python调用腾讯语音合成接口
一、安装腾讯云开发包
pip install tencentcloud -i https://mirrors.cloud.tencent.com/pypi/simple/
需要注意的是,这里一定要指定源:https://mirrors.cloud.tencent.com/pypi/simple/。否则很可能会安装失败。
二、开通腾讯语音服务
2.1 登录腾讯云平台
地址:https://cloud.tencent.com/
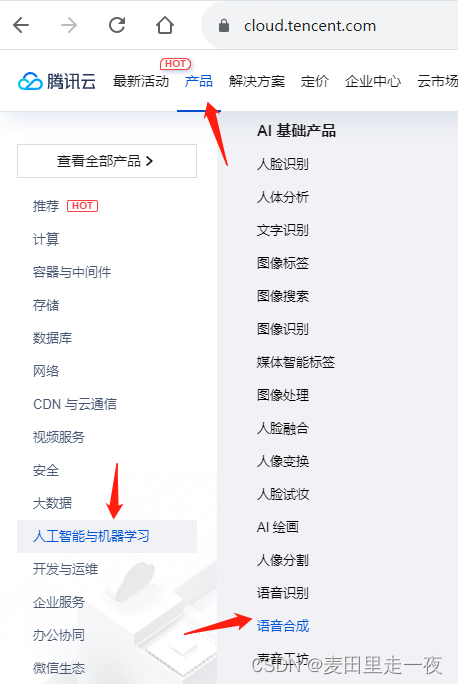
在主菜单选择【产品】|【人工智能与机器学习】|【语音合成】
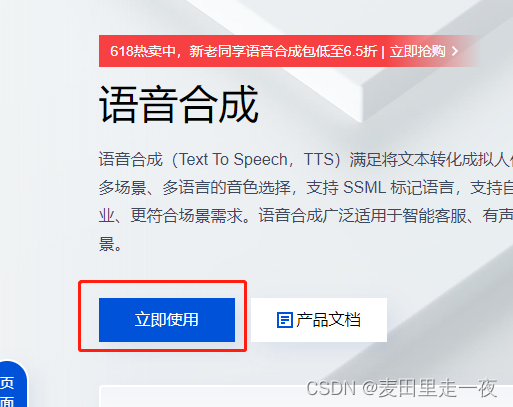
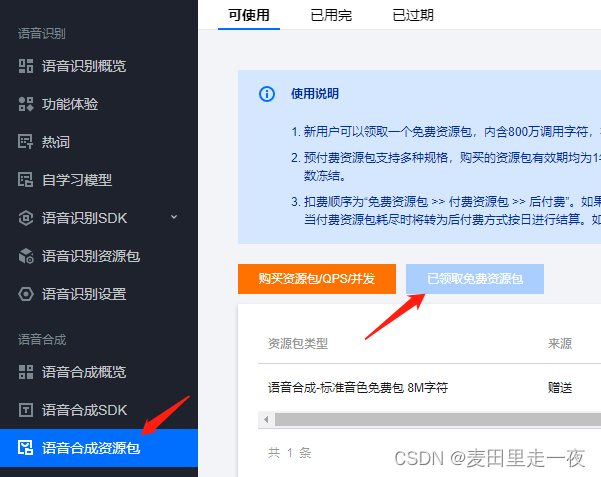
领取免费资源包。
首次领取可免费使用800万的语音合成。
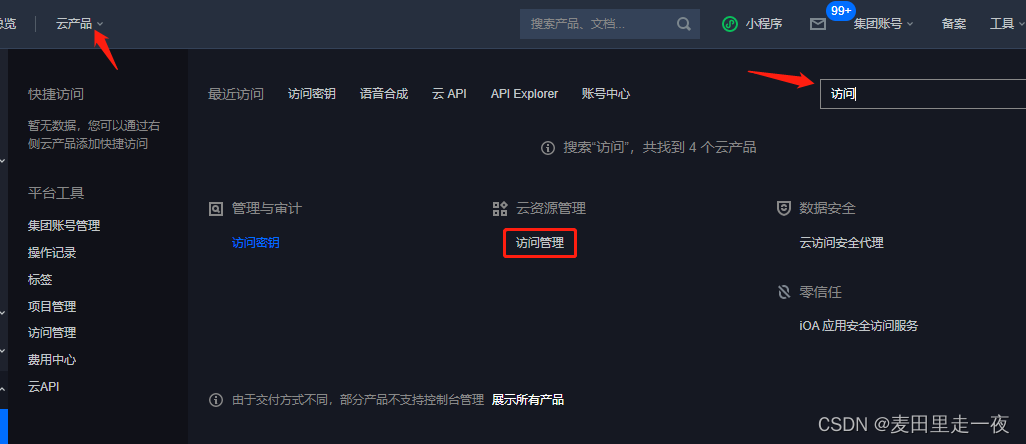
2.2 生成SecretKey
进入【云资源管理】|【访问管理】
在API密钥管理页面【新建密钥】

会得到三个值:APPID,SecretId和SecretKey
请把他们记下来。
三、写代码
3.1 导入开发包
# -*- coding:utf-8 -*-
import json, uuid
import base64
# 语音合成包客户端
from tencentcloud.tts.v20190823.tts_client import TtsClient
# 语音合成数据模型
from tencentcloud.tts.v20190823.models import TextToVoiceRequest
# 腾讯云异常处理
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
# 参数处理工具
from configparser import ConfigParser
# 安全验证
from tencentcloud.common.credential import Credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
3.2 配置文件tcloud_auth.ini
将2.2中获取到的密钥信息配置在这个文件中。
#用户鉴权参数
#测试账号
[authorization]
AppId=你的AppId
SecretId=你的SecretId
SecretKey=你的SecretKey
[expired]
ExpiredTime=3600
3.3 调用接口生成语音
创建一个类voice_generation,类中函数text_to_voice的功能是将文本合成语音,并将语音数据写成一个语音文件。
代码如下:
auth_file_path = "./voice/conf/tcloud_auth.ini"
class voice_generation():
def __init__(self) -> None:
conf = ConfigParser()
conf.read(auth_file_path)
self.appid = conf.getint("authorization","AppId")
self.secretId = conf.get("authorization", "SecretId")
self.secretKey = conf.get("authorization", "SecretKey")
def text_to_voice(self,text):
try:
# 实例化一个认证对象,入参需要传入腾讯云账户 SecretId 和 SecretKey,此处还需注意密钥对的保密
# 代码泄露可能会导致 SecretId 和 SecretKey 泄露,并威胁账号下所有资源的安全性。以下代码示例仅供参考,建议采用更安全的方式来使用密钥,请参见:https://cloud.tencent.com/document/product/1278/85305
# 密钥可前往官网控制台 https://console.cloud.tencent.com/cam/capi 进行获取
cred = Credential(self.secretId, self.secretKey)
# 实例化一个http选项,可选的,没有特殊需求可以跳过
httpProfile = HttpProfile()
httpProfile.endpoint = "tts.tencentcloudapi.com"
# 实例化一个client选项,可选的,没有特殊需求可以跳过
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
# 实例化要请求产品的client对象,clientProfile是可选的
client = TtsClient(cred, "ap-shenzhen-fsi", clientProfile)
# 实例化一个请求对象,每个接口都会对应一个request对象
req = TextToVoiceRequest()
sessionid = uuid.uuid4().hex
params = {
"Text": text,
