在LoRA中,目标是找到一种有效的方法来更新模型的权重,而不必再次训练每个参数。在PEFT中也有增加方法,旨在在不更改权重的情况下提高模型性能。在这个视频中,您将探索一个叫做prompt tuning的第二种参数高效微调方法。
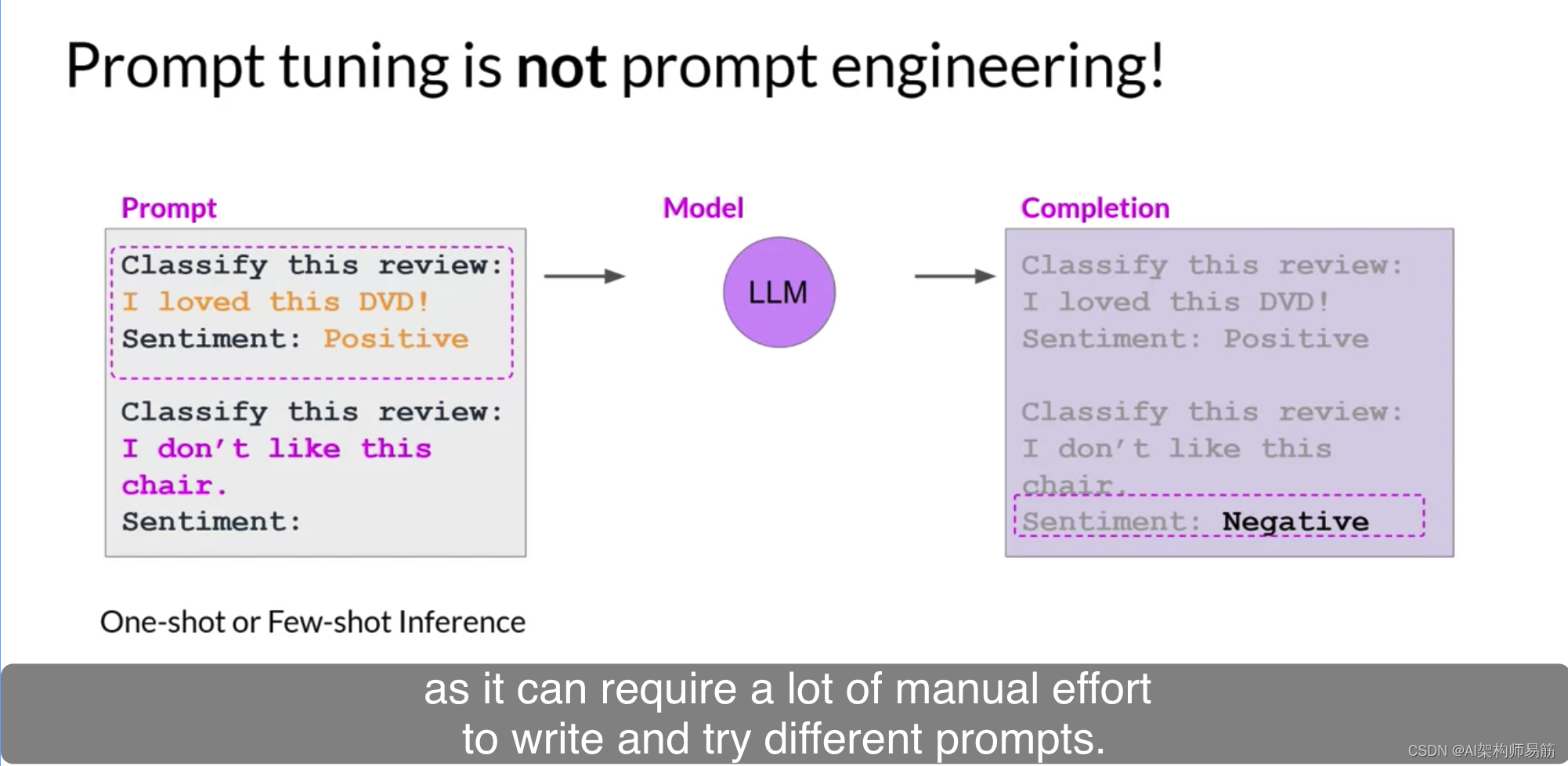
现在,prompt tuning听起来有点像prompt engineering,但它们彼此之间是非常不同的。使用prompt engineering,您可以修改您的提示的语言以获得所需的完成。这可能很简单,例如尝试不同的词语或短语,或者更复杂,例如包括一个或几次推断的示例。目标是帮助模型理解您要求它执行的任务的性质,并生成更好的完成。然而,prompt engineering有一些限制,因为编写并尝试不同的提示可能需要大量的手动努力。您还受到上下文窗口长度的限制,最后,您可能仍然无法达到您的任务所需的性能。
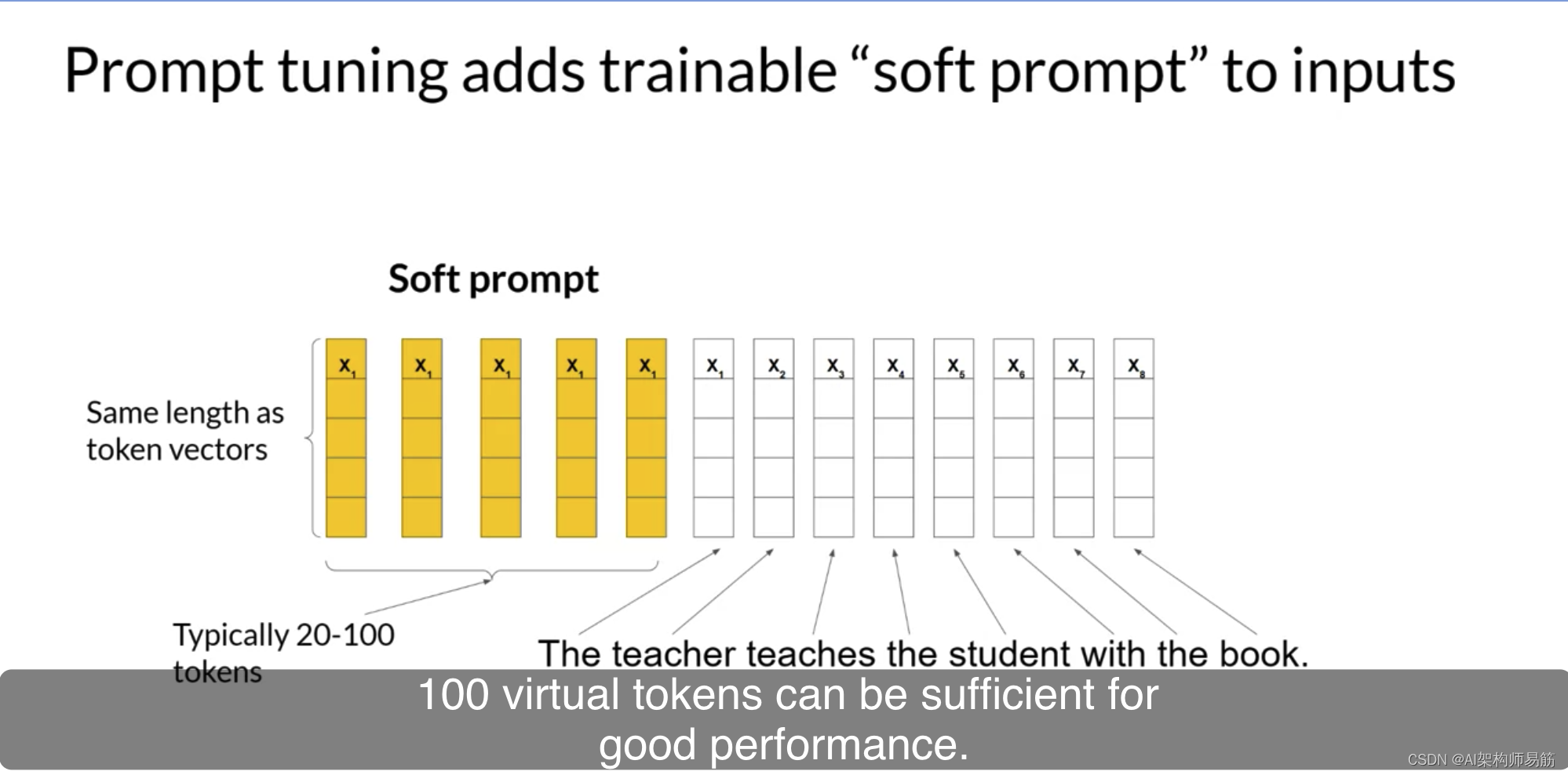
通过prompt tuning,您将额外的可训练令牌添加到您的提示中,并让监督学习过程确定它们的最佳值。这组可训练的令牌称为soft prompt,并附加到代表您的输入文本的嵌入向量。soft prompt向量与语言令牌的嵌入向量具有相同的长度。并且包括大约20到100个虚拟令牌可能足以获得良好的性能。
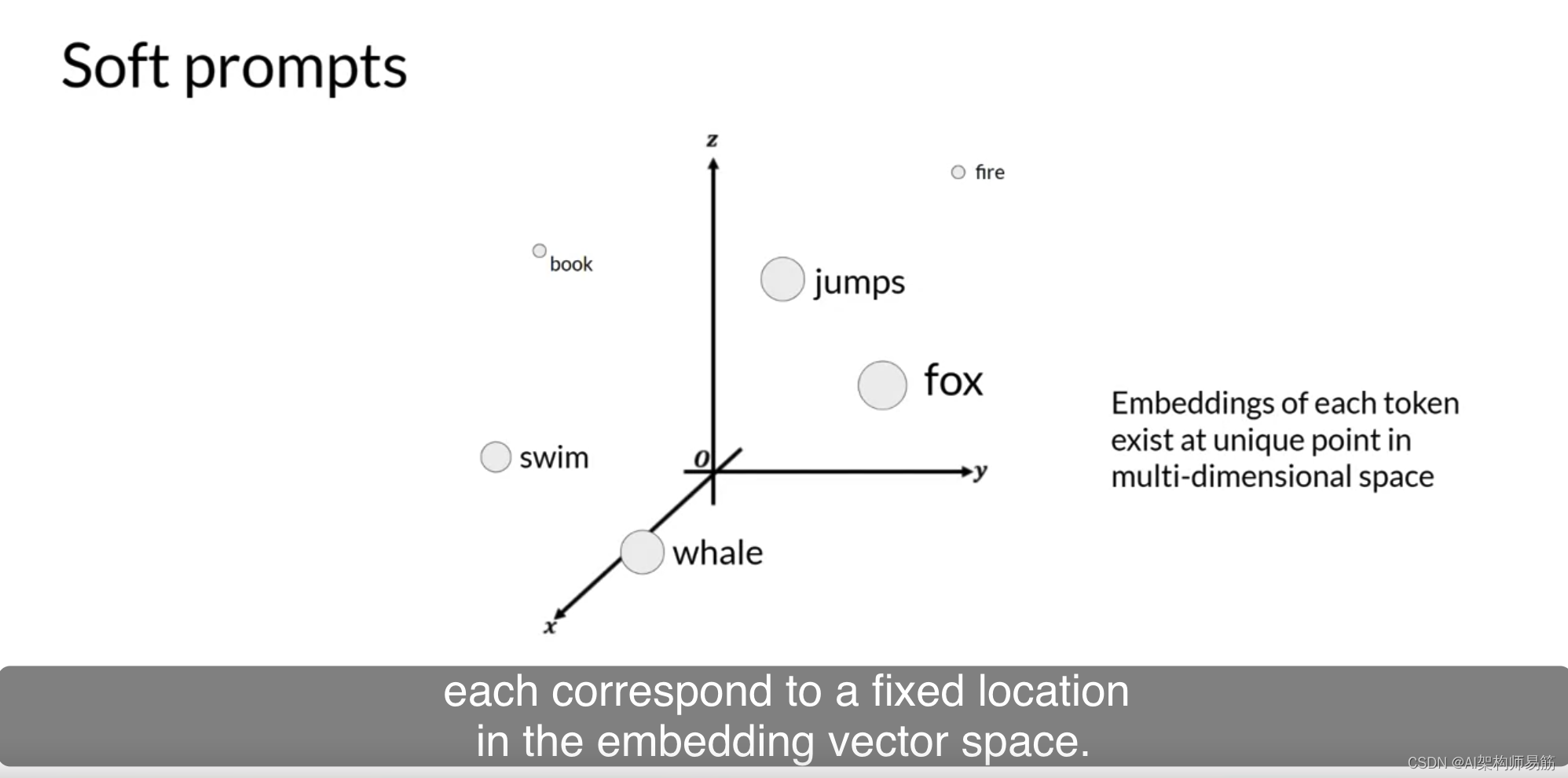
代表自然语言的令牌是硬的,因为它们每个都对应于嵌入向量空间中的固定位置。
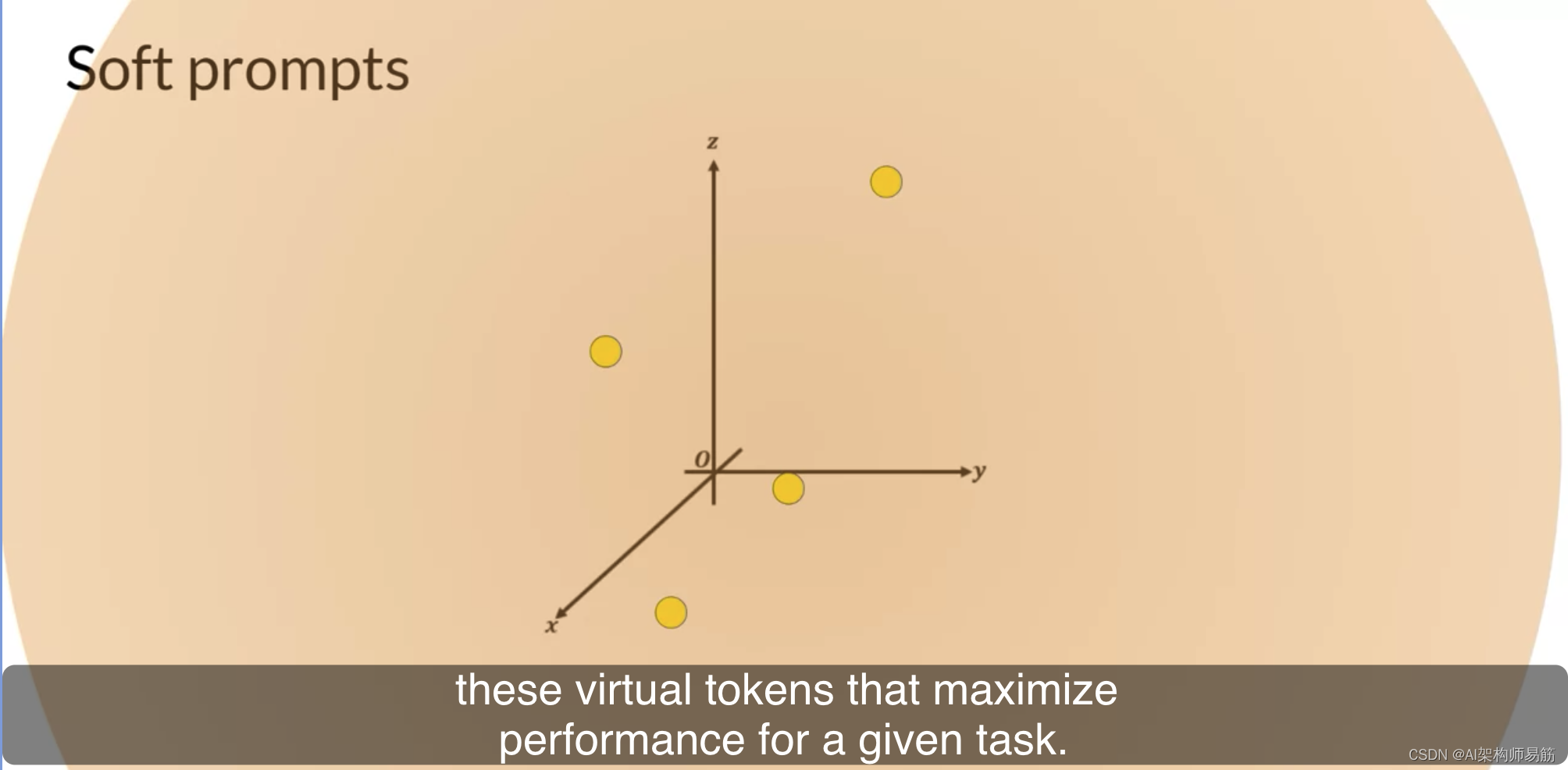
但是,soft prompt不是固定的自然语言的离散单词。相反,您可以将它们视为可以在连续的多维嵌入空间内采取任何值的虚拟令牌。通过监督学习,模型学习了这些虚拟令牌的值,以便为给定任务最大化性能。
在完全微调中,训练数据集由输入提示和输出完成或标签组成。在监督学习过程中更新了大型语言模型的权重。与prompt tuning相比,大型语言模型的权重被冻结,基础模型不会得到更新。
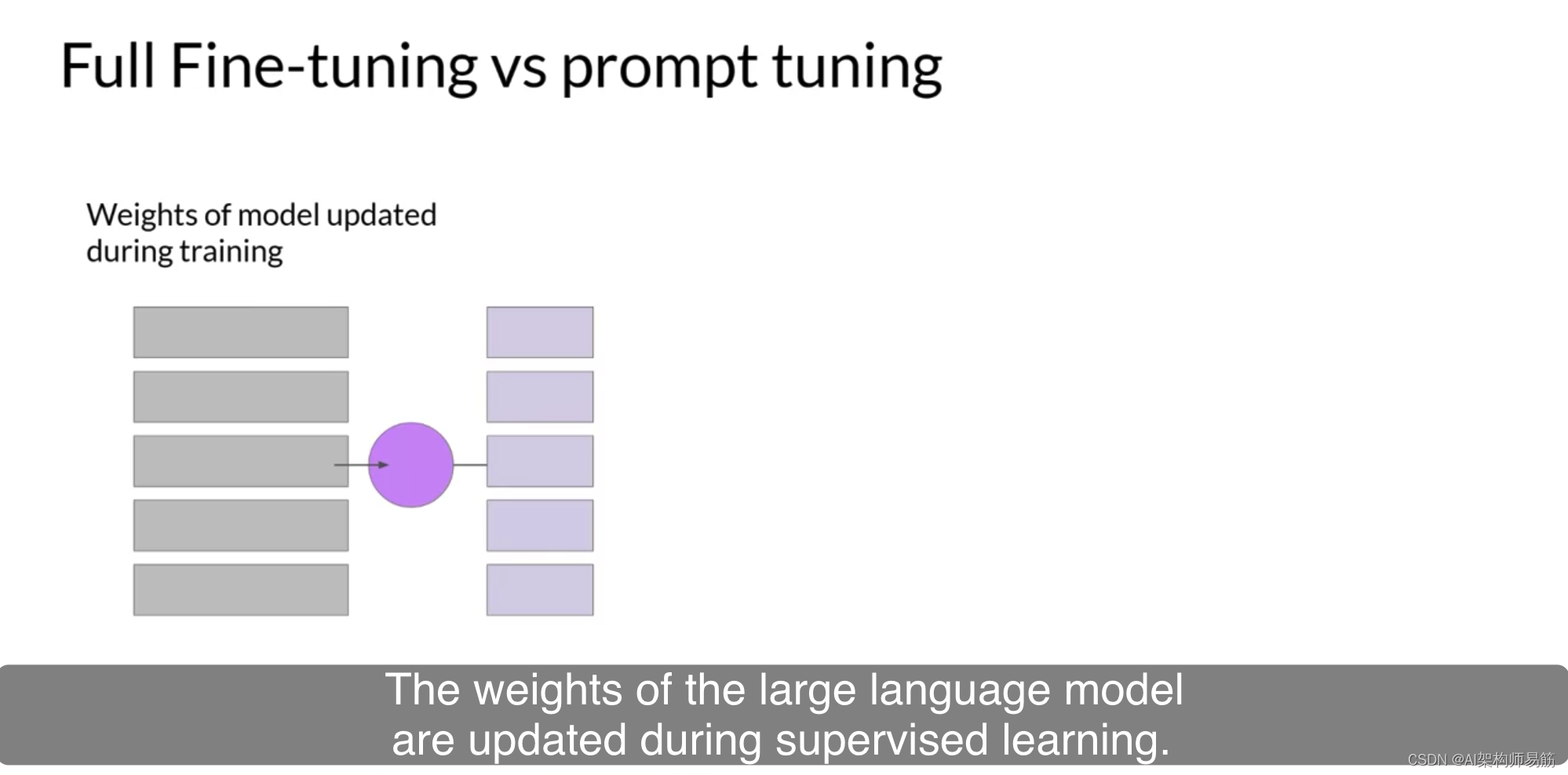
相反,随着时间的推移,soft prompt的嵌入向量得到了更新,
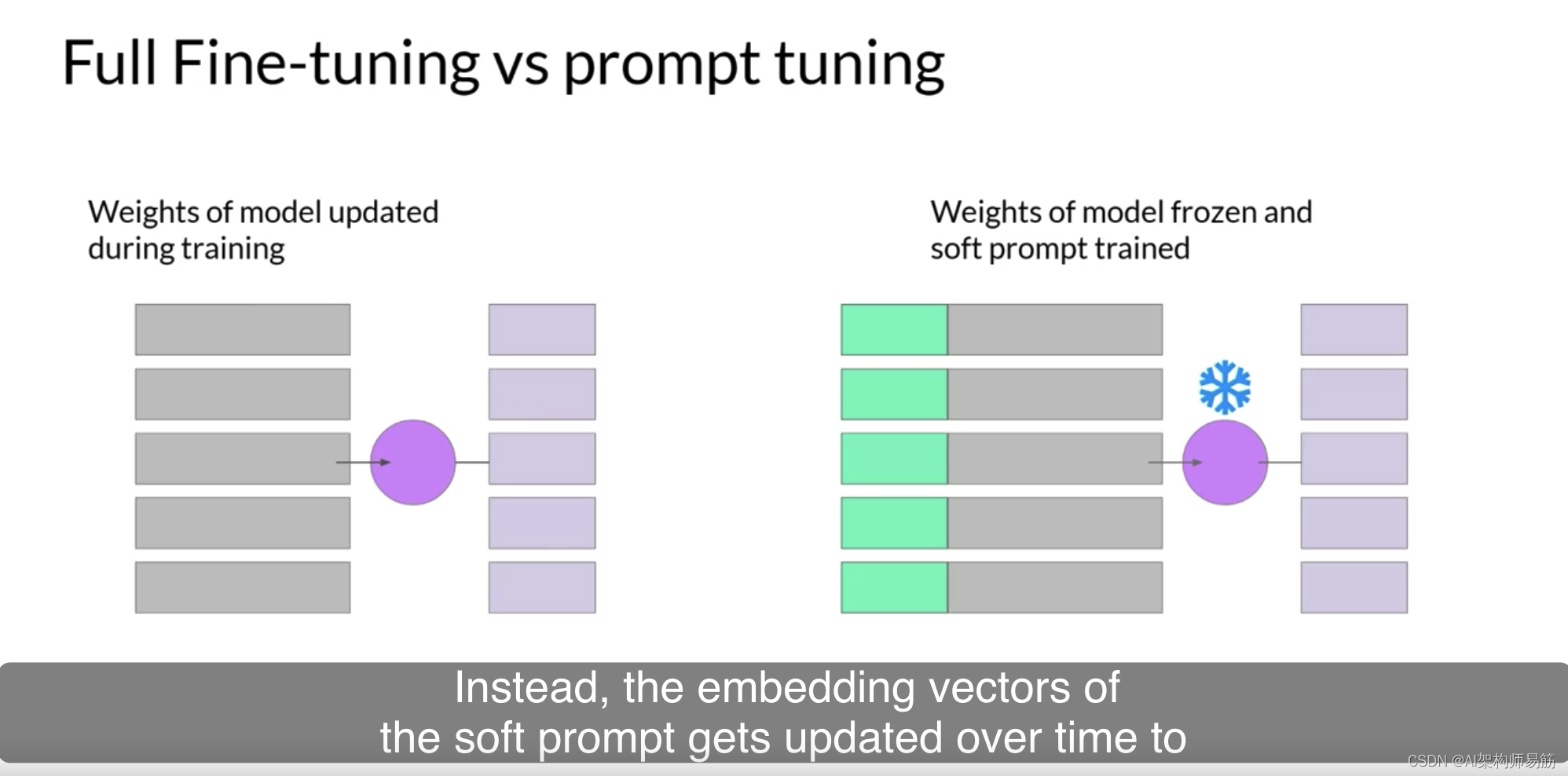
以优化模型的提示完成。
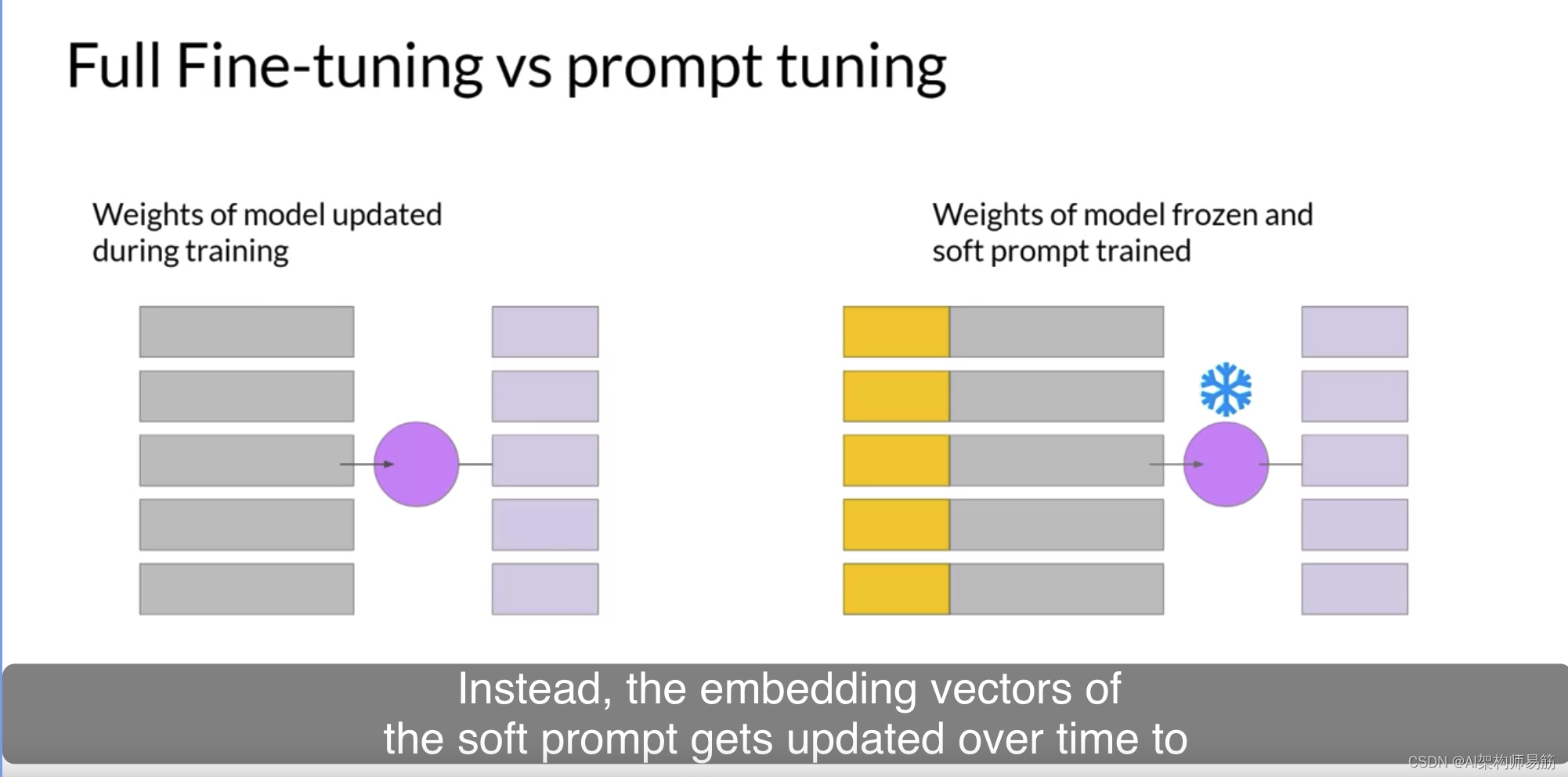
