目录
Amazon Bedrock VS Amazon SageMake
什么时生成式人工智能
生成式人工智能(Generative Artificial Intelligence,简称生成式 AI)是一种基于机器学习和人工智能技术的范畴,其目标是让计算机系统能够自主地生成各种类型的数据,如文本、图像、音频等,而不仅仅是对已有数据的模仿或分类。生成式 AI 的核心能力在于创造新的内容,而不仅仅是对已知模式的重复应用。其中,生成式人工智能模型是生成式 AI 的重要组成部分,而 chatGPT 就是其中的一种代表性模型。成式 AI 的原理基于深度学习,特别是神经网络技术,它可以通过分析大量的训练数据来学习数据的分布和模式,然后利用这些学习到的模式来生成新的数据。生成式 AI 不仅可以生成高质量的文本,还可以用于图像生成、音乐创作、视频生成等各种领域。
亚马逊云的生成式 AI产品
AWS 为大型语言模型开发人员提供了多种可能性。Amazon Bedrock 是使用 LLM 构建和扩展生成式人工智能应用程序的最简单方法。Amazon Bedrock 是一项完全托管的服务,可通过 API 提供来自 Amazon 和领先 AI 初创企业的 LLM,因此您可以从各种 LLM 中进行选择,找到最适合您的应用场景的模型。


Amazon Bedrock VS Amazon SageMake
- mazon Bedrock和Amazon Sagemaker是两个独立的服务
- Amazon SageMaker是端到端的机器学习平台,它的功能包括从数据标注到数据训练、再到部署、上线以后的持续监控以及基于原始数据的再迭代等端到端的能力。在生成式AI大模型出现之前,它就已经非常成熟的在帮助客户解决问题了。
- Amazon Bedrock的定位是要解决以下几个核心的问题:
- 一是能帮客户快速找到行业领先模型,并通过API的方式尽可能的不用客户自己去管理底层硬件和运维即可访问。
- 二是,用户采用Amazon Bedrock做模型调优和训练的时候,和使用Amazon SageMaker的区别是,Amazon SageMaker首先是面向数据科学家,需要编写代码并提供数据以及添加参数去做模型和调优。从应用形式上,在Bedrock里面,客户只需要提供20个已经标注好的数据,就可以很快展开,不需要编写太多的代码。
- 二者基本的区分如果画一下用户画像的话,SageMaker是针对专业人员,Bedrock是尽可能降低门槛,让偏向于行业的场景用户能够更好的用起来。
- Bedrock作为一个新的、生成式AI的生产工具,依托于现有的五个已经预设的基础模型,通过API直接调用,生成更多的内容。 Amazon SageMaker是全方位的、全功能化的机器学习工具,包括数据标注到训练到推理,整个能力都是具备的,同时它也有一些预设的能力。可以根据需要选择适用的场景。也就是说,Bedrock只是在生成式AI领域,Amazon SageMaker是针对所有机器学习和人工智能领域。生成式AI只是AI的一部分,而Amazon SageMaker是面向整个AI/ML的。
- 另外,在部署集成方面,Amazon SageMaker和Bedrock还有一些结合点。事实上SageMaker的某些功能可以被复用到Bedrock训练出来的模型上面。比如客户通过Bedrock自己定制了一个模型出来,新的模型在应用的时候,模型管理的流程是可以互通的。客户可以将基础模型与 Amazon SageMaker 机器学习功能集成,使用 Experiments 测试不同模型和使用Pipelines 大规模管理基础模型等等。
Amazon Bedrock的由来
具体来说,Bedrock主要包含两部分,一个是亚马逊云科技自己的模型Titan,另一个是来自初创公司AI21 Labs、Anthropic,以及Stability AI的基础模型。
基础模型具体包括:
-
Amazon自研Titan
-
Claude(Anthropic)
-
Jurassic-2(AI21 Labs )
-
Stable Diffusion(Stability.AI)
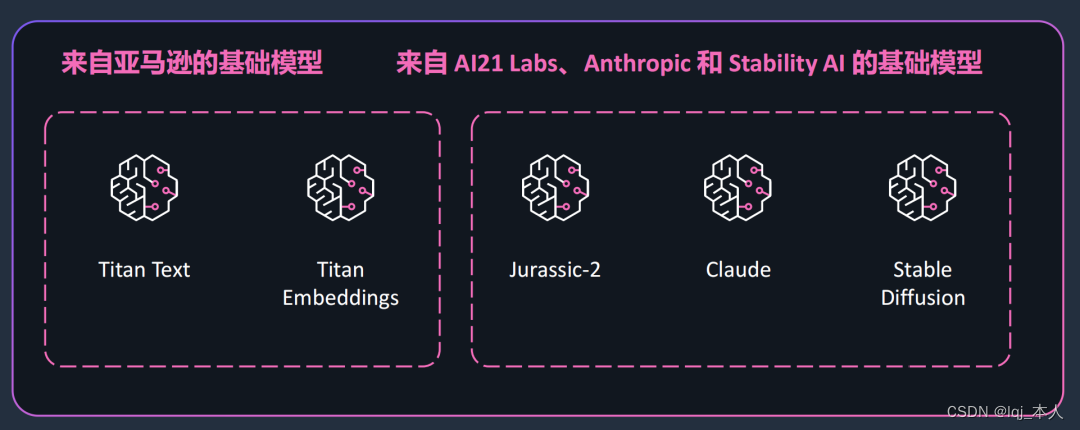
Titan基础模型的构建是基于亚马逊云科技在机器学习领域20多年的经验。Titan包含了两个大语言模型,一个是用于生成文本的Titan text,一个是让网络搜索个性化的Titan Embeddings。Titan text针对的是总结、文本生成、分类、开放式问答和信息提取等任务。文本嵌入Titan Embeddings模型,能够将文本输入(字词、短语、大篇幅文章)翻译成包含语义的数字表达(embeddings入编码)。

