简单介绍
抓取数据 简单来说就是从web页面提取所需要的数据。
抓取数据原理 从web源码解析 HTML 标签的过程,比如提取 HTML 标签的属性或文本内容。因此,了解 web 页面结构对于爬数据是必要的。
selenium 高级爬虫、交互式爬虫(比如点击,打开链接,翻页等)必不可少的。有兴趣的同鞋可以了解一下。
Beautiful Soup
Beautiful Soup【 文档 】 是一个可以从HTML或XML文件中提取数据的 Python 库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
在 Python 中还有其他库可以解析 HTML, 有兴趣的童鞋可以百度一下,本文用的是
Beautiful Soup
教你抓取CSDN首页博客数据
CSDN首页 https://www.csdn.net
我们需要的数据
- 博客标题
- 博客地址(url)
- 博客简单描述(摘要)
了解页面结构
Google Chrome 开发者工具查看,对于 web 开发的同鞋应该不陌生。
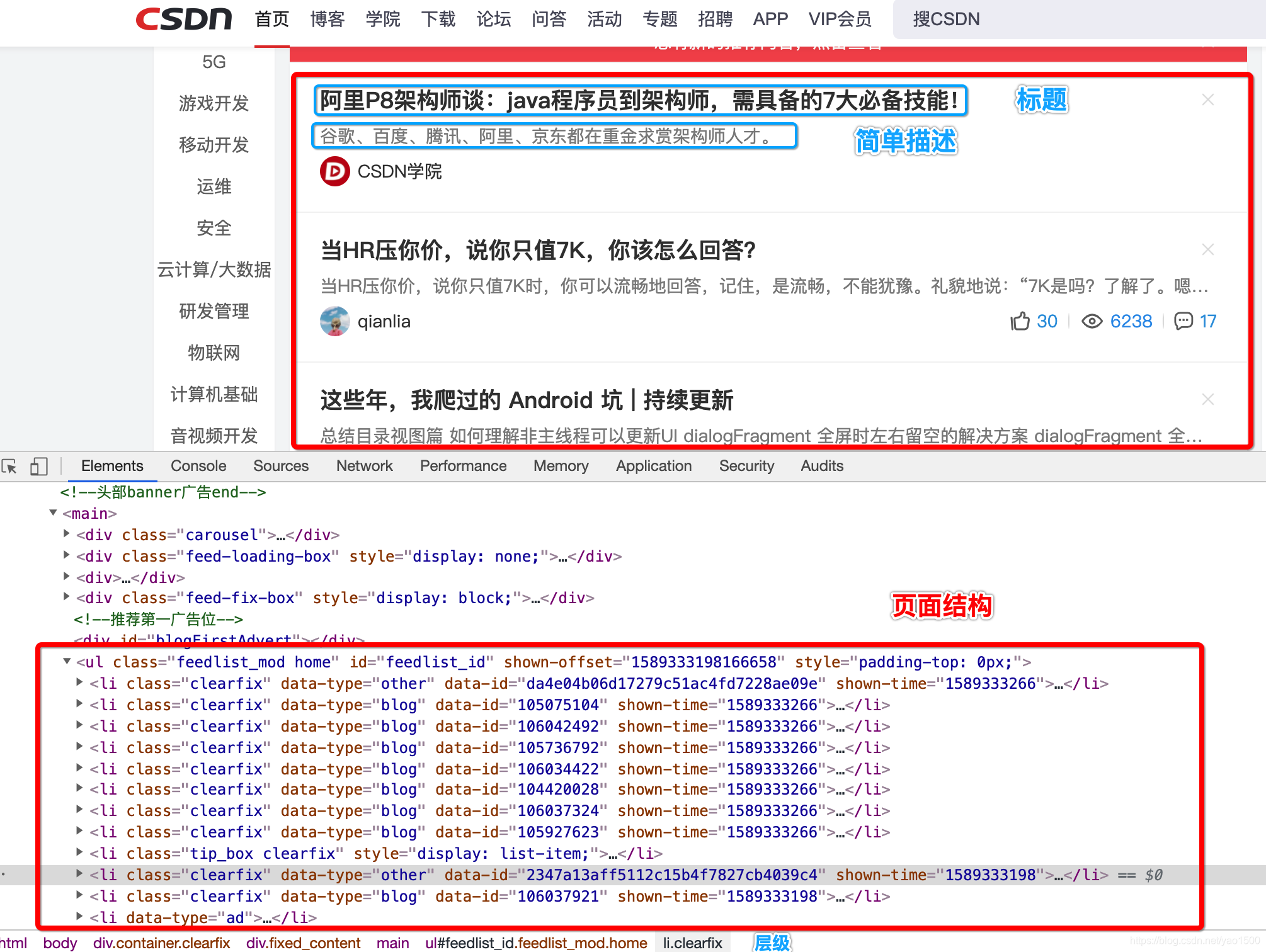
从截图我们看到,我们需要的数据都放在
li标签中,因此我们提取li标签是第一步。li的父容器ul的id选择器为feedlist_id,要记住这个,对后面的编码理解有帮助。
看看 li 标签内部结构
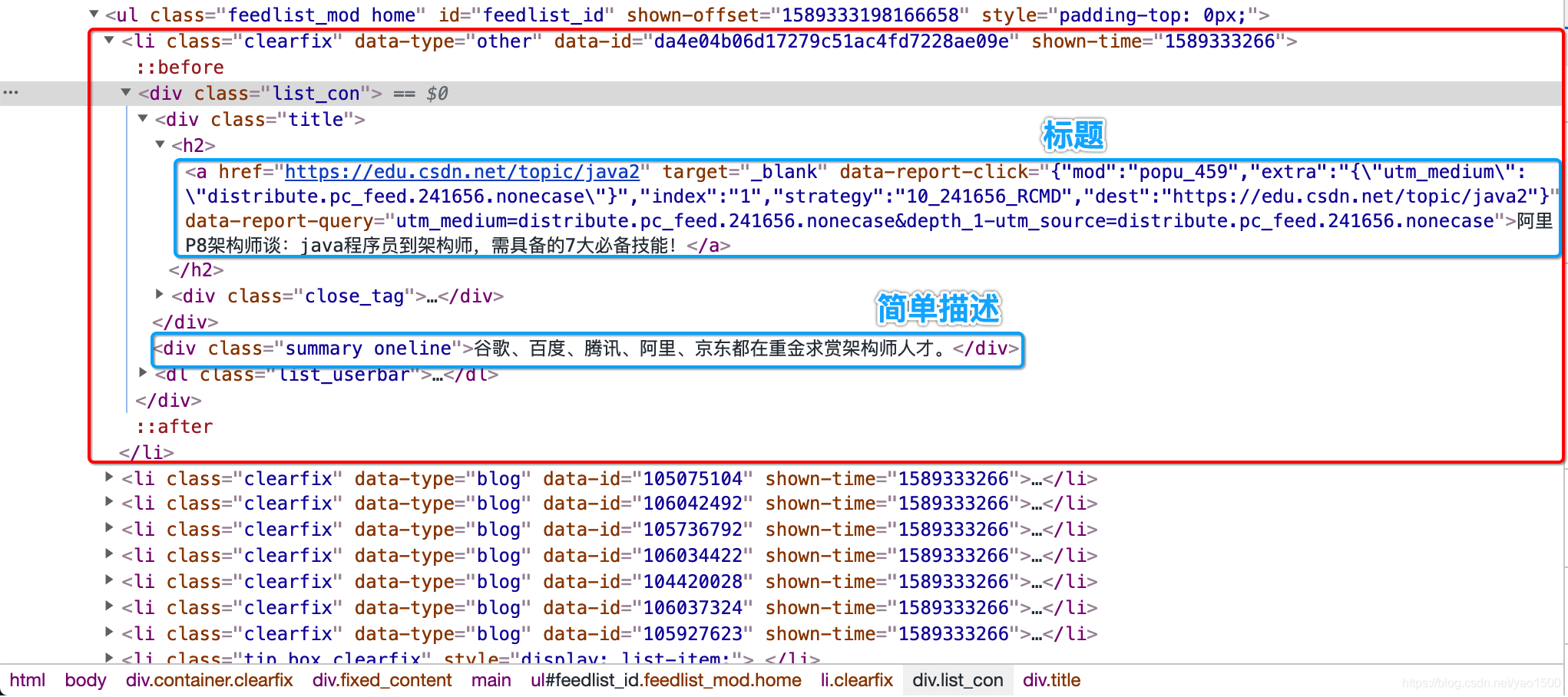
从截图看到,标题是放到
a标签中,简单描述是放到div中,所以我们第二步所这两个标签解析出来就算完事了
开始编码
- 获取页面源码
import lxml
import requests
from bs4 import BeautifulSoup
# 获取源码
url = 'https://www.csdn.net'
html_source = requests.get(url)
- 提取
li标签
import lxml
import requests
from bs4 import BeautifulSoup
# 获取源码
url = 'https://www.csdn.net'
html_source = requests.get(url)
# 提取 `li` 标签
html_parser = BeautifulSoup(html_source.text,'lxml') # 创建页面解析器
results = html_parser.select('ul#feedlist_id > li') # 返回的是一个列表,符合条件的 `li` 标签集合
html_parser.select是通过 CSS 选择器去解析标签。
类别选择器是通过.连接,比如:ul.class > li。
