虽然LLM因其在单一模型内执行多种不同语言任务的能力而变得出名,但您的应用程序可能只需要执行单一任务。在这种情况下,您可以微调一个预训练的模型,以仅提高您感兴趣的任务的性能。例如,使用该任务的示例数据集进行摘要。有趣的是,相对较少的示例就可以取得良好的结果。通常只有500-1000个示例就可以与模型在预训练期间看到的数十亿篇文本形成鲜明对比,从而获得良好的性能。
然而,对单一任务进行微调存在一个潜在的缺点。这个过程可能导致一种称为灾难性遗忘的现象。灾难性遗忘发生是因为全面微调过程修改了原始LLM的权重。虽然这导致了在单一微调任务上的出色性能,但它可能会降低其他任务的性能。
例如,微调可以提高模型对评论进行情感分析的能力,并产生高质量的完成,
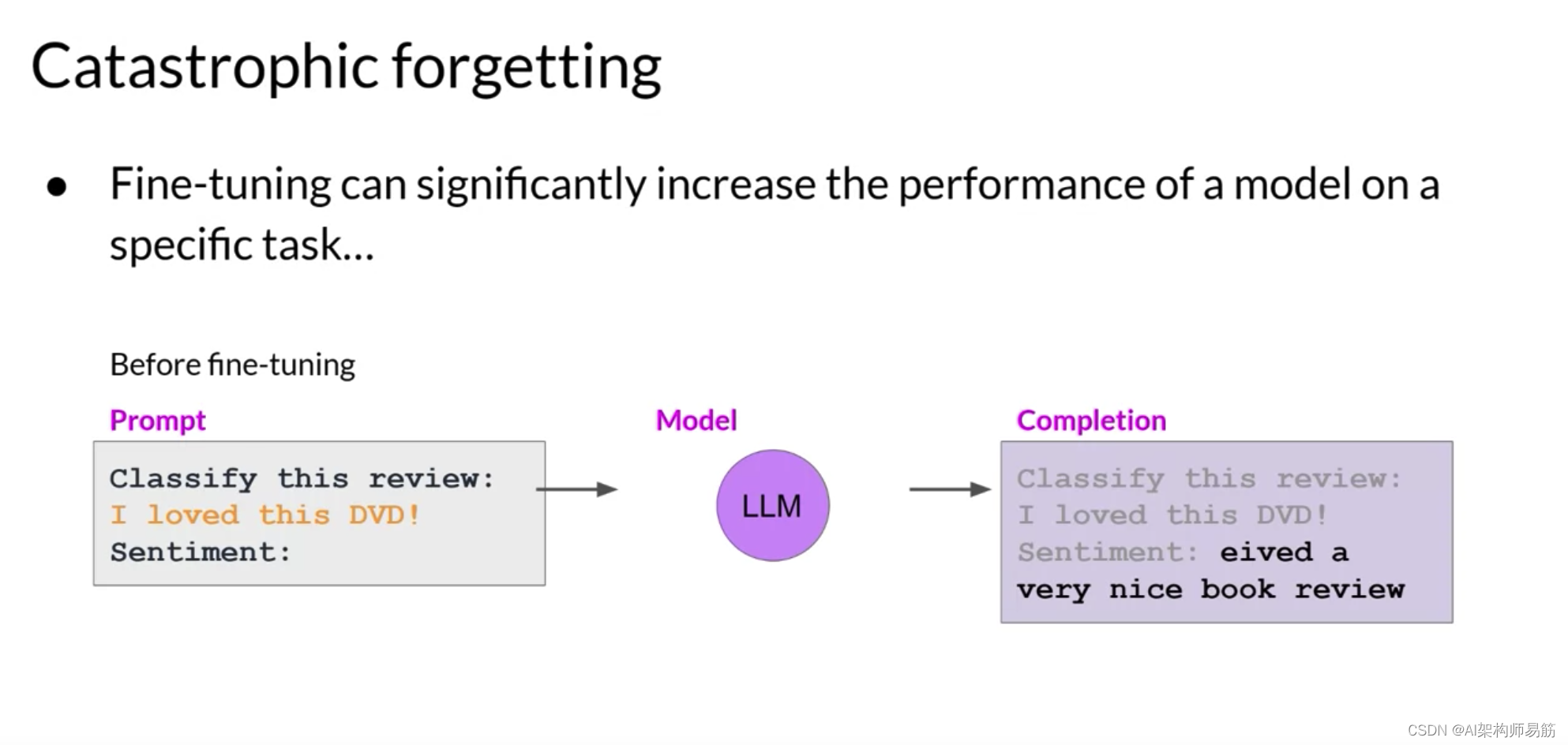
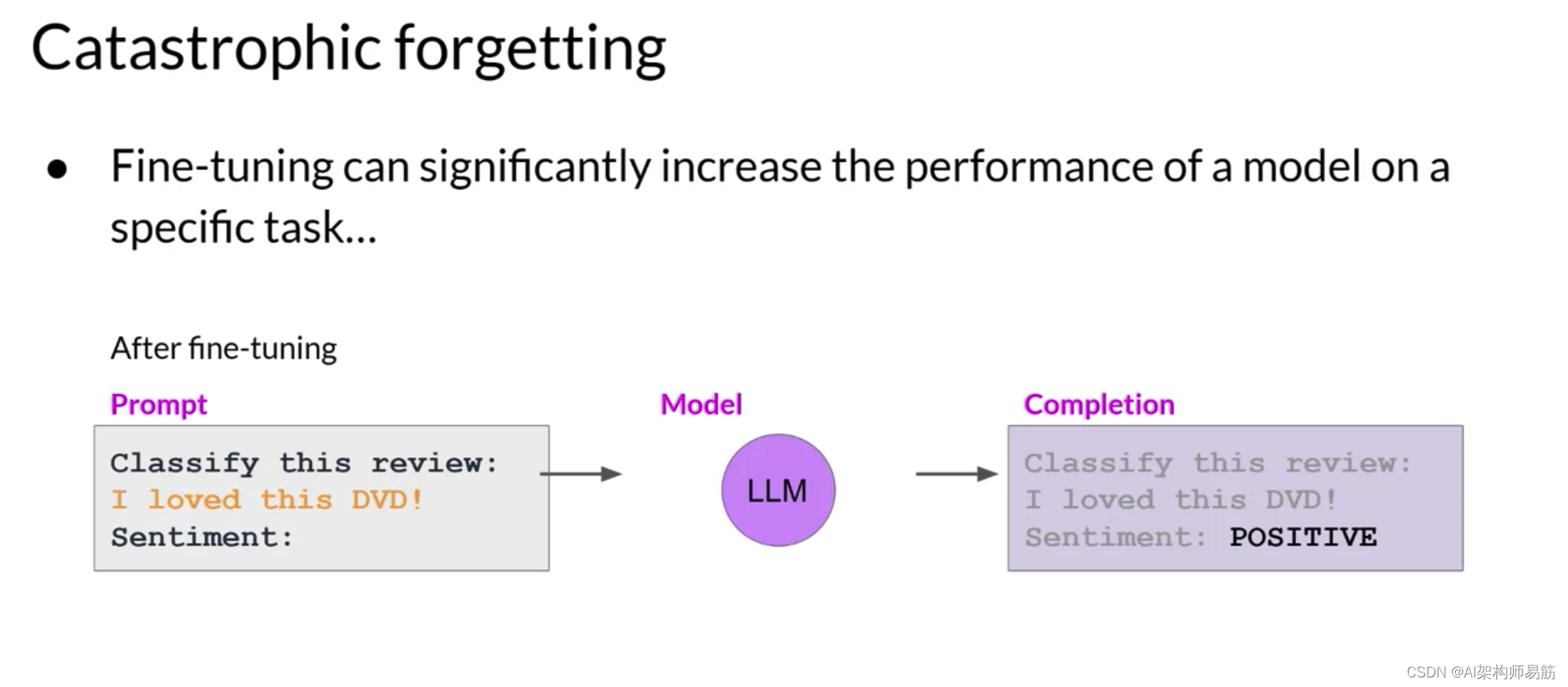
但模型可能会忘记如何执行其他任务。
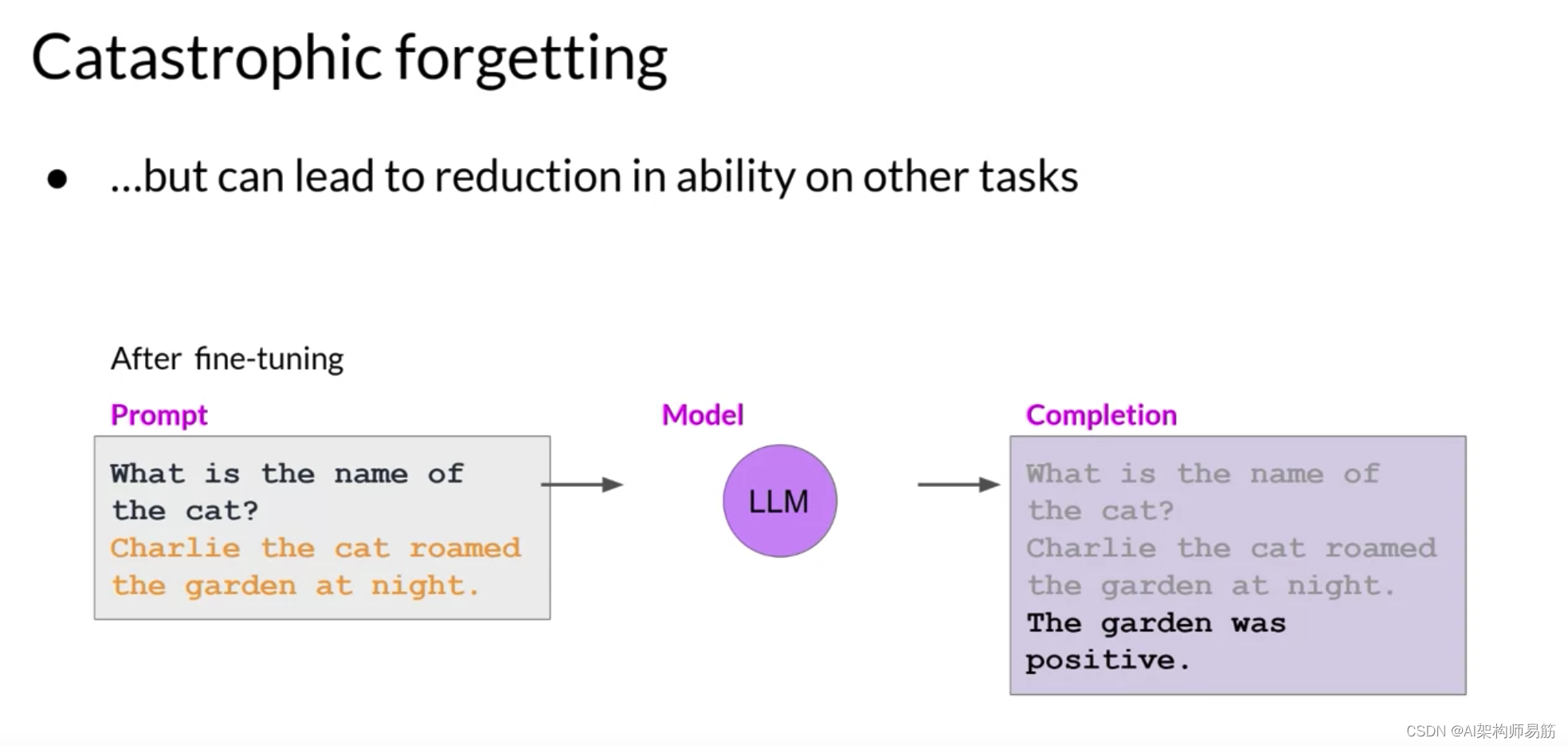
这个模型在微调之前知道如何正确地识别句子中猫名字为Charlie的命名实体识别任务。
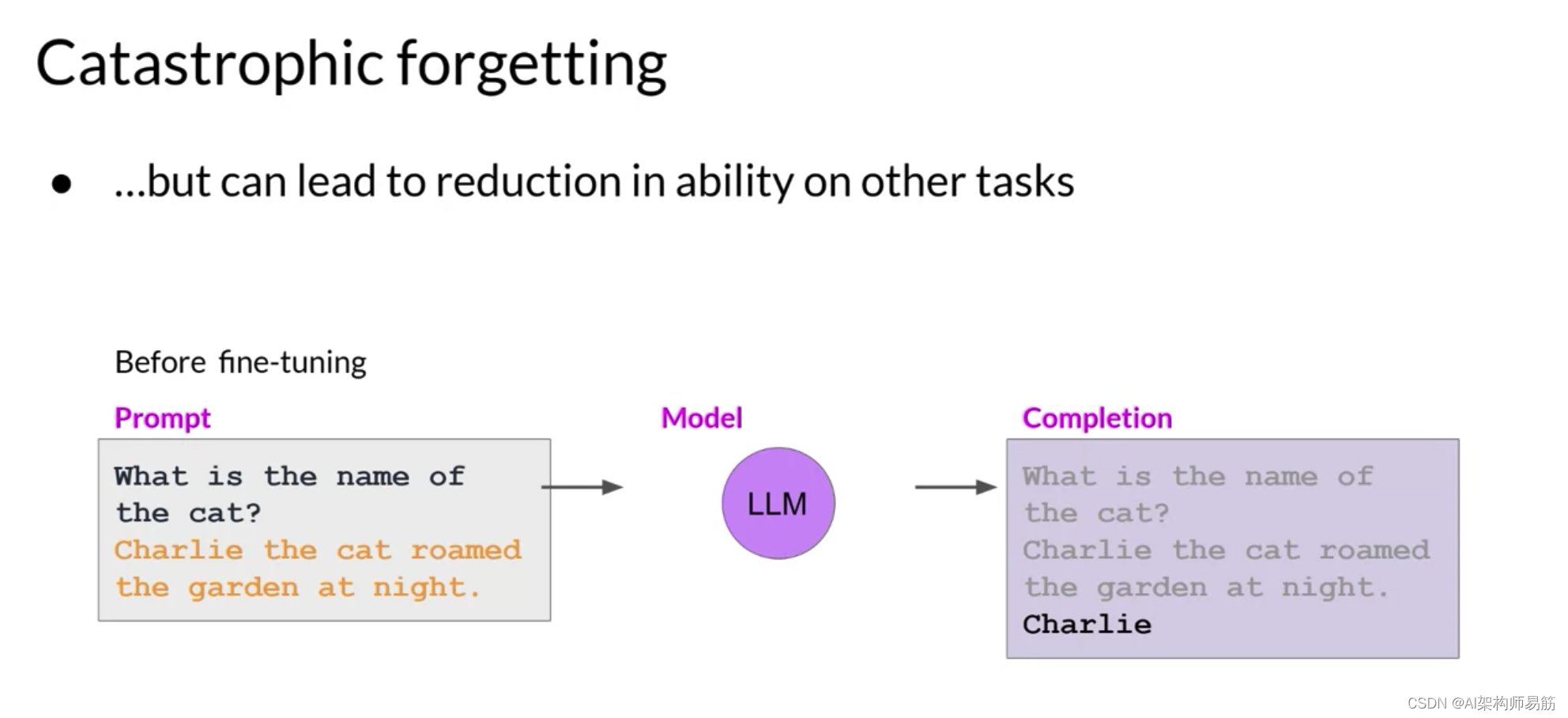
但微调后,模型再也不能执行这个任务,既混淆了它应该识别的实体,也表现出与新任务相关的行为。
那么您有哪些选项来避免灾难性遗忘呢?
- 首先,重要的是决定灾难性遗忘是否实际影响您的用例。如果您只需要在您微调的单一任务上获得可靠的性能,那么模型不能推广到其他任务可能不是问题。
- 如果您确实希望或需要模型保持其多任务泛化能力,您可以一次对多个任务进行微调。良好的多任务微调可能需要跨多个任务的50-100,000个示例,因此将需要更多的数据和计算来进行训练。我们将在短期内更详细地讨论这个选项。
- 我们的第二个选项是Parameter Efficient Fine-tuning执行参数高效微调,或简称为PEFT,而不是全面微调。PEFT是一组保留原始LLM权重并仅训练少量任务特定适配器层和参数的技术。由于大多数预训练权重保持不变,PEFT对灾难性遗忘表现出更大的鲁棒性。PEFT是一个令人兴奋和活跃的研究领域,我们将在本周晚些时候进行介绍。
与此同时,让我们继续观看下一个视频,并更仔细地了解多任务微调。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/cTZRI/fine-tuning-on-a-single-task