prompt tuning是一种非常参数有效的策略,因为只有少数参数正在被训练。
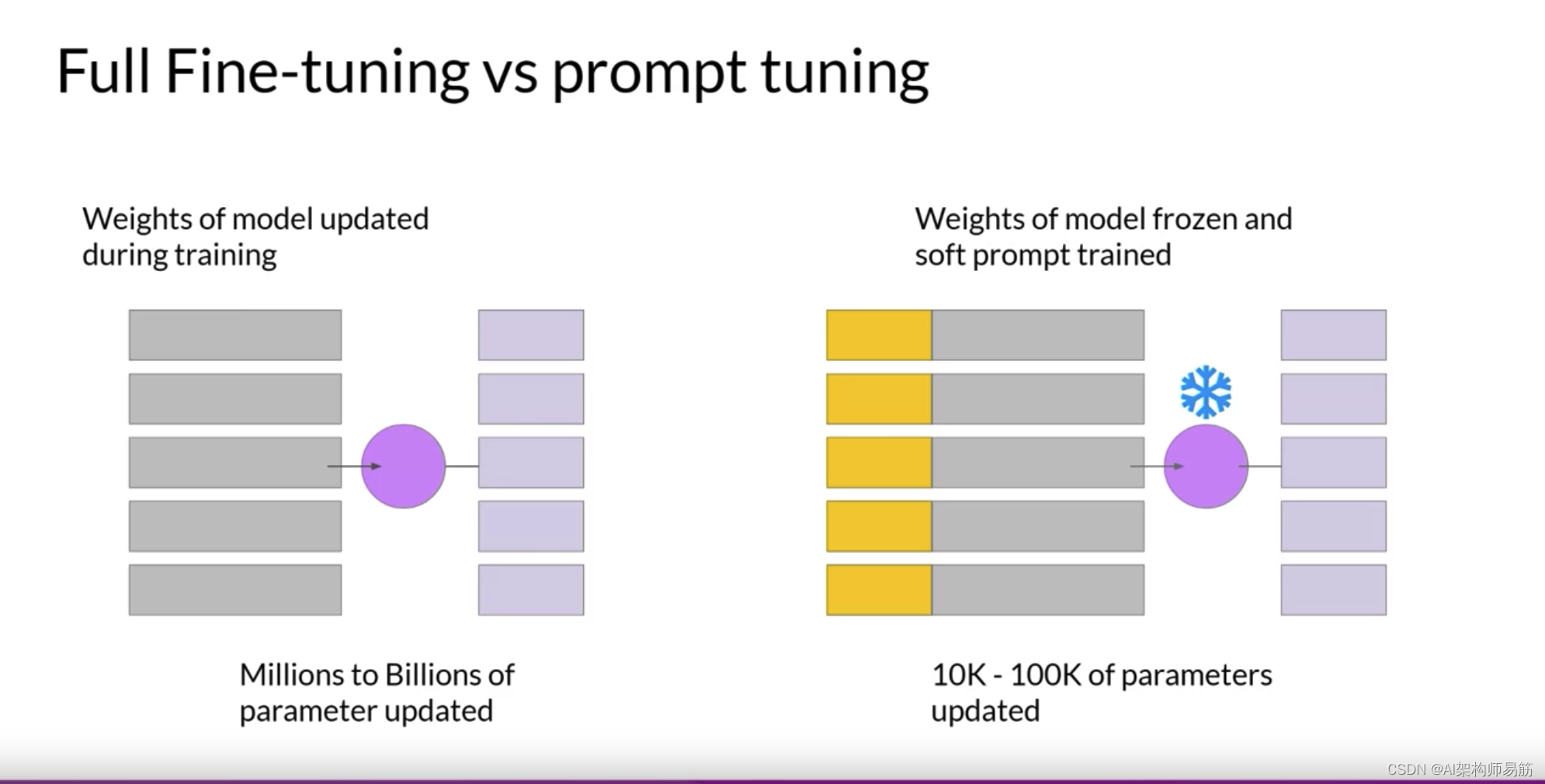
与完全微调中的数百万到数十亿的参数相比,这与您在LoRA中看到的相似。您可以为每个任务训练一组soft prompt,然后在推理时轻松地互换它们。您可以为一个任务训练一组soft prompt,

为另一个任务训练另一组。要使用它们进行推理,您可以使用已学习的令牌来预处理您的输入提示;要切换到另一个任务,您只需更改soft prompt。Soft prompts在磁盘上非常小,因此这种微调非常高效和灵活。您会注意到,同一个LLM被用于所有的任务,您所要做的就是在推理时切换soft prompts。