ID 选择器是通过#连接,比如:ul#id > li。
不使用 CSS 选择器也可以的,可以通过增加多层结点来确保正确性,比如:把'ul#feedlist_id > li'换成div > div > main > ul > li。
- 解析
li标签内部标签
import lxml
import requests
from bs4 import BeautifulSoup
# 获取源码
url = 'https://www.csdn.net'
html_source = requests.get(url)
# 提取 `li` 标签
html_parser = BeautifulSoup(html_source.text,'lxml') # 创建页面解析器
results = html_parser.select('ul#feedlist_id > li') # 返回的是一个列表,符合条件的 `li` 标签集合
# 解析 `li` 标签内部标签,提取我们所需要的数据
for item in results:
a_tag = item.select('div > div > h2 > a')[0] # 提取 a 标签
title = a_tag.get_text('|', strip=True) # 获取 a 标签的文本,即标题,strip=True 去掉空白字符,如果有多行,用 `|` 拼接
href = a_tag['href'] # 获取 a 标签的属性 href,即博客 url
desc = item.select('div > div.summary')[0].get_text(strip=True) # 提取摘要
print('title: ' + title)
print('url: ' + href)
print('desc: ' + desc, end='\n\n')
到此,抓取数据的目标已完成,但是实际开发中仍然对数据进行过滤,比如
li标签有可能是广告,这不是我们需要的,我们只要博客数据,这时我们需要对数据进行过滤,以确保脚本的正常运行。
- 过滤数据
import lxml
import requests
from bs4 import BeautifulSoup
# 获取源码
url = 'https://www.csdn.net'
html_source = requests.get(url)
# 提取 `li` 标签
html_parser = BeautifulSoup(html_source.text,'lxml') # 创建页面解析器
results = html_parser.select('ul#feedlist_id > li') # 返回的是一个列表,符合条件的 `li` 标签集合
