使用生成式人工智能来改善分析体验,使业务用户能够询问有关我们数据平台中可用数据的任何信息。
在本文中,我们将解释如何使用新的生成式人工智能模型 ( LLM ) 来改善业务用户在我们的分析平台上的体验。假设我们为零售销售经理提供 Web 应用程序或移动应用程序,他们可以使用自然语言实时分析销售和库存行为。
这些应用程序通常具有一系列限制,主要显示通用类型的分析,用户可以根据某些过滤器对其进行过滤或分段,并提供诸如以下的信息:
- 销售行为
- 通过...渠道贩卖
- 缺货
- 股票行为
所有这些数据,无论粒度大小,都可以回答某人之前确定的问题。问题在于,并非所有用户都有相同的问题,有时定制水平太高,以至于解决方案变成了一条大鲸鱼。大多数时候,信息是可用的,但没有时间将其包含在 Web 应用程序中。
过去几年,市场上出现了一些低代码解决方案,试图加快应用程序的开发速度,以尽可能快地响应此类用户的需求。所有这些平台都需要一些技术知识。LLM 模型使我们能够以自然语言与用户进行交互,并将他们的问题转化为代码并调用我们平台中的 API,从而能够以敏捷的方式向他们提供有价值的信息。
生成式人工智能营销平台用例
为了增强我们的销售平台,我们可以包括两个用例:
1. 迭代业务分析问题
允许业务用户通过以下功能询问有关我们数据平台中的数据的迭代问题:
- 能够用自然语言提问,可以是交互式的,但也必须允许用户保存他的个性化问题。
- 答案将基于更新的数据。
2. 讲故事
当您向业务用户提供有关销售共享的数据时,一个基本部分是讲故事。这可以增强理解并将数据转化为有价值的信息。如果我们能够让用户能够以自然语言获得这种解释,而不是用户必须解释指标,那就太好了。
实例:设计聊天营销
概述
这是一个实现起来非常简单的想法,并且为用户带来了很多商业价值,我们将训练我们的 LLM 模型,使其能够提出问题,以了解哪个数据服务提供信息。为此,我们的架构必须满足三个要求:
所有数据均通过API公开。
所有数据实体均已定义并记录。
我们有一个标准化的 API 层。
下图显示了该高级解决方案的架构:
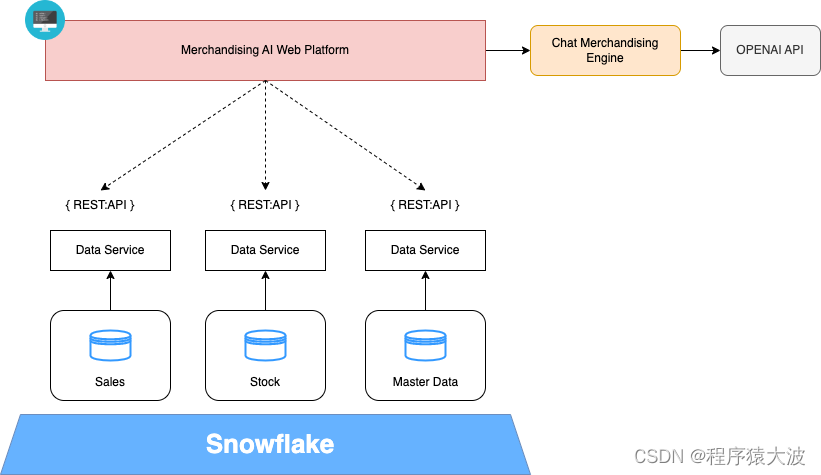
- Merchandising AI Web Platform:基于Vue的网络渠道,通过用户使用聊天推销。
- 数据服务:它提供API Rest来消费数据平台中可用的业务数据实体。
- Chat Merchandising Engine:Python后端服务,执行前端和LLM服务之间的集成;在本例中,我们使用 Open AI API。
- 开放人工智能:它提供了一个 Rest API 来访问生成式人工智能模型。
- 业务数据域和数据存储库:新一代数据仓库,例如 Snowflake,以业务实体可用的数据域为模型。
在此 PoC 中,我们使用了 OpenAI 服务,但您可以使用任何其他 SaaS 或部署您的 LLM;另一个重要的一点是,在这个用例中,我们不会向 OpenAI 服务发送任何业务数据 ,因为 LLM 模型所做的只是将用户以自然语言发出的请求转换为对我们数据服务的请求。
营销人工智能网络平台
通过 LLM 和生成式UI,前端获得了新的相关性、用户与其交互的方式以及前端如何响应交互;现在我们有一个新的参与者,即生成人工智能,它需要与前端交互来管理用户请求。
前端需要为用户消息提供上下文,并能够以用户想要的方式显示响应。在此 PoC 中,我们将从模型中得到不同类型的响应:
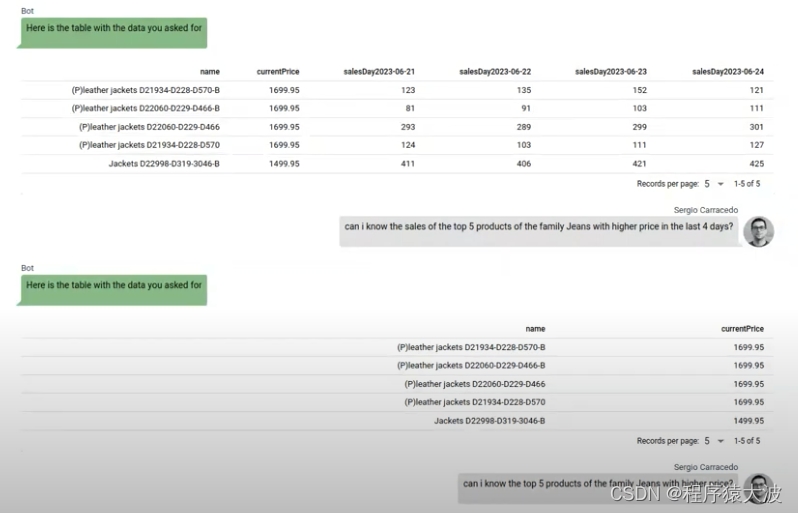
要在表中显示的数据数组:
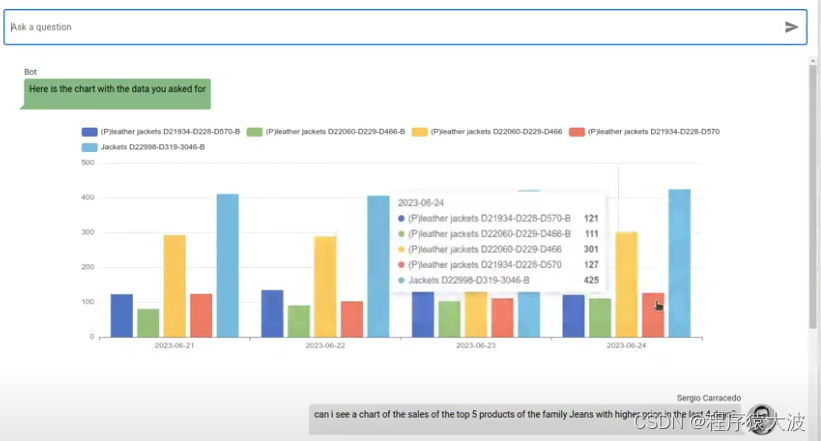
要在图表中显示的数据数组:
前端需要知道模型或用户希望在响应中看到的内容如何按要求行事;例如,如果用户请求一个图表,前端需要渲染一个图表;如果它要求一个表格,前端应该渲染一个表格,如果它刚刚经过测试,则显示文本(即使存在错误,我们也应该以不同的方式显示它)。
我们输入聊天商品引擎响应(在后端和前端):
export interface TextChatResponse {
type: 'text'
text: string
}
export interface TableDataChatResponse {
type: 'table-data'
data: TableData
}
export interface ChartChatResponse {
type: 'chart'
options: EChartOptions
}
export interface ErrorChatResponse {
type: 'error'
error: string
}
export type ChatResponse = TextChatResponse | TableDataChatResponse | ErrorChatResponse | ChartChatResponse这就是我们决定显示哪个组件的方式。
<div class="chat-messages">
<template v-for="(message, index) in messages" :key="index">
<q-chat-message
v-if="message.type === 'text'"
:avatar="message.avatar"
:name="message.name"
:sent="message.sent"
:text="message.text"
/>
<div class="chart" v-if="message.type === 'chart'">
<v-chart :option="message.options" autoresize class="chart"/>
</div>
<div class="table-wrapper" v-if="message.type === 'table-data'">
<q-table :columns="getTableCols(message.data)" :rows="message.data" dense></q-table>
</div>
</template>
</div>通过这种方法,前端可以以结构化的方式接收消息,并知道如何显示数据:作为文本、作为表格、作为图表或任何你能想到的东西,并且对于后端也非常有用,因为它可以获取侧通道的数据。
对于图表,您可以在 JS 对象中配置与图表相关的所有内容(对于任何类型的图表),因此在 PoC 的下一次迭代中,您可以向模型询问该对象,它可以告诉我们如何渲染图表,甚至是更适合数据的图表类型等。
聊天营销引擎
我们在引擎中的逻辑非常简单:它的职责只是充当前端、开放人工智能服务和我们的数据服务之间的网关。这是必要的,因为开放人工智能模型没有在我们的服务环境中进行训练。我们的引擎负责提供该上下文。如果模型经过训练,我们在该引擎中包含的小逻辑将位于前端服务层。
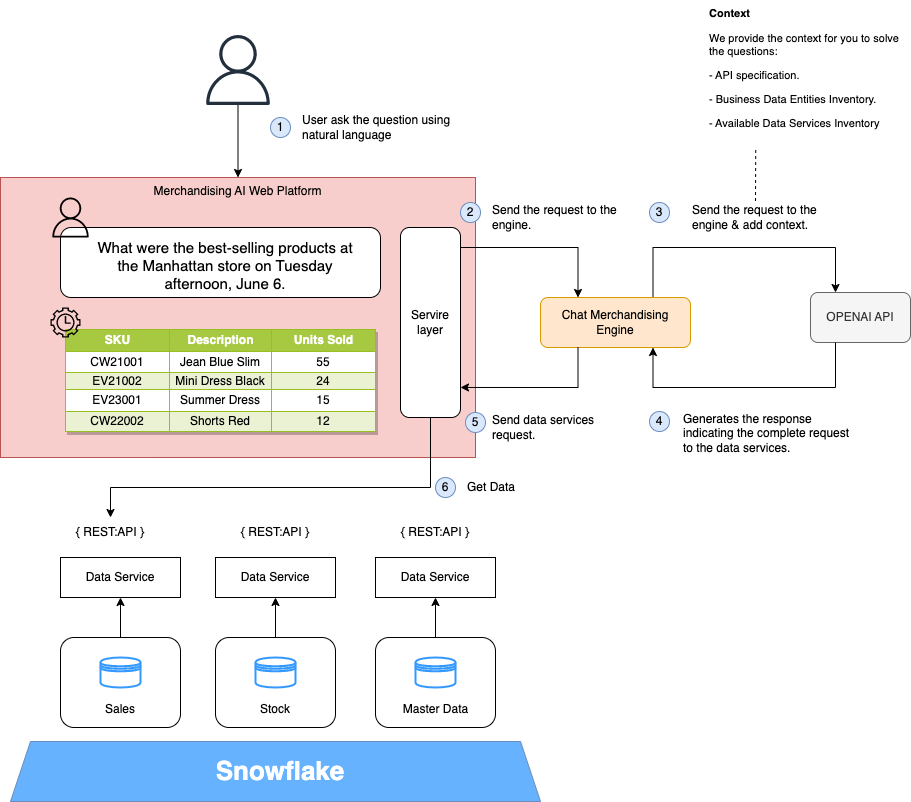
我们使用 Python 实现了这项服务,因为Open AI提供了一个库来促进与其 API 的集成。我们正在使用聊天完成 API(型号 gpt-3.5-turbo),但我们可以使用新功能函数调用(型号 gpt-3.5-turbo-0613)。
# Initial context
messages=[
{"role": "system", "content": API_description_context},
{"role": "system", "content": load_openapi_specification_from_yaml_to_string()},
{"role": "system", "content": entities},
]
# Add User Query to messages array
messages.append({"role": "user", "content": user_input})
# Call Open AI API
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0
)
# Get messages
generated_texts = [
choice.message["content"].strip() for choice in response["choices"]
]我们用自然语言描述组成了上下文,其中包括一些示例、API 规范和 API 的定义。
Merchandasing Data Service is an information query API, based on OPEN API 3,
this is an example of URL http://{business_domain}.retail.co/data/api/v1/{
{entity}}.
Following parameters are included in the API: "fields" to specify the attributes of the entity that we want to get;
"filter" to specify the conditions that must satisfy the search;
For example to answer the question of retrieving the products that are not equal to the JEANS family a value
would be products that are not equal to the JEANS family a value would be filter=familyName%%20ne%%20JEANS我们解析响应并使用正则表达式获取生成的 URL,尽管我们可以选择使用一些特殊引号的另一种策略。
def find_urls(model_message_response):
# Patrón para encontrar URLs
url_pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
urls = re.findall(url_pattern, model_message_response)
return urls我们还要求模型在 URL 中添加一个片段(例如 #chart),以便我们了解用户期望在前端看到什么
该解决方案比在用户输入中搜索字符串要好得多,因为用户可以在不使用图表词(即模型)的情况下请求图表,该模型“理解”谁决定使用图表表示的问题。
最后,我们将此答案发送回前端,因为对数据服务的调用是从前端本身进行的,这允许我们使用用户自己的 JWT 令牌来使用数据服务。
结论
在过去的几年里,许多组织和团队致力于拥有敏捷的架构、良好的数据治理和 API 策略,使他们能够以敏捷的方式适应变化。生成式人工智能模型可以提供巨大的商业价值,并且只需很少的努力就可以开始提供价值。
我们在几个小时内开发了这个 PoC,您可以在视频中看到,使用 Vue3、Quasar Ui 作为基本组件和表格,并使用 Echarts 来渲染图表和 Open AI。毫无疑问,算法是新趋势,也将是数据驱动战略的关键;从标准化和敏捷架构开始的组织在这一挑战中处于领先地位。