那么prompt tuning的性能如何呢?在原始论文中,通过Brian Lester和Google的合作者探索该方法。作者将prompt tuning与多种模型大小的其他方法进行了比较。在这篇论文中的这个图中,您可以看到X轴上的模型大小和Y轴上的SuperGLUE分数。这是您在本周早些时候了解的评估基准,它评估模型在多种不同语言任务上的性能。红线显示了通过完全微调创建的模型的分数。
而橙色线显示了使用多任务微调创建的模型的得分。绿线显示了prompt tuning的性能,最后,蓝线显示了仅用于prompt engineering的得分。如您所见,对于较小的LLM,prompt tuning的性能不如完全微调。
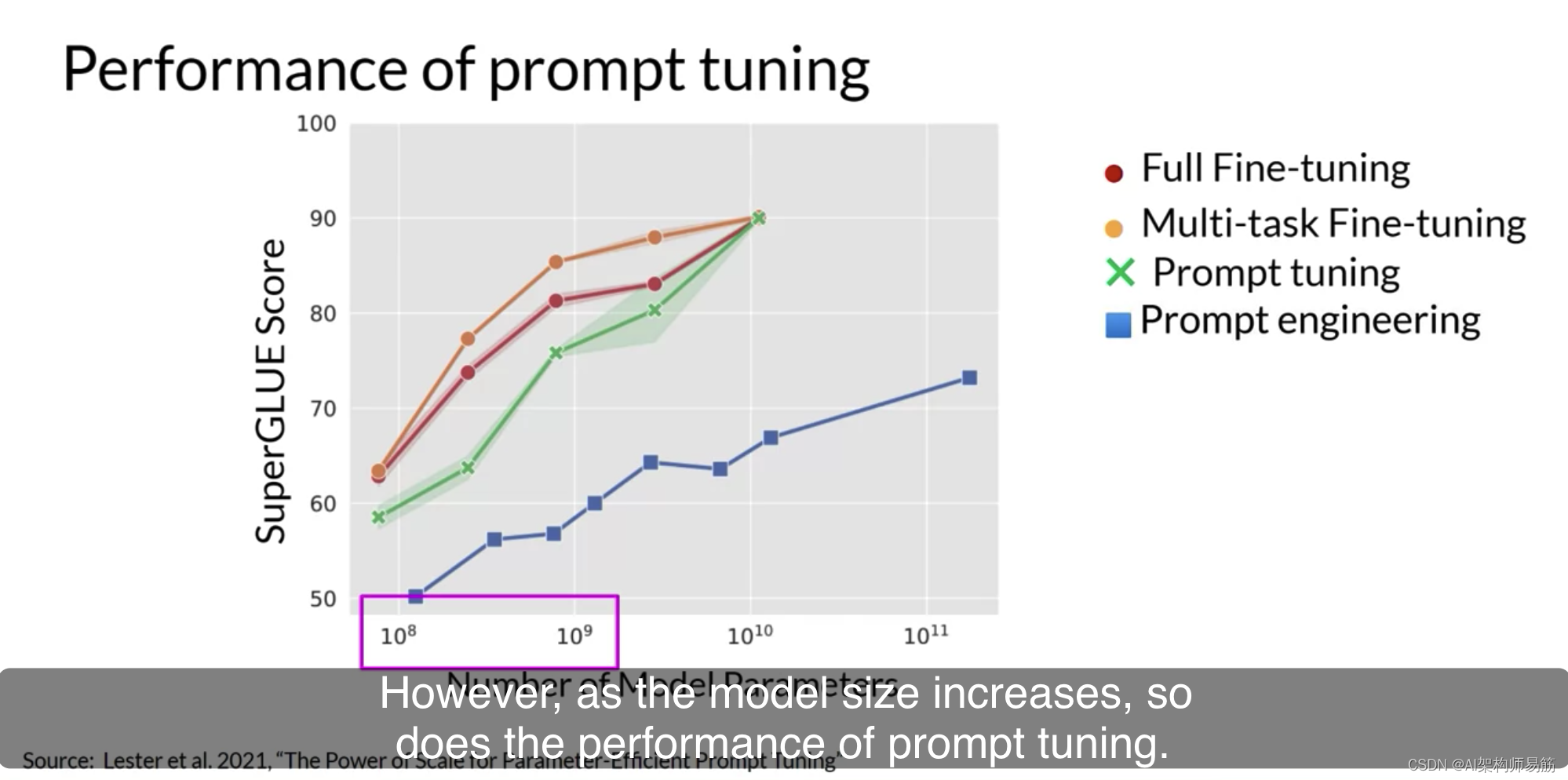
但是,随着模型大小的增加,prompt tuning的性能也随之增加。