"SessionId": sessionid,
"Volume": 0,
"Speed": 0,
"ProjectId": 0,
"ModelType": 1,
"VoiceType": 1009,
"PrimaryLanguage": 1,
"SampleRate": 16000,
"Codec": "mp3",
"SegmentRate": 0,
"EmotionCategory": "neutral",
"EmotionIntensity": 100
}
req.from_json_string(json.dumps(params))
# 返回的resp是一个TextToVoiceResponse的实例,与请求对象对应
resp = client.TextToVoice(req)
# 输出json格式的字符串回包
print(resp.RequestId)
audio = resp.Audio.encode()
file_path = f"static/voice/{
sessionid}.mp3"
with open(file_path, "wb") as f:
f.write(base64.decodebytes(audio))
f.close()
return f"{
sessionid}.mp3"
except TencentCloudSDKException as err:
print(err)
3.4 初始化函数
3.4.1 读取参数
加载3.2中创建的参数配置文件,读出文件中的配置信息,即,AppId,SecretId,SecretKey并存放在变量中。
def __init__(self) -> None:
conf = ConfigParser()
conf.read(auth_file_path)
self.appid = conf.getint("authorization","AppId")
self.secretId = conf.get("authorization", "SecretId")
self.secretKey = conf.get("authorization", "SecretKey")
3.5 重要参数说明
3.5.1 创建验证信息
cred = Credential(self.secretId, self.secretKey)
3.5.2 接口地址
tts.tencentcloudapi.com是腾讯语音合成接口地址
httpProfile = HttpProfile()
httpProfile.endpoint = "tts.tencentcloudapi.com"
3.5.3 语音合成参数
req = TextToVoiceRequest()
sessionid = uuid.uuid4().hex
params = {
"Text": text,
"SessionId": sessionid,
"Volume": 0,
"Speed": 0,
"ProjectId": 0,
"ModelType": 1,
"VoiceType": 1009,
"PrimaryLanguage": 1,
"SampleRate": 16000,
"Codec": "mp3",
"SegmentRate": 0,
"EmotionCategory": "neutral",
"EmotionIntensity": 100
}
req.from_json_string(json.dumps(params))
必须参数:
| 参数 | 值 |
|---|---|
| Text | 要转换成语音的文本 |
| SessionId | 一个字符串,回原样返回 |
3.6 输出语音文件
语音合成接口,将合成的语音以base64格式数据返回。因此在存放文件时,需要对数据进行base64解码。
3.6.1 生成语音并储存为语音文件
代码:
# 返回的resp是一个TextToVoiceResponse的实例,与请求对象对应
resp = client.TextToVoice(req)
# 输出json格式的字符串回包
print(resp.RequestId)
# 返回Audio为字符串型,因此需要先进行二进制编码
audio = resp.Audio.encode()
file_path = f"static/voice/{
sessionid}.mp3"
with open(file_path, "wb") as f:
f.write(base64.decodebytes(audio))
f.close()
return f"{
sessionid}.mp3"
3.6.2 返回数据结构说明
| 参数名称 | 类型 | 描述 |
|---|---|---|
| Audio | String | base64 |
| SessionId | String | 一次请求对应一个SessionId |
| Subtitles | Array of Subtitle | 时间戳信息,若未开启时间戳,则返回空数组。 |
| RequestId | String | 唯一请求 ID,每次请求都会返回。定位问题时需要提供该次请求的 RequestId。 |
四、参考资料
腾讯语音合成API文档:https://cloud.tencent.com/document/product/1073/37995