# 解析 `li` 标签内部标签,提取我们所需要的数据
for item in results:
if 'data-type' not in item.attrs: # item.attrs 是 li 标签属性集合,类型为 dict
continue
if item.attrs['data-type'] != 'blog': # 过滤数据,只要 博客数据
continue
a_tag = item.select('div > div > h2 > a')[0] # 提取 a 标签
title = a_tag.get_text('|', strip=True) # 获取 a 标签的文本,即标题,strip=True 去掉空白字符,如果有多行,用 `|` 拼接
href = a_tag['href'] # 获取 a 标签的属性 href,即博客 url
desc = item.select('div > div.summary')[0].get_text(strip=True) # 提取摘要
print('title: ' + title)
print('url: ' + href)
print('desc: ' + desc, end='\n\n')
脚本运行结果展示
title: 荐|终于有人把域名和DNS服务器给写明白了
url: https://blog.csdn.net/qq_17623363/article/details/106037921
desc: 终于有人把域名和DNS服务器给写明白了
title: 荐|母亲节不能陪在妈妈身边,我用css和js给妈妈做了一个爱心飘落
url: https://blog.csdn.net/weixin_43570367/article/details/106018731
desc: 这篇博客做了一个爱心飘落的动图,给妈妈送去节日的祝福!
title: 程序猿版:溢出吧,后浪
url: https://blog.csdn.net/loongggdroid/article/details/106030143
desc: 【回复“1024”,送你一个特别推送】那些口口声声一届不如一届的程序猿,应该看着你们像我一样我看着你们满怀羡慕计算机发展积攒了几十年的财富层出不穷的不断迭代的技术,框架,算法和遗留的祖传...
title: Intellij IDEA 美化指南
url: https://blog.csdn.net/qq_35067322/article/details/105852521
desc: 经常有人问我,你的 IDEA 配色哪里搞的,我会告诉他我自己改的。作为生产力工具,不但要顺手而且更要顺眼。这样才能快乐编码,甚至降低 BUG 率。上次分享了一些 IDEA 有用的插件,反...
......