一旦模型拥有大约100亿个参数,prompt tuning就可以像完全微调一样有效,并在仅使用prompt engineering上提供了显着的性能提升。
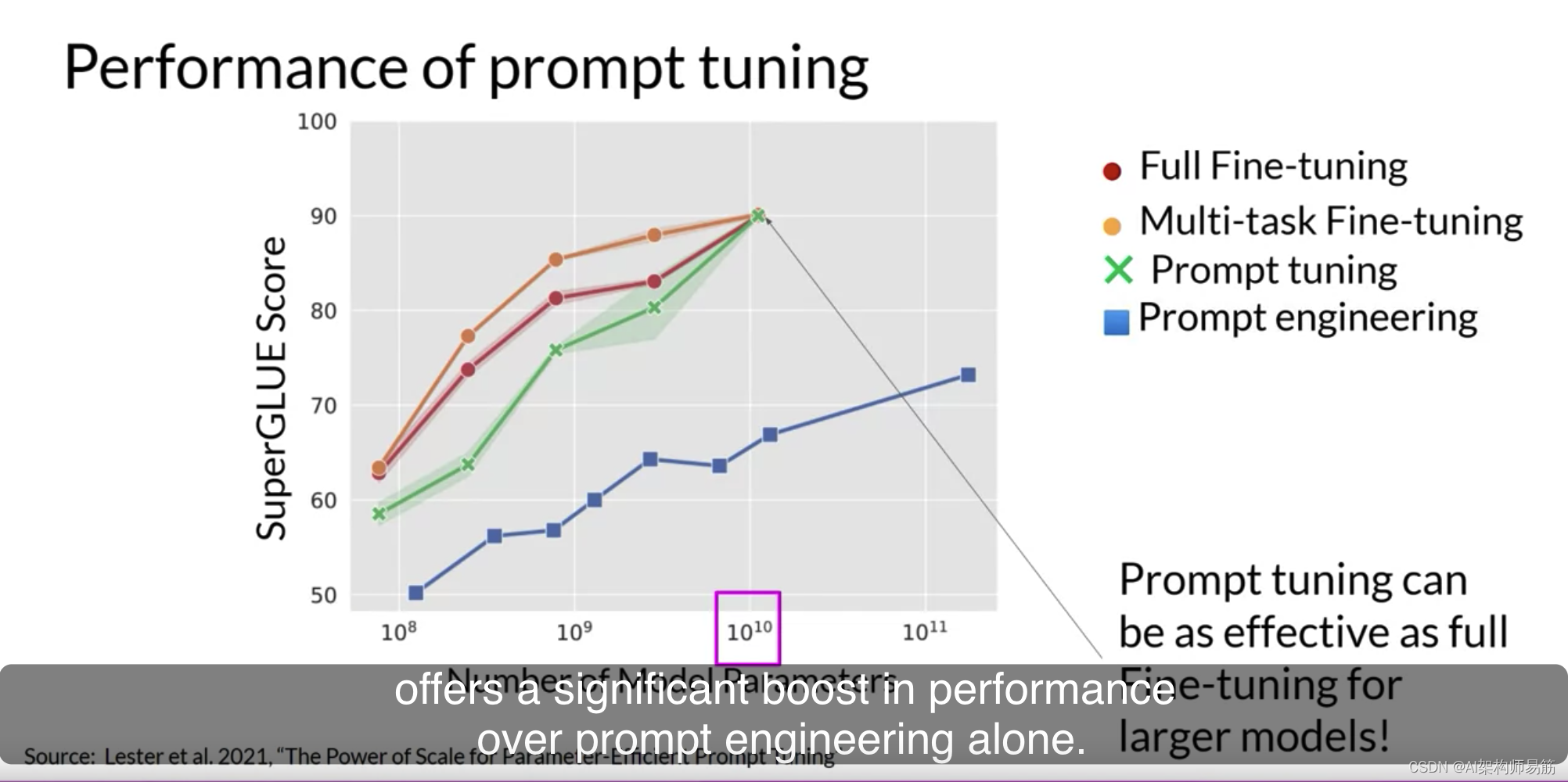
需要考虑的一个潜在问题是学习的虚拟令牌的可解释性。请记住,由于soft prompt令牌可以在连续的嵌入向量空间内采取任何值。经过训练的令牌不对应于LLM词汇中的任何已知令牌、单词或短语。

然而,对soft prompt位置的最近邻令牌的分析显示,它们形成了紧密的语义簇。与soft prompt令牌最接近的单词具有相似的含义。识别的单词通常与任务有关,这表明提示正在学习单词般的表示。
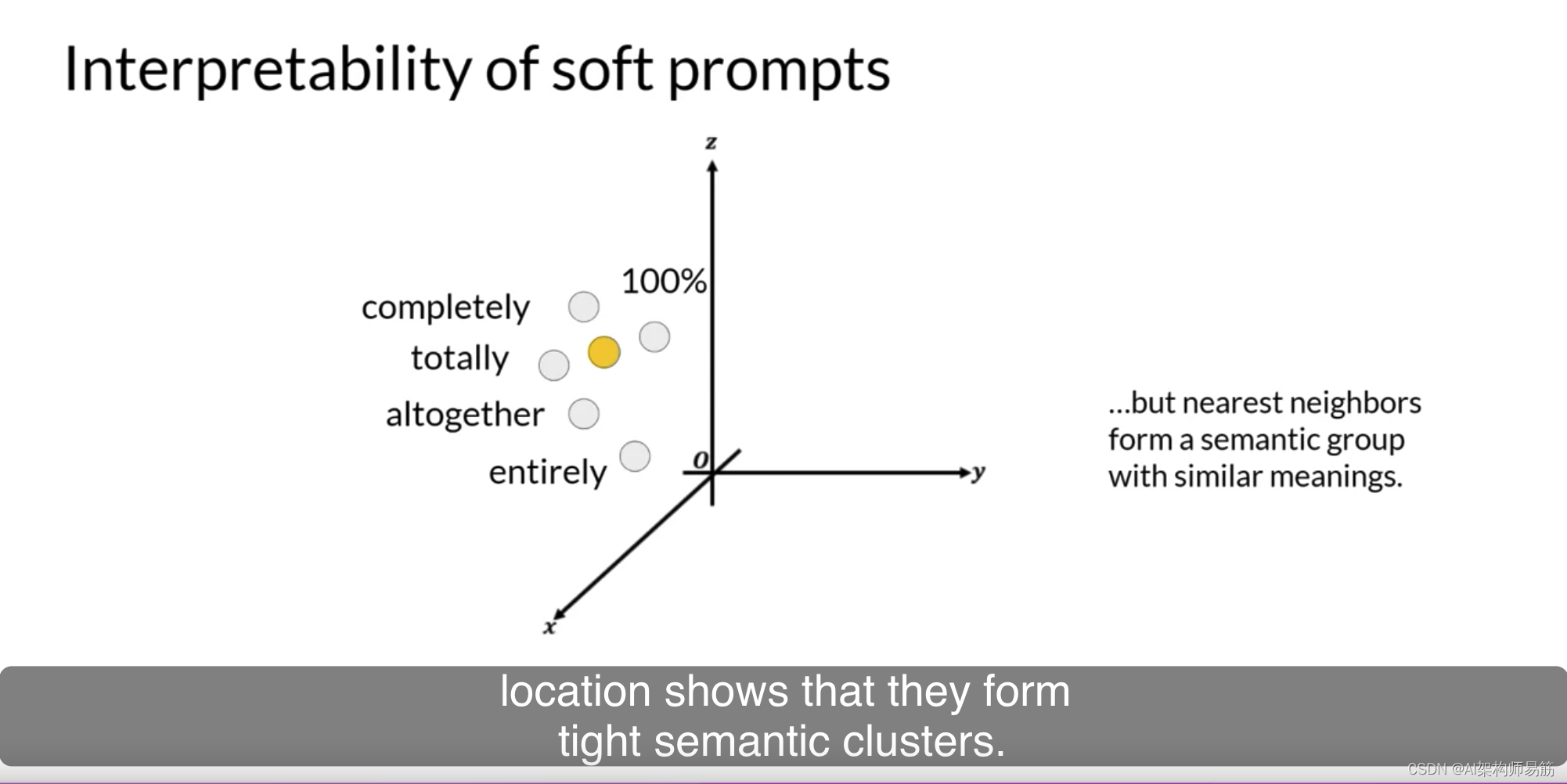
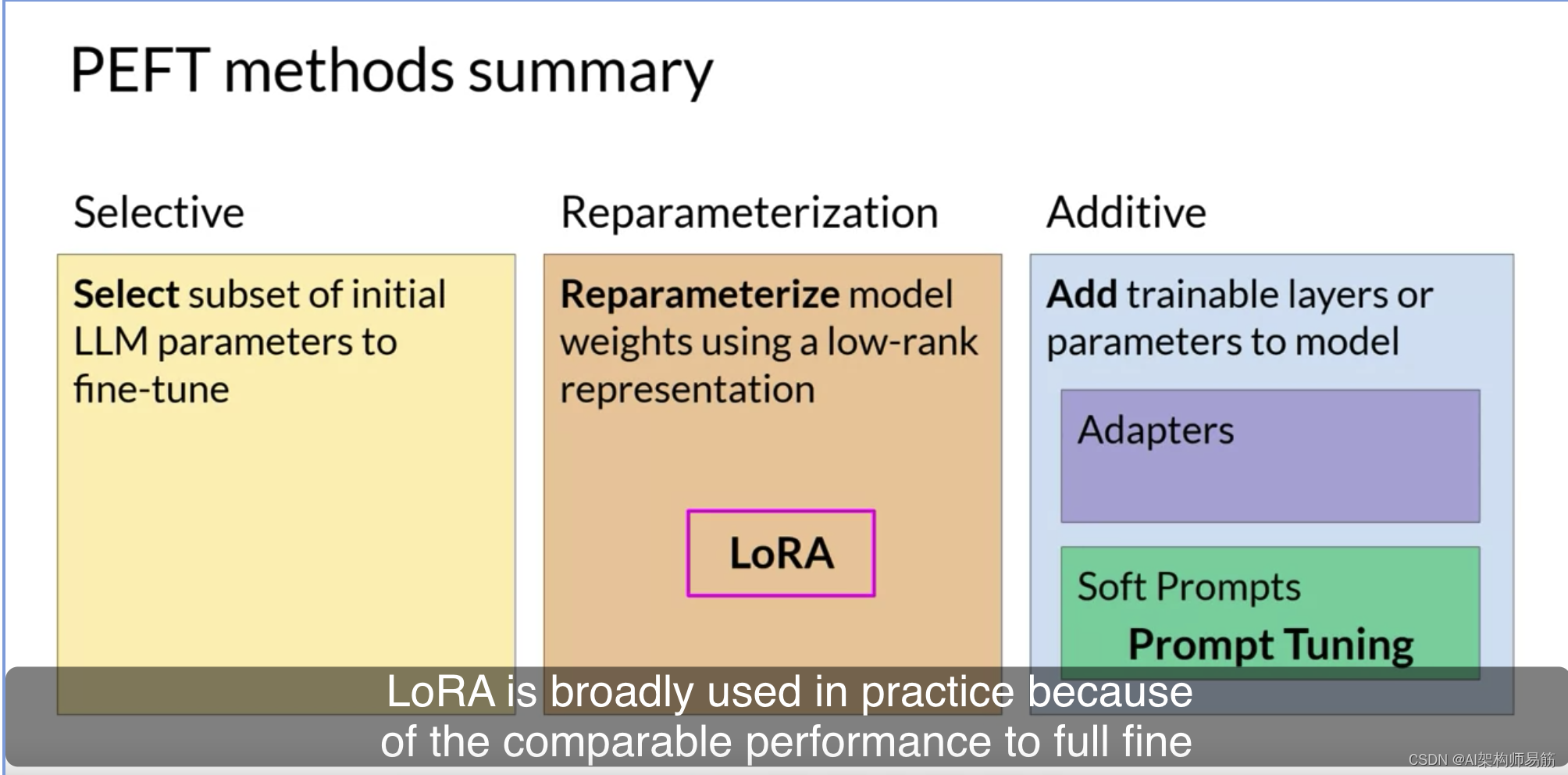
