一、canal概念
canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)
二、canal使用场景
(1)中间件的使用——用于监听获取变更数据
阿里otter(阿里用于进行异地数据库之间的同步框架)中间件的一部分,这是原始场景
图片来源对线JAVA面试
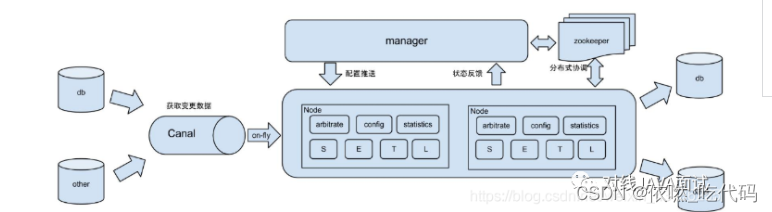
(2)更新缓存
如果有大量的请求发送到mysql的话,mysql查询速度慢,QPS上不去,光查mysql可能会瘫痪,那就可以在前面加个缓存,这个缓存有2个主要的问题。一是缓存没有怎么办,二是数据不一致怎么办。对于第一个问题查缓存没有就差mysql,mysql再往缓存中写一份。对于第二个问题,如果数据库修改了,那就采用异步的方式进行修改,启动一个canal服务,监控mysql,只要一有变化就同步缓存,这样mysql和缓存就能达到最终的一致性。
(3)抓取业务数据新增变化表,用于制作拉链表:做拉链表是需要有增加时间和修改时间的,需要数据今天新增和变化的数据,如果时间不全就没办法知道哪些是修改的。可以通过canal把变化的抽到自己的表里,以后数据就从这个表出。
(4)取业务表的新增变化数据,用于制作实时统计
四、Canal工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议。
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )。
- canal 解析 binary log 对象(原始为 byte 流)。
Mysql主从复制原理
MySQL 的主从复制依赖于 binlog ,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上。复制的过程就是将 binlog 中的数据从主库传输到从库上。
这个过程一般是异步的,也就是主库上执行事务操作的线程不会等待复制 binlog 的线程同步完成。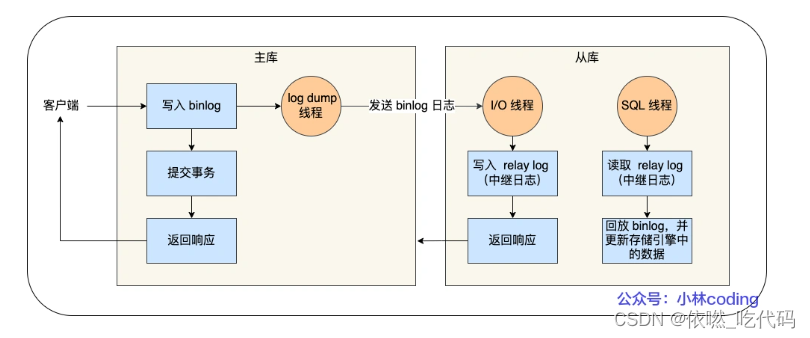
MySQL 集群的主从复制过程梳理成 3 个阶段:
- 写入 Binlog:主库写 binlog 日志,提交事务,并更新本地存储数据。