用户可以通过自己的数据定制Titan模型。并且,亚马逊云科技非常保护用户数据隐私,不会将用户数据拿来再训练Titan模型。而且,不同于其他大模型时常会出现的「幻觉」,Titan在训练时非常关注精度,就是为了保证产生的响应一定是高质量的。除了亚马逊云科技的Titan模型,开发者们还可以利用其他的基础模型。其中包括AI21 Labs开发的Jurassic-2多语种大语言模型系列,能够根据自然语言指令生成文本内容,目前支持西班牙语、法语、德语、葡萄牙语、意大利语和荷兰语。还有Anthropic开发的大语言模型Claude,能够执行多轮对话和文本处理任务。第三个基础模型便是Stability AI的文本图像生成模型Stable Diffusion。通过这些模型,开发者只用20个样本,就能一键定制自己的模型。
举个例子,一位营销经理想为手提包新品开发广告创意,他只需向Bedrock提供标注过的最佳广告,以及新品描述,Bedrock就能自动生成媒体推文、展示广告和产品网页。同样的,所有数据都进行了加密,任何客户数据都不会被用于训练底层模型。目前,Coda AI、Deloitte、埃森哲、Infosys等合作伙伴已经用上了Bedrock。
Amazon Bedrock 的申请与使用
-
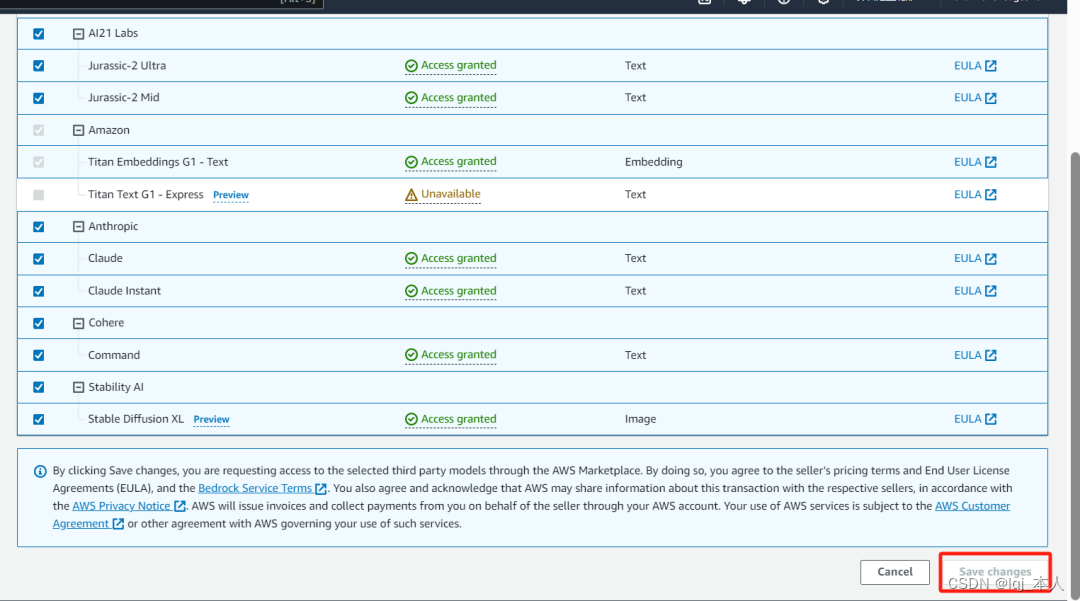
首先在使用Bedrock之前要首先申请模型的访问权限,目前只在us-east-1,us-west-2,ap-southeast-1,ap-northeast-1中可用,需要先申请模型的访问权限,对于所有模型,默认都是没有开放的,在model access界面首先选择请求访问,会让您这边填写一下公司名称,网址,用途,然后请求访问权限就好,这边公司网址尽量选择海外,目前中国区域不稳定,另外这个账号的付款公司也是需要选择海外的,之后选择自己所需模型。
-
登录Bedrock控制台之后,首先到model access界面,点击Edit,勾选需要的模型,如不需要的模型只要勾选留空会自动删除,然后选择保存,保存之后就可以使用所提供的模型了,比如Claude和Stable Diffusion XL等。因为使用外海时默认为英文状态下的控制台。
-
创建完成之后,通过控制台左侧可以看到很多的功能,我们可以选择我们的base model,在 Amazon Bedrock 控制台中,可以按各种模型对其进行分组 属性。还可以筛选模型视图、搜索模型和查看信息关于模型提供程序。

-
选择模型之后,在playground中打开,就可以使用模型的各个功能了
Amazon Bedrock 的使用案例
比如,我们制作一个属于自己的AI认知聊天工具,可以通过选择Bedrock的一些基础模型或者是我们自己微调过的模型来进行,例如: