的特点:
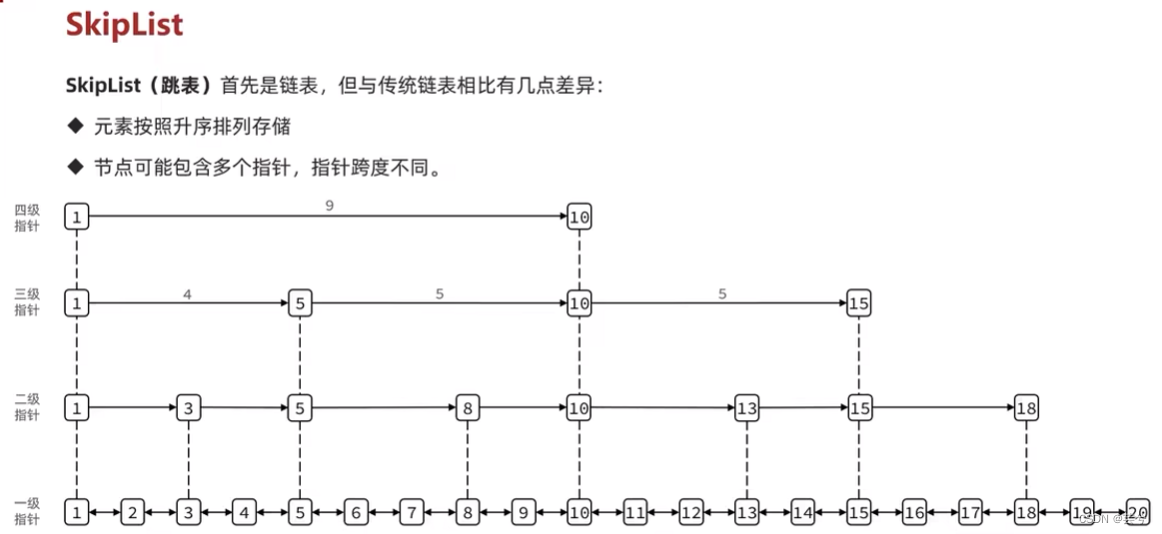
- 跳表是一个双向链表,每个节点都包含score和ele,score类似index,而ele是实际存储的字符串内容,节点按照score值排序,score值一样则按照ele字典序排序。
- 每个节点都可以包含多层指针,层数是1-32之间的随机数。
- 不同指针到下一个节点的跨度不同,层级越高,跨度越大。
- 增删改查效率与红黑树基本一致,实现却更简单。
动态索引建立
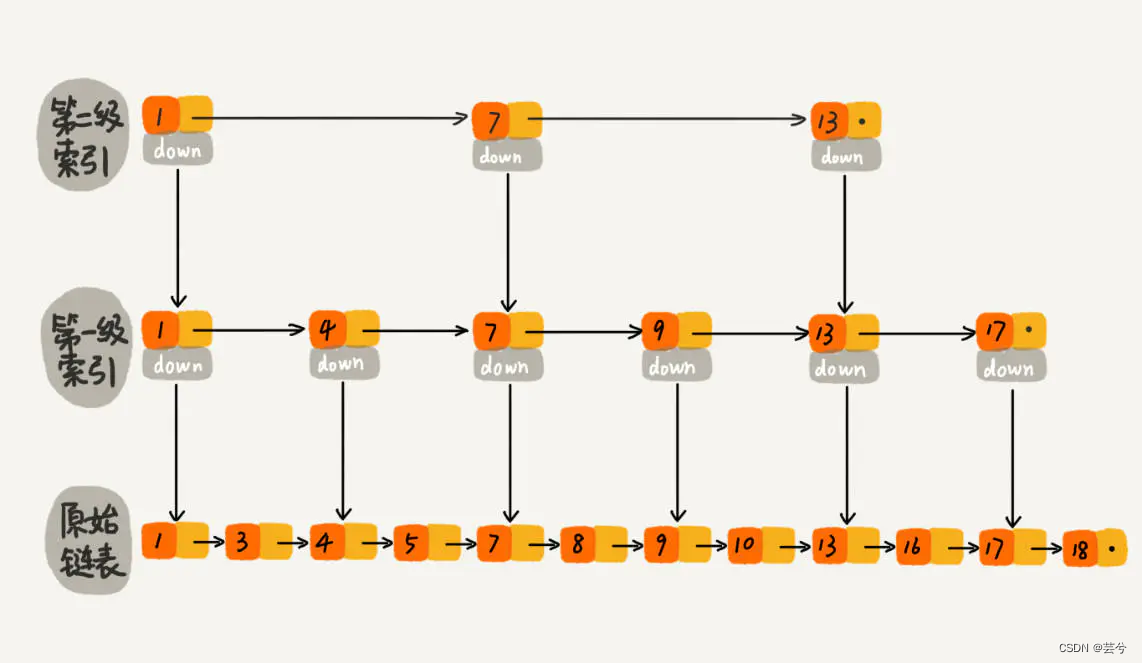
在已知数据分布的情况下,不断选择数据中点作为索引建立的位置是最理想的:
而实际中我们建立跳表的过程是一个个动态添加或者删除的。如一直往原始列表中添加数据,但是不更新索引,就可能出现两个索引节点之间数据非常多的情况,极端情况,跳表退化为单链表:

最理想的索引就是二分查找的情形,在原始链表(假设长度为n),随机选 n/2 个元素做为一级索引、随机选 n/4 个元素做为二级索引、随机选 n/8 个元素做为三级索引,依次类推,一直到最顶层索引。