- 同步 Binlog:把 binlog 复制到所有从库上,每个从库把 binlog 写到暂存日志中。
- 回放 Binlog:回放 binlog,并更新存储引擎中的数据。
具体详细过程如下:
- MySQL 主库在收到客户端提交事务的请求之后,会先写入 binlog,再提交事务,更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
- 从库会创建一个专门的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog 日志,再把 binlog 信息写入 relay log 的中继日志里,再返回给主库“复制成功”的响应。
- 从库会创建一个用于回放 binlog 的线程,去读 relay log 中继日志,然后回放 binlog 更新存储引擎中的数据,最终实现主从的数据一致性。
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行。
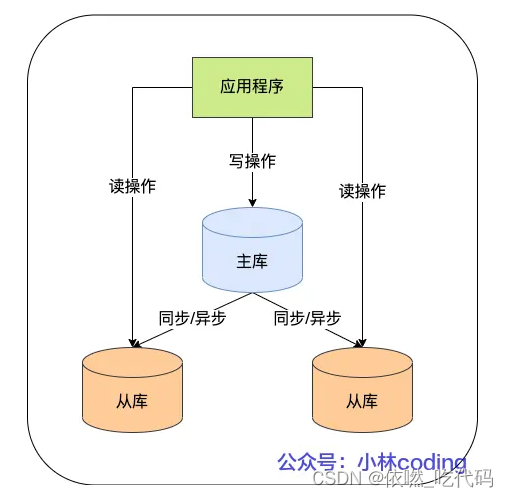
binlog中的二进制日志
mysql的二进制日志记录了所有的DDL和DML(除了数据查询语句),以事件的形式进行记录,包含语句执行消耗的时间,mysql的二进制日志是事务安全型的。
开启二进制日志大概会有1%的性能损坏。二进制日志有2个主要的使用场景:①mysql的主备复制②数据恢复,通过使用mysqlbinlog工具来恢复数据(用这个做恢复是备选方案,主方案还是定期快照,定期执行脚本导数据,其实就是把当前所有数据导成insert,这个量少)
二进制日志包括2类文件:①二进制日志索引文件(后缀为.index)用于记录所有的二进制文件②二进制日志文件(后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)
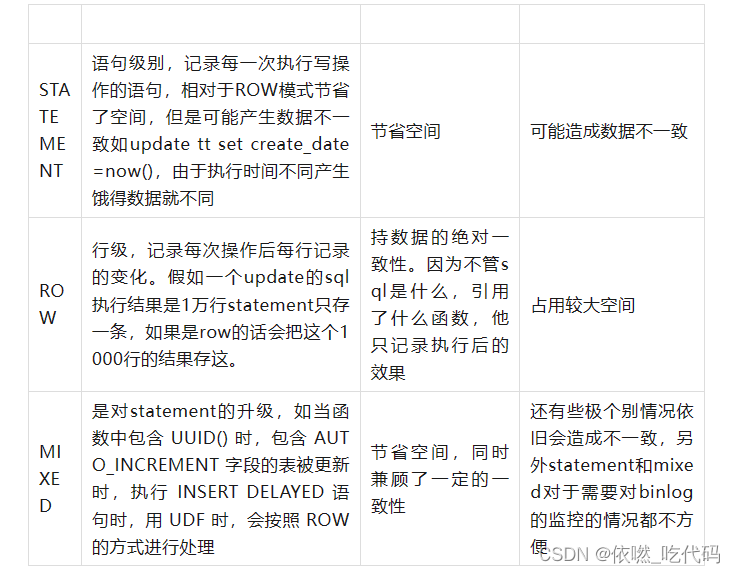
binlog格式选择
如果只考虑主从复制的话可以用mixed,一般情况下使用statement,遇到几种特殊情况使用row,同步的话有SQL就行,因为手里有数据,前提是有数据才能执行这个SQL。在大数据场景下我们抽取数据是用于统计分析,分析的数据,如果用statement抽了SQL手里也没数据,不知道执行修改哪些,因为没有数据,所以没办法分析,所以适合用row,清清楚楚的表明了每一行是什么样。