您在本课中探讨了两种PEFT方法:LoRA,它使用等级分解矩阵以高效的方式更新模型参数;和Prompt Tuning,其中添加了可训练的令牌到您的提示,并且模型权重保持不变。这两种方法都使您能够微调模型,可能提高您的任务性能,同时使用比完全微调方法更少的计算资源。
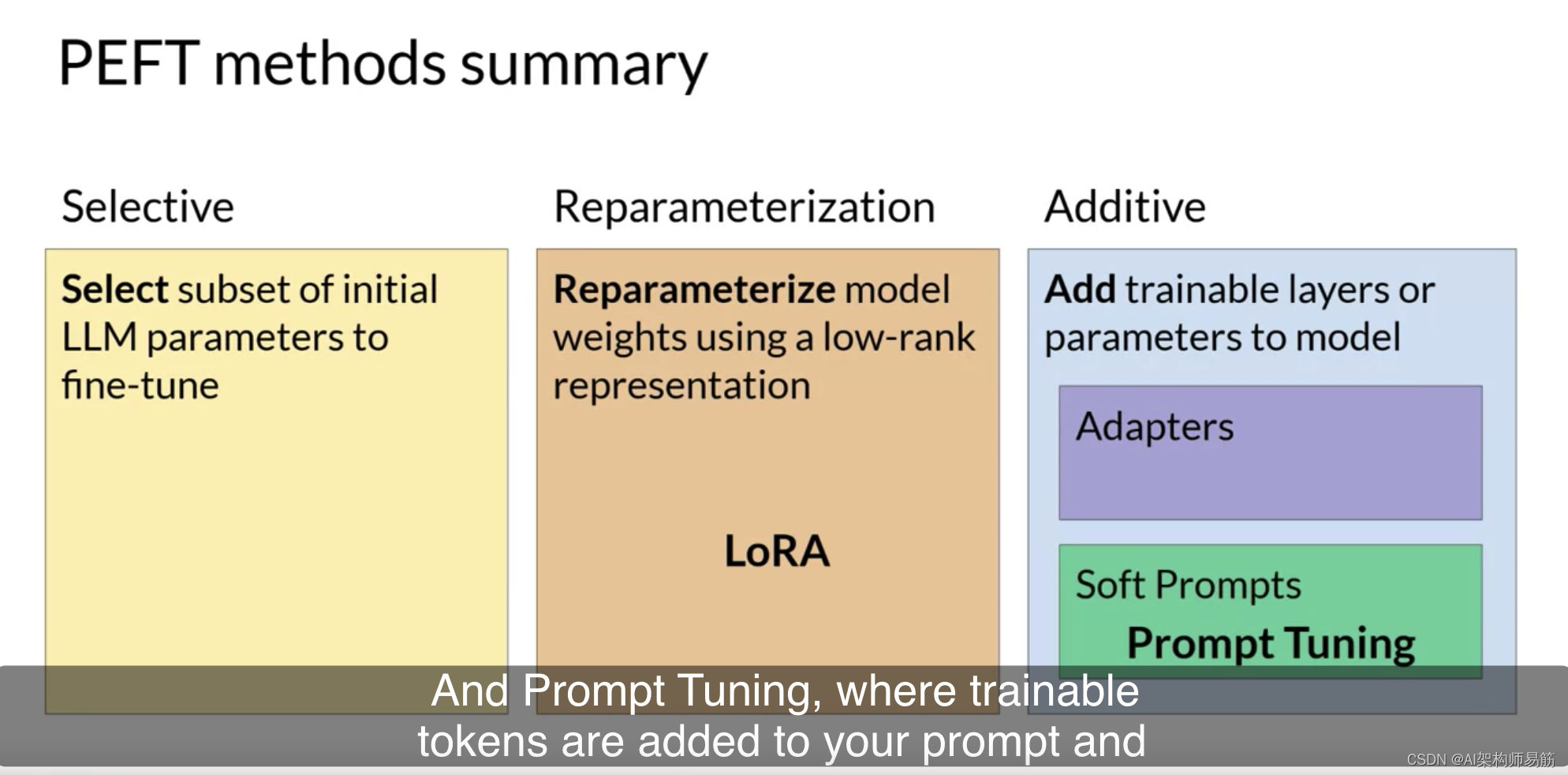
LoRA因其与完全微调在许多任务和数据集上具有可比性能而在实践中被广泛使用,您将在本周的实验室中尝试一下。
因此,恭喜您完成了第二周。让我们回顾一下您本周早些时候所看到的内容,Mike带您了解了如何通过一个称为指令微调的过程来适应基础模型。
一路上,您看到了用于训练FLAN-T5模型的一些提示模板和数据集。您还了解了如何使用ROUGE和HELM等评估指标和基准来衡量模型微调期间的成功。
在实践中,指令微调已经证明在广泛的自然语言用例和任务中非常有效和有用。只需几百个例子,您就可以微调一个模型以适应您的特定任务,这真是令人惊奇。
接下来,您了解了参数有效的微调(PEFT)是如何减少微调模型所需的计算量的。您了解了可以用于此目的的两种方法,LoRA和Prompt Tuning。顺便说一下,您还可以将LoRA与您在第一周了解的量化技术相结合,以进一步减少您的内存占用。这在实践中被称为QLoRA。实践中,PEFT被大量用于最小化计算和内存资源。从而最终降低微调的成本,让您充分利用您的计算预算,并加速您的开发过程。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/8dnaU/peft-techniques-2-soft-prompts