跳表中采用randomLevel() 方法来实现上述索引建立过程,该方法会随机生成 1~MAX_LEVEL 之间的数(MAX_LEVEL表示索引的最高层数),且该方法有 1/2 的概率返回 1、1/4 的概率返回 2、1/8的概率返回 3,以此类推。(randomLevel()的实现可以是循环调用一个有0.5概率返回1的函数,如果是1,则继续调用该函数 ,直至为0。)
跳表实际上是使用了这种随机产生元素的索引高度的方式,来打乱了输入的规律性,使得整体上按索引查询某个元素的时间复杂度为O ( l o g N ) O(logN)O(logN)
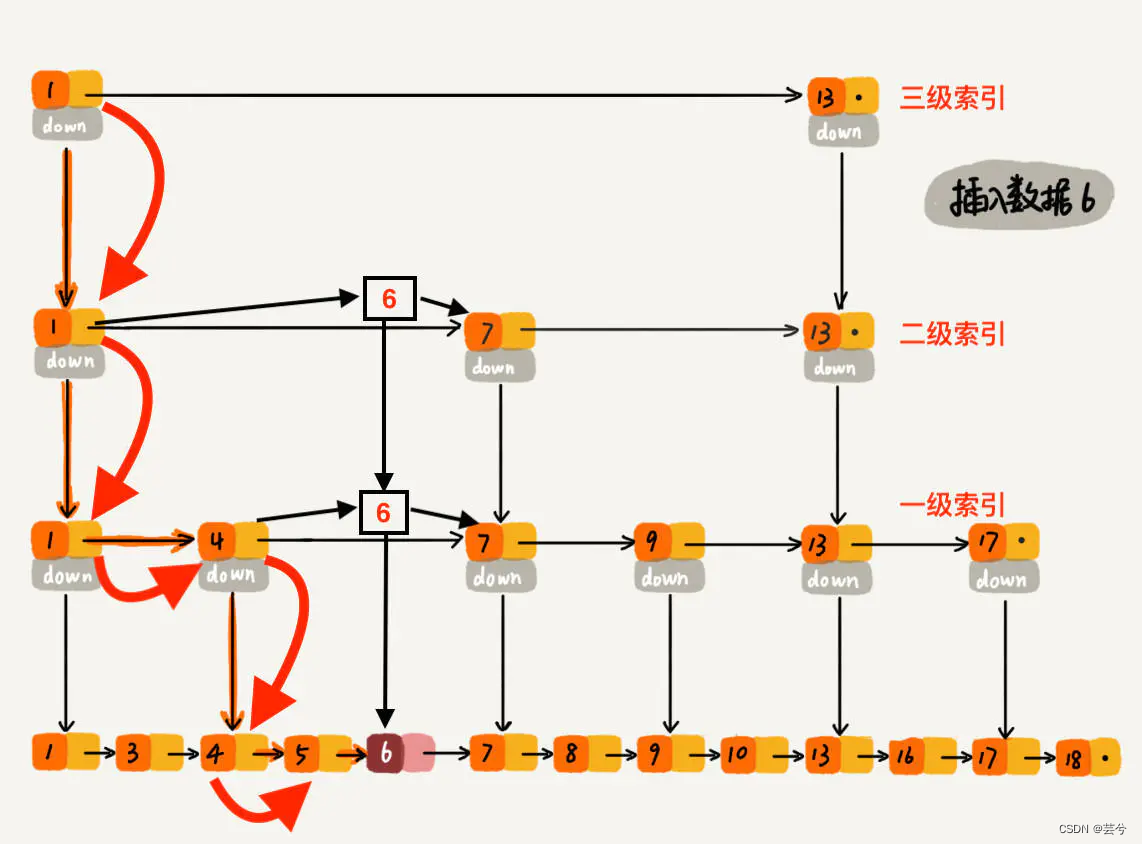
假设新加入一个元素6,通过randomLevel()函数返回了1,即建立一层索引(一层索引只能建立在最下边的层),它的建立方式如下:
从表头节点的最高层索引出发,如果某个节点的下一个元素大于该插入元素(6),则停止,进入下一层索引,依次类推,直至当前层与元素(6)的索引层相同,将节点插入。
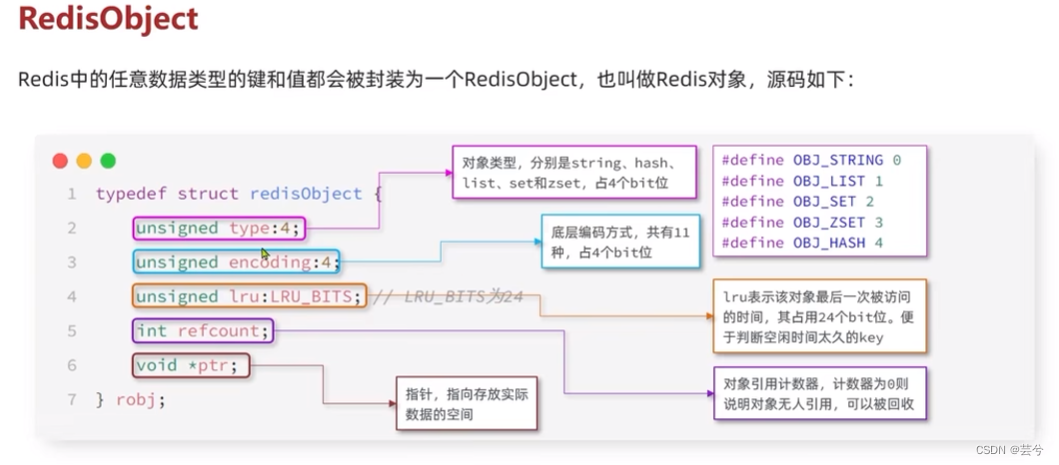