Canal消费方式
Canal在伪装成为目标MySQL的一个Slave节点后,获取到来自主节点的BinaryLog日志内容。那么作为BinaryLog消费者该如何使用canal监听得到的内容呢。Canal为我们提供了两种类型的方式,直接消费和投递。直接消费即使用Canal配套提供的客户端程序,即时消费Canal的监听内容。投递是指配置指定的MQ类型以及对应信息,Canal将会按照BinaryLog的条目投递到指定的MQ下,再交由MQ为各种消费形式提供数据消费。
应用实践
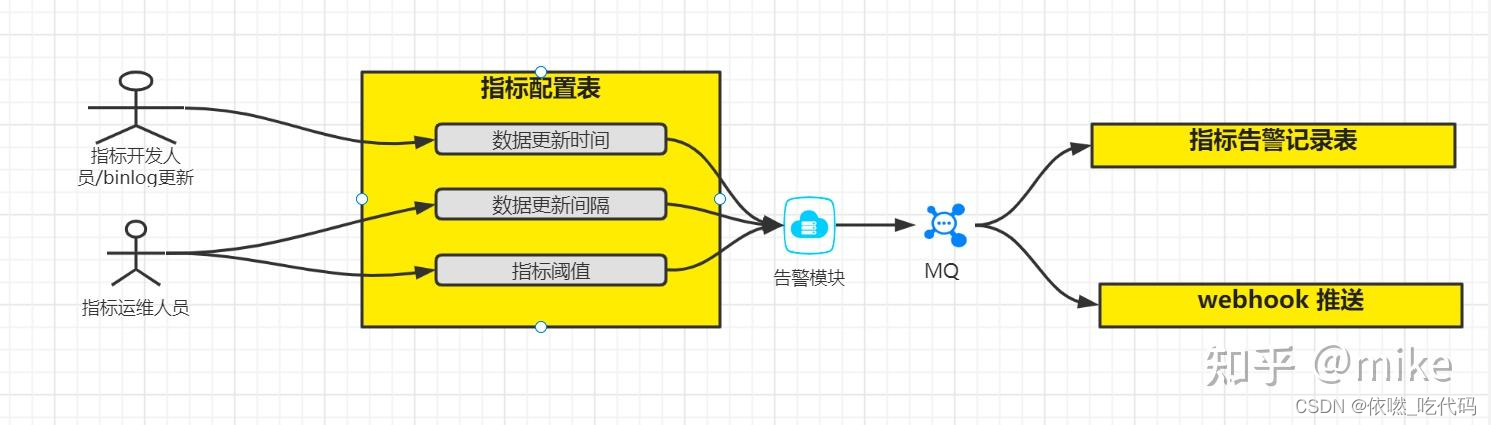
- 监听字段更新
使用Canal对指定的指标表进行监听,对指标表的更新数据Binlog进行解析,然后以日志形式记录。针对每一条数据内容能够识别到具体的指标,把当前更新的数据信息记录到库表中。再按照对应的指标更新要求,感知更新日志表的数据库,就能够确保及时知道指标的更新频次是否符合预期,指标数据每次更新的数据内容,做到更新频次可监控,更新数据变动可追溯。
-
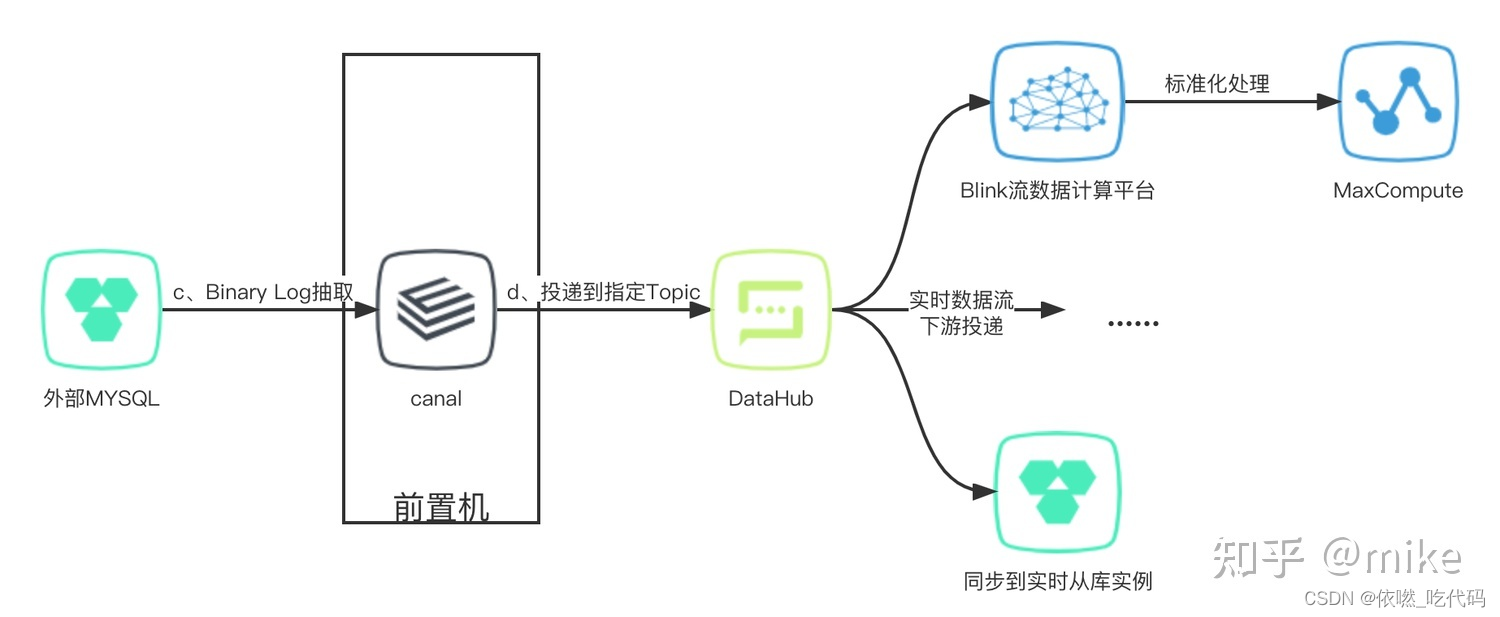
数据同步实时化
为了使数据能够进行实时同步,决定使用Canal接入到外部数据库,然后把Canal监听的BinaryLog接入到新建设的MySQL库中,使得两边的数据库数据同步延迟仅有秒级差异。Canal的接入也使得每日执行的同步任务得以取消,减少了额外的系统维护工作。而且BinaryLog的监听推送对外部数据库性能来说影响较少。 -
增量数据投递消费
此外,Canal投递消费能力能够拓展数据增量改动的体现形式。Canal把感知到的数据库变动内容投递到指定的MQ Topic,为后续的消费途径提供多样性。如:Canal订阅指定数据表的变动数据投递到Datahub中,投递的内容就如上面的数据结构展示。允许借助Blink计算平台对数据进行感知整合,实现业务场景的下聚合统计等实时计算诉求;也能够开放Datahub的Topic订阅权限,把增量数据的变动开发到指定使用者,提供实时数据变动推送。
总结
这个cannal与美团中的DTS比较类似,业务需求中可能监听表的插入、更新、删除的操作,然后发送mafka消息。
参考:
第一个