RedisObject
RedisObject是Redis中存放数据对象的实际类型。

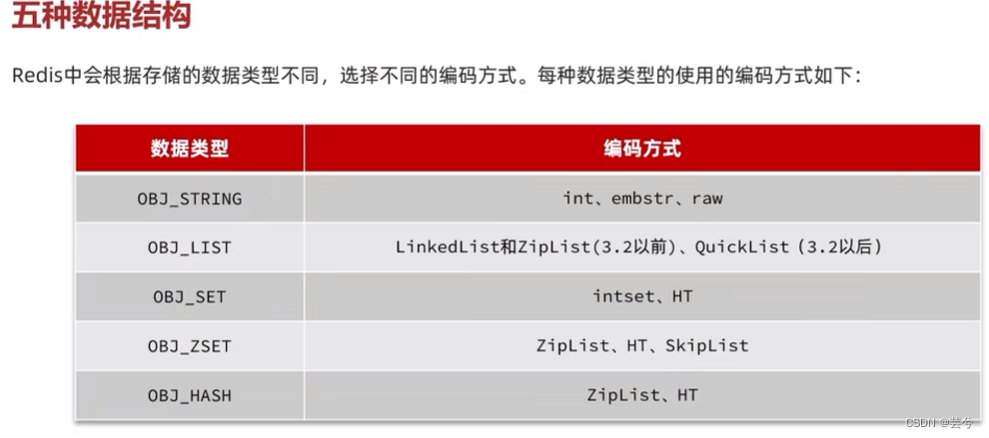
变量类型与数据结构实现
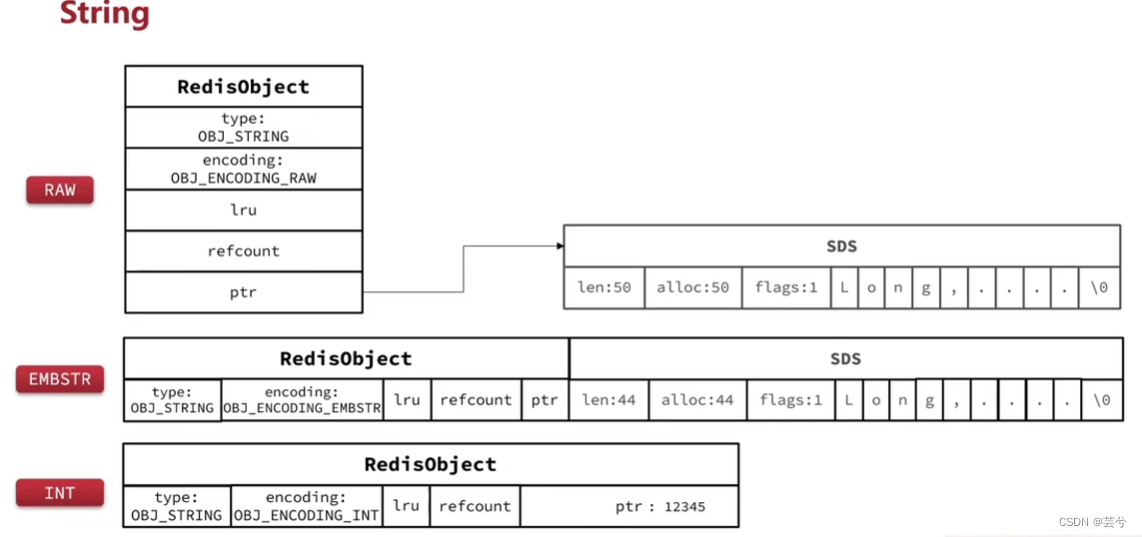
String
String类型的RedisObject中包含有很多头部信息,因此如果能够使用数值类型,尽量使用集合来保存,这样一个RedisObject中就能存放更多的元素。
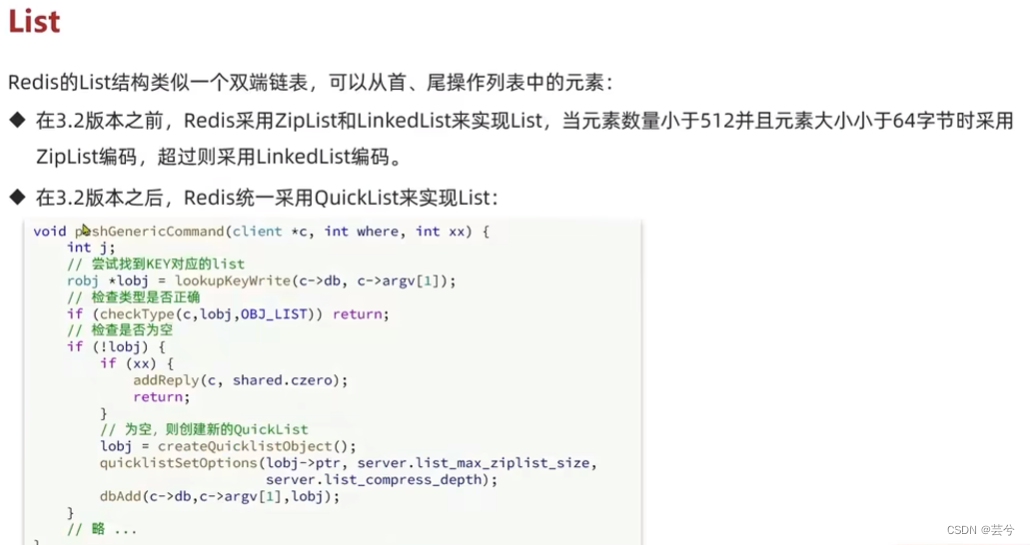
List
3.2版本之前采用ZipList和LinkedList实现,3.2版本之后,统一采用QuickList实现。
Set
- 为了查询效率和唯一性,Set使用Dict实现。
- 当存储所有数据都是整数,可以采用IntSet编码实现。

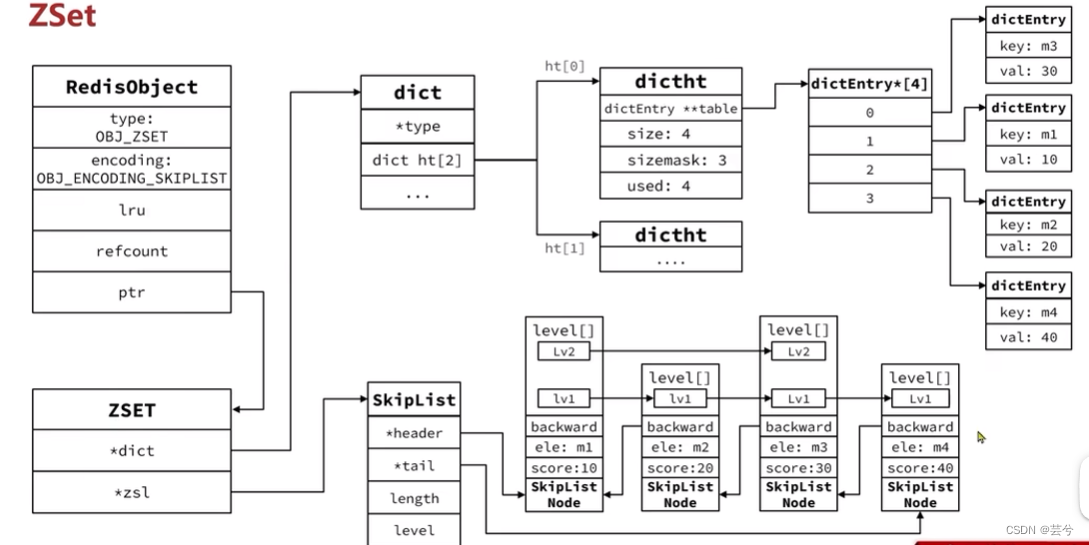
ZSet
ZSet(有序集合)是通过跳表(保证有序)和字典(保证查询是否存在的效率)这两种数据结构实现的:
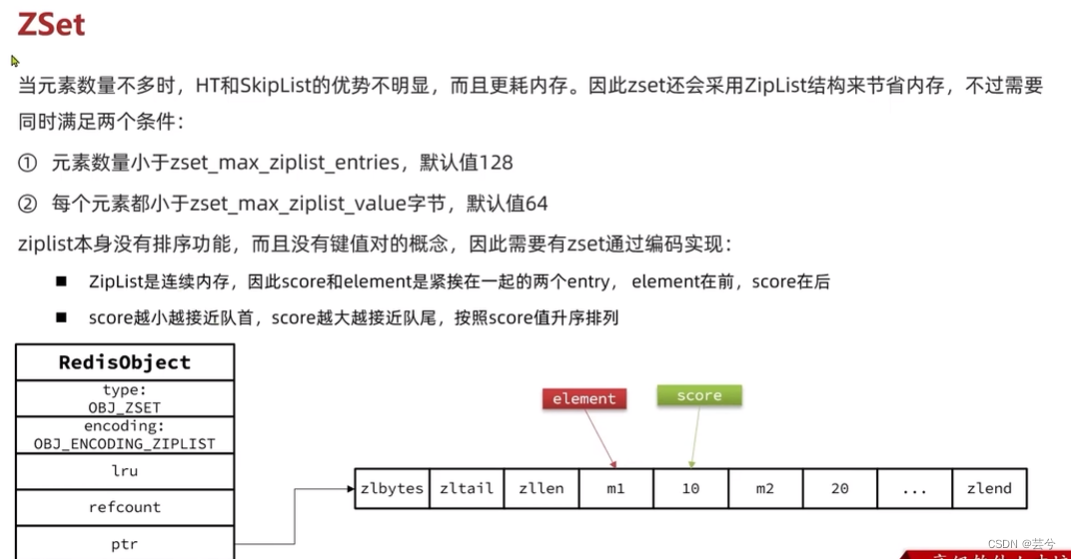
但是当元素数量不多时,HT和SkipList优势不明显,ZSet会采用ZipList结构来节省内存:
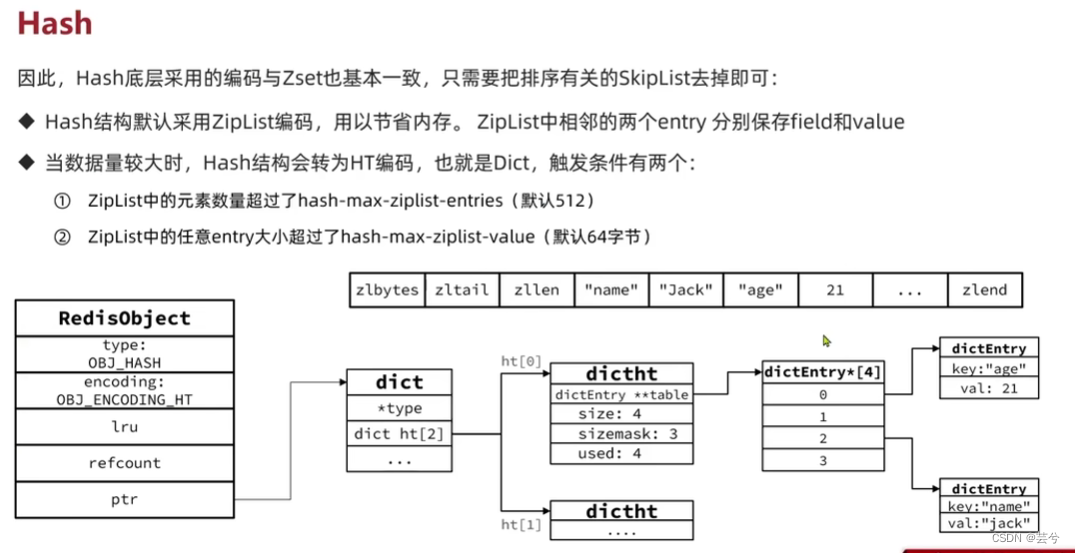
Hash
Redis网络模型
Redis是单线程还是多线程?
- 如果仅仅聊Redis的核心业务部分(命令处理),都是单线程的。
- 如果聊整个Redis,就是多线程。
为什么Redis要选择单线程?
- 抛开持久化不谈,Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的线程上下文切换,带来不必要的开销。
- 引入多线程会面临线程安全问题,必然要引入锁等保证线程安全的手段,实现复杂度高,且性能也会大打折扣。
epoll事件通知模式

内存回收策略
过期策略
Redis是如果知道一个key是否过期?

利用两个Dict分别记录key-value和key-TTL对,通知TTL,检测是否过期
是不是TTL到期就立即删除了呢?
不是,Redis采用了下面两种过期策略:
- 惰性删除
- 周期删除
惰性删除是在后期再次访问同一个key时,会检查key是否过期,如过期则删除。

惰性删除的方式下,对于已经过期但是后续没有访问的数据,会一直存活占用内存。这时候Redis又引入了周期删除策略:
通过设置定时任务,周期性的抽样key,判断是否过期,如果过期则删除。
周期删除有两种工作模式:
- 在Redis的initServer()函数中,会按照server.hz的频率来执行过期key的清理,模式为SLOW,默认每秒10次。
- Redis的每个事件循环前回调用beforeSleep()函数,执行过期key的清理,模式为FAST。
- SLOW执行低频但清理更加彻底。FAST模型执行高频,但执行时机较短。


淘汰策略
内存淘汰策略执行的时机:
Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰。
Redis支持8种不同的策略进行key的淘汰,默认的淘汰策略是noeviction,不淘汰任何key,但是内存满的时候不允许写入新数据。
其他常见内存淘汰策略,通常分为对全体key处理和对设置了TTL的key处理。
包括按照TTL优先淘汰将要过期key。
对全体key,随机淘汰,对设置了TTL的key随机淘汰。
基于LRU算法对全体key或者设置了TTL的key进行淘汰。
基于LFU算法对全体key或者设置了TTL的key进行淘汰。

LRU与LFU
- LRU(least recently used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大,淘汰的优先级越高。
- LRU是基于时间的,时间敏感,最近的,新出现的热点key,更有可能被常驻到内存中,而那些长时间没有使用的key则更有可能被淘汰掉。
- LFU(least frequently used),最少频率使用。会统一每个key的访问频率,值越小,淘汰优先级越高。
- LFU是频率敏感的,更适合保存包含有多个热点key,某个key上一次访问已经是昨天中午12:00,并且在昨天12:00的5分钟内,高频访问了200次,如果今天中午还有这样的需求,按照LFU的策略,昨天的热key会常